AlphaGo技术原理分析及人工智能军事应用展望
2016-11-02陶九阳吴琳胡晓峰
陶九阳 吴琳 胡晓峰
1.国防大学信息作战与指挥训练教研部北京100091 2.解放军理工大学指挥信息系统学院江苏南京210007
围棋被誉为人类最后的智慧高地,一直是检验人工智能发展水平的重要标志之一.围棋复杂的盘面局势评估和巨大的状态搜索空间,成为学者们面临的巨大障碍.仅仅依赖常规的知识推理和启发式搜索[1]策略,会有极高的计算复杂度.2016年AlphaGo[2]围棋人工智能的突破,反映出最近兴起的深度学习等人工智能技术解决围棋这类完美信息博弈问题的优异性能.以深度学习为代表的人工智能技术的快速发展,使得人工智能逐渐具备了分层抽象及知识表达的自动化,极大降低了搜索的复杂度,为人工智能解决围棋问题提供了关键技术基础.
AlphaGo是谷歌公司旗下DeepMind公司研发的围棋人工智能程序.其分布式版本构建于1920个CPU和280个GPU之上,它综合运用了深度学习和蒙特卡洛树搜索算法,2015年以5:0完胜欧洲围棋冠军、职业二段选手樊麾[2],2016年又以4:1战胜世界围棋冠军李世石.从技术上看,AlphaGo与1997年轰动一时的国际象棋“深蓝”具有本质的不同.“深蓝”依赖计算能力对所有状态空间进行穷尽式暴力搜索,是用确定性算法求解复杂问题,体现的是一种“机器思维”.而AlphaGo依靠深度学习的方法,建模了人类的“直觉”棋感和大局观,通过增强学习的方法,拥有了自主学习、自我进化的能力.它运用蒙特卡洛树搜索随机算法将深度神经网络进行融合,最终具备了在“直觉”基础上的“深思熟虑”,而这正是一种典型的“人类思维”处理复杂问题的方式.这为解决复杂决策智能的问题提供了一种工程技术框架[3].
以AlphaGo为代表和标志的技术突破,预示着一种具有直觉、认知和自我进化能力的新的人工智能时代的到来,也预示着智能化战争时代可能即将到来.这不仅给工业界带来巨大的震动,也为人工智能的军事应用打开了进入快车道的大门.对AlphaGo技术原理进行深入剖析,研究其智能化方法框架,预见人工智能技术的军事应用,可以为解决复杂战争问题,储备必要的理论与技术基础并指明方向.
1 AlphaGo技术原理分析
1.1 “深蓝”工作原理
1997年战胜国际象棋大师卡斯帕罗夫的“深蓝”,主要技术原理是运用局势评估函数和α−β剪枝搜索算法对象棋的状态空间进行穷举搜索[4].“深蓝”根据棋盘上的状态来评估当前的局势,其盘面状态s(t)由每个棋子的重要程度、所处位置、可以影响的范围、王的安全系数、先手/后手等变量组成,对当前盘面状态s(t)进行评估的函数的定义为局势评估函数v:s(t)→R,局势评估函数值表示对当前状态形势好坏的一个判断.利用局势评估函数和当前所处的状态,“深蓝”可以建立一棵博弈树,如图1所示,博弈树[5]的节点表示博弈一方所处的状态1部分参考书中将博弈树的结点定义为结(node),表示的是采取行动的时点.,博弈树的边表示可采取的策略,节点的特征值取值为博弈一方的局势评估函数值.博弈树自根节点向叶节点移动推进的过程,描述了博弈双方交替选择策略(行动)并获得相应收益的过程.“深蓝”运用α−β剪枝算法,通过对博弈树上策略(行动)的搜索来寻找最优策略.
α剪枝和β剪枝互为对偶问题,这里以α剪枝为例说明其基本原理:假设“深蓝”当前处于博弈树的A点,那么深蓝希望得到的是A点的最大局势值.象棋是一个零和博弈,一方赢另一方必然输.图1中,下一步卡斯帕罗夫将会进入B点或者C点.深蓝为了获得保底的收益,由此,需要采用“极小化极大策略”,即在最小的B和C里面找一个最大的.于是可以得到选择判断用的公式(1):
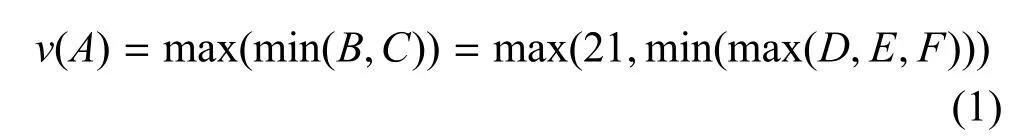
由于在C节点作极小化极大运算有min(max(D,E,F)≤15,而对B节点作极小化极大运算所得结果等于21,所以在A节点处有v(A)=max(min(B,C))=v(B)=21.此时不需要计算C的局势值也可知道A的局势值,相当于可以将博弈树的C枝剪掉.
通过上面的步骤可以看到,“深蓝”所使用的α−β剪枝搜索算法是一种最大化最小搜索算法,是一种非常保守的搜索策略.这种策略的优势是非常稳健,这可能是“深蓝”和卡斯帕罗夫的对弈中出现平局较多的主要原因.α−β剪枝搜索算法是对最大化最小基本搜索的一种改进,它的算法效率高低与节点的排列顺序高度相关.
1.2 AlphaGo建模原理和基本组成
“深蓝”在国际象棋中所采用的技术并不能直接复制到围棋领域,原因在于围棋的状态空间比象棋大得多.无论是围棋还是象棋,人工智能落子的选择主要依赖于对状态空间的搜索,象棋每一步搜索的宽度大概是30,搜索的深度大概是80,整个搜索空间大约为1050.而围棋搜索的宽度大概是250,深度大概150,搜索空间在10170以上.由于搜索空间太大,计算机难以处理,只依赖评估函数和α−β剪枝搜索算法无法在有限的时间穷尽所有状态,因此,难以使用.
观察可知,人类棋手并不像“深蓝”那样对全部策略空间进行暴力搜索,而是先通过宏观的“势”,或者是所谓的“棋感”选出几个感觉上比较好的落子方案,再对每个方案进行“深思熟虑”的多步推演,然后比较得出最好的落子位置.人类棋手凭经验和“直觉”确定候选方案,是在降低搜索的“宽度”,一些明显不好的落子方案不再进行深入的搜索.人类棋手的“深思熟虑”也不是推演到棋局的最后一步,往往是推演几步最多十几步后就对盘面进行综合评估判断局势好坏.这种综合评估,降低了搜索的“深度”.对于人类棋手而言,无论是落子“直觉”还是盘面综合评估,主要依赖棋手的经验来选点,推演只是辅助手段.AlphaGo充分借鉴了人类棋手的下棋模式,用策略网络(Policy network)来模拟人类的“棋感”,用价值网络(Value network)来模拟人类对盘面的综合评估,同时,运用蒙特卡洛树搜索将策略网络和价值网络融合起来,来模拟人类棋手“深思熟虑”的搜索过程.

图1 α−β剪枝算法示意图
AlphaGo由策略网络(Policy network)和价值网络(Value network)组成[2],如图2所示.策略网络又分为有监督学习策略网络(SL policy network)、快速走子策略(Rollout policy)和增强学习策略网络(RL policy network).

图2 AlphaGo神经网络的训练
1.3 AlphaGo策略网络和价值网络
有监督学习策略网络ρσ是一个13层的卷积神经网络[6−8],其主要功能是:输入当前的盘面特征参数,输出下一步的落子行动的概率分布p(a|s),判断预测下一步落子位置,如图2策略网络所示.ρσ首先将围棋盘面状态s抽象为19×19的网格图像,再人工抽取出48个盘面特征作为图像的通道.ρσ的输入就是19×19×48的图像.ρσ训练样本采用3千万个人类围棋棋手产生的盘面数据(s,a),用随机梯度下降算法[9]进行训练调优.其中,ρσ的每个卷积层有192个卷积核,共包含约40万个神经元.网络最后加了一个softmax层,能够将标签映射为每个位置走子概率的概率分布p(a|s),∑ap(a|s)=1,其中s为当前盘面,a表示下一步的行动,p(a|s)表示在当前盘面s下,下一步采用行动a(或者叫在a处落子)的概率值.ρσ在使用中选择概率值最大的a作为下一步采取的策略(行动).如果单纯用ρσ,可以实现在测试集上以57%的准确率预测围棋大师下一步的落子位置.AlphaGo平均走子速度为3ms.
快速走子ρπ是一个线性模型,其主要功能与ρσ完全相同.模型的输入是人工抽取的当前盘面的十几万个特征模式(Feature of patterns),输出是下一步的落子行动的概率分布p(a|s).快速走子可以看成是一个两层的神经网络,输入层是十几万的特征模式,输出层是通过softmax函数将输入映射为一个概率分布:softmax:parterns→p(a|s).如果单纯用快速走子,能够在测试集上以24.2%的准确率预测围棋大师下一步的着法.平均走子速度为2µs.这比ρσ快1000多倍.
增强学习策略网络ρρ是通过增强学习(Reinforcement learning)[10−11]的方法对 ρσ加强.ρρ的网络结构和功能与有监督学习策略网络ρσ完全相同,性能上强化了学习.其增强学习的主要过程是:首先取 ρσ为第一代版本 ρσ1,让 ρσ1与 ρσ1自对弈N局,产生出N个新的棋谱,再用新的棋谱训练ρσ1产生第二代版本 ρσ2,再让 ρσ2与 ρσ1自对弈N局,训练产生第三代版本ρσ3,第i代版本随机选取前面的版本进行自对弈,如此迭代训练n次后得到第n代版本ρσn=ρρ,这就产生了增强学习的策略网络ρρ.AlphaGo增强学习自对弈共进行了3000万局.用训练过的ρρ与Pachi围棋软件对战能取得85%的胜率,而若用训练过的ρσ与Pachi围棋软件弈棋仅仅能取得11%的胜率.Pachi使用了蒙特卡洛树搜索算法,是一个开源的围棋弈棋程序.
价值网络νθ是一个13层的卷积神经网络,与策略网络具有相同的结构.主要功能是:输入当前的盘面参数,输出下一步在棋盘某处落子时的估值,以此评价走子的优劣.νθ利用人类棋手的16万局对弈所拆分出的3000万盘局面来训练,用测试集测试有0.37的均方误差,而在训练集上只有0.19的均方误差,显然发生了过拟合.究其原因主要是3000万盘面之间具有相关性.为了克服相关性带来的过拟合,νθ从增强学习策略网络ρρ产生的3000万局对弈中抽取样本,每一局中抽取一个盘面从而组成3000万不相关的盘面作为训练样本.最终在训练集上获得0.226的均方误差而在测试集上获得0.234的均方误差.

图3 AlphaGo蒙特卡洛树搜索算法
1.4 AlphaGo蒙特卡洛树搜索算法
AlphaGo策略网络和价值网络的主要作用是降低博弈树的搜索宽度和搜索深度,通过剪枝来控制搜索空间的规模.但是要作出合适的决策,不仅需要依赖于搜索空间的降低,还需要采用合适的搜索算法.AlphaGo运用蒙特卡洛树搜索(Monte Carlo tree search,MCTS[12−13])算法来实现对博弈树的搜索.MCTS算法的原理是:先随机走子,然后再通过最终的输赢来更新原先那些走子的价值.设定随机走子的概率,与先前计算出的走子价值成正比.如此进行大量的随机模拟,让好的方案自动涌现出来.AlphaGo中MCTS算法的工作原理如图3所示[2]:
图3(a)中,当处于“选择”阶段时,在当前的盘面下,下一步要选择Q+U(P)最大的分支走子.Q表示走子价值,价值越大越应该往该分支走.仿真开始时,设置每个分支上的价值都相同,初始假设为0,蒙特卡洛树搜索算法通过不断地模拟来更新搜索树每一个分支上的Q值,让Q值大的分支涌现出来,而U(P)表示每条分支上的先验知识,U(P)∝P(s,a)/(1+N(s,a)),其中P(s,a)= ρσ(s,a),是在当前盘面下,通过策略网络产生的每个分支上的先验知识,N(s,a)表示蒙特卡洛仿真搜索分支(s,a)的次数,它与U(P)成反比,以此来鼓励探索新的分支,避免随着搜索次数的增加算法过快停止搜索而产生过大误差.在图3(b)的“扩展”阶段,MCTS树搜索算法首先用策略网络ρσ走L步(实际L取值为20),走到搜索树盘面SL的节点.因为搜索树有很多分支,所以SL是一个节点集合.用估值网络νθ为每个SL进行估值得到νθ(sL).此时整个模拟并有结束,为了加快搜索速度,用快速走子模型ρπ以每个SL节点为起点走到底,在进入图3(c)所示的“估值”阶段,根据最终的输赢情况给出评价值zL=r.最后对整个搜索进行回退更新Q值,进入图3(d)所示的“回退”阶段.这一阶段,首先是根据ρπ评价值r和估值网络νθ评价值νθ(sL)来计算sL的综合值ν(sL):
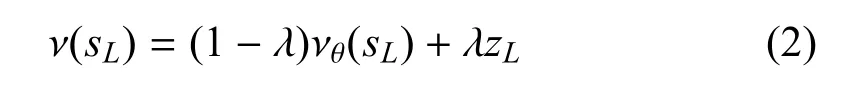
式(2)中,λ为常数,实验检验发现取值0.5时效果最好.ν(sL)是 νθ(sL)与zL的加权平均.然后,用ν(sL)值更新Q值:
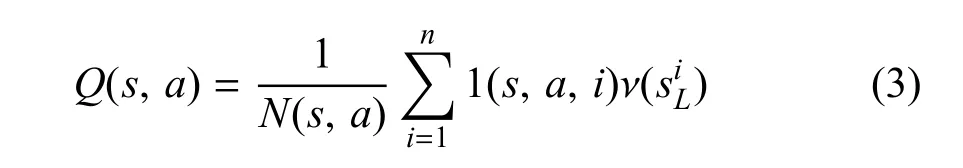
式(3)中,1(s,a,i)为布尔函数用来将遍历到的分支选择出来,如果第i次模拟遍历到(s,a)分支则函数值为1,否则函数值为0.式(3)表示蒙特卡洛模拟了n次后的分支(s,a)的Q值.最终,第t步选择的策略at由式(4)来计算:
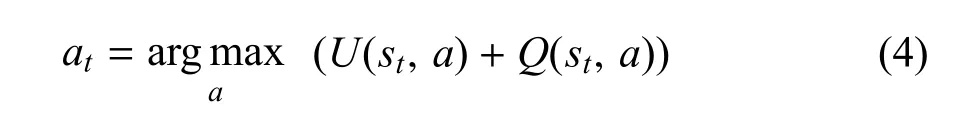
式(4)表明,at由两部分组成,一部分来自策略网络的值U(st,a),另一部分来自蒙特卡洛树搜索的Q(st,a).前者建模了人类的“棋感”,后者建模了人类在“棋感”基础上的“深思熟虑”.因此,可以说AlphaGo通过蒙特卡洛树搜索综合了策略网络的“棋感”和价值网络的“深思熟虑”,具有典型的人类思维的特征.
2 人工智能军事应用展望
一般来说,按照作战活动的不同,可以将战争空间划分为物理域、信息域、认知域和社会域4个交叠构成的具有跨域特性的作战域[14−15].随着机器学习和人工智能的快速发展,以谷歌AlphaGo、微软智能图像识别、IBM沃森等为代表的人工智能技术必然会应用于战争空间的各作战域.美国国防部高级研究计划局(Defense Advanced Research Projects Agency,DARPA)作为美国先进科技的引领者,在人工智能领域正在和计划开展大量研究项目.表1列出了人工智能技术在各个作战域中的可能应用情况以及DARPA开展项目的情况2本文列出的相关项目和计划主要是从DARPA官方网站公布的近年项目资助预算书等资料中获得,网址为:http://www.darpa.mil/.其他军方研究机构也有大量人工智能领域相关研究正在进行,本文未一一列出..
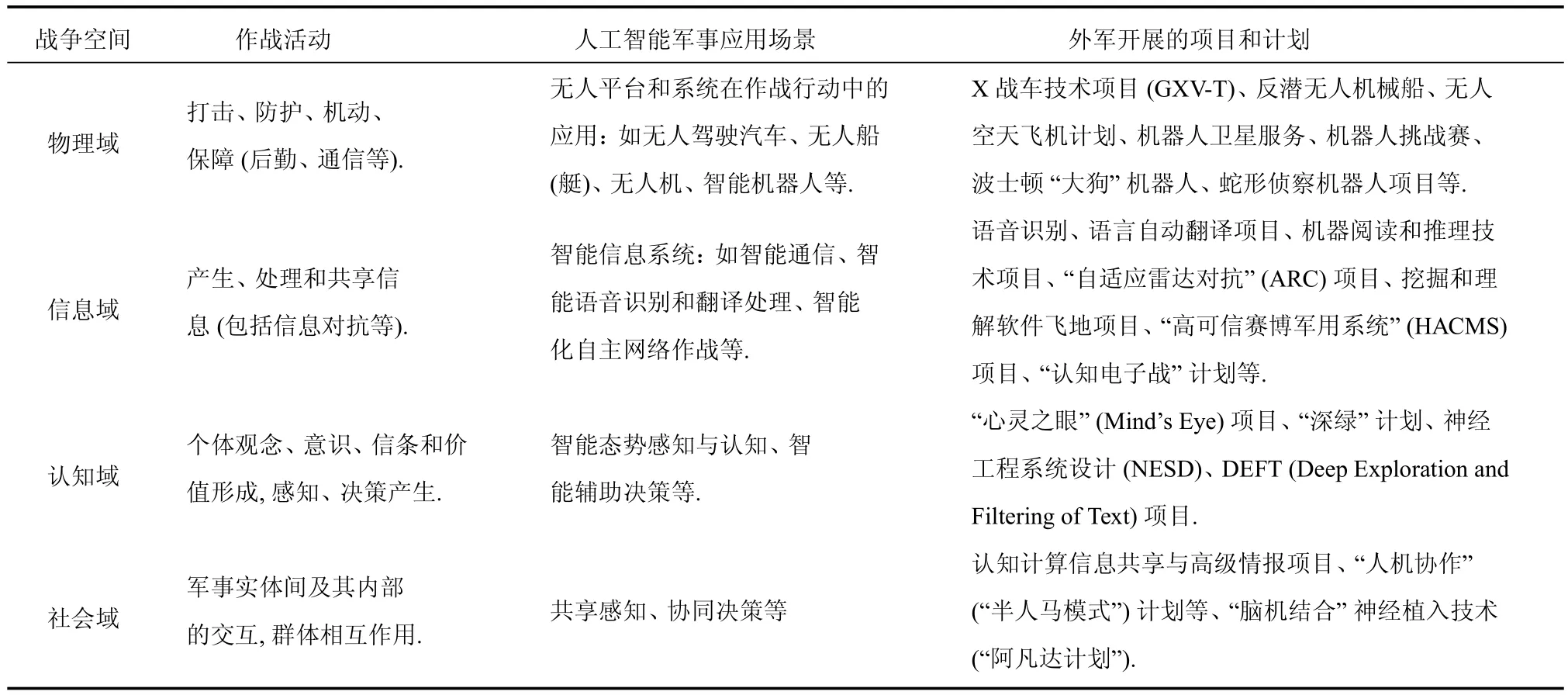
表1 人工智能技术在4个作战域的应用展望
物理域是各种军事力量进行交战、打击、防护和机动的作战域.人工智能技术在该域的应用,必然导致大量智能化无人作战平台的出现,如智能作战机器人、无人驾驶汽车、无人船、无人机等.这些智能化的无人作战平台与当前的无人系统将具有本质性的区别,是一类具有思考决策能力的系统,而不是简单地应对大致有限的既定环境.这必然导致打击、机动和防护能力的全面提升.如DARPA正在研发的X战车(GXV-T),依赖先进的人工智能技术具备更快行驶速度,超强侦察外部环境躲避敌方侦察的能力.
信息域是信息化战争对抗发生的主战场,是信息产生、处理、共享与对抗发生的领域.长期以来,由于信息的处理共享等环节需要大量的人工操作,例如战场侦察卫星传回的图像、无人机侦察图像、各类人员语音信息等非结构化数据需要人工判读,这直接导致信息的处理速度和利用效率极低,甚至可能使指挥员淹没在“信息洪流”中.微软的ImageNet图像识别理解、科大讯飞的语音识别等人工智能技术的发展,使智能化处理非结构化战场数据越来越接近实战要求,由此正在催生各类传感器、数据处理器以及信息网络的全面智能化,使得信息收集的范围更为广泛,信息处理的速度更快质量更好.另外,信息域中的网电对抗,借助于人工智能技术将能够实现自主敏捷反应,如DARPA资助的“认知电子战”计划使用最新的人工智能和机器学习方法,能够自主识别对手的信号频谱并作出反应.
认知域和社会域是感知、认知和决策产生的作战域,智能态势感知理解和自主决策是目前人工智能亟待解决的领域,是通向真正意义的智能化战争的关键一环.由于战场环境具有高度的复杂性和不确定性,长期以来,态势理解及预测等认知活动机器智能还无法胜任,主要依赖人工完成.现代化战争复杂程度越来越高,陆、海、空、天、电、网各维度态势相互铰链,单纯依赖人工对态势图判读来理解和预测态势将会变得越来越困难.另外,由于战争内在的复杂性,对手行为的高度不确定性,长期以来,辅助决策功能一直饱受诟病.为了解决这一问题,DARPA从2008年开始支持“深绿”计划,试图研究一种能够嵌入美军C4ISR系统的先进辅助决策模块.“水晶球”和“闪电战”是两大核心模块.水晶球负责生成和更新未来作战可能的各个分支,即绘制和更新战争的博弈树,而闪电战模块用来对每个分支进行模拟并给出交战结果,即完成对博弈树的剪枝和搜索,这与AlphaGo采用的方法极为类似.因此,AlphaGo的成功极有可能带来这类智能军事决策的突破,这也是AlphaGo技术最有借鉴意义之所在.在社会域上,共享感知和协同决策是实现联合作战行动的基础,是整合其他各作战域智能作战力量形成作战体系的关键所在.DARPA正在大力发展的“人机协作”(“半人马模式”)等计划,其目标就是实现将人与机深度融合为共生的有机整体,让机器的精准和人类的可塑性完美结合,利用机器的速度让人类做出最佳判断,以协助人类提升认知速度和精度,快速作出决策并指挥无人系统协同行动.
3 人工智能对OODA循环的颠覆性影响分析
人工智能应用于战争领域,必将带来一次新的军事革命.美军2014年提出的“第三次抵消战略”,就是以人工智能技术为核心,综合生物、信息、空间、网电等技术领域发展能够“改变未来战局”的颠覆性技术群,来形成相较于对手的绝对军事优势.分析人工智能对作战活动的影响可以发现,其最主要的优势:一是增强作战行动的敏捷性,二是提高作战行动的力量.
通常,作战过程可以由OODA循环来描述,人工智能在物理域、信息域、认知域和社会域的运用,能够显著影响交战各方的OODA循环来改变战争的进程.OODA循环理论认为作战过程是“观察、判断、决策、行动”的不断循环、往复过程[16].战争的作战双方是一种对抗行为,其各自的OODA循环过程都受对手的作战行动的影响.战争双方的OODA环就像两个耦合在一起的“齿轮”,如图4所示.
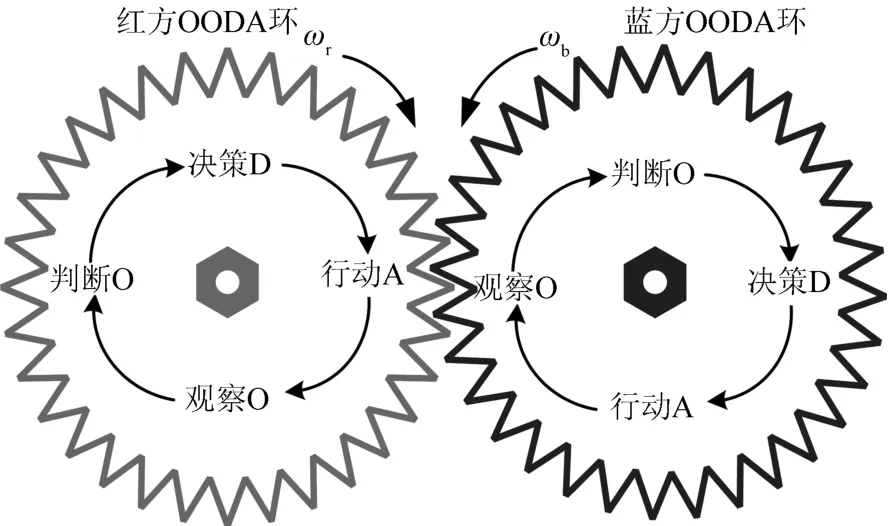
图4 红蓝双方相互耦合的OODA环示意图
战争规律告诉我们,掌握战争主动权往往能够赢得战争胜利,被动就会处于不利地位.所以战争可以看成是冲突双方较量谁能更快更好地完成OODA循环的过程,是争夺“主动轮”位置的过程.在这个耦合的OODA“齿轮”系统中,“主动轮”的位置通常由两个因素决定,一个是“齿轮”的转速,即OODA循环完成的速度,另一个是“齿轮”的转动力量,即OODA完成的质量,如打击效果等.通过前面分析可以看出,一方面,认知人工智能的进步和应用会大大提高感知和决策的质量和速度(如美军大力发展的“深绿”计划),使得OODA循环的每一个环节都会加速,从而使“齿轮”转速提高而产生敏捷性优势[17];另一方面,无人作战力量(如机器人、无人机等)自身所具有的速度和力量,会提高打击行动的精度、力量和强度(如超高速智能无人机能够更快更精准地实施打击),无人和有人系统的有机融合也会大大提升作战效能,使得OODA的行动(A)环节更有力,能够克服更大的战争阻力.一旦一方OODA循环的速度大大快于对手,就会使对方无法跟上战争节奏而导致系统崩溃.例如在交战过程中OODA循环显著慢的一方可能陷入反复的“观察(O)”、“判断(O)”或机械的跟随“行动(A)”过程中,而不能完成完整的OODA循环,被对方牵着走,从而失去战争主动权.另外,一方打击力量远远弱于对手,即使OODA循环的速度再快,也难以调动对手跟随,只有OODA环的力量足够强大才能带动整个战争系统按照自己的节奏运行,掌握战争主动权.
4 结论
本文分析了AlphaGo的技术原理,并展望了人工智能在军事领域的应用.虽然AlphaGo在围棋人工智能方面取得了突破性进展,但围棋毕竟是一种完美信息博弈,而战争是不完美信息博弈,其状态空间规模和复杂性都远远超过围棋.因此,应该看到人工智能在复杂军事领域中的应用尚处于起步阶段,前路依然充满挑战.我们认为,战场态势感知智能化是首先需要解决的一个挑战,是解决其他复杂军事问题的起点.因此,借鉴AlphaGo的技术原理和实现框架,研究面向战场态势感知理解和自主决策的战场态势特征提取方法和深度神经网络的构建方式,获取、组织和运用态势数据来训练智能感知深度神经网络,是目前亟需开展的工作.
