大数据关键技术在基建营房综合管理系统中的应用
2016-10-29郭宇栋李生林
郭宇栋,李生林
(后勤工程学院,重庆 401331)
大数据关键技术在基建营房综合管理系统中的应用
郭宇栋,李生林
(后勤工程学院,重庆 401331)
重点研究了大数据处理及分析挖掘等关键技术,结合基建营房综合管理系统的应用环境,论述大数据技术在基建营房综合管理系统架构、数据标准、数据处理、分析挖掘等方面的应用情况。
大数据挖掘;基建营房;信息管理系统
1 引言
随着信息系统的广泛应用和信息技术的高速发展,特别是地理信息系统、数据存储技术和物联网等技术的发展,使得“数据”规模呈现指数级别增长。在工业、交通运输、医疗卫生、电子商务、社交网络等领域,都积累了TB级、PB级乃至EB级的大数据。这些大数据正在影响着人类认识、理解社会的方式,推动社会发展和管理模式变革,成为信息社会的重要财富[1]。
2011年5月,在麦肯锡全球研究院发布的《大数据:创新、竞争和生产力的下一个新领域》的研究报告中指出,大量数据作为重要的信息要素,已经渗透到各行各业和业务职能领域,大数据的实际应用将引领一波新的生产率增长和商业利润浪潮的到来。2012年3月29日,美国政府在白宫网站发布了《大数据研究和发展倡议》,提出通过收集大量复杂的数据资料提升获取知识的能力,并且将投资2亿美元启动“大数据研究和发展计划”。
人类进入信息化时代以后,短短的数年时间,积累了大量的数据,步入了“大数据时代”,使人类以前所未有的速度、厚度、细度和准确度对信息的掌握成为可能。面对大量的数据,基于充足的数据基础,对数据进行挖掘与分析,并将其运用于企业、军队等领域的精细管理,也就不仅成为可能而且势在必行[2]。
随着国家、军队建设发展和改革深入,基建营房建设管理面临着前所未有的挑战和困难,工程建设“三超”(超规模、超投资、超面积)现象屡禁不止,房地产“管不住”问题无法根治,国防工程维护管理消耗“不明确”问题长期存在,住房制度改革举步维艰等,这些困难和挑战靠现有的信息能力已无法支撑,靠传统的管理模式难以解决。大数据关键技术及在基建营房综合管理系统中的应用研究,是将大数据应用到基建营房综合管理系统中,运用大数据的理论、机制、模型和方法等解决基建营房建设、管理、维护中的决策问题,通过问题分析原因、通过现象预测结果,并提供大数据关键技术在基建营房综合管理系统中的应用方案,实现基建营房信息主导、精确管控、工程透明、科学决策的目标,为提升信息保障能力、创新管理保障模式提供新的方法和手段[3]。
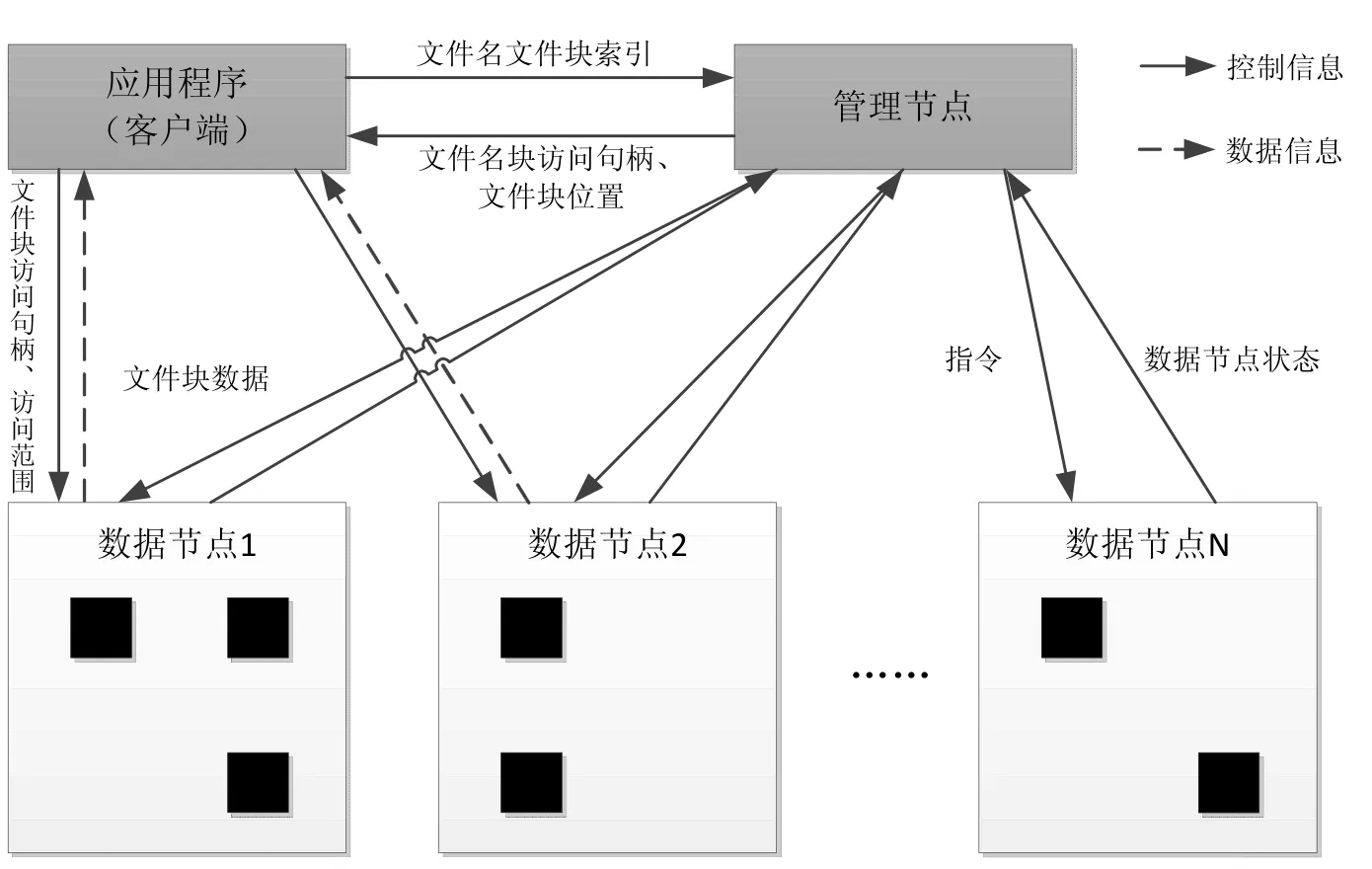
图1 分布式文件存储架构
2 大数据关键技术
一般意义上,大数据是指无法在可容忍的时间内用传统IT技术和软硬件工具对其进行感知、获取、管理、处理和服务的数据集合。大数据的特点可以总结为4个V,即Volume(体量巨大)、Variety(类型繁多)、Velocity(生成快速)和Value(价值巨大但密度很低)。大数据处理的关键技术主要是指能够在容忍时间内处理大量不同类型的数据,而大数据分析挖掘的关键技术主要体现在运用各种机器学习算法分析和挖掘数据中的价值。本文将分别介绍大数据处理和分析数据挖掘的关键技术[4]。
2.1 大数据处理关键技术
2.1.1 分布式计算架构。大数据环境下的分布式计算架构与传统的分布式处理系统有所区别。传统的分布式计算架构通常采用纵向拓展的方式,其计算性能增长速度无法跟上数据增长速度,性能提升存在上限。大数据环境下的数据呈现指数级增长,传统的数据处理架构显然已无法适应,所以采用横向拓展方式的分布式计算架构将成为大数据处理架构的主流。
2006年Google首次提出大数据的分布式处理模式,包括分布式文件存储系统、分布式计算编程模式等技术体系,同时还提出了一系列学术论文作为理论依据供研究学者进行讨论。在这种分布式计算思想的指导下,Hadoop等优秀的分布式处理软件框架应运而生,架构如图1所示。
分布式文件存储架构是通过大量普通PC机或廉价服务器集群而构建的松耦合存储系统,能够以分块、分片等方式高效地存储海量数据。其中,MapReduce是利用了分布式文件存储架构而设计的大数据存储与计算编程模型,主要思想是搭建廉价的中低端服务器集群,对每个服务器节点性能要求不高,提供整体的松耦合性、扩展性和容错性等。当发生服务器宕机或者节点从集群中移除时,整个集群依然能够保持良好的运行状态和计算性能,几乎不受单个节点的影响。在电子商务、社交网络等领域,分布式存储和计算架构已经成功得到了实际验证,其开源模式更为程序开发人员提供了二次开发的可能,以键值对<key,value>形式存储数据格式不受限定;在MapReduce编程模式中,Map和Reduce函数为用户提供了计算编程接口,可以自定义实现较复杂的数据处理逻辑,为海量半结构化、非结构化数据处理提供了高效的处理方式,也为大规模数据集机器学习与挖掘等技术的实现提供了基础架构[5]。
2.1.2 并行数据库技术。分布式计算架构为大规模数据集的处理提供了技术基础,但是由于所有的数据处理逻辑必须由用户自定义开发,原本应该由数据库完成的任务移交给了程序开发人员,导致应用程序的使用成本增长。所以,并行数据库技术的出现则针对这方面的缺陷提供了一个优势的解决方案。
并行数据库技术经过几十年的研究发展,技术水平有了长足的进步。早在20世纪70年代,并行数据库技术在数据库机的研究领域中逐渐走进人们的视野,主要研究内容是关系数据库的并行操作与专用硬件设备的开发,旨在通过硬件设备实现分布式操作关系型数据库。上世纪80年代,并行数据库技术摒弃了原来的硬件设备的研发,转移到从组织调度策略层面构建并行数据库机。90年代后,随着多核处理器、大容量存储、高速计算能力等信息技术的发展,并行数据库技术的研究得到了质的飞跃,其研究的重心变为时间、空间数据的并行化方面,如图2所示。
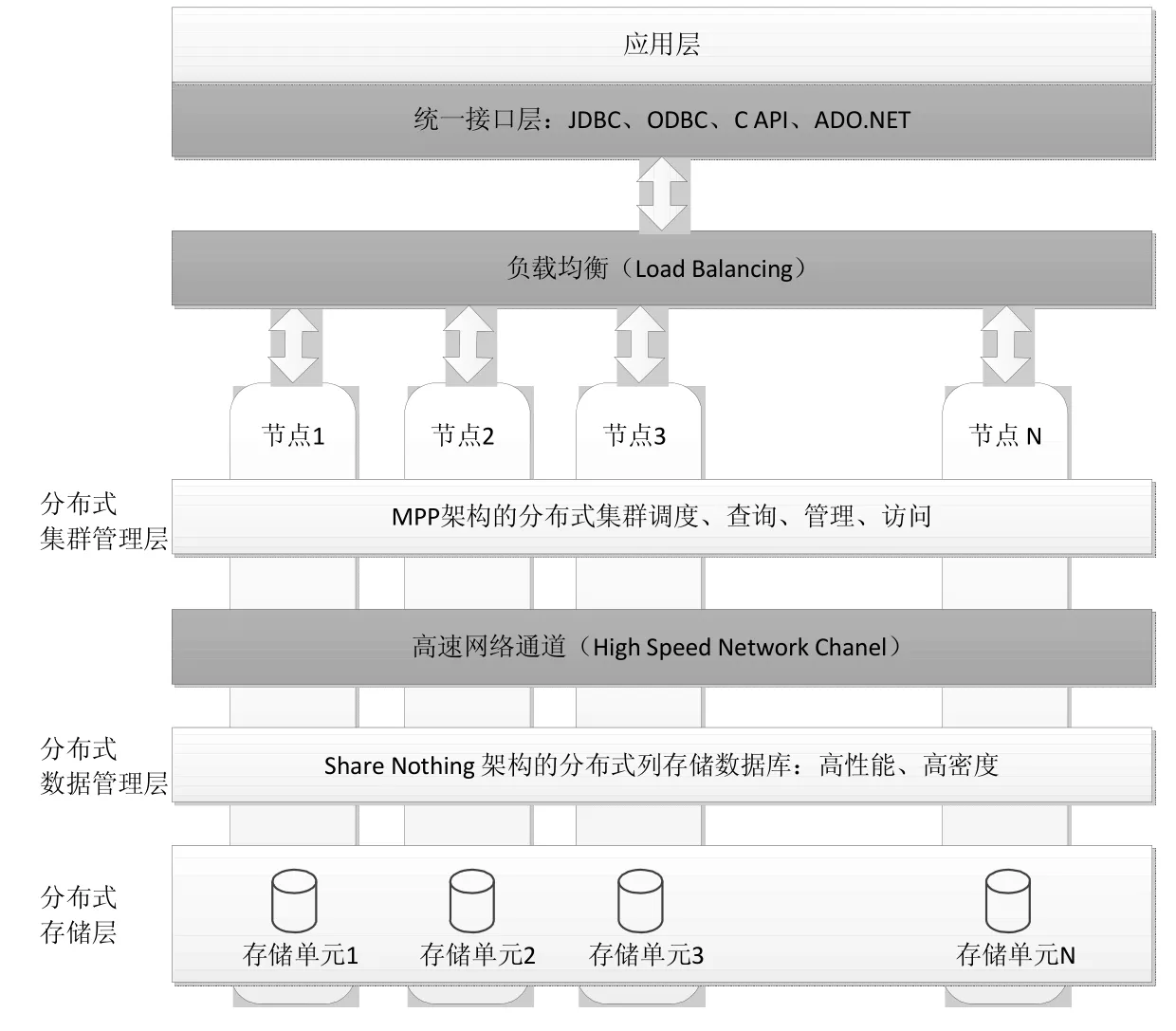
图2 并行数据库架构图
在处理大规模数据集的过程中采用并行数据库技术,目的是利用系统集群的高效运算性能,实施时将关系数据库的数据表中的数据分块或分片,根据分配策略分发给各个节点进行处理并执行数据库事务操作,最后将处理结果反馈给用户,实现节点间的完全无共享,同时将各节点数据进行镜像备份,强化冗余并提升数据库性能。此外,并行数据库能够建立在廉价的服务器集群上,节点间可保持很好的拓展性和容错性。
2.1.3 大数据处理模式。目前,为了满足大数据在极短的时间内处理海量数据,获取有价值信息的需求,在数据处理过程中主要采用流处理和批处理两种方式。流处理是在不存储数据情况下对实时数据进行处理,批处理则是先将数据存储至本地后再处理。
(1)流处理。流处理是指数据的来源是实时的,数据价值的时效性非常高,而随着时间的增加价值不断地减少,因此必须用最短的时间处理数据给出最优结果。在大数据处理过程中需采用流数据处理模式的领域主要有数字化传感器实时监控、网站点击量的实时统计、电子商务及社交网络中的高频通信等。在流处理的处理过程中,在一段时间内的数据将被视为流,每次数据流到来时立即进行处理并返回运算结果。流处理模式中的数据流模型,如图3所示。
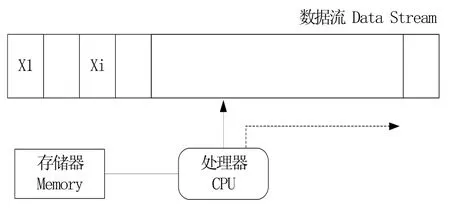
图3 基本数据流模型
在数据流处理的实际过程中,由于数据来源是源源不断的且数据量巨大,对时效性要求极高,所以只对数据本身进行处理运算,而不会对数据进行持久化储存,所有的计算都在内存中完成,所以系统这种处理方式具有较高的运算效率。但是,流处理方式更多地依赖内存设备的性能,内存容量成为限制流处理的一个瓶颈。目前,多核处理器与相变存储器等设备的出现,为流处理模式的发展提供了更好的平台。
经过几十年的研究发展,数据流处理模式不仅在理论层面有较为深入的研究,在各个领域也得到了广泛的应用,一些代表性的开源流处理框架如Twitter的Storm、Yahoo的S4以及Linkedin的Kafka等。
(2)批处理。2004年Google公司首先提出分布式计算思想和并行批处理编程模型MapReduce,处理过程如图4所示。
MapReduce模型利用了分布式计算的思想,处理过程是首先将数据源进行分块、分片处理,然后分别传递至Map任务区进行任务分配。Map过程能够从各自的输入数据中解析获取键值对<key,value>集合,然后调用用户自定义的Map函数执行,将计算结果持久化存储至本地硬盘文件系统或数据库系统中。在执行Reduce任务过程时,从本地硬盘读取数据,根据Key值索引排序,执行用户自定义的Reduce函数,将Key对应的Value值合并返回结果。
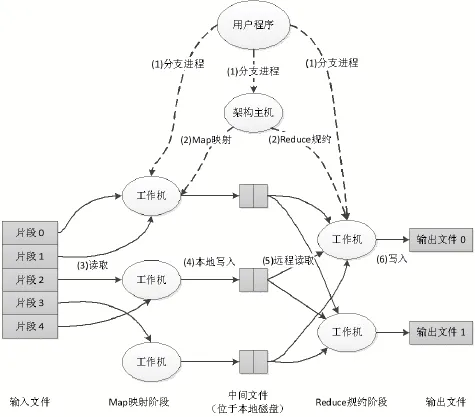
图4 MapReduce处理过程图
从上述处理过程可以看出,以MapReduce为代表的批处理模式主要设计思想是:(1)将复杂计算分散化,再将计算结果合并返回;(2)以数据为驱动旨在解决任务分配,而不是以运算为中心,这样可以有效地减少数据通信过程中的开销。批处理模式架构部署方便快捷,在很多领域都得到了广泛应用,如舆情分析、文本挖掘、数据预测等。
流处理和批处理作为大数据处理的两种主流方法,各有利弊。在实际数据处理过程中应该按照用户的需求选择使用其中一种,亦或二者结合。海量数据的一个重要的来源是互联网(包括网站流量、电子商务和社交网络等),很多互联网大数据解决方案都是根据具体业务处理的时效性需求定制拟采用的处理模式。如著名的职场社交平台Linkedin将自身的业务划分为在线处理、近线处理和离线处理三种方式,每一种处理方式所需的时间消耗是不同的。其中,在线处理时间范围是秒级甚至是毫秒级,所以采用上述的流处理方式;近线处理的时间范围在分钟级或者小时级,用户可自定义采用任何一种处理模式,实际应用较多采用批处理或者传统的OLAP等;离线处理的时间范围是24小时,即1天之内的数据,可以采用批处理方式有效地节约内存消耗,提升磁盘利用率[6]。
2.2 大数据分析挖掘关键技术
2.2.1 大数据机器学习方法。传统的数据分析方法有很多,包括数据仓库、多维在线分析(OLAP)和经典的数据挖掘算法等。随着信息产业的发展,数据量的剧增,传统数据分析方法已经无法满足大数据环境下的数据分析需求。相比之下,大数据分析的核心需求就是从数据量巨大、结构种类繁多、高速变化的数据中挖掘出隐藏的规律,进而使数据发挥出最大化的价值,这些需求使得传统的数据分析方法不再适用,大数据机器学习方法的优势逐渐展现出来。
大数据时代根据用户数据量、时效性和价值等的需求选择机器学习算法,并对其加以改造,例如数据分类与预测(决策树、神经网络算法等)、聚类分析(KMeans、SOM、FCM算法等)、关联规则(Apriori、FPGrowth算法等)、时序分析(平稳时序分析、非平稳时序分析算法等)。机器学习的监督、半监督式学习方法是获取大量数据中隐藏价值的核心,这些数据既包括结构化的文本数据、关系型数据库,又包括图片、视频等非结构化的数据。对于大数据处理架构编程中还需考虑采用时空亚线性算法、外存索引算法、并行算法和众包算法等来提高分析处理的时空效能、存储能力、运算能力和信息协调能力。
2.2.2 大数据可视化方法。传统的数据可视化是通过图表、报表、仪表盘等方式进行展现,这种图文集合的方式能够直观体现数据价值。但是这些数据价值往往是一次性的,而不是实时的分析结果,更无法与用户做出实时交互式查询,对于一些复杂的数据分析需求可能还需更改程序。传统的可视化方法在大数据环境下难以适用,因此需借助SPSS、SAS、Weka、Gephi、R等专业数据分析与可视化工具来进行数据展现。
R作为大数据分析可视化的一款常用工具,本身属于GNU系统的一个开源软件,不仅用于统计计算和数据绘图,更包含了大量数据挖掘算法,如线性和非线性回归、统计检验、时空序列分析、分类与聚类分析等。开源的R语言插件能够部署运行在Hadoop集群中,实现跨平台部署,能够对HDFS分布式文件系统中的非结构化数据进行分析和对HBase中的非关系型数据进行分析,以满足大数据环境下的数据挖掘与可视化需求[7]。
3 大数据在基建营房综合管理系统中的应用
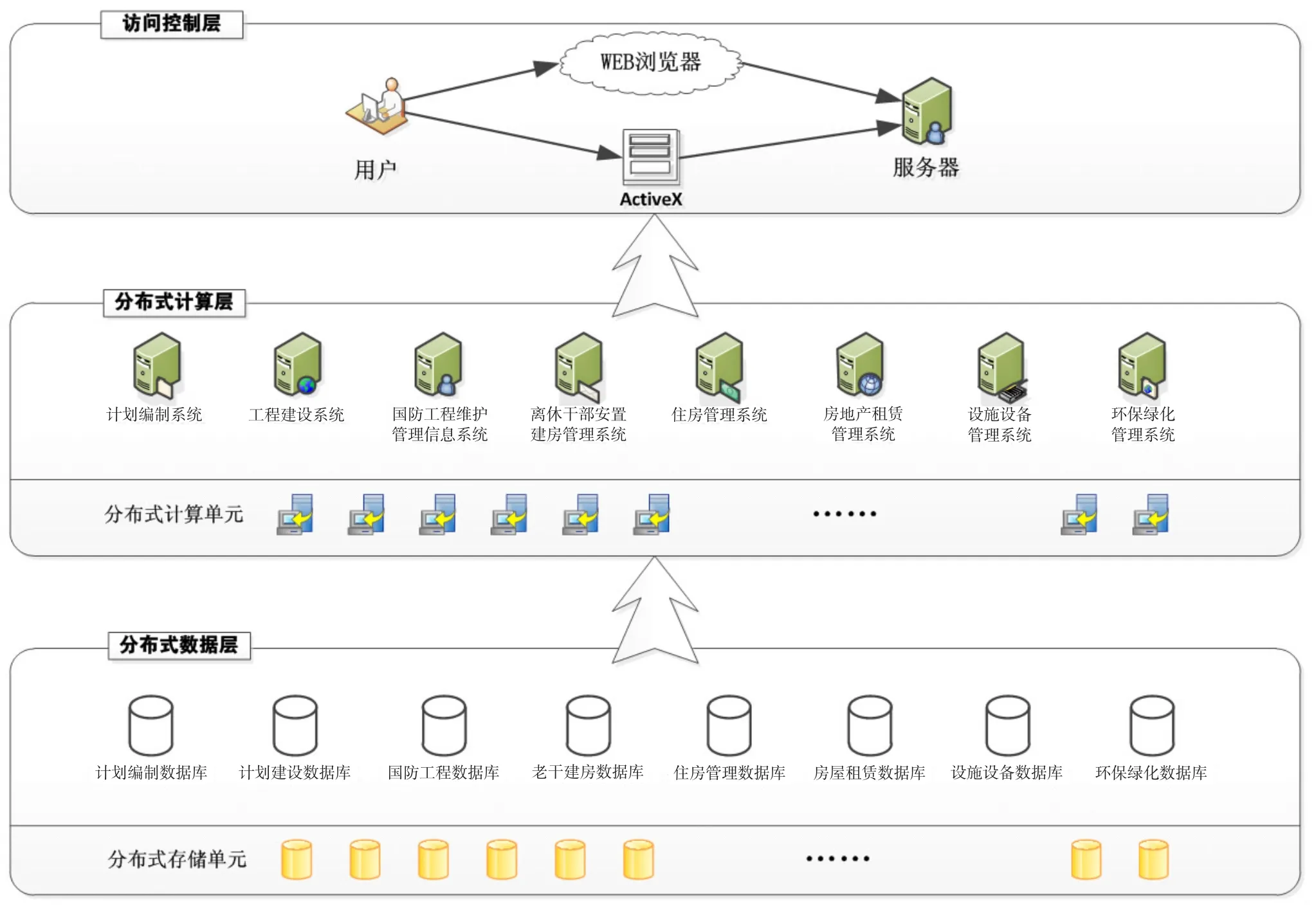
图5 大数据环境下基建营房综合管理系统架构图
3.1 基建营房综合管理系统概述
为了切实贯彻总后首长“要建立基础数据库,实行信息化联网管理”,“通过信息手段,实现房地产保障资源可视掌控、基本建设投向投量精确合理”的指示要求,积极推进军队基建营房向信息化转型发展,基建营房综合管理系统拟综合运用信息化手段构建涵盖基建营房各业务领域、满足各使用对象需求,能为实现工程透明、资产可视、营区感知、全域管控提供支撑,能形成基于信息系统体系作战基建营房保障能力,提高基建营房保障效能提供技术手段的基建营房大系统。
在基建营房综合管理系统中引入大数据关键技术,重点解决基建营房各业务领域信息系统数据标准不一致、业务覆盖不全面、流程管控不透明、辅助决策水平低等问题,实现基建营房信息主导、精确管控、工程透明、科学决策的目标,形成基于计算机网络环境下通过信息系统开展营房保障和管理的工作模式。
3.2 系统架构设计
大数据环境下的基建营房综合管理系统架构如图5所示,主要采用分布式计算架构,结合并行数据库技术,有效地搭载基建营房各类数据(包括业务数据、控制数据等),支持大数据的流处理模式和批处理模式,能够实现基建营房海量数据存储与维护和跨层级分布式业务处理,为系统功能的柔性重组提供一个松耦合的集成框架[8]。
3.3 数据标准编制
(1)基建营房大数据的来源。基建营房大数据来源,一方面是全军展开的“两项普查”数据作为大数据分析决策的基础,优选出基建营房相关的基础数据项和数据库表,建立了从计划、建设、竣工、移交、住用、日常管理到辅助决策的数据关联,另一方面是基于军队基建营房综合管理系统实时动态数据采集,包括对业务人员、指挥人员、系统访问人员的行为数据和数字化、智能化设施设备实时生成的数据,这些数据是具有大数据4V特征的动态数据,是基建营房大数据时效性和精准性的保证。因此,解决基建营房大数据的来源问题是保证数据集成真实有效、数据分析实时精准、数据挖掘科学合理的前提条件。
(2)基建营房大数据的标准。基建营房数据标准的统一,是实现数据集中管理、融合共享的前提,是建立唯一的基建营房中心数据库与统一挖掘模型的基础。首先,利用大数据并行数据库技术建立分布式业务数据库,为基建营房各个业务子系统提供高自由度的数据环境;然后,分别建立业务数据模型与标准模型的映射管理,这里包括结构化数据的字段映射、半结构化和非结构化数据的语义映射等大数据映射标准;最后,分别将各业务子系统数据库的数据按照时间节点横向划分,通过多个节点并行数据处理任务,为实现基建营房综合管理系统大数据分析挖掘提供数据准备。
3.4 数据处理应用
基建营房业务领域涵盖面广、部门交叉性强、处理过程中存在大量的大数据存储与交换,例如包括营房土地、国防工程、住房实力、环保绿化核防、空余房地产、物资装备等房地产资源数据和包括建设项目、住用单位、营区坐落、设施设备、室外管线、绿化资源、储备营区应急保障能力以及五图一影等的日常维护保障数据。这些数据规模远远超过GB级,达到TB级。另外,这些数据结构复杂,包括结构化、半结构化和非结构化数据(如地理信息、卫星影像、三维模型等数据),远远超出普通管理信息系统数据处理能力的范围,必须借助大数据技术才能对其进行有效的存储和分析。因此,解决基建营房大数据的处理问题是保证数据存储与交换的可靠性、数据分析与预测的科学性和先进性的核心因素。
在基建营房综合管理系统中,所有的业务处理都是通过数据的流动来实现的,包括子系统内部数据流动和跨系统分布式的数据流动。基建营房综合管理系统的业务数据中除了结构化的业务数据表单外,还有很多文档、方案等半结构化数据和地理信息、图片、视频等非结构化数据。而且各类的数据又存储在不同系统、不同数据库、不同服务器、不同的数字化装备设备中。所以,在建立集成中心数据库时采用服务器的分布式存储与控制,这种方式会大大提高系统稳定性且减少系统响应时间,实现更稳定的信息化保障方式和更好的用户体验。同时,还应当考虑服务器集群的分级、分类构建,半结构化与非结构化数据在不同类型服务器中的分片存储与处理,异地数据加密与备份等。
由于基建营房业务需求广泛和数据多样化的特点,需要对基建营房大数据处理策略进行研究,目标是构建一个满足能存储海量数据、自主定时定量、高度适应、容错一致性可调的大数据集成环境,明确数据动态监管过程中的数据粒度与数据实时性,不同的数据类型指定动态监管方式也不同。例如国防工程日常维护设施设备监控数据项,这种数据粒度细、实时性极强。全军各种设施设备每个参数每秒钟的动态变化是不可能记录到系统数据库中的,只能存在于智能设备的内部存储中。总部级既关注战时保障数据的精确定位与实时反馈,又关注各战区的年度、季度、任务消耗统计值的横向比较与决策分析,所以如何利用智能设备接口调用实时数据是实现动态数据监管的基础,而且集成中心数据库的动态数据抽取、转换、加载过程(ETL)的时间范围须谨慎设计并加以控制。
3.5 数据分析与挖掘
解决大数据的挖掘问题是解决数据之间联系的问题,通过问题分析原因,通过现象预测结果,打破业务数据之间的屏障,使之统一化、透明化。基建营房各领域内业务处理过程中,会出现许多决策问题,例如通过对基建营房工程项目三年滚动计划(建设、预备、储备)数据的挖掘分析,预测工程建设中的违规违纪,实现工程项目定量、定向管控安排,防止工程建设项目中的腐败问题;通过对住房管理数据挖掘分析,提供年度、季度住房人员、房屋面积、房源租赁信息等计量值,提供住房管理的实时“阳光维护”,有效解决并预防住房“三超”(超规模、超投资、超面积)问题;通过对国防工程战场设施实时动态监控数据分析,预测不同环境下的各级工程维护管理费年度消耗标准,解决国防工程维护管理消耗“不明确”的问题;通过对军队基建营房综合管理系统中业务人员、指挥人员、系统访问人员的行为(包括浏览、留言等操作)数据挖掘分析,提供可靠的各类人群数据模型,分析不同人群对房地产资源政策制度的观点和对未来住房政策的期望,科学有效地推进军队住房制度改革等。这些问题类型复杂,专业性强,计算量大,传统的解决方式是依靠经验判断和人工完成,然而这种方式过多依赖于业务人员和决策人员的能力素质,缺乏客观的数据定量分析作为支持,局限于主观性、盲目性和偶然性。因此,解决基建营房大数据的挖掘问题是解决基建营房业务领域现实问题的决定因素。
在确定基建营房综合管理系统的系统架构、数据标准和数据处理的基础上,完成对数据的智能化处理,即建立分级索引库和挖掘模型库,实现对海量数据抽取、转换、加载、搜索、挖掘、分析和预测。
4 结语
着眼新时期军队基建营房发展,按照全面建设现代后勤总体部署,本文以大数据为技术基础,通过对大数据关键技术在基建营房综合管理系统中应用研究,介绍分布式计算架构、并行数据库技术、大数据处理模式等大数据处理关键技术和大规模机器学习、统计分析可视化等大数据分析挖掘关键技术,提出大数据环境下基建营房综合管理系统架构、数据标准、数据处理、分析挖掘等应用,实现充分有效地利用基建营房数据资源并提供资源动态分析预测,为优化基建营房资源配置、强化营房业务科学管理、加快推进建设现代营房、切实转变基建营房保障模式提供理论基础,进一步增强核心保障能力和提升质量效益。
[1]李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域—大数据的研究现状与科学思考[J].中国科学院院刊,2013,27(6):647-657.
[2]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[3]马建光,姜巍.大数据的概念、特征及其应用[J].国防科技,2013,34(2):10-77.
[4]Frankel F,Reid R.Big Data:Distilling meaning from data[J]. Nature,2008,455(7 209):1-136.
[5]Silva Y N,Reed J M.Exploiting MapReduce-based similarity joins[A].Proc of SIGMOD 2012[C].New York,2012.
[6]Yang Lai,Shi Zhongzhi.An efficient data mining framework on Hadoop using Java persistence API[A].Proc of CIT 2010[C]. Piscataway,NJ,2010.
[7]Apache.Apache Mahout:Scalable machine learning and data mining[EB/OL].http://mahout.apache org.
[8]贾俊芳,张日权.基于分布式的大数据集聚类分析[J].计算机工程与应用,2008,44(28):133-135.
Study on Application of Key Big Data Technologies in Capital Construction and Barrack Comprehensive Management System
GuoYudong,LiShenglin
(LogisticalEngineeringUniversity,Chongqing 401331,China)
In this paper,we mainly studied the key big data processing and mining technologies,then in connection with the application environment of the capital construction and barrack comprehensive management system,elaborated on the application of the big data technologiesinthearchitecture,datastandard,dataprocessing,anddatamining,etc.,ofthesystem.
bigdatamining;capitalconstructionandbarrack;informationmanagementsystem
E235
A
1005-152X(2016)05-0169-07
10.3969/j.issn.1005-152X.2016.05.037
2016-04-14
郭宇栋(1987-),男,辽宁辽阳人,后勤工程学院研究生五队博士研究生,研究方向:后勤信息化。
