一种融合词项关联关系和统计信息的短文本建模方法
2016-11-08马慧芳曾宪桃李晓红
马慧芳 曾宪桃 李晓红 贠 宁
(西北师范大学计算机科学与工程学院 甘肃 兰州 730070)
一种融合词项关联关系和统计信息的短文本建模方法
马慧芳曾宪桃李晓红贠宁
(西北师范大学计算机科学与工程学院甘肃 兰州 730070)
传统文本表示方法通常基于词袋模型,而词袋模型是基于文本中词项之间是相互独立的假设。最近也提出一些通过词共现来获取词项之间关系的统计分析方法,却忽略了词项之间的隐含语义。为了解决传统文本表示方法词袋模型对文本语义的忽略问题,提出一种融合词项关联关系和统计信息的短文本建模方法。通过词语之间的内联及外联关系耦合得到词语关联关系,充分挖掘了显示和隐含的语义信息;同时以关联关系作为初始词语相似度,迭代计算词语之间及文本之间的相似度,改善了短文本的表示。实验证明,该方法显著地提高了短文本聚类的性能。
内联关系外联关系词语相似度文本相似度短文本相似度
0 引 言
近年来随着社交网络的兴起,短信、微博等短文本形式的信息量急剧增长。短文本的出现给文本的研究也带来了新的挑战:首先,短文本篇幅短小,往往不能提供足够的统计信息;其次,在社交网络中,缩写词广泛地使用,新单词不断地创建,这也给获取短文本的语义信息带来很大的挑战。传统的文本表示方法词袋模型忽略文本词语间的上下文联系,将文本表示成一个空间向量VSM(VectorSpaceModel)[1],用TF-IDF(词频及逆文档频率)作为其权值,该方法在长文本的研究中取得了不错的效果。但若将此方法简单地运用在短文本上,得到的数据集矩阵往往出现高维稀疏的问题。
为了更多地获取词语间的语义信息,近年来提出了各种改进的方法,主要分为两大类:一类是扩充短文本特征空间,代表性的工作包括基于统计分析挖掘语义信息的上下文向量模型[2,3];还有通过外部知识库来加强短文本语义信息的,如使用Wordnet[4]、维基百科[5]等。这些方法仅仅简单地考虑文本中词语的共现关系,同时还存在外部知识库与文本内容间不匹配的问题,也仍将忽略大量隐含的语义信息。另一类是通过关键词技术来提炼短文本语义信息。有利用很少的词提升短文本分类的方法[6],但是如何获取关键词却是非常困难的。同时,虽然关键词在语义上能精简短文本表示,但从统计学的角度看,关键词技术将短文本短小的特征进一步加剧,同样不利于短文本模型的构建。
为了克服传统文本模型的缺陷,本文在耦合词项关系[7,8]及语义信息和统计分析相结合[9]的启发下,提出一种融合词项关联关系和统计信息的短文本建模方法。具体地,首先利用词语间内联及外联关系计算耦合关系作为初始词语相似度;然后迭代计算词语以及文本之间的相似度,直到其结果收敛为止;最后由词语间相似度构造出相似性矩阵。本文方法不仅通过耦合关系充分挖掘文本词语间的语义信息,同时迭代计算词语之间以及文本之间的相似度,改善了短文本的表示。因此,构造的短文本模型能显著提高短文本聚类的性能。流程如图1所示。
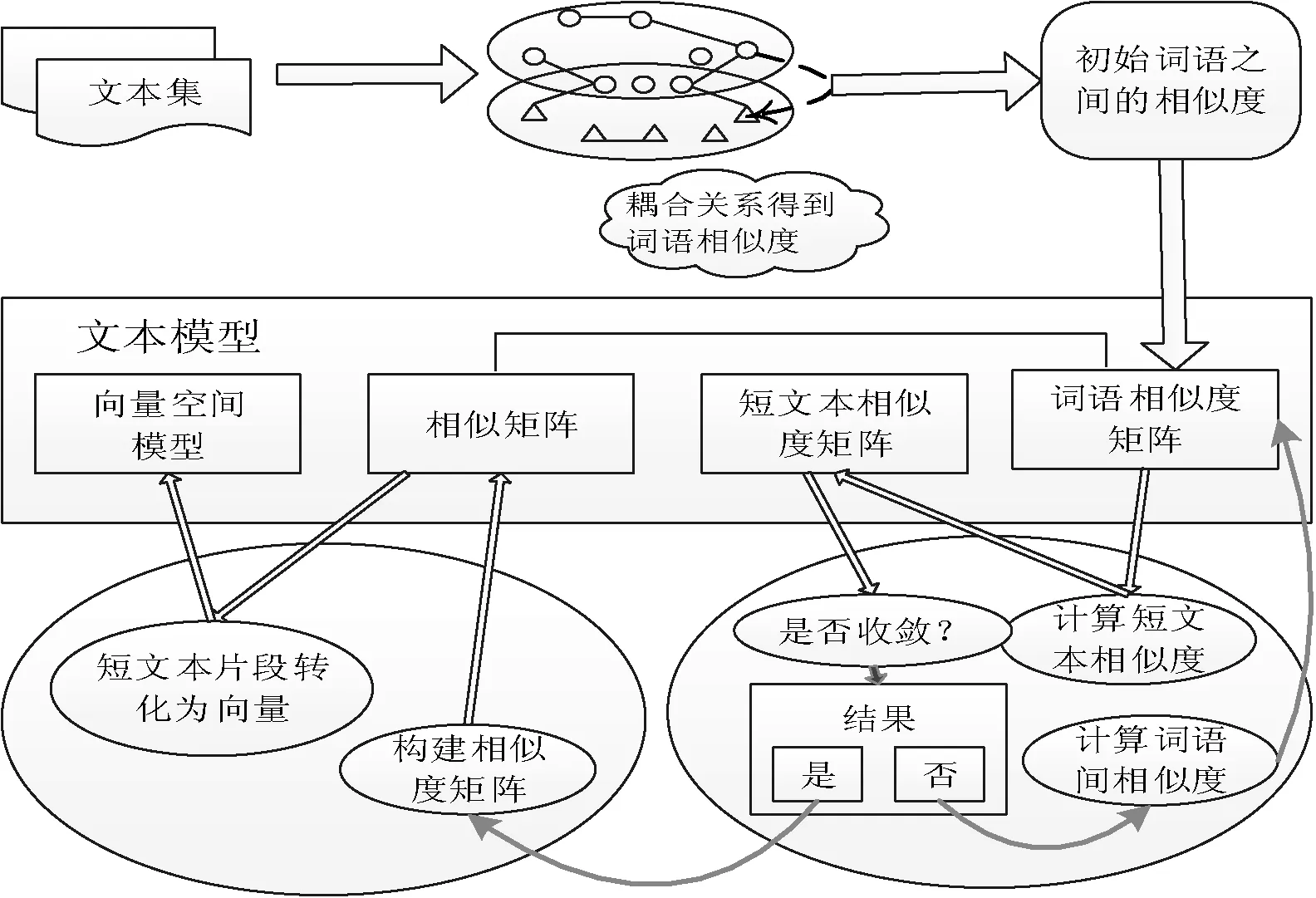
图1 程序流程
1 相关工作
1.1文本表示模型
文本集D通常被表示成D={d1,d2,…,dM},其中di表示文档集中的一个文档,并且每个文档di都被表示成一个空间向量:
(1)
其中:ti是文档集中出现的某个词语,M是文本集D中的文本的总数,N是文本集D中所有不重复出现的单词的总数。TF是词频,它是指单词在给定文档中出现的次数。IDF以出现某个单词的文本数为参数来构建单词的权重,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。公式如下:
(2)
其中:ni表示出现单词ti的文档数目。为了综合考虑词对单篇文档的重要程度及其在整个文档集中的区分能力,通常将TF和IDF综合起来作为空间向量的权值。
文本集D就被表示成一个M×N维的矩阵W。W的行代表文本集D中的文档,列代表文档集中的词项。
1.2关联词信息
传统向量空间模型忽略词语间的上下文关系,但是词语间关系对充分挖掘文本蕴含的内容、扩充文本表示模型具有至关重要的作用。本文将关联词信息定义为两种,如图2所示。

图2 关联词类型
图中分别表示两篇文档,黑色点表示两篇文档中共有的词项,实线框内表示关联词关系的两种模式。左图表示词项在同一篇文档中的关联关系,称之为词语的内联关系;右图表示词项在不同文档中的关联关系,称为词语的外联关系。详细的关联关系定义如下:
定义1(内联关系)若两个词语在同一篇文档中共现,则这两个词语具有内联关系,如图3左部所示。

图3 内联及外联关系示意图
图中词ti和tk在d1中共现,tj和tk在d2中共现,因此ti和tk、tj和tk之间是有内联关系的。根据Jaccard相似度[10]计算得出ti和tk的共现关系:
(3)
其中:ti、tk和tj都是文档集中的某个词项,i、j、k均小于N;W表示文本集D的矩阵,Wxi和Wxk分别代表词ti和tk在文档dx中的TF-IDF的权值。|H|表示集合H={x|(Wxi≠0)∪(Wxk≠0)}中的元素个数,如果集合H为空则CoR(ti,tk)=0。
为了得出实际需要的内联关系,利用条件概率将共现关系规范化到[0,1]之间,公式如下:
(4)

定义2(外联关系)在两篇不同文档中,若d1和d2中的词与共有词中的同一个词共现,则这两个词具有外联关系,如图3右部所示。
图中词ti和词tk在d1中共现,词tj和词tk在d2中共现,通过词tk可以把词ti和词tj关联起来。词ti和词tj通过关联词tk联系的外联关系定义如下:
R_IeR(ti,tj|tk)=min(IaR(ti,tk),IaR(tj,tk))
(5)
其中:IaR(ti,tk)和IaR(tj,tk)分别代表词ti和词tk、词tj和词tk的内联关系。
考虑数据集中所有能将词ti和词tj联系起来的关联词,求得词ti和词tj的最终外联关系并将其规范化到[0,1]之间,公式如下:
(6)
其中:|L|是集合L={tk|(IaR(tk,ti)>0)∩(IaR(tk,tj)>0)}中的元素个数,如果L为空则定义IeR(ti,tj)=0。
2 文本相似度
2.1耦合词项关系
上文中词语间内联关系表征两个词在同一篇文档中的相关性大小,而词语的外联关系挖掘出两个词不在同一篇文档中出现但可能相关的特性。所以,通过综合词语的内外联关系,可以充分挖掘出词语间全部的语义信息,得出耦合词项关系(CR):
(7)
其中:α∈[0,1]是决定内联关系权重的参数,IaR(ti,tj)和IeR(ti,tj)分别代表词ti和词tj的内联和外联关系。
词语间初始相似度矩阵SCR(i,j)=CR(ti,tj),SCR(i,j)的值在0~1之间,0表明两个词之间是完全没有关系的,1表示两个词是完全一样的。SCR(i,j)的值越高,两个词之间的相似度越高。
2.2迭代计算词项之间,文本之间的相似度
基于耦合词项关系得出的词语之间的相似度,对于文档集中的任意两个短文本片段d1和d2的相似度被定义成:
(8)
其中:
sim(wj,wk)=SCR(j,k)
同样地,基于两个短文本片段的相似度,可以重新定义两个词之间的相似度:
(9)
其中:
由上面的计算可以看出,如果两个词在多篇文档中共现或者在相似的文档中出现,则认为它们在概念上很相似。
前面的式(8)、式(9)中,Sjk由词语之间的相似度得到,Tik则由文本片段之间的相似度得到。可以看出,文本之间的相似度和词语之间的相似度是相互依赖并且循环计算的,因此文本之间相似度和词语之间相似度的计算可以通过迭代算法来求解,迭代的函数定义如下:
sim(l)(d1,d2)=(1-λ)sim(l-1)(d1,d2)+
(10)
sim(l)(w1,w2)=(1-λ)sim(l-1)(w1,w2)+
(11)
其中:参数λ是阻尼系数,取值在 0~1之间,l表示第l次迭代计算,式(10)和式(11)中的λ可以取不同的值(在本文的实验中为了简便计算就取了相同的值,都为0.5)。
迭代计算词语及文本相似度直到它们的值收敛。理论上是无法保证式(10)和式(11)是收敛的,因此在实际求解时,每次迭代后都把参数λ的值减少20%以加快迭代速度。
2.3构建相似性矩阵

(12)
(13)

(14)
由于每个词和它本身肯定是相似的,因此上式中加号左边的结果包含的所有元素都是非零的。此外,假设语料库中至少存在两个词是相似的,这就可以保证加号右边的结果是一个非零的矩阵。由于短文本片段中出现的所有词都存在一定的语义相似性,所以文本向量中的元素都是非零的。因此,映射之后,每个短文本的空间向量都将不再那么稀疏。
(15)
其中:dnew是新来文本的空间向量,di是文本库中已经存在的文本向量。
3 实 验
3.1数据集
本部分实验数据采用20个新闻组的共20 000篇短文本片段[11]。由于是网页数据,所以首先对其进行去标签处理,然后去除停用词,最终得到实验可用的数据。依据本文提出的方法对实验数据进行建模,最后使用k-means[12]聚类算法和hardmo-VMF[9]算法对实验数据进行聚类处理。其中k-means算法是聚类中最经典的方法,而hardmo-VMF是文献[9]中使用的一种较为高效的算法,所以本文选取这两种算法进行实验。并且对照原始数据的类别属性分析短文本模型的性能。
3.2评价指标
本文将采用三个指标来评价聚类的性能:纯度(Purity)[13]、F值、归一化互信息NMI(NormalizedmutualInformation)[14]。
(16)
其中:k表示k个聚类。
F值是综合准确率(precision)和召回率(recall)的一个综合评价指标,定义如下:
(17)
其中precision表示所有聚类中正确聚类的比例,recall表示所有相似文本中正确聚类的比例。
NMI是聚类与数据集标签之间互信息和聚类与预先存在类别的熵值的平均值的比值:
(18)
其中C表示聚类的随机变量,L表示数据集中预先存在类的随机变量。I(C;L)是聚类与数据集标签之间互信息:
(19)
H(C)和H(L)分别是C和L的信息熵值:
(20)
|Ci|、|lj|和|Ci|∩|lj|分别是簇Ci和类别lj的数量,以及Ci和lj中共同的文档数。
上面的三个聚类指标的取值都规范化在[0,1]之间,并且可以发现其值都是越高越好。
3.3实验结果及分析
实验比较了关联关系融合迭代计算方法(本文方法)与传统的TF-IDF方法、文献[7]耦合词项关系(关联关系)方法、文献[8]中提出的TSemSim算法和文献[9]中提出的迭代计算的方法。
其中TF-IDF方法是最经典的文本建模方法,忽略了词项之间的语义信息;文献[7]耦合词项考虑词语之间的内外联关系,较充分地挖掘了短文本语义信息;文献[8]在TF-IDF的基础上结合语义信息,并对短文本集进行一定程度的降维处理;文献[9]则是在Wordnet单词网络的基础上求初始词语相似度,再结合统计信息。
如表1和表2所示,是TF-IDF、关联关系、TSemSim算法、迭代计算方法以及本文方法五种不同方法的聚类结果。分别统计出两种不同的聚类算法在纯度、F值、归一化互信息上的实验结果。

表1 k-means聚类算法结果
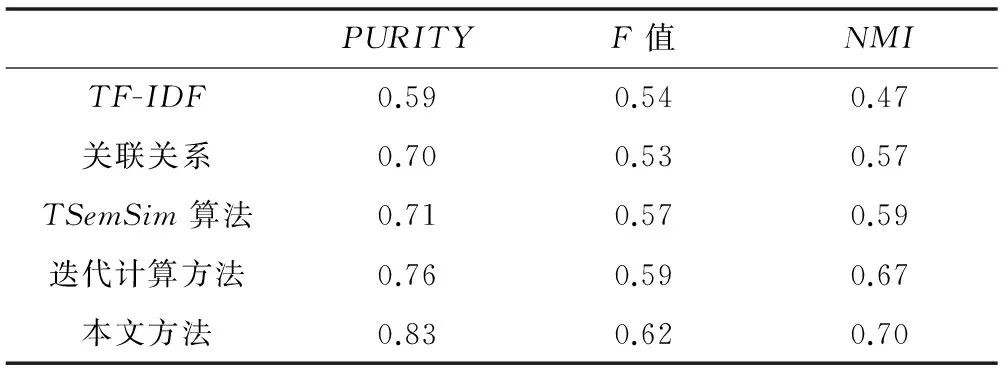
表2 hard mo-VMF聚类算法结果
从表1中可以看出,传统的TF-IDF方法无论是在纯度、F值、还是归一化互信息上的实验结果都明显地低于其他方法。主要的原因在于词频及逆文档频率把文本词语都假定为相互独立的,仅仅简单地考虑词语在文档中出现的频率,此外也没有添加其他任何信息,所以聚类的结果相对较差。接下来是关联关系的方法,它在词袋模型的基础上考虑了文本词语的内外联关系,较充分地挖掘了短文本显示的和隐含的语义信息,所以聚类的性能提升了,但还是要比其他三种方法的性能低。原因在于其他三种方法不仅考虑了短文本的语义信息,还或多或少地结合或者使用统计学的方法。虽然关联关系较词频逆文档的方法已经显示出了一定的优越性,但该方法表示出的短文本仍然还存在文本矩阵高维稀疏的问题。
接下来分析另外三种方法的聚类结果。TSemSim算法和迭代计算方法的结果相近,但总体来说迭代计算的方法要比TSemSim算法的性能稍好一些。这是由于TSemSim算法虽然对文本集进行降维处理,使用了一定的统计学方法,但是迭代计算的方法通过迭代函数使得短文本的特征空间不再稀疏,这对短文本相似度的计算是非常有用的。而本文的方法在性能上要比其他方法都好,这是由于在语义挖掘方面使用词项关系,将短文本的语义信息表示得较充分。同时融合迭代计算的统计信息,改善了短文本的特征空间,优化其表示。这样在计算短文本相似性上能够更加准确,自然地,聚类的性能得到了提高。
表2用hardmo-VMF聚类算法比较各种不同方法的性能。从表中可以看出,虽然各种方法在不同算法下的结果不一样,但是三种不同方法的优劣性是不变的。这也可以看出本文方法在性能上的优势。
总结来说,短文本由于其短小的固有特性,在对短文本的建模处理中,不仅要考虑短文本的语义,更需要使用统计学的方法解决短文本集矩阵高维稀疏的问题。本文提出的融合词项关联关系和统计信息的方法将两者结合得较好,所以相对于其他方法表现出更好的性能。
接下来实验验证了α参数不同取值对本文方法的影响。
如图4所示是参数α取不同值时,本文方法的短文本模型在三个不同聚类指标上的性能变化曲线图。

图4 α取值和本文方法的性能
α参数表征的是词语关联关系中内联关系所占的权重。从图中可以看到,三个不同评价指标的曲线走势差不多都是先随着α的增大而增大,然后随着α的增大而减小。在α的某一个中间取值时会取得峰值。这说明内外联关系的不同权重会对词语间的关联关系产生较大的影响。当α取值为0时,完全忽略了词语的内联关系,而当α取值为1时又完全忽略了词语的外联关系,所以在曲线的两端都表现出短文本模型较差的性能。因此,选取合适的参数α对本文的短文本模型也显得至关重要。
4 结 语
针对短文本研究带来的一些挑战,本文将词项关联关系和统计信息相结合用于短文本建模。方法主要分三步:首先由词项之间的耦合关系求出初始词语相似度,然后迭代计算词语之间及短文本之间的相似度,最后构造相似性矩阵。实验证明,本文的方法在短文本聚类的性能上明显优于其他方法。
同时解决偶然词共现情况对词语内外联关系的影响,以及如何决定内外联关系在词语关联关系中各占的权重可以成为后续工作的研究点。
[1]GuptaV,LehalGS.Asurveyoftextminingtechniquesandapplications[J].JournalofEmergingTechnologiesinWebIntelligence,2009,1(1):60-76.
[2]BillhardtH,BorrajoD,MaojoV.Acontextvectormodelforinformationretrieval[J].JournaloftheAmericanSocietyforInformationScienceandTechnology,2002,53(3):236-249.
[3]KalogeratosA,LikasA.Textdocumentclusteringusingglobaltermcontextvectors[J].KnowledgeandInformationSystems,2012,31(3):455-474.
[4]HothoA,StaabS,StummeG.Wordnetimprovestextdocumentclustering[C]//ProceedingsoftheSemanticWebWorkshopatthe26thAnnualInternationalSpecialInterestGrouponInformationRetrieva(SIGIR)Conference,Toronto,Canada,2003.NewYork:AssociationforComputingMachinery,2003:541-544.
[5]HuJ,FangLJ,CaoY,etal.EnhancingtextclusteringbyleveragingWikipediasemantics[C]//Proceedingsofthe31stAnnualInternationalACMSpecialInterestGrouponInformationRetrieva(ACMSIGIR)ConferenceonResearchandDevelopmentinInformationRetrieval,Singapore,2008.NewYork:AssociationforComputingMachinery,2008:179-186.
[6]AixinSun.ShortTextClassificationUsingVeryFewWords[C]//Proceedingsofthe35thAnnualInternationalACMSpecialInterestGrouponInformationRetrieva(ACMSIGIR)ConferenceonResearchandDevelopmentinInformationRetrieval,Portland,Oregon,USA,2012.NewYork:AssociationforComputingMachinery,2012:1145-1146.
[7]ChengX,MiaoDQ,WangC,etal.CoupledTerm-TermRelationAnalysisforDocumentClustering[C]//Proceedingsofthe2013InternationalJointConferenceonNeuralNetworks,Dallas,TXUSA,2013:1-8.
[8] 黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864.
[9]LiuWY,QuanXJ,FengM,etal.Ashorttextmodelingmethodcombiningsemanticandstatisticalinformation[J].InformationSciences,2010,180(20):4031-4041.
[10]BollegalaD,MatsuoY,IshizukaM.Measuringsemanticsimilaritybetweenwordsusingwebsearchengines[C]//Proceedingsofthe16thInternationalConferenceonWorldWideWeb(WWW2007),Banff,Canada.NewYork:ACM,2007:757-766.
[11]LangK.Newsweeder,Learningtofilternetnews[C]//ProceedingsoftheTwelfthInternationalConferenceonMachineLearning,TahoeCity,California,USA.USA:MorganKaufmann,1995:331-339.
[12]MacQueenJ.Somemethodsforclusteringandanalysisofmultivariateobservations[C]//ProceedingsofthefifthBerkeleySymposiumonMathematicalStatisticsandProbability,1967.Berkeley:UniversityofCaliforniaPress,1967,1:281-297.
[13]ZhaoY,KarypisG.Criterionfunctionsfordocumentclustering:Experimentsandanalysis[R].TechnicalreportUniversityofMinnesota,2001.
[14]AlexanderStrehl,JoydeepGhosh.Clusterensemblesaknowledgereuseframeworkforcombiningmultiplepartitions[J].JournalofMachineLearningResearch,2003,3(3):583-617.
ASHORTTEXTMODELLINGMETHODFUSINGCORRELATIONOFLEXICALITEMSANDSTATISTICINFORMATION
MaHuifangZengXiantaoLiXiaohongYunNing
(CollegeofComputerScienceandEngineering,NorthwestNormalUniversity,Lanzhou730070,Gangsu,China)
Traditionaltextrepresentationmethodsareusuallybasedonthemodelofbagofwords,whilethismodelisbasedontheassumptionthatthelexicalitemsareindependenteachotherinthetext.Recentlythestatisticalanalysismethodsarealsopresentedwhichobtaintherelationsbetweenlexicalitemsbywordco-occurrences,butignoretheimpliedsemanticsbetweenlexicalitems.Inordertoovercometheneglectingproblemofthebagofwordsmodeloftraditionaltextrepresentationmethodsontextsemantics,thispaperpresentsashorttextsmodellingmethodwhichfusesthelexicalitemscorrelationandthestatisticsinformation.Itobtainstermscorrelationthroughcouplingtheintra-relationandinter-relationbetweenterms,whichfullyinvestigatestheexplicitandimpliedsemanticinformation;meanwhileitemploysthecorrelationastheinitialtermssimilarity,anditerativelycalculatesthesimilaritiesbetweentermsandtexts,thusimprovestherepresentationoftheshorttext.Experimentsshowthatthismethodsignificantlyimprovestheperformanceofshorttextclustering.
Intra-relationInter-relationTermsimilarityTextsimilarityShorttextsimilarity
2015-05-18。国家自然科学基金项目(61363058,6116 3039);甘肃省自然科学基金青年科技基金项目(145RJZA232);中国科学院计算技术研究所智能信息处理重点实验室开放基金项目(IIP2014-4)。马慧芳,副教授,主研领域:人工智能,数据挖掘与机器学习。曾宪桃,本科生。李晓红,讲师。贠宁,本科生。
TP
ADOI:10.3969/j.issn.1000-386x.2016.10.007
