基于LDA的微博用户粉丝亲密度评价模型
2016-11-08王秋森俞浩亮徐浩诚冯旭鹏刘利军黄青松
王秋森 俞浩亮 徐浩诚 冯旭鹏 刘利军 黄青松,3*
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)2(昆明理工大学教育技术与网络中心 云南 昆明 650500)3(云南省计算机技术应用重点实验室 云南 昆明 650500)
基于LDA的微博用户粉丝亲密度评价模型
王秋森1俞浩亮1徐浩诚1冯旭鹏2刘利军1黄青松1,3*
1(昆明理工大学信息工程与自动化学院云南 昆明 650500)2(昆明理工大学教育技术与网络中心云南 昆明 650500)3(云南省计算机技术应用重点实验室云南 昆明 650500)
用户关系是目前微博研究的热门方向,微博用户亲密度评价在对用户隐含亲密粉丝的发现、微博网络环境优化等方面具有重要意义。目前微博用户群体庞大且关系复杂,仅从用户自身出发,以用户特征和关系网络等为依据对用户关系亲密度评价的准确率太低。针对这一问题,提出基于LDA的微博用户粉丝亲密度评价模型。首先,对用户粉丝集中非活跃粉丝过滤剔除,获取其活跃粉丝。然后,利用LDA主题模型对用户某时间段所发微博集进行训练,获取用户阶段性微博的主题分布;同时通过主题分布推断其兴趣取向分布,并利用余弦相似方法计算用户与其粉丝之间的兴趣相似度。最后,结合用户的背景相似度和关系紧密度,为用户建立综合的亲密度评价标准。通过新浪API接口抓取微博近期相关数据,组成实验数据集。在数据集上基于评价的推荐实验结果表明,所提出的模型方法具有较高的准确率和有效性。
亲密度LDA粉丝主题模型相似度
0 引 言
微博,继Twitter问世之后迅速发展成为一种主流的信息发布社交网络平台。以新浪微博为代表,其简洁性、实时性等特点[1]以及新颖的表现形式、独特的传播方式[2],迅速吸引了大量的使用人群,成为了国内最重要的社交媒体之一。微博从最基本的用户信息交流,逐渐发展成为信息发布和商业营销的平台,这种发展为社交网络的用户关系分析与用户个性化推荐提供了良好的研究环境。
社交网络用户关系分析的相关研究主要集中在用户影响力分析[3]、信息的传播[4]等方向,体现了用户关系在社交网络中重要研究价值。用户关系分析,以微博用户亲密度分析为代表,为用户寻找隐性亲密粉丝提供良好依据,在构建由用户彼此亲密粉丝组成的微博网络环境上提供有效资源。其在优化社交网络环境、推进社交网络的透明化发展、用户个性化推荐以及企业商业化推荐等方面都具有重要的现实意义。
对微博用户关系的分析,Yanagimoto等人[5]将微博社交网络视为一个加权无向图,每个边表示用户之间的关系,边的权值表示他们之间的关系强度[6],通过比较相关特征,计算用户之间关系强度。这种方法在用户关系的分析上有一定效果,但忽略了用户自身属性特征,所以对用户关系强度的评价不够客观。Kahanda等人[7]利用用户之间的交互性和自身属性特征来评价用户关系强度。Xiang等人[8]结合了用户之间的交互性和用户相似度来计算用户的关系强度。以上研究侧重于从用户自身出发进行分析研究,其优点是对用户关系强度评价效果较为明显,但是忽略了微博内容对用户关系的影响,因此对用户之间个性化特点的评价不准确。
用户关系分析经常被应用于用户个性化推荐。Chen等人[9]通过获取社交网络的历史数据,凭借基于内容的方法进行用户推荐获得了一定效果,但单纯使用基于内容的方法比较片面,不能很好体现用户的推荐行为。Hannon等人[10]采用了基于内容相似和协同过滤方法来推荐Twitter用户,取得了一定的推荐效果,但该方法还是未能考虑用户的个人属性特征,在用户个性化推荐方面的效果不够理想。徐雅斌等人[11]提出了选取反映微博用户之间相关性的多个特征,并通过逻辑回归模型对潜在的用户进行评分排序,为目标用户推荐前N个潜在用户,在用户普通推荐上效果较为明显。但该方法对用户个人信息特征选取不准确,而且忽略了用户的兴趣取向等重要特征因素,使得该方法在用户个性化推荐上效果不明显。
针对传统方法在微博用户关系评价分析中准确率低的现象,本文提出基于LDA的微博用户粉丝亲密度评价模型。从微博及微博用户本身出发,综合考虑了微博用户的被动活跃度(其他用户对该用户的主动性)、用户之间的背景相似度(选取用户有针对性的自身属性建立向量,用以计算用户之间的相似度)、用户之间的关系强度[6,12](用户之间的转发、评论、提及互动强度)等属性特征,并结合LDA主题模型对微博内容进行分析。在微博内容分析方面,首先,对于微博内容的主题进行分析,获取用户相关的主题分布;然后通过主题分布推断其兴趣分布,以此计算博主与每一个粉丝的兴趣相似度;最后,融合以上特征为用户建立综合亲密度评价得分标准,按评价得分结果进行Top-N排名,得到该评价模型下的用户推荐列表。利用新浪API接口抓取微博近期相关数据,组成实验数据集。在数据集上基于评价的推荐实验结果表明,本文提出的模型方法在用户的个性化推荐应用方面更有针对性,效果更好。
1 用户粉丝亲密度的评价模型
该部分主要介绍用户亲密粉丝的评价推荐流程中的用户粉丝亲密度评价模型,如图1第三部分所示。用户亲密粉丝评价推荐流程主要由微博数据获取、构建数据、用户粉丝亲密度评价模型(BLDA)和推荐粉丝排名四个部分组成。第一部分,通过微博API按要求采集微博相关数据,并将其存入数据库;第二部分,通过分析数据库数据,建立博主与之对应粉丝集合的数据集;第三部分,通过用户粉丝亲密度评价模型对每个粉丝给出对应的综合评价得分;第四部分,根据第三部分得到的综合评价分数,按得分高低顺序推荐出前N个粉丝为亲密粉丝。下文详细介绍用户粉丝亲密度评价模型,具体包括微博用户粉丝活跃度筛选、微博用户背景相似度分析、微博用户关系强度对比、微博用户兴趣相似度分析;最后给出粉丝亲密度综合评价得分计算方法。
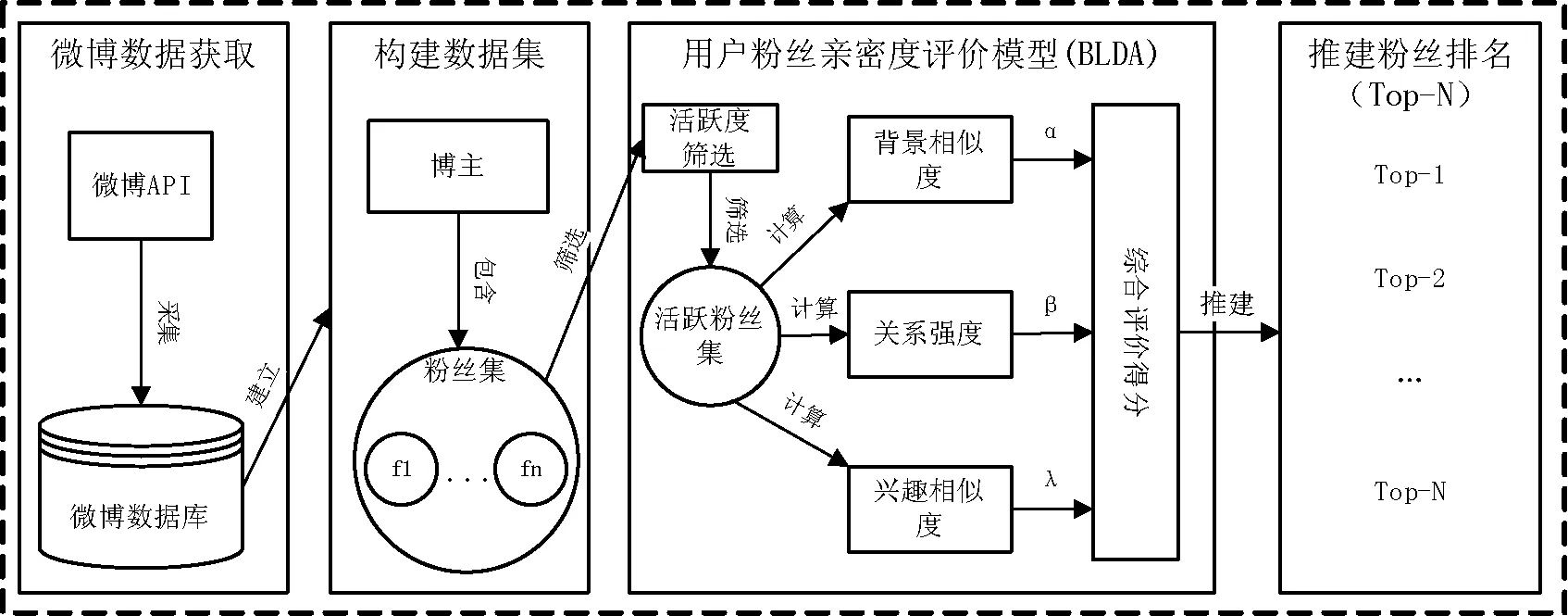
图1 用户亲密粉丝评价推荐流程
1.1微博用户粉丝活跃粉丝筛选
用户粉丝亲密度评价推荐对效率和准确率的精度要求很高,如果笼统对博主所有的粉丝进行评价推荐,会导致效率和准确率降低。特别当粉丝中包含大量对粉丝亲密度评价有干扰的“僵尸粉”时,评价推荐的准确率会大大降低。因此,在用户粉丝亲密度评价之前,需要从粉丝集合中剔除这些粉丝。针对“僵尸粉”主动性好、被动性差的特点,本文提出用户被动活跃度指标对博主的粉丝进行筛选,定义如下:
定义1令b表示某一个博主,被动活跃阈值为θ,则其活跃粉丝集合表示为F(b)。假定在微博数据时间段K内,微博用户u发表原创的、被转发的以及被评论的数目的总和为S(u),那么用户的被动活跃度a可表示为:
(1)
当博主的某粉丝用户的被动活跃度a低于事先设定的阈值θ时,剔除该粉丝。博主b剩下的粉丝为有效活跃粉丝,表示为F(b)。
1.2微博用户背景相似度分析
活跃在背景环境相似下的微博用户,会有相似的人生观、价值观等一些内在共性,这样的群体更容易发展成为亲密粉丝关系。本文选取微博用户的相关背景属性,主要包括用户年龄、注册时间(微龄)、是否加V、关注数/粉丝数、男粉丝/女粉丝、粉丝对博主博文行为/博主所发博文,进行相似度分析。则对微博用户背景相似度的定义如下:
定义2令背景属性向量为Ubg,微博用户背景属性向量表示为Ubg=(year,rage,isV,af,nvf,mbf),博主背景属性向量为Bbg,第i个粉丝的背景属性向量为Fbgi,Simbgi为博主与其第i个粉丝背景的相似度。设向量A(a1,a2,…,an)与向量B(b1,b2,…,bn),则向量A、B的相似度关系为:
(2)
则结合式(2),博主与其第i个粉丝背景相似度表示为:
Simbgi=Cos(Bbg,Fbgi)
(3)
其中背景属性向量Ubg属性变量的定义如下:
定义3令year表示微博用户出生年代的类别集合,记作year{00后,90后,80后,70后,60后},并依次赋予权值{2,4,5,3,1};
定义4令rage表示微博用户的微龄段集合,记作rage{不到1岁,2岁,3岁,4岁,5岁以上},并依次赋予权值{5,4,3,2,1};
定义5令isV表示微博用户是否加V集合,记作isV{是,否},并依次赋值{1,0};
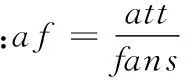
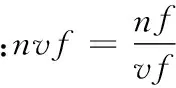
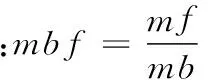
1.3微博用户关系强弱度分析
博主与粉丝之间的互动反映着他们之间的关系强弱,亲密粉丝一般与博主有较强的关系紧密度。因此,用户之间的关系强弱度对粉丝亲密度评价有较大影响。令Rui表示博主与第i个粉丝的关系强度,则博主与第i个粉丝之间的互动率表示为:
(4)
式中,h为博主与第i个粉丝在相同时间段内发的相同条数微博数,Ebi、Pbi、Jbi分别表示博主转发、评论、提及第i个粉丝fi的数量,Efi、Pfi、Jfi分别表示第i个粉丝fi转发、评论、提及博主的数量。
1.4微博用户兴趣相似度分析
高明等人[13]提出基于面向微博系统的实时个性化推荐中推断微博主题分布和用户兴趣取向的研究方法的基础上,本文提出一种分析博主与粉丝的兴趣相似度的研究方法。由于每条微博通常会关联到一个或多个主题,这种特征符合LDA主题模型方法,故本文第一步采用LDA主题模型来分析微博的主题分布。同时,由于用户所发微博能很好地反映用户所关心的主题,本文第二步通过研究用户所发微博的主题分布与其兴趣取向分布的关系,给出博主与粉丝间的兴趣相似度的计算方法。下文为方法的详细介绍。
1.4.1主题分布和兴趣取向定义
定义9令Z={z1,z2,…,zT}为预先给定的T个主题的集合,p(z1|blog),p(z2|blog),…,p(zT|blog)为用户所发某一微博blog的主题分布,p(zi|blog)表示微博blog属于主题zi的后验概率,其数值越大则微博blog属于主题zi的可能性就越大。
定义10令{blog1,blog2,…,blogh}为用户在某一特定时间内发布的h条微博集合,Ou=(ou1,ou2,…,ouT)表示该用户的兴趣取向向量,ouk(k=1,2,…,T)为用户u的第k个兴趣取向,结合定义1可以表示为:
(5)
式中,ouk表示该用户对第k个主题感兴趣的平均概率,blogj表示第j条微博,zk表示第k个主题。
1.4.2微博主题推断
通过新浪微博API采集相关数据作为训练数据集,进行LDA主题模型的学习,得出训练数据集中每条微博的主题分布以及每个单词在T个主题上的分布情况。对于每条微博的主题分布,都可以通过推断该微博中各单词所属主题,来推断该微博的主题分布。具体推断方法如下:
假定由n个单词组成的微博为blog,其单词集合记为{ω1,ω2,…,ωn}。令随机变量cωi表示单词ωi的主题,则对微博blog中单词ωi,cωi=j的概率计算表示为:
(6)
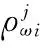
(7)
单词ωi的主题是从分布Xωi=(x1,x2,…,xT)中抽样得到,则微博blog属于第j个主题的概率∂blog,j描述为:
(8)
最后,微博blog的主题分布表示为:
∂blog=(∂blog,1,∂blog,2,…,∂blog,T)
(9)
1.4.3兴趣取向分布
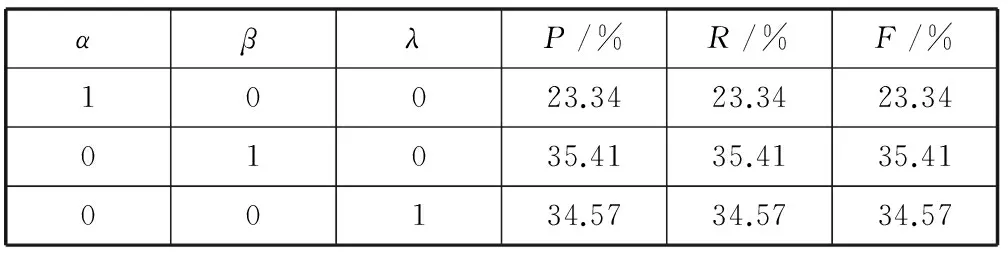
用户的兴趣取向是用一个T维向量Ou=(ou1,ou2,…,ouT)描述的,每一个用户的兴趣取向向量根据数据集中用户微博集而确定。对于每一个用户,选取的h条微博的主题分布可以用一个矩阵表示。令矩阵Gu表示用户的微博集合所产生的主题分布矩阵,选取通过LDA对博主的微博集进行训练得到的主题Z={z1,z2,…,zT}为矩阵的行,选取微博用户发的微博集合Blog={blog1,blog2,…,blogh}为矩阵的列。其中,对于博主,选取某段时间的若干条微博;对于粉丝,选取与博主相同时间段的相同条数的微博。假设某个用户在时间段t内发了x条微博,取其中h(h (10) Ou=(ou1,ou2,…,ouT) (11) 1.4.4兴趣相似度计算 兴趣相似度反映着用户之间的内在共性,粉丝与博主相似度越大,该粉丝就越容易成为亲密粉丝。根据用户的兴趣分布分析,令博主的兴趣分布向量为Ob,粉丝i的兴趣分布向量为Ofi,由式(1)过滤得到博主的活跃粉丝集合为F(b)。令Simbfi表示博主与粉丝i的兴趣相似度,则通过式(2)、式(11)可将博主与粉丝i的兴趣相似度表示为: Simbfi=Cos(Ob,Ofi)i∈F(b) (12) 1.4.5粉丝亲密度综合评价计算方法 王焕玲[14]在《“粉”字心义》中对“微博粉丝”的解释是:在微博里对某一博主保持持续关注的人类群体。当微博的博主在其微博上发表新的留言,第一时间关注他的大多数情况下就会是该微博的粉丝。亲密粉丝是与博主有较高的亲密度的粉丝,主要表现在活跃度高、与博主之间关系紧密、与博主在兴趣上相似度大。则对用户粉丝亲密度的定义如下: 定义11令F表示某一博主的粉丝集合,标记为F={f1,f2,…,fn},由式(1)过滤得到博主的活跃粉丝集合为F(b)。设Qfi表示对博主第i粉丝亲密度评价得分,由式(3)中Simbgi表示博主背景与第i个粉丝背景相似度,式(4)中Rui表示博主与第i个粉丝的关系强度,式(10)中Simbfi表示博主与第i个粉丝兴趣相似度。则结合式(2)、式(3)、式(4)、式(10),博主第i个粉丝的亲密度表示为: Qfi=αSimbgi+βRui+λSimbfii∈F(b) (13) α+β+λ=1 (14) 式中,α、β、λ是对应的权重变量,权重变量由实验数据统计获得,实验部分将详细介绍。通过式(13)计算的Qfi值可以得出对博主第i个粉丝的亲密度评价得分。对博主活跃粉丝集合F(b),用以上计算方法,能得出每一个活跃粉丝综合推荐评分,选取Top-N个活跃粉丝为博主的亲密粉丝。 2.1实验数据 本实验采用用户粉丝亲密度评价模型(BLDA),对微博用户进行亲密粉丝推荐,并将结果与基于协同过滤的用户推荐模型(BPR)[15]和逻辑回归的用户推荐模型(LR)[11]进行效果对比,侧面反映用户粉丝亲密度评价效果。利用新浪微博开放API的方式获取用户基本信息和最新发布一系列微博信息,构成实验数据集。数据集中每个用户基本信息包括用户年龄、微博注册时间(微龄)、是否加V、关注人数、粉丝人数、男粉丝数、女粉丝数、用户发博文次数、粉丝关注所发博文数(对于每篇博文,只要有粉丝有相关的关注行为则记为一次,一条微博只记一次,不重复记)。为了对比BPR和LR推荐模型在对亲密粉丝推荐上的效果,数据集中每个用户的微博信息应包括用户及其关注用户的微博、用户标签、用户社交圈、用户个人信息(地区、性别)。同时为了实验方便进行,本实验要求数据集选取的每个用户关注人数不少于30人,粉丝数在100到2000个之间,且所发微博数不得少于60条。 本实验按照数据集的要求,使用Java语言编写的程序,从新浪开放API接口获取了376个满足条件的用户及其粉丝的个人基本信息以及相关微博信息。将获取的376个用户作为目标用户,并将这376个目标用户对应的亲密粉丝作为待推荐的用户,其亲密度由训练获得。 将获取的微博用户数据集分为训练数据集和测试数据集。训练集由376个目标用户及其对应亲密粉丝组成,测试集由376个目标用户及剔除亲密粉丝后剩余的对应粉丝组成。对于测试集中的每个目标用户,随机选取对应的40个待推荐的粉丝并隐藏其10个亲密粉丝(共50个粉丝)作为测试集。模型训练结束后,对测试数据集进行实验,得到按降序排列的Top-N推荐结果。 2.2实验评价指标 在实验中,采用准确率(P),召回率(R),综合指标(F)作为评价标准。 准确率: (15) 召回率: (16) 综合指标: (17) 其中a表示推荐出来的粉丝为亲密粉丝数,b表示推荐出来的粉丝为非亲密粉丝数,c表示没有推荐出来的亲密粉丝数。 2.3评价权重α、β、λ的调整 表1 评分权重α、β、λ分别取1的实验结果 表2 评分权重α、β、λ调整后的实验结果 2.4实验结果与分析 为验证本文方法的准确性和有效性,实验随机选取5组数据集中的用户,每组10个用户参与实验。对基于协同过滤的用户推荐模型(BPR)和逻辑回归的用户推荐模型(LR)在本文数据集上推荐结果的准确率、召回率和综合指标三个指标进行对比,从而进行亲密粉丝推荐效果的比较。分别取每个用户的Top-1、Top-2、Top-3、Top-4、Top-5、Top-6、Top-7、Top-8、Top-9和Top-10十种情况下的实验结果,即推荐结果的前1个、前2个、前3个、前4个、前5个、前6个、前7个、前8个、前9个和前10个粉丝中,隐藏亲密粉丝占推荐结果的平均比例,实验结果如图2所示。 图2 BLDA、BPR和LP的推荐效果比较 由实验结果容易观察出:BLDA方法模型对用户亲密粉丝推荐的整体准确率要优于LR和BPR方法模型。随着K值的增大,BLDA方法模型的召回率和综合指标值趋于稳定,效果明显优于LR和BPR方法模型。亲密粉丝推荐,关注的是推荐出来的是不是亲密粉丝以及粉丝的亲密度排名,因此准确率、召回率和综合指标的值越大,效果越好。这说明了本文提出的BLDA方法模型对优质粉丝的推荐优于BPR和LR方法模型。 BPR方法模型虽然考虑了用户多维特征间的相似性,并取得了一定的推荐效果,但由于该方法数据稀疏性处理不够,对亲密粉丝推荐并不理想。LR方法模型从用户兴趣、社交圈和个人信息多个角度出发,数据信息比较充分;并通过深层挖掘用户信息中潜在支配推荐排序信息的逻辑回归模型[8],综合利用这些特征进行用户亲密粉丝推荐。该方法在数据稀疏处理方面比较合理,但对用户兴趣的分析是从自身特征研究,缺乏客观性,因此在用户亲密粉丝上的推荐效果不理想。BLDA方法模型更加全面地从博文与用户本身出发,以用户所发博文为根据,利用LDA主题模型分析博文的主题分布,用以反映用户兴趣取向。其对用户兴趣的推断更加客观准确,从而对用户粉丝的亲密度评价更为客观,对亲密粉丝的推荐针对性更强。综合利用这些特征对亲密粉丝的推荐效果有了较大的提高,侧面反映了该用户亲密度评价模型的有效性和准确性。 本文主要从微博用户自身相关特征与博文内容出发,对博文进行深层次挖掘,利用LDA主题模型分析博文的主题分布,反映出兴趣取向分布,融合微博用户的背景特征以及相关行为特征构建了一个综合的用户粉丝亲密度评价模型。实验结果表明,本文所搭建的模型在一定程度上提高了亲密粉丝个性化推荐的准确率、召回率和综合指标。但实验过程中仍存在一些问题:(1) 特征选取不够全面,对用户关系的亲密度评价效果的影响较大;(2) 实验效果跟权值的选定有一定关联。因此,对微博用户背景、活跃度、兴趣的相互关系的深入研究是未来研究的方向。随着新浪微博的发展以及互联网越来越开放,可以获取到更丰富的用户属性,为用户关系更深入的评价分析提供更多的可靠依据。 [1] 傅颖斌,陈羽中.基于链路预测的微博用户关系分析[J].计算机科学,2014,41(2):201-205,244. [2] 闫强,吴联仁,郑兰.微博社区中用户行为特征及其机理研究[J].电子科技大学学报,2013,42(3):328-333. [3] 毛佳昕,刘奕群,张敏,等.基于用户行为的微博用户社会影响力分析[J].计算机学报,2014,37(4):791-800. [4] 曹玖新,吴江林,石伟,等.新浪微博网信息传播分析与预测[J].计算机学报,2014,37(4):779-790. [5]YanagimotoH,YoshiokaM.RelationshipStrengthEstimationforSocialMediaUsingFolksonomyandNetworkAnalysis[C]//2012IEEEInternationalConferenceonFuzzySystems,2012:1-8. [6] 徐志明,李栋,刘挺,等.微博用户的相似性度量及其应用[J].计算机学报,2014,37(1):207-218. [7]KahandaI,NevilleJ.Usingtransactionalinformationtopredietlinkstrengthinonlinesocialnetworks[C]//ProceedingsoftheICWSM’09,SanJose,USA,2009:74-81. [8]XiangRJ,NevilleJ,RogatiM.Modelingrelationshipstrengthinonlinesocialnetworks[C]//ProceedingsoftheWWW2010,Raleigh,NorthCarolina,USA,2010:981-990. [9]ChenJ,GeyerW,DuganC,etal.Makenewfriends,butkeeptheold:Recommendingpeopleonsocialnetworkingsites[C]//ProceedingsoftheSIGCHIConferenceononHumanFactorsinComputingSystems.NewYork:ACM,2009:201-210. [10]HannonJ,BennettM,SmythB.Recommendingtwitteruserstofollowusingcontentandcollaborativefilteringapproaches[C]//ProceedingsoftheACMConferenceonRecommenderSystems.NewYork:ACM,2010:199-206. [11] 徐雅斌,石伟杰.微博用户推荐模型的研究[J].电子科技大学学报,2015,44(2):254-259. [12]YangL,LiC,DingQ,etal.CombiningLexicalandSemanticFeaturesforShortTextClassification[J].ProcediaComputerScience,2013,22:78-86. [13] 高明,金澈清,钱卫宁,等.面向微博系统的实时个性化推荐[J].计算机学报,2014,37(4):963-975. [14] 王焕玲.“粉”字新义[J].现代语文:下旬.语言研究,2012(4):94-95. [15] 胡大伟.基于标签协同过滤算法在微博推荐中的研究[D].包头:内蒙古科技大学,2012. EVALUATIONMODELOFWEIBOUSERFOLLOWERSINTIMACYBASEDONLDA WangQiusen1YuHaoliang1XuHaocheng1FengXupeng2LiuLijun1HuangQingsong1,3* 1(FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500,Yunnan,China)2(EducationalTechnologyandNetworkCenter,KunmingUniversityofScienceandTechnology,Kunming650500,Yunnan,China)3(YunnanKeyLaboratoryofComputerTechnologyApplications,Kunming650500,Yunnan,China) Userrelationshipisapopulardirectionofmicrobloggingresearchnowadays,theevaluationofweibo(microblogginginChina)userfollowers’intimacyisofgreatsignificancetothediscoveryofimplicitusers’intimatefollowersandtheoptimisationofmicrobloggingnetworkenvironment.Currentlytheweibousergroupsarelargeandhavecomplexrelationships,ifevaluatingtheintimacyofusers’relationshiponlystartingfromusersownandbasedonusers’characteristicsandrelationshipnetwork,theaccuracyistoolow.Inordertosolvethisproblem,inthispaperweputforwardtheLDA-basedevaluationmodelofmicroblogginguserfollowersintimacy.Firstitfiltersandweedsoutthoseinactivefollowersinuserfollowerssettoobtainactivefollowers.Then,itusesLDAthememodeltotrainthemicrobloggingarticlesetwrittenduringagivenperiodsoastoacquirethemesdistributionofphasedmicroblogsofusers.Meanwhile,accordingtothemesdistributionsthemodelinferstheinterestsorientationdistributionofmicroblogs,andusescosinesimilaritymethodtocalculatetheinterestsimilaritybetweenusersandtheirfollowers.Finally,combiningthebackgroundsimilarityandrelationshipintimacyofusers,wesetupacomprehensiveintimacyevaluationstandard.ThroughSinaAPIinterfaceswecrawledrecentcorrelatedmicrobloggingdataandformedtheexperimentaldataset,theresultsofevaluation-basedrecommendationexperimentondatasetshowedthattheLDA-basedmodelhashigheraccuracyandeffectiveness. IntimacyLDAFollows(fans)ThememodelSimilarity 2015-06-11。国家自然科学基金项目(81360230);科技部科技型中小企业技术创新基金项目(13C26215305404)。王秋森,硕士生,主研领域:机器学习,自然语言处理。俞浩亮,硕士生。徐浩诚,硕士生。冯旭鹏,硕士。刘利军,讲师。黄青松,教授。 TP ADOI:10.3969/j.issn.1000-386x.2016.10.015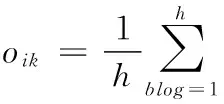
2 实验及分析
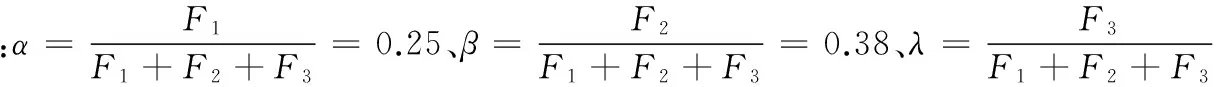

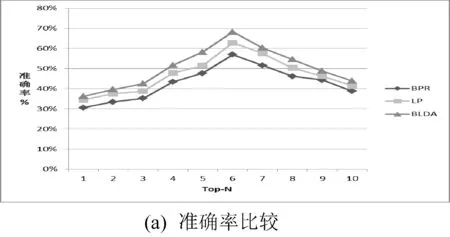

3 结 语
