基于朴素贝叶斯点击预测的查询推荐方法
2016-11-08李朝锋
石 雁 李朝锋
(江南大学物联网工程学院 江苏 无锡 214122)
基于朴素贝叶斯点击预测的查询推荐方法
石雁李朝锋
(江南大学物联网工程学院江苏 无锡 214122)
查询推荐作为一种改善用户查询体验和效率的重要方式,可以帮助用户筛选并提供更加准确的查询描述。目前很多查询推荐方法主要集中在热门推荐或是基于相似度匹配的推荐上,忽略了用户的查询意图,无法有效提供个性化推荐。为此,基于对用户查询点击日志进行分析与挖掘,训练出一个朴素贝叶斯模型,针对用户输入的查询,根据历史数据预测其与URL的点击率,再利用二分图将URL的预测点击值平均分配给相对应的每个查询项,最后结合Jaccard相似度和时间相关因子综合分析用户当前输入的查询与历史中查询的相关度,并给出推荐。实验证明了该方法的可行性并取得了较好的推荐效果。
查询推荐用户日志点击预测朴素贝叶斯二分图Jaccard相似度
0 引 言
在目前主要根据关键词进行检索的搜索引擎框架中,用户往往无法得到令其满意的返回结果。这一方面是由于网络数据呈海量增长态势,每条查询都可能会有上万到几十万条的相关反馈信息,在这庞杂的信息中要找到用户满意的结果,这就要求用户尽可能准确地描述查询请求,同时需要搜索引擎在一定程度上能够理解用户查询意图,这对用户和搜索引擎来说,都面临一定挑战。而另一方面,在用户获得了比较满意的结果后,如何帮助用户发掘潜在的相关信息来提升用户的搜索体验,这也是亟待解决的问题。
查询推荐作为搜索引擎改善用户查询体验的有效方式之一,其旨在接受用户输入某个查询后,尽可能理解用户的查询需求并向用户推荐与用户查询语义相关的其他查询[1]。
在搜索点击日志中,包含了大量用户真实的搜索行为[2],对这些数据进行分析与挖掘,可以更好地理解用户查询意图,发现与用户查询相关的其他查询。因此,本文在用户点击日志的基础上,对用户搜索行为进行建模,找出与用户查询意图相关的查询信息,并给出个性化推荐。
1 查询推荐相关研究
目前查询推荐已经作为国内外各大商业搜索引擎的标准配置功能之一,在学术界也得到了广泛关注和研究。然而现在的搜索引擎中大多针对用户输入的查询文本本身,进行改写和扩展,或是简单地提供与用户查询文本近似的热门搜索作为推荐,并没有考虑查询中潜在的用户搜索意图。如果搜索引擎能够根据查询词自动找出背后的用户搜索意图,然后根据不同的用户,提供不同的查询推荐,这无疑会增加搜索引擎用户的搜索体验。而查询日志中记录了用户大量的查询点击信息,这些信息体现了用户的查询习惯和点击意图,利用日志可以挖掘用户潜在的查询意图,目前针对日志进行分析的主流方法主要有两类[3]:基于查询会话(Session)的方法和基于点击图的方法。
1.1基于查询会话方法
查询会话是某个用户在较短时间内连续发出的多个查询,一般而言,在同一查询会话内的查询之间往往存在一定的语义相关性[4]。比如某个用户想要购买手机,在某个集中的时间内连续向搜索引擎发出:“苹果手机”、“iphone 6图片”、“iphone 6价格”等一连串查询,这就形成一个查询会话。通过将用户搜索日志划分为大量不同的查询会话,然后利用各种数据挖掘算法对查询会话进行统计与分析,推荐的结果往往是一批查询对,这些查询在搜索过程中经常共同出现,反应了用户的搜索意图。李亚楠等人认为同一Session中的查询都具有语义相关性,而其中的前后查询具有一定的概率“跳转”,所以对Session进行划分,并据此建立查询关系图,使用加权的SimRank算法在图结构中进行相似计算,从而挖掘出查询间的间接关联和语义关系[4]。在文献[5]中,将查询推荐分为两阶段:第一阶段分析用户日志,从中抽取用户Session,第二阶段从用户Session中使用关联规则算法挖掘出查询间的关系,找出相关查询。Sadikov等人提出一种结合文档点击和用户查询Session的共现信息,利用近似用户搜索行为的马尔可夫多随机游走模型,根据用户的可能潜在意图进行查询修改聚类,用来改善搜索引擎中返回的查询建议[6]。
1.2基于点击图方法
从用户查询日志记录中可以看到用户提出某个查询,搜索引擎返回相关结果后,用户会有选择地点击其中某些链接。之所以认为这种点击行为很有意义,是因为用户在看了返回的网页标题和摘要后,认为此链接和查询比较相关,所以才会点击。而将用户的查询和相对应点击的链接网址(URL)使用边连接起来,就构成了点击图,这是一种二分图[7],一端节点是用户发出的查询,另一端是对应点击的URL。在使用点击图作为查询推荐的一个简单的通用基本框架是:如果两个查询分别对应的点击URL中,有相当一部分比例是相同的,那么说明这两个查询有很大的语义相关性,可以作为相关查询进行推荐。不同的学者据此也提出了各种扩展和改进的方法。Hamada M.Zahera 等人提出根据查询和URL点击二分图,对查询进行相似聚类,然后对用户提出的查询,找出与其最相似的一组进行排序推荐[8]。刘钰峰等人提出基于查询上下文训练词汇与查询间的语义关系,并结合查询和URL对应的点击图以及查询的序列行为构建Term-Query-URL异构信息网络,采用重启动随机游走算法进行查询推荐,该方法综合了语义和日志信息,提高了稀疏查询的推荐效果[9]。文献[10]中,提出一种新的基于上下文感知查询建议方法,该方法分为线下和线上两步。在线下,使用用户点击图进行聚类,把查询总结成不同概念,然后为Session数据序列构造概念后缀树作为查询建议模型。在线上,把用户提交的查询序列映射到概念中,获取用户搜索上下文,通过查询概念后缀树得到相关查询。
综上,除了日志分析方法中的两个主流方法外,还有基于相似度方法、基于时间分布法等[1]。虽然目前提出的很多方法对查询推荐有一定的效果,但由于大多具有高度复杂性并且用户意图不明确,所以很难得到广泛的实际应用。本文根据点击日志,对用户的查询进行意图点击预测,进而将预测值传播给其他查询,结合相似度和时间因子获得相关查询。最后在搜狗实验室提供的数据中进行实验,获得了较好的推荐效果。
2 基于用户日志挖掘的查询推荐
在对用户日志和搜索引擎进行深入分析后,提出基于图1的框架来研究查询推荐。从中可以看出用户在发出查询后,一部分经搜索引擎返回相关网页,而另一部分使用朴素贝叶斯针对用户查询,预测URL的点击率,将其值用在反向点击图中,从而找出相关查询,推荐给用户。
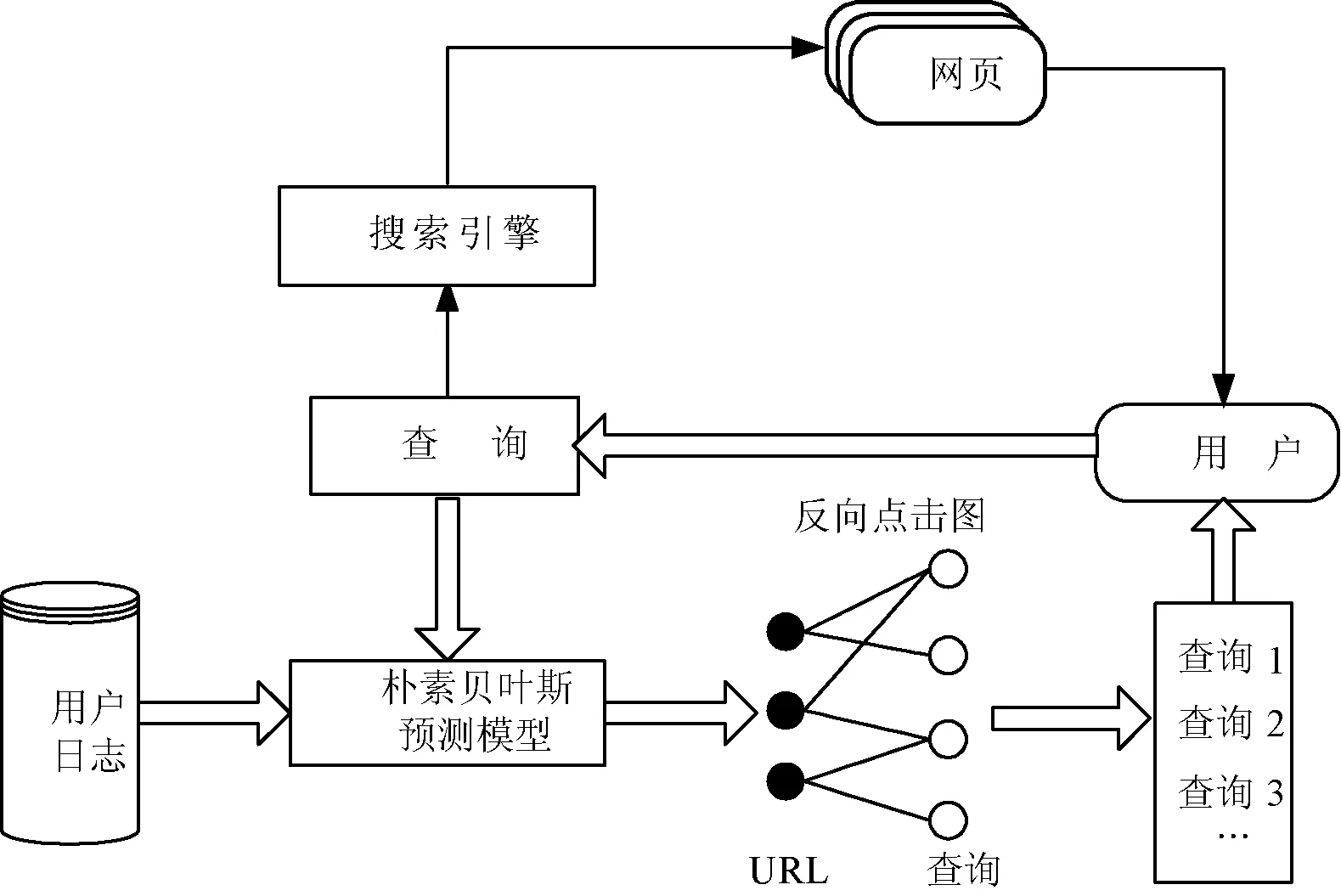
图1 查询推荐基本结构
2.1使用朴素贝叶斯进行URL点击率预测
朴素贝叶斯是一种基于贝叶斯理论的有监督的概率分类算法,尤其适用于样本特征维数很高的情形。有资料显示,就算样本属性相互独立的假设不成立,或者在完全相反的情况下(属性相互依赖),依然可以证明该算法是最优的[11]。在这里,将朴素贝叶斯算法作为一种预测模型,用它来预测URL对于用户及其所提交的查询的点击率,也就是说可以根据它计算出用户在提交某个查询时想要看到某个链接的概率。
首先,需要根据用户日志对朴素贝叶斯进行训练,将每个URL作为概念,每个与其对应的查询作为样本,根据所需计算出各个概念的先验概率及其对应的样本的条件概率,然后再依据用户当前输入的查询(实例)计算其与每个概念的点击值。具体过程如下:
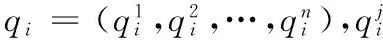
输出:实例q对应URL的点击率。
a) URL的先验概率及样本属性的条件概率
(1)
(2)
式(1)代表每个URL的先验概率,分子为每个URL的频数,分母为样本个数;式(2)代表每个属性的条件概率,分子为属性和URL的联合概率。
b) 经过训练后,就可以对用户当前提出的查询实例q=(q1,q2,…,qn),进行URL点击预测。公式如下:
(3)
这样每个相关URL都会有一个预测值,该预测值代表了用户输入的查询和URL的点击相关度,值越大,表示用户想要点击URL的意图性越强。
2.2使用反向点击图进行查询推荐
2.2.1反向点击图推荐模型
基于二分图结构,提出一种URL-Query的反向点击图推荐模型,如图2所示。
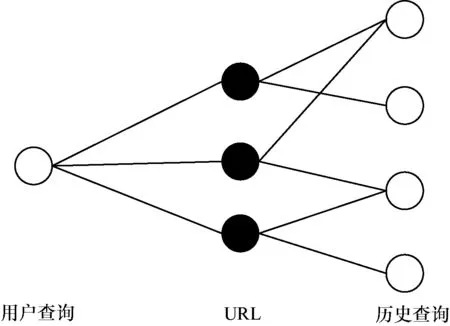
图2 反向点击图模型
在该模型中,根据2.1节计算出用户当前查询对于历史点击中URL的预测点击值,作为URL的权重,并将其平均分配给与其对应的查询,这样每个查询经过整合后会有一个相关值,这个相关值也代表了用户的查询意图,如图3所示。
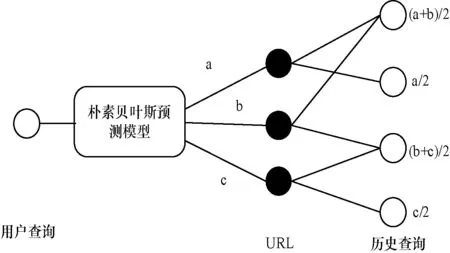
图3 预测点击值的分配
考虑一个由n个URL和m个查询(Query)构成的点击二分图,表示为G(U,Q,E),E表示URL和Query之间连接的边,URL节点表示为U={(u1,a1),(u2,a2),…,(un,an)},其中ai为计算用户当前查询的预测点击值,Query节点表示为Q={q1,q2,…,qm}。根据图3中的计算,每个qi的相关值经过传播求和,计算如下:
(4)
其中:k(uj)表示与uj连接的qi的个数;aj为URL的预测值。
然而由于对用户输入的查询进行朴素贝叶斯URL点击预测后的值会被均分到相对应的历史查询中,这会导致将每个查询均等化。鉴于此,对式(4)进行补充修正,加入了用户历史查询和对应URL的点击比率,公式如下:
(5)
其中:公式的后半部分表示qi的点击数占总点击数的比率,比率越大,表示在点击历史中,用户关注的越多,用户想要点击的意图性就越强。
2.2.2融合文本相似度和时间因子
利用朴素贝叶斯预测用户查询行为,本质上是找到查询与链接(URL)的关系,但这忽略了用户查询与历史查询之间的文本相似性,很多时候我们想搜索的是和当前词相似的或是扩展的查询内容,比如在百度输入“江南大学”,在网页底部就会出现相关搜索,如表1所示。

表1 “江南大学”相关搜索推荐
在表中可以看到除了其他大学外(而这些大学我们假设经过用户点击过的并给予预测的推荐查询),与“江南大学”相似的或者说是扩展的推荐查询词占了较高比率,用户可能想查询与“江南大学”有直接关系的信息。而通过融合文本相似度可以增强这一相关性,在这里采用简单有效的Jaccard相关系数来计算当前用户提交的查询和用户历史查询的文本相似性,公式如下:
(6)
在点击日志中,时间因素是一个重要的上下文信息。一般来说,用户当前的查询和用户历史中最近的点击行为关系更大[12]。现在假设用户在时间t发出一个查询q,点击历史数据中的URL和其对应查询中的时间,记为:t0,t1,t2,t3,t4,t5,如图4所示,这样图中后面的四个查询的点击时间分别包括:q1(t0,t2),q2(t1),q3(t3,t4),q4(t5)。可以看到一个查询对应多个不同的URL,会有不同的点击时间,所以不能简单地采用最近时间作为标准衡量时间。对此,使用式(7)计算相关时间因子。该式综合了当前时间和所有历史时间差的和的均值作为衡量因素。
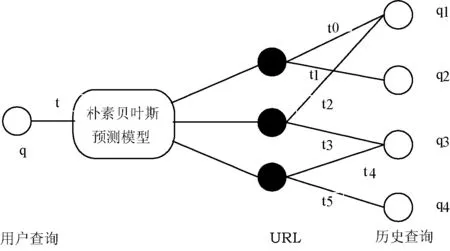
图4 查询点击时间
(7)
其中:α是时间衰减参数,可以根据不同的数据集选择合适的参数,如果用户查询意图变化快,就选择较大的值,相反需要取较小值。tq是用户当前查询时间,tqi是不同的查询点击时间,分母是点击次数。这样就可以根据时间的变化来优化预测推荐。
为了举例说明,现假设用户发出一个查询q时间为9:40,在用户历史点击数据中,查询q1的时间为8:40、10:40和q2的时间为7:40、11:40、13:40。按式(7)计算相关时间因子t(q,q1)和t(q,q2)(这里α取1,时间为小时)。所以不论从时间上的直观性来看,还是计算后的数值大小比较上,q和q1更具有明显的时间相关性。
≈0.27
在最终的推荐中,整合式(5)、式(6)和式(7),如式(8):
(8)
通过计算,对qi的相关值进行降值排序,按Top-N推荐给用户。
3 实验与结果分析
3.1实验数据
本实验采用的数据来自搜狗实验室提供的2008年6月份查询日志中的一天数据,共1 724 264条查询。该日志中包括每条查询的时间、用户ID、查询串、URL返回的排名、点击顺序以及点击的URL。经过预处理,选择用户查询数在200条以上的点击数据,在这里选取了10名用户,共2803条查询。每名用户中点击数据的80%用作训练,另外一部分用来测试。实验平台使用Intel® CoreTMDuo T2450 @ 2.00 GHz双核处理器,2 GB内存,Windows XP 32位操作系统,算法使用Java语言编写,分词工具使用来自轻量级中文分词包IKAnalyzer2012_u6.jar[13]。
3.2实验设计及结果分析
尽管在国内外关于查询推荐的相关研究已有不少成果,但总体上仍然缺乏统一和客观的评价方法,尤其是针对中文的查询推荐的研究,仍然比较欠缺。由于对于一个查询来说并不存在某种标准的推荐结果,在考虑基于用户意图的查询推荐时,更是无法把握用户的真实想法。因此,一般的查询推荐评价都采用信息检索里的评价指标[14]。本文采用Top-N的精度P@N(Precision at N)和平均精度均值MAP(Mean Average Precision)作为评价指标。由于在所有候选推荐中,很难得到所有相关查询数目,因而召回率(Recall)很少作为评价指标[15]。实验对于一个给定的查询qi,系统推荐出m个查询,这m个查询中的P@N精度为:
(9)
(10)
其中K是查询测试集,这里选取每个用户的20个查询作为测试集,N为5,然后由人工进行判断产生的查询推荐是否相关。对于单个查询qi的平均精度,定义为:
(11)
(12)
在实验中,选取文献[8]中基于查询日志的查询聚类方法和文献[16]的基于用户兴趣的Apriori方法进行对比实验(在实验中分别称为查询聚类法和Apriori法。)本文方法的时间参数α需要根据不同用户点击数据集的时间分布进行选择,这里α取1。在P@5和MAP上的对比结果如表2。
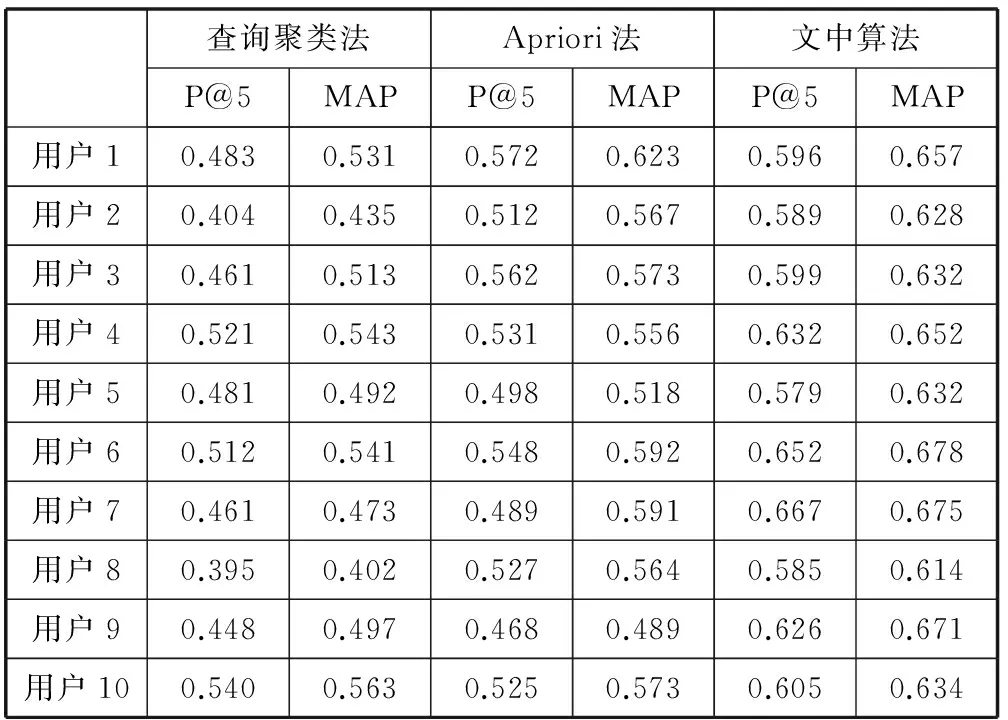
表2 三种算法在P@5和MAP上的对比结果
本文在P@3、 P@5、P@7、P@9上进一步对这三种算法在不同P@N上的变化进行测试对比。从10名用户中选取用户1和用户2作参考,图5、图6为对比结果,从中可以看出本文方法在P@N上的精准度要优于前两种方法。
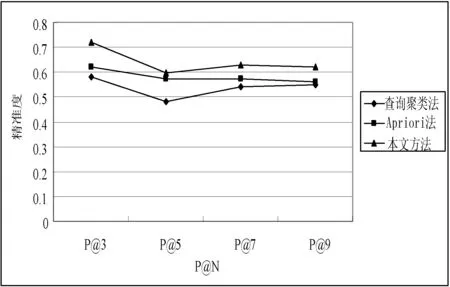
图5 用户1三种算法在不同P@N上的比较
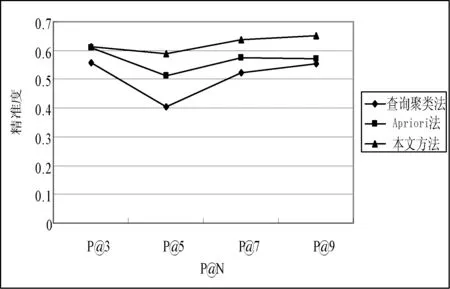
图6 用户2三种算法在不同P@N上的比较
为了比较直观地观察推荐效果,现列出部分查询推荐示例如表3所示,从中可以看到,本文的算法在推荐的相关查询上取得了较好效果。由于本算法关注的是用户查询的相关性和意图性,忽略了查询间的冗余性,从而在一定程序上,推荐的查询有一定的重复率。另外,由于用户查询的稀疏问题,也造成了一定的推荐不明确性。

表3 部分查询推荐示例
续表3
4 结 语
查询推荐作为个性化搜索引擎的一项重要研究课题,其改善和提升了用户的搜索体验,它可以为不同的用户提供多样性和个性化的查询推荐。本文在前人的研究基础上,首先采用基于朴素贝叶斯模型预测用户查询点击URL的值,然后使用反向点击图将每个URL预测值作为用户查询意图传播给日志中与其对应的查询项,再结合文本匹配度和时间相关因子作出Top-N相关查询推荐。实验结果表明了该方法的有效性以及在一定程度上表达了用户的查询意图。在下一阶段的研究中,将会考虑查询的稀疏问题以及将基于用户的协同推荐理论用到查询推荐上。
[1] 李亚楠,王斌,李锦涛.搜索引擎查询推荐技术综述[J].中文信息学报,2010,24(6):75-84.
[2] 董志安,吕学强.基于百度搜索日志的用户行为分析[J].计算机应用与软件,2013,30(7):17-20.
[3] 张俊林.这就是搜索引擎:核心技术详解[M].北京:电子工业出版社,2012:146-258.
[4] 李亚楠,许晟,王斌.基于加权SimRank的中文查询推荐研究[J].中文信息学报,2010,24(3):4-10.
[5]FonsecaBM,GolghePB,MoursaESDe,etal.DiscoveringSearchEngineRelatedQueriesUsingAssociationRules[J].JournalofWebEngineering,2004,2(4):215-227.
[6]SadikovE,MadhavanJ,WangL,etal.Clusteringqueryrefinementsbyuserintent[C]//Proceedingsofthe19thinternationalconferenceonWorldWideWeb.Raleigh,NorthCarolina,USA:ACM,2010:841-850.
[7] 王栖,段双艳.一种改进的基于二部图网络结构的推荐算法[J].计算机应用研究,2013,30(3):771-774.
[8]HamadaMZahera,GamalFElHady,WaielFAbdEl-Wahed.QueryRecommendationforImprovingSearchEngineResults[J].InternationalJournalofInformationRetrievalResearch,2011,1(1):45-52.
[9] 刘钰锋,李仁发.基于Term-Query-URL异构信息网络的查询推荐[J].湖南大学学报:自然科学版,2014,41(5):106-112.
[10]HuanhuanCao,DaxinJiang,JianPei,etal.Context-AwareQuerySuggestionbyMiningClick-ThroughandSessionData[C]//Proceedingsofthe14thACMSIGKDDinternationalconferenceonKnowledgediscoveryanddatamining.NewYork:ACM,2008:875-883.
[11]RishI.AnempiricalstudyofthenaïveBayesclassifier[EB/OL].IBMResearchReport,RC22230 (W0111-014),2001:41-46.http://www.cc.gatech.edu/~isbell/classes/reading/papers/Rish.pdf.
[12] 项亮.推荐系统实战[M].北京:人民邮电出版社,2012:130-132.
[13] 林良益.基于Java语言开发的轻量级的中文分词工具包[EB/OL].(2015-1).http://git.oschina.net/wltea/IK-Analyzer-2012FF/tree/master.
[14]RicardoBaeza-Yates,BerthierRibeiro-Neto.现代信息检索[M].黄萱菁,张奇,邱锡鹏,译.2版.北京:机械工业出版社,2012:98-103.
[15] 廖振.基于查询点击核心图的查询推荐问题研究[D].天津:南开大学,2013.
[16] 石林,徐飞,徐守坤.基于用户兴趣建模的个性化推荐[J].计算机应用与软件,2013,30(12):211-214,264.
QUERY RECOMMENDATION BASED ON NAIVE BAYES CLICK PREDICTION
Shi YanLi Chaofeng
(School of Internet of Things Engineering,Jiangnan University,Wuxi 214122,Jiangsu,China)
Query recommendation, as an important way to improve user-query experience and efficiency, can help users to filter and offer more accurate query descriptions. Many of the current query recommendation methods mainly focus on popular recommendation or the recommendation based on similarity matching, but neglect user’s query intention, thus are unable to effectively provide the personalised recommendation. Therefore, on the basis of analysing and mining users’ query-click logs, we have trained a Naive Bayes model. Aiming at the queries inputted by the user, the model predicts CTR (click-through rate) between these queries and URL according to historical data, then uses bipartite graph to averagely assign the predicted CTR of URL to each corresponding query, and at last it combines the Jaccard similarity with time correlation factor to comprehensively analyse the relevance between the query currently inputted by the user and the historical queries, and provides the recommendations. In subsequent experiment it is proved the feasibility of this method, as well as the better recommendation effect achieved.
Query recommendationUser logClick-through predictionNaïve bayesBipartite graphJaccard similarity
2015-07-07。国家自然科学基金项目(61170120)。石雁,硕士,主研领域:信息检索,推荐系统。李朝锋,教授。
TP391
A
10.3969/j.issn.1000-386x.2016.10.005
