命名数据网络中基于多级计数Bloom过滤器的名字查找方法研究
2016-11-01吴婷婷
侯 睿,吴婷婷
(中南民族大学 计算机科学学院,武汉 430074)
命名数据网络中基于多级计数Bloom过滤器的名字查找方法研究
侯睿,吴婷婷*
(中南民族大学 计算机科学学院,武汉 430074)
针对目前NDN中大多数基于Bloom过滤器的名字查找方法仅考虑速率而忽略冲突概率的局限,提出了一种考虑名字冲突概率并基于多级计数Bloom过滤器的名字查找方法.该方法的实验结果表明:相对于目前广泛研究的计数Bloom过滤器、哈希函数和d-left计数Bloom过滤器,所提方法能有效降低冲突概率.
Bloom过滤器;名字查找;命名数据网络;最长匹配前缀
随着互联网信息量的爆炸式增长,用户逐渐趋向于关注信息的内容而不是其所处的地理位置.信息中心网络(ICN)[1-2]以其通过信息内容查找数据的方式受到世界各国研究者的关注,并被认为是下一代计算机网络体系结构的典型代表,命名数据网络(NDN)[3-4]是ICN的一种有效实现方式,目前得到广泛研究.
NDN通过层次化命名方式,将数据名字分级标识,类似于目前的统一资源定位符 (URL) 命名方案[5].针对NDN网络架构中固定长度的前缀查找方法已有很多,文献[6]中将NDN的名字不作层次化命名,看作扁平化命名,利用名字组件树进行查找.该方案降低了查找树的深度,相对地加快了查找速度.但若使用该方法,不利于速度的提升;文献[7]提出一种平行于NDN架构的平行名字查询(PNL)方案,该方案利用硬件并行加速了查找的过程,同时保持较低的内存冗余和计算复杂度,然而该方案的内存开销较大;文献[8]提出一种名字组件编码(NCE)方案.此方案采用代码分配机制和状态转换阵列两个核心思想,与名字组件树方法相比有效加快了其查找速率,但其代码分配机制产生的冲突概率较大,且其运行平台的设计成本较大;文献[9]提出一种名字滤波器方案,通过应用两个阶段的计数Bloom过滤器(CBF)有效地将哈希计算和内存访问的次数从kN次减少到k次,因此相对地提高了查找速度.但依旧没有解决由于哈希函数的冲突,导致CBF的效率受到冲突率的影响;此外文献[10]提出一种新型Bloom过滤器方案d-left哈希函数的Bloom Filters(DLCBF),在负载率的平衡性上进行了一定程度的改进.
以上的研究仅关注查找速度而忽略了冲突概率,本文提出一种基于多级计数Bloom过滤器(MLCBF)的名字查找方法,有效地降低了查找过程中名字的冲突概率.
1 最长匹配前缀的查找
NDN中是以最长匹配前缀原则实现名字匹配,如请求包的名字为K/X/Y/Z,此时路由表中包含K/X/Y/Z和K/X/Y,那么按照最长匹配前缀原则与K/X/Y/Z匹配.在本文中,名字前缀根据其长度分别映射进不同长度的Bloom过滤器中,通过查询Bloom过滤器,名字的最长匹配前缀被确定.这个阶段采用的是One Memory Access Bloom Filters[11]使得一次查询中内存访问的次数从k次(k是每个Bloom过滤器中hash函数的个数)减到1次,其主要思想是把k个hash函数的结果映射为一段字符串,提高了基于散列的字符串性能,加快了Bloom过滤器在第一阶段的操作.第一阶段Bloom过滤器的映射流程结构如图1所示.

图1 One Memory Access Bloom Filters映射流程图Fig.1 The mapping flow chart of One Memory Access Bloom Filters
当请求包需要被查询的名字为/wuhan/scuec/2015/.../时,依次将各层次的名字按照长度映射进Bloom过滤器中,此方案会先从最长长度的过滤器中查找,若没找到,则向相邻且长度较小的过滤器中查找,直到找到输出最长匹配前缀为止.
2 多级计数Bloom过滤器
MLCBF是采用哈希函数映射并且结合信息指纹来构建计数型Bloom过滤器的方法,如图2所示.该方案将存储区分为d层(本文为了论述方便,按照d=4来划分存储区),每层记作LV1,LV2,LV3,LV4,每块又依赖递减率R分为不同数量但相同容量的块.本文将每层中各个块看作桶(bucket),从上到下记作BN1,BN2,…,BNn桶内存储H个元素.每个桶由标签、信息指纹、计数器和下一跳端口组成.每层桶的数量由固定的递减率R(R<1)决定.设R0=1+R+R2+…+Rd-1,那么LV1桶的数量BN1=[n/(HR0)],第LVi桶的数量为BNi=[BNi-1R](i≥2) .例如,如图2所示将存储区划分为4个层次,每层按照递减率R=0.5划分为若干个桶,每桶深度为8,即能存储8个信息指纹.当插入元素key时,由 d个独立的哈希函数计算元素key的哈希值,然后映射进各个块中的桶地址,分别记作 h1(e),h2(e),…,hd(e).然后将key插入到 BE1(h1(e)),BE2(h2(e)),…,BEd(hd(e))中负载最轻的那个桶中.如果存在多个负载最轻的桶,则选择最上面层次的桶.遵循上述方法,可使得各个层上各个桶的负载率较为平均,所以该方案适用于大规模数据的存储和查询,除此之外也支持网址黑名单白名单功能.文献[5]中的实验表明,与一般的哈希表查询相比该方案获得90.9%的内存节省,且有效地提高了查找速率.以下为进行插入和查询元素时的算法.
Algorithm 1 Pseudo-code for insertion and search in MLCBF
FunctionMLCBF-INSERT(key)
ifMLCBF-SEARCH(key) then
fori←1 toDdo
pos←LVi[hi(key) modBNi]
forj←1 toHdo
ifBEpos.LB[j]=0 then
BEpos[j].fingerprint ←hf(key)
BEpos[j].CC←BEpos[j].CC+1
BEpos.LB[j]←1
return 1
return 0
FunctionMLCBF-SEARCH(key)
fori←1 toDdo
pos←LVi[hi(key)] modBNi
ifBEpos.LB≠0 then
forj←1 toHdo
ifBEpos.LB[J]=1 then
ifBEpos[J].fingerprint ≠hf(key) then
j←j+1
else return 1
elsej←j+1
return 0
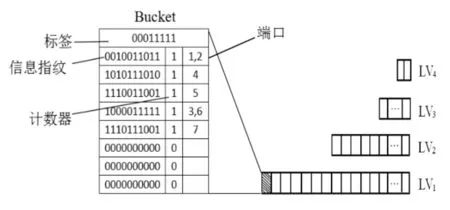
图2 MLCBF框架举例(R=0.5)Fig.2 An example of MLCBF construction (R=0.5)
3 MLCBF冲突率
目前的哈希函数Bloom过滤器得到的哈希值分作两个部分,高位部分用作随机地址,低位部分留作信息指纹.但是这样的哈希过程冲突率较高,且不能进行插入删除等操作,即无法处理变动的集合,并且此时各个bucket的负载并不均衡.目前所提出的DLCBF与MLCBF主要区别在于它每一层桶的个数是相等的,而MLCBF是依赖固定的递减率R来分配每一层桶的个数,那么在插入元素时,MLCBF的负载均衡率较高于DLCBF,所以在冲突率方面也是略小于DLCBF.
建立一个元素集合S={x1,x2,…,xn}, mn为计数器个数,N为所有元素个数,令η=mn/N (全局负载指数),F为元素多样性即当F越大时,元素重复率就越小.当查找元素x,y时,其中x∉S,y∈S,但存在hf(x)=hf(y),此时便产生了冲突现象,由此造成错误的定位是不能接受的.所以,尽管提高了查找速度,越高的d,H依旧会造成一定程度的冲突现象.对于MLCBF,其冲突率不会超过dH2-F,那么MLCBF的冲突率EP1可以表示为:
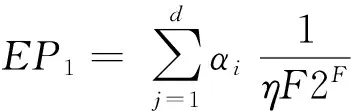
(1)
其中αj/η可以理解为该层的负载率(Load):

(2)
对于DLCBF:
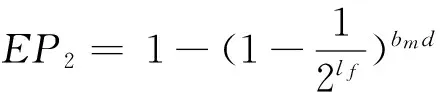
(3)
当lf≥8时,(3)式可近似为:
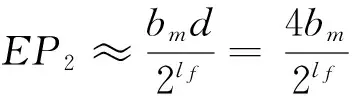
(4)

(5)

(6)
4 实验结果与分析
以公式(1)和公式(4)为依据,F(元素多样性)为自变量进行冲突率分析实验.实验对目前广泛研究的CBF、DLCBF和BloomHash与本文所提出的MLCBF方案冲突率进行比较.当η=1,2时,全局负载过高,计数器几乎满载,桶易溢出,实验数据不可靠,所以本次实验值考虑η=3,4,5,6四种情况,实验结果如图3.
如图3所示,当η=5,6时,BloomHash、CBF的冲突率和MLCBF、DLCBF的冲突率差距较大,所以此时只比较后者两种Bloom过滤器,由于CBF和BloomHash冲突概率不随F变化,当F增大时,MLCBF冲突率优势趋于明显,当F=14,15时MLCBF的冲突概率几乎为0,DLCBF和MLCBF冲突概率平均减小率如表1所示.
表1DLCBF和MLCBF冲突概率平均减小率
Tab.1The average conflict probability decrease rate of DLCBF and MLCBF
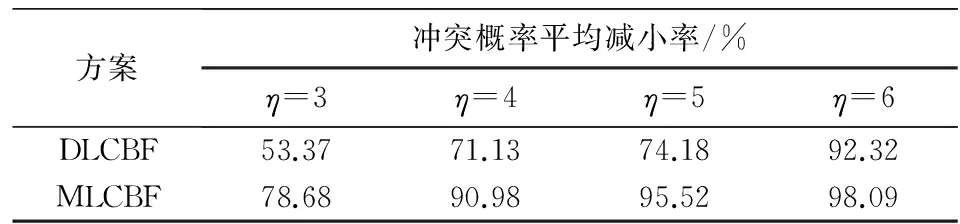
方案冲突概率平均减小率/%η=3η=4η=5η=6DLCBF53.3771.1374.1892.32MLCBF78.6890.9895.5298.09
由表1可见,随着F的增大,MLCBF冲突概率平均减小率大于DLCBF,说明当元素多样性增大时,MLCBF能更有效地降低名字的冲突率.当F>15时,元素基本都各不相同,重复概率低,冲突率无限趋于0,所以实验只考虑F≤15的冲突率情况.如图3(d)所示, 当η≥6时,两种方案的冲突率都无限趋近于0且重合,所以η>6后的情况此时不用再讨论.
5 结语
由于当前互联网的局限性,命名数据网络成为了符合新兴通讯需求的全新网络架构,是未来网络架构研究方案之一.本文利用MLCBF实现多层次化计数存储名字,较便捷地插入和删除元素.实验结果表明,相比其余三种方案,当元素多样性增长时MLCBF因其多层次的优势使得各层次负载率趋于平衡,且能有效地降低名字的冲突概率.
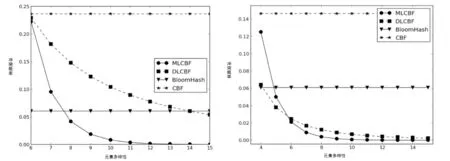
(a) η=3 (b) η=4

(c) η=5 (d) η=6图3 取不同值时四种方案的冲突率Fig.3 False positive rate of four paradigm
[1] 吴超,张尧学, 周悦芝, 等. 信息中心网络发展研究综述[J]. 计算机学报, 2015, 38(3): 455-471.
[2] 黄韬,刘江,霍如,等. 未来网络体系架构研究综述[J].通信学报,2014,35(8):184-197.
[3]Zhang L X,Estrin D,Burke J,et al.Named data networking(ndn). Project[R].California: PARC,2010.
[4]林啸.以内容为中心的新一代互联网体系架构研究[J].电信科学,2010,5: 1-7.
[5]Feng Y H, Huang N F, Chen C H. An efficient caching mechanism for network-based URL filtering by multi-level counting bloom filters[C]//IEEE. International Conference on Communications (ICC).Kyoto: IEEE, 2011: 1-6.
[6]Park C, Hwang S. Fast URL lookup using URL prefix hash tree[EB/OL]. (2008-05-11).http://dbpia.co.kr/.
[7]Wang Y, Dai H, Jiang J, et al. Parallel name lookup for named data networking[C]//IEEE. Global Telecommunications Conference (GLOBECOM 2011).Houston: IEEE, 2011: 1-5.
[8]Wang Y, He K, Dai H, et al. Scalable name lookup in NDN using effective name component encoding[C]//IEEE. The 32nd IEEE International Conference on Distributed Computing Systems (ICDCS).Macau: IEEE, 2012: 688-697.
[9]Wang Y, Pan T, Mi Z, et al. NameFilter: Achieving fast name lookup with low memory cost via applying two-stage bloom filters[C]//IEEE. The 32nd IEEE International Conference on Computer Communications (INFOCOM).Turin: IEEE, 2013: 95-99.
[10]Bonomi F, Mitzenmacher M, Panigrahy R, et al. An improved construction for counting bloom filter[M]. Berlin: Springer, 2006: 684-69.
[11]Qiao Y, Li T, Chen S. One memory access bloom filters and their generalization[C]// IEEE. Berlin The 30nd IEEE International Conference on Computer Communications (INFOCOM). Shanghai: IEEE, 2011:1745-1753.
Named Lookup Based on Multi-Level Counting Bloom Filters for Named Data Network
HouRui,WuTingting
(College of Computer Science,South-Central University for Nationalities,Wuhan 430074,China)
In view of the present most of NDN name lookup method based on Bloom filter, only consider the rate and ignore the limitations of the conflict probability, proposes a consider name conflict probability and name lookup method based on Multi-level Counting Bloom Filters. The experiment results show that relative to the extensive research of Counting Bloom Filters, hash function and d - left Counting Bloom Filters, the proposed method can effectively reduce the collision probability.
Bloom filters;named lookup; named data networking; the longest prefix matching
2016-04-12*通讯作者吴婷婷,研究方向: 光网络技术,E-mail: wtt_617@yeah.net
侯睿( 1977-) ,男,教授,博士,研究方向: 光网络交换技术研究,E-mail: hourui@mail.scuec.edu.cn
武汉市科技计划资助项目(2015010101010008,2013010501010125),湖北省普通高等学校“战略性新兴(支柱)产业人才培养计划”资助项目
TP393
A
1672-4321(2016)03-0107-04
