流程挖掘在银行服务管理中的应用*
2016-10-28卢盛祺李远刚
卢盛祺,李远刚,管 连,周 赟
(1.上海财经大学 信息管理与工程学院,上海 200433;2.上海财经大学 上海市金融信息技术重点实验室,上海 200433;3.复旦大学 软件学院,上海 200433;4.国际商业机器(中国)有限公司,北京 100101)
流程挖掘在银行服务管理中的应用*
卢盛祺1,2,3,李远刚1,2,管连4,周赟3
(1.上海财经大学 信息管理与工程学院,上海 200433;2.上海财经大学 上海市金融信息技术重点实验室,上海 200433;3.复旦大学 软件学院,上海 200433;4.国际商业机器(中国)有限公司,北京 100101)
随着银行服务信息化的不断发展,银行面临如何从大量的服务数据中提取有价值的信息用以提升服务效率的问题。在银行服务管理系统的实际应用中,由于其业务具有并发性事件多、日志数量大等特点,选择并行Apriori算法进行分析。与传统的Apriori算法相比,针对银行业务中并发性业务较多的特点,设计使用了并行Apriori算法,解决了单服务器运行效率随日志数量明显下降的弊端。银行服务管理系统每日会产生大量流程的日志数据,记录每一位参与员工的工作状态,通过调用并行Aporiori算法,挖掘服务流程日志中的关联规则,找出能够高效协作的员工组合。实验结果表明,将并行Apriori算法应用于服务流程日志的关联规则挖掘,使系统可以根据规则将协作关系紧密的员工分配在一起共同处理服务请求,提高了服务效率,取得了合理的应用效果,提高了银行服务管理系统中服务分配的智能。
流程挖掘;关联规则;员工组合;组织优化;并行Apriori算法
引用格式:卢盛祺,李远刚,管连,等. 流程挖掘在银行服务管理中的应用 [J].微型机与应用,2016,35(18):88-92.
0 引言
随着银行同业竞争之间的压力逐渐加剧,将数据挖掘技术应用于发现流程日志数据中的有用模式,解决银行在新形势下面临的问题,成为大数据时代下银行信息化应用的研究热点[1-2]。作为银行信息化核心系统之一的银行服务管理系统,需要针对来自于银行各种业务渠道的客户进行一站式的管理服务,并帮助银行优化客户服务管理流程,提高服务效率。现有的银行服务管理系统主要提供诸如服务请求录入、服务请求查询等基本的业务操作功能,但系统的智能性普遍不高。此外,银行服务管理系统在长期的运行过程中积累了大量的流程日志,包括事件以及事件执行者等数据[3],这些流程日志所包含的数据反映了流程的执行过程[4]。因此,数据挖掘技术的应用为解决上述问题提供了新的机遇[5-6]。通过对流程日志数据的分析和重现业务流程模型,可以发现影响银行效率的瓶颈,并更好地利用现有资源提高服务质量,推进了银行的业务设计和管理的改进[7-8]。
学术界和企业界已经探讨了如何应用银行流程日志的分析来提高银行服务管理系统的智能[9]。例如,基于时间序列的数据挖掘可以预测银行客户未来的行为[10]。还有基于支持向量机和决策树的改进算法,对数据进行分析并最终预测银行的业务效率[11-12]。但总体而言,目前的相关研究还主要集中在对银行流程日志中所包含的客户相关数据的分析,而对于银行内部运营效率提升方面的应用研究还相对较少,特别是银行员工作为服务流程的参与者,他们之间的合作关系也是影响银行运营效率的主要因素[13]。
本文重点讨论了如何找到合作效率较高的员工组合,来提升银行服务效率,其中针对银行服务管理系统流程日志的大规模特点,探讨了如何有效地应用并行Apriori算法分析银行员工与服务效率之间的关系[14]。
1 银行服务管理流程日志预处理
1.1流程日志的数据分析
银行服务管理系统通常会对服务请求处理的流程数据加以记录,最常见的是以日志文件的形式进行保存。而流程日志作为流程挖掘的输入,记录了流程执行过程中的相关数据。
在银行服务管理系统产生的流程日志中,可以提取参与某次服务请求处理的所有员工、处理的时间等数据。其中,参与某次服务请求处理的所有员工可以看成是针对该次服务请求处理组成的临时团队,而所花费的总处理时间反映了服务的效率。对流程日志数据进行简单的观察,即可发现针对相同类型的服务请求,参与处理的员工组合不同,所花费的总处理时间也是不同的。这很大程度上是因为员工之间的协作紧密程度影响着服务效率。通常协作关系好的员工在一起处理服务请求,具有更高的服务效率。这说明完成服务处理的员工的组合与总处理时间之间存在一定的关联关系。因此可以通过关联分析找到与高服务效率相关联的员工组合,回答“怎样的员工组合是高效的”,也侧面回答了“哪些员工在一起工作是协作紧密的”,从而提高了系统的智能性。在此基础上,针对各类服务请求,生成相应的服务分配规则,将协作关系紧密、可以提供高服务效率的员工分配一起,从而提高服务效率,减少客户的等待时间,提高客户满意度。
流程日志文件本身往往不是为关联分析所设计的,它包含了与分析主题无关的属性,也存在与分析主题所需数据维度不一致的情况,因此数据预处理是整个流程日志挖掘过程的基础以及保证规则有效性的前提,从大量的数据属性中提取与挖掘过程有关的属性从而降低了原始数据的维数。数据预处理主要包括以下几方面。
(1)忽略或者删除与关联分析无关的属性。
(2)对噪声数据、错误数据、缺失数据进行数据清洗处理[15]。由于系统的异常、人为的误操作等情况都可能产生噪声数据、错误数据、缺失数据,这些数据会影响分析的结果,因此在数据预处理过程中需要对这些数据进行数据清洗,以提高数据挖掘算法的效率和准确度。其中,对缺失数据的问题,通常可以通过数据补齐和数据预测等方法处理。对于少量错误数据的问题,通常采取删除错误记录的方式进行处理。
(3)对数据进行转换。这主要包括定义衍生列,并根据逻辑计算其值,对隐私信息进行转换等操作。
1.2流程数据的预处理
(1)数据清理
针对在流程日志数据分析中发现的典型问题,可以通过以下方法进行处理:
①针对错误数据、缺失数据的问题,通过定义规则来定位错误数据和缺失的数据,并将其删除。例如“InQueueDateTime”、“OutQueueDateTime”分别表示服务请求进入员工服务队列池的开始时间和结束时间,显然“InQueueDateTime”晚于“OutQueueDateTime”的数据为异常数据。因此,可以定义规则:如果记录中的“InQueueDateTime”晚于“OutQueueDateTime”,则删除该条记录。
②针对需要对数据进行转换的问题,可以定义字段转换规则和计算公式,并据此产生衍生字段。例如设定计算规则:“处理池停留时间(Duration)”可以由“服务请求进入处理池的时间”到“服务请求离开处理池的时间”的间隔计算得到。对各步的处理池停留时间求和,就可以得到衍生字段“总服务处理时间”。
③反映服务效率的服务处理时间一般是正态分布的,因此代表高服务效率的记录往往很少。针对该问题,可以仅截取代表高服务效率的记录作为分析的数据集,然后设定合适的服务效率分级规则。
(2)会话识别
要识别每一条会话,一条完整的会话的界定比较复杂,以拨打电话为例,用户会在不明确服务流程的情况下,拨打好几次电话进行尝试,但其中只有服务成功的会话才是有效的,所以在识别会话的过程中有一些启发式规则可以使用。
①在短时间内,一个用户进行多次的服务请求,都可以认为是一个会话。
②一个用户如果发起了不同的服务请求,需要被认为是不同的会话。
③与用户确认结束服务作为一个会话的结束,保证会话的有效性。
在各类企业信息系统所产生的日志文件中,XML是一种比较常见的形式。其中,每一个XML标签(tag)被称为一个元素,对应一个属性。针对银行服务管理系统产生的流程日志的文件形式,可以通过ETL工具对其进行预处理,只采集与关联分析有关的属性。使用 ETL工具读取流程日志文件和元数据配置文件,将流程数据加载到数据库中。流程数据表包含的主要属性有请求类别(RequestType)、请求子类的唯一标识码(RequestCode)、此次服务请求的唯一标识(RequestCaseUniqID)、操作类别(ActionType)、日志记录类别(LogRecordType)、系统用户账号(LogonID)、会话号(SessionID)、会话开始时间(SessionStartDateTime)、会话结束时间(SessionEndDateTime)、进入处理池时间(InQueueDateTime)、离开处理池时间(OutQueueDateTime)和产品代码(ProdectCode)等。
1.3数值属性离散化
并行Apriori算法是一种用以挖掘布尔关联规则频繁项集的关联规则分析算法,而服务请求的总时间是数值类型的,因此需要对服务请求总时间进行属性离散化。
以处理申请无抵押贷款的服务请求为例,用ProcessRequest_APPL-UPL代表处理客户申请无抵押贷款的服务请求,且该请求在系统中需要通过4个步骤完成。其基本流程是个人贷款部门业务员完成对请求的相关信息录入;客户信息管理部门根据录入的信息核对该客户信息并在系统中给予核准意见;对于通过核准步骤的请求,贷款部的额度组根据客户收入和信息确定批准的贷款金额;最后,个人贷款部门业务员发放贷款并在系统中更新该信息。用TCT代表完成此次服务请求的总耗时。包含上述员工的服务请求的部分流程分析数据如表1所示。
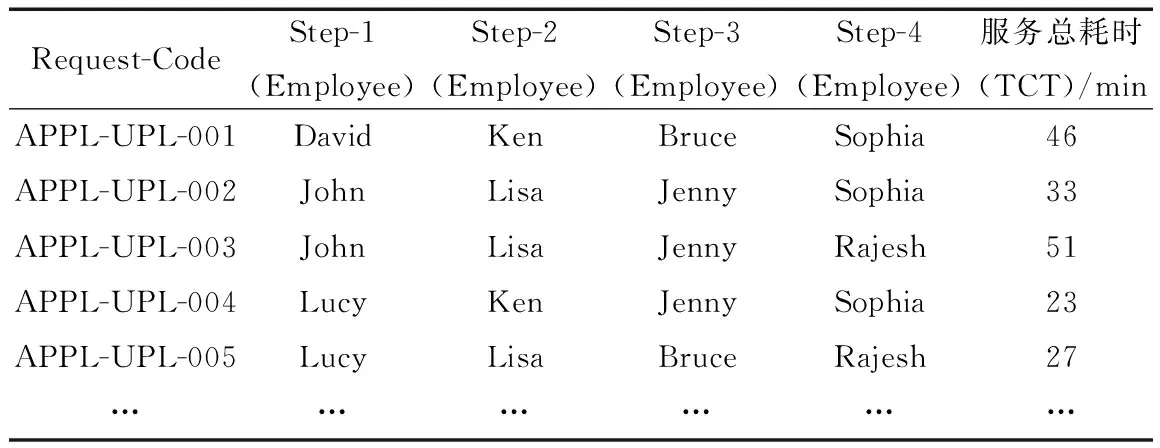
表1 处理前数据示例
服务总时间数据离散的过程如下:
(1)计算针对客户申请无抵押贷款类的服务请求(APPL-UPL),所有员工序列的总平均处理时间(Average-Consumed-Time,ACT),即ACT=sum(TCT)/ (records count)。
(2)将各组员工序列的处理总时间(Total-Consumed-Time,TCT)减去总平均处理时间(ACT)并与总平均处理时间求比值,用TCT%表示。
(3)确定服务请求处理效率的分级规则。对服务请求的处理效率进行分级时,需要分析经过步骤(2)计算后的TCT%的分布情况,并根据数据的分布情况确定最小置信度的区间。
依据以下原则选取合适的服务请求处理效率分级规则。
①保证分级后,包含期望出现在挖掘结果中的服务等级的记录数与总记录数的比值大于选取的最小置信度。例如,假设定义TCT% 小于-50%为Class A,代表具有高服务处理效率,期望挖掘出的关联规则是员工组合与高服务效率(Class =A)之间的关联关系。
②保证分级后,挖掘出的结果是有意义的。如果将TCT% 小于-1%划分为Class=A,则挖掘出的关联规则包含Class=A的项集。因为各组员工的TCT%符合正态分布,假设现有的服务效率(Productivity-Class)分为5级,数据分布以及在此基础上设定的服务效率分级规则如表2所示。
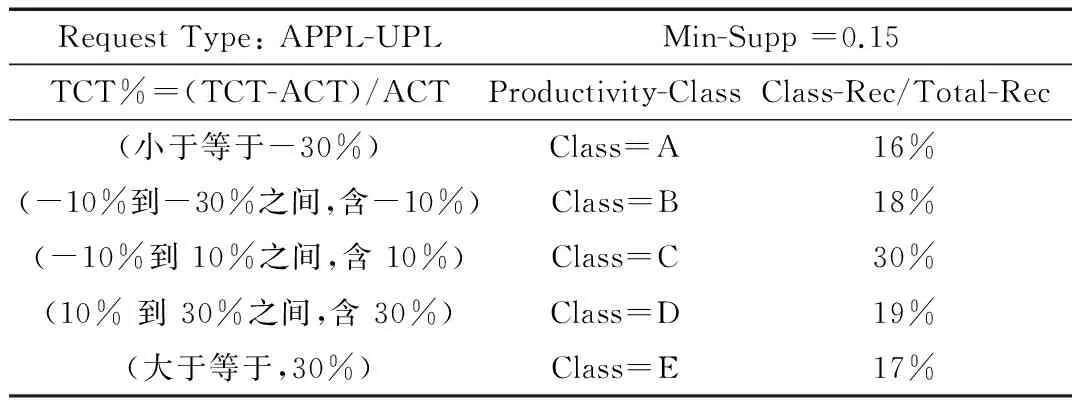
表2 服务效率分级规则示例
(4)根据步骤(3)确定的服务效率分级规则对(ACT)进行离散化处理。假设根据表2的规则对数据进行离散化处理,处理后的结果如表3所示。
经过上述步骤,数值型的总服务处理时间就转换成了布尔型的服务效率等级。
2 银行服务管理日志挖掘
针对大量的并发操作,银行服务管理系统往往采用了并行的处理架构以应对数据增加带来的性能瓶颈问题。因此,系统产生的流程日志文件也分布在多个服务器上。如果将位于各个服务器上的流程日志文件采集集成到一个服务器上处理,则随着数据量的不断累积和增加,最终导致处理和挖掘效率的直线下降。与此同时,Apriori挖掘算法在扫描储存了大量数据的数据库表时也会消耗大量的资源。

表3 数据离散化处理后的数据示例
基于上述问题,本文充分利用银行服务管理系统本身的并行架构,采用基于并行处理的Apriori算法[16]。假设表4是处理后的完整数据集合,若选择0.4作为最低支持度阈值,则可应用并行Apriori算法挖掘员工序列与服务效率之间的关联关系。
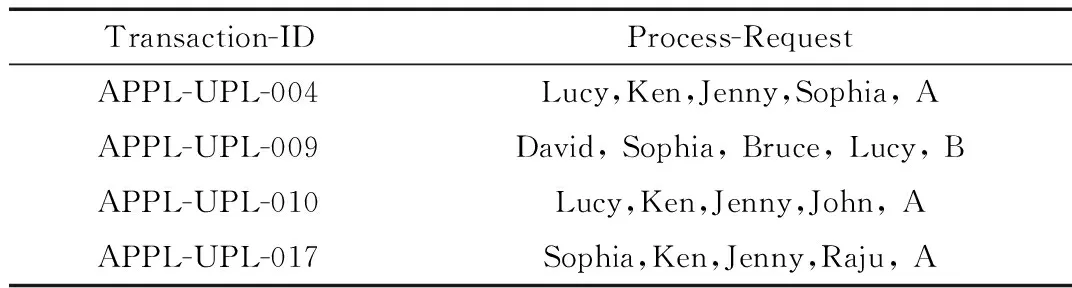
表4 局部预处理后的数据集合
(1)生成局部频繁集
使用典型的Apriori算法对每个流程日志文件进行关联分析,分别得到局部的频繁项目集。
(2)使用并行的Apriori算法计算关联规则
首先将所有局部频繁项集进行合并,组合成全局候选的频繁项集合。然后删去其中不满足最小支持度的集合,得到全局的频繁项目集合。获得所有频繁集的非空子集并计算子集的置信度,得到关联规则集。最后,选择与业务需求相关的关联规则,即(员工组合)=>(服务等级)形式的规则。
3 实验
为了验证使用并行Apriori关联规则挖掘员工组合与服务处理效率之间关联关系的效果,这里选择了银行服务管理系统在一个月内产生的流程日志文件进行实验。由于不同类别的服务请求处理的流程和所涉及的处理员工差异较大,因此仅提取包含处理客户申请无抵押贷款的服务请求的数据进行实验分析。剔除未完成的服务处理请求记录,满足条件的数据集大约有15万条记录,其中根据默认的服务等级划分后的数据分布如表5所示。
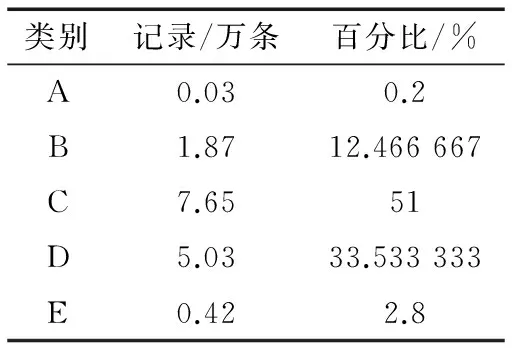
表5 按默认规则划分服务等级后的数据分布表
服务等级(Class=A)的记录由于所占比例太小,在寻找频繁项集的过程中,会因为不符合最小支持度阈值而被过滤。而如果设定较小的最小支持度阈值,则会带来性能的问题,并挖掘出大量的无用规则。因此排除服务等级为D和E的记录,并根据选取的最小支持度对服务等级重新划分。
在完成对数据的预处理后,使用分布式处理的每一个处理节点都加载包含了对常见的关联规则算法实现的R扩展包arules后,调用rules包中的apriori函数对处理后的数据做关联分析。指定合适的最小支持度和最小置信度后,获得满足条件的关联规则的部分结果输出如下:
1{E1=John,E2=Lisa,E3=Jenny,E4=Raju}=>{Class=D} 0.154545450.7500000 5.892857
2 {E1=John, E2=Lisa, E3=Jenny, E4=Rajesh} => {Class=C} 0.16363636 0.4285714 2.619048
3 {E1=John, E2=Lisa, E3=Jenny, E4=Rajesh} => {Class=B} 0.172727270.4285714 2.964286
4 {E1=John, E2=Lisa,E3=Jenny,E4=Sophia}=>{Class=A} 0.154545450.7500000 2.291667
5 {E1=David, E2=Ken, E3=Bruce,E4=Sophia}=>{Class=A} 0.145454550.8888889 2.716049
... ...
上述结果所对应的包含服务等级A的规则如下:
1.{E1=John,E2=Lisa,E3=Jenny,E4=Sophia} => {Class=A} conf:(0.7500000)
2.{E1=David,E2=Ken,E3=Bruce,E4=Sophia} => {Class=A} conf:(0.8888889)
... ...
如果仅仅使用Apriori关联算法,在计算支持度时需要多次扫描数据库,而Eclat算法对候选n项集进行支持度计算时不需再次扫描数据库。因此通过应用Eclat关联规则算法对实验数据进行关联规则挖掘,通过对比挖掘出的结果验证规则的有效性,并比较它们在性能上的差异。
在加载包含了对常见的关联规则算法实现的R扩展包arules后,调用rules包中的eclat函数对处理后的相同数据做关联分析。指定相同的最小支持度和最小置信度后,获得满足条件的关联规则集合。
基于本实验的数据集,且在相同实验的环境下,加载R扩展包arules后,通过分别调用apriori函数和eclat函数以实现Apriori关联规则挖掘和Eclat关联规则挖掘,然后获取两者所消耗的时间并进行比较。结果表明,两者在性能上差异很小。其中,采用Eclat算法进行挖掘比采用非并行Apriori算法进行挖掘快2 min得出结果,并行Apriori算法的时间明显减少,其中并行算法使用3台Dell R530/2.83 Hz/8 GB服务器,其他使用单台服务器配置。修正最小支持度阈值,得到表6所示的实验结果。
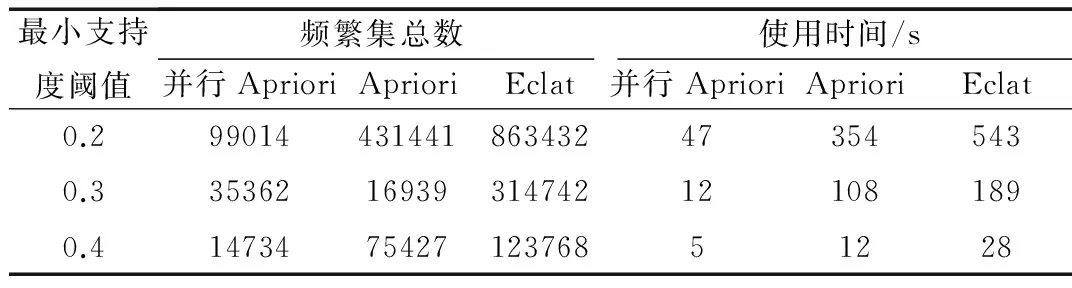
表6 修正最小支持度阀值计算结果
因此基于目前银行服务管理系统产生的流程数据,采用并行Apriori关联规则算法进行挖掘,取得了比较理想的效果。
4 结论
协作的紧密程度影响着服务处理的效率,分配协作紧密度高的员工在一起合作可以提高服务的效率。哪些员工在一起合作具有紧密的协作关系,能提供高效的服务,蕴藏在流程日志数据中。本文分析了如何有效地应用并行Apriori算法从流程日志中挖掘出服务处理员工序列与服务效率之间的关系。将挖掘出的关系映射成对服务分配的规则,使得系统根据规则将协作关系紧密的员工分配在一起共同处理服务请求,提高了服务效率,取得了合理的应用效果,实现了银行服务管理系统中服务分配的智能化。如何应用数据挖掘技术更深层次地去挖掘蕴含在流程日志中的有用模式或知识,是需要进一步思考的问题。
[1] LNMON W H.数据仓库(第3版)[M].王志海,译.北京:机械工业出版社,2005.
[2] LAROSE D T. Discovering knowledge in data: an introduction to data mining[M].New Jersey: Wiley-Interscience,2005.
[3] 赵卫东.智能化的流程管理[M].上海:复旦大学出版社,2014.
[4] van der AALST W M P, WEIJTERS T, MATUSTER L.Workflow mining:discovering process models from event logs[J] .IEEE Transactions on Knowledge and Data Engineering, 2004,16(9):1128-1142.
[5] BERSON A, SMITH S, THEARLING K. Building data mining applications for CRM[M]. New York: McGraw-Hill Companies, 2000.
[6] ROMBEL A. CRM shifts to data mining to keep customers[J].Global Finance,2001,15(11):97-98.
[7] WEISS G M. Data mining in telecommunications[A].The data mining and knowledge discovering handbook[M].Springer US,2005:1187-1201.
[8] GROTH R.Data mining:building competitive advantage[M].Prentice Hall,1999.
[9] 赵卫东,刘海涛.流程挖掘在流程优化中的应用[J].计算机集成制造系统,2014,20(10):2633-2641.
[10] PARVATHY A G,VASUDEVAN B G,KUMAR A,et al.Leveraging call center logs for customer behavior prediction[A]. ADAMS N M.Advances in Intelligent Data Analysis VIII-8th International Symposium on Intelligent Data Analysis[C].Lyon: Springer-Verlag,2009,57772:143-154.
[11] WRITTEN I H, FRANK E.Data mining practical machine learning tools and techniques[M].Burlington:Morgan Kaufmann,2011.
[12] LIN S W, SHIUE Y R, CHEN S C,et al.Applying enhanced data mining approaches in predicting bank performance:A case of Taiwanese commercial banks [J].Expert Systems with Applications, 2009,36(9):11543-11551.
[13] AKHIL K,DIJKMAN R M,SONG M.Optimal resource assignment in workflows for maximizing cooperation[A].Business Process Management (Proceedings of the 11th International Conference on Business Process Management)[C] .Berlin Heidelberg: Springer-Verlag,2013:235-250.
[14] Wu Xindong, KUMAR V.The top ten algorithms in data mining[M].USA:Chapman and Hall/CRC,2009.
[15] Han Jiawei.Data mining:concepts and techniques[M].Burlington:Morgan Kaufmann,2011.
[16] YE Y, CHIANG C C. A parallel apriori algorithm for frequent itemsets mining[C]. Fourth International Conference on Software Engineering Research, Management and Applications, 2006, IEEE, 2006: 87-94.
卢盛祺(1978-),通信作者,男,博士,主要研究方向:数据挖掘、电子推荐。E-mial:shengqilu@fudan.edu.cn。
李远刚(1976-),男,博士,主要研究方向:数据挖掘。
管连(1972-),男,硕士,主要研究方向:数据挖掘。
The application of process mining to bank service management
Lu Shengqi1,2,3,Li Yuangang1,2,Guan Lian4,Zhou Yun3
(1.School of Information Management and Engineering,Shanghai University of Finance and Economics, Shanghai 200433, China; 2.Shanghai Key Laboratory of Financial Information Technology, Shanghai University of Finance and Economics, Shanghai 200433, China; 3.Software School, Fudan University, Shanghai 200433, China; 4.International Business Machine China Co., Ltd. ,Beijing 100101, China)
With the development of bank service information, the bank faces the problem how to extract valuable information from a large amount of service data to help banks improve service efficiency. In the practical use of the management systems of banks, because of its specialty of having lots of concurrency operation and producing many event logs, we choose the parallel association algorithm to analyze the process of bank management. Compared with the traditional Apriori algorithm, this paper uses the parallel algorithm given that the bank management system has many concurrency operations. As a result, it solves the problem that the efficiency of system declines rapidly with the increase of the number of event logs. Management systems of the bank generate much log data to record bank’s staff work every day. In this paper, the parallel Apriori algorithm is applied to find association rules in the service process log to identify efficient team of employees. As a result, this algorithm improves the efficiency of bank service.
process logs mining; association rules; staff collaboration; organization optimization; parallel Apriori algorithm
国家自然科学基金(71271126);教育部博士点专项科研基金(20120078110002)
TP391
ADOI: 10.19358/j.issn.1674- 7720.2016.18.026
2016-04-18)
