面向工业4.0的多表架构与NoSQL大数据集成的数据存储策略研究
2016-10-28文棒棒曾献辉
文棒棒,曾献辉
(1. 东华大学 信息科学与技术学院,上海 201620;2.数字化纺织服装技术教育部工程研究中心,上海 201620)
面向工业4.0的多表架构与NoSQL大数据集成的数据存储策略研究
文棒棒1,2,曾献辉1,2
(1. 东华大学 信息科学与技术学院,上海 201620;2.数字化纺织服装技术教育部工程研究中心,上海 201620)
工业4.0环境下,生产现场的监测数据除了需要实时显示与分析外,还需要作为历史记录进行保存。面对海量的生产数据,现有的数据库技术已经很难满足该要求。提出了一种基于传统数据库多表架构与NoSQL大数据库相结合的新型数据存储方案。该方案基于传统数据库的多表架构实现实时数据的分布式存储,同时将历史数据迁移至NoSQL大数据库,解决了工业4.0下的海量数据存储问题。最后给出了某企业基于SQL Server和MongoDB的实际应用,验证了本文方法的正确性和有效性。
多表结构;NoSQL大数据库;数据迁移;MapReduce分析
引用格式:文棒棒,曾献辉.面向工业4.0的多表架构与NoSQL大数据集成的数据存储策略研究[J].微型机与应用,2016,35(18):6-9.
0 引言
进入21世纪以来,随着网络信息技术、智能科学的蓬勃发展,信息化和智能化正逐步融合到工业生产中,向人们展示着工业4.0时代的到来[1]。在工业4.0 时代,企业在生产过程中累积的大量与生产监测相关的数据汇聚成数据的海洋,这些数据不仅种类繁多同时产生速度快、价值密度低。要充分利用这些数据,就需要企业不仅能够实现这些数据的实时显示与分析,同时又能够对产生的历史数据进行有效的存储与分析。本文针对此问题,提出了一种基于传统数据库多表架构和大数据相结合的数据存储策略,该方法解决了工业数据的实时存储,同时可实现对海量历史数据的有效保存与分析,以帮助企业充分利用这些数据。
1 工业数据存储技术
工业4.0时代的到来,也意味着工业生产大数据时代的到来[2]。一般意义上讲,大数据具有数据量大、数据种类多、商业价值高、处理速度高等特点。在此基础上,工业生产中的数据还有两大特点:一是准确率高,二是实时性强。工业生产中重要的应用场景是实时监测、实时预警、实时控制。一旦数据的采集、传输和应用等全处理流程耗时过长,就难以在生产过程中发挥其价值[3]。如图1所示,在多个采集工作站进行数据采集时,每天产生的数据量都是非常大的,此时不仅要保证这些数据的实时性,同时还需要一种存储技术能够实现这些数据的历史保存。传统的数据库存储技术主要有两种:一种是采用数据直接存放的方式,即单一表格存储;另一种则是采用数据库多表架构的方式,即多表存储。
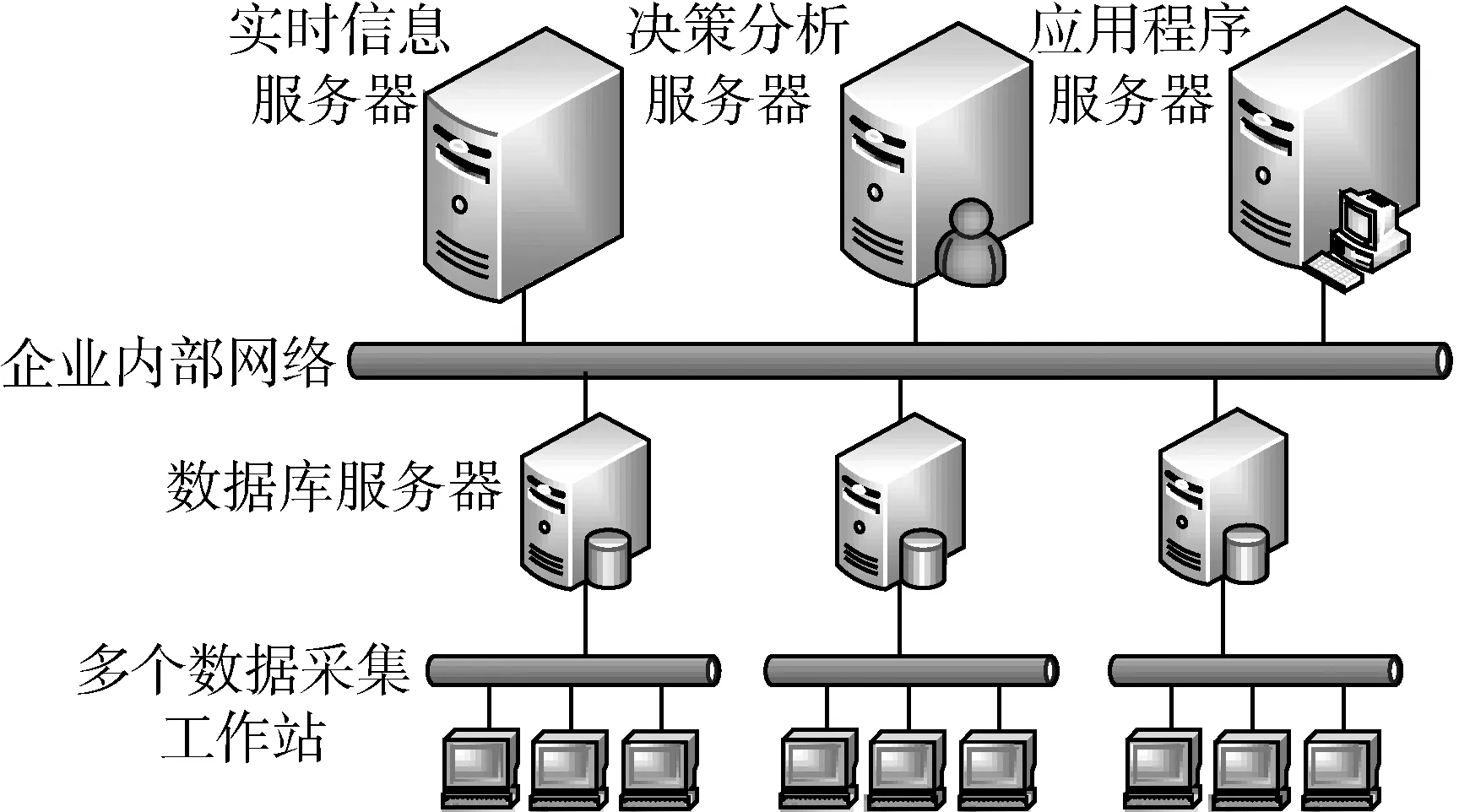
图1 工业生产数据网络拓扑图
1.1数据库单表直接存放形式存储
传统的数据库存储方法大多采用数据的直接存放形式,即单一表格形式。这种方法是将所有数据都直接存放在一个单表里,表中包括数据的所有字段和记录。该方法的优点是设计简单,使用非常方便,能够较好地实现数据的存储。但是由于只是单个表格,当单表数据量非常大时,数据库的访问速度会急剧下降,会使得系统变得相当不稳定,此时若继续对数据进行查询与插入,甚至可能出现死机等不能运作的情况。因此这种方法不适合大量数据的实时存储。
1.2数据库多表分布式存储
不同于数据的直接存储方式,分表,顾名思义,就是通过一系列的切分规则将数据分布到不同的表中,如按照自然时间来分,可分为按日生成表、按月生成表和按年生成表。分表不仅能够更好地完成大量数据的分布式存储,增大数据库的存储容量,而且减少了数据库的负担,提高了数据库的效率,特别是提高了单个表的增删改查效率,能够实现数据的实时显示与分析。但是,对于分表后存储的历史数据,在对其进行统计分析时往往需要遍历所有的表格进行多表之间的联合,查询速度会相当慢,不便于实现历史数据的有效分析。
1.3NoSQL大数据库存储
随着工业生产数据的不断增加,关系型数据库在面对大量历史数据的存储和访问等问题上逐渐暴露出一些不足之处。为了弥补这些不足,NoSQL数据库应运而生。NoSQL[4](Not Only SQL)是对传统关系型数据库以外的非关系型数据库的统称。NoSQL数据库凭借其不固定的键值对结构打破了传统数据库中表与表之间的关联问题导致的性能瓶颈,大大减少了对历史数据进行存储、计算、查询等操作在时间和空间上的开销。但是,在实时数据的分析与显示方面,NoSQL往往显得力不从心,数据处理不够快速,且不能直观显示处理后的结果。
2 多表架构与大数据集成的新的数据存储策略
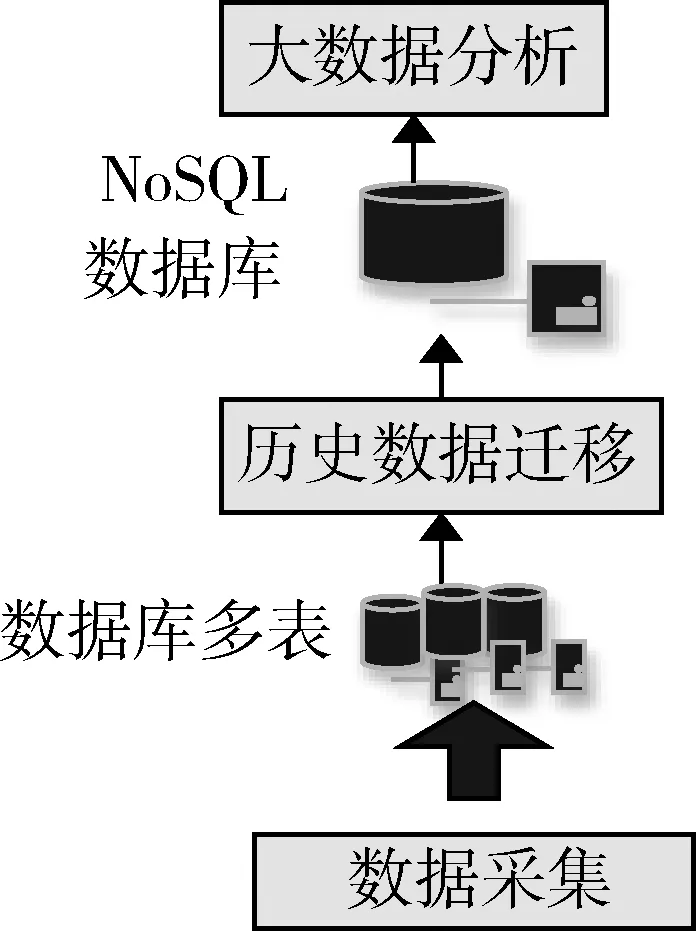
图2 传统数据库多表与NoSQL结合的数据存储流程
面对工业生产上的实时数据,不仅要求能够对其进行实时显示与分析,同时还要将其作为历史数据进行保存。对此,现有的数据库方法已经无法满足。本文提出一种基于传统数据库多表架构与NoSQL大数据库相结合的新型数据存储方案,该方案利用传统数据库的多表方法实现数据的实时存储,并实现对数据的实时操作与查询显示。此外,对于累积的历史数据,则利用数据迁移技术迁移至NoSQL数据库进行历史保存,不仅解决了海量数据的存储问题,而且可以利用大数据技术对历史数据进行深层次的分析处理,以实现生产数据的最大化利用。图2所示为传统数据库与NoSQL大数据库相结合的数据存储方案的处理流程。
2.1传统多表架构实现实时存储与访问
利用传统数据库的多表架构可以实现数据的实时存储与访问,而多表的实现则主要利用存储过程方法。存储过程,即一组预先写好的能实现某种功能的一段程序,将其保存在数据库中,以后若要实现该功能则直接可调用该程序来完成[5]。因此,只要预先定义好存储过程,当对数据进行存储时则可直接进行调用,从而将数据实时地存储在不同的表格里。而对于数据的访问,同样可以将相应的操作通过建立存储过程来实现。利用多表架构一方面能够保证数据的实时性存储要求,另一方面将数据存储在多个表里可以提高每个表的访问速度,便于对表中的数据进行实时显示与相应的增删改查处理。
2.2大数据技术实现历史记录保存与分析
数据库多表架构解决了数据的实时性问题。但是,对于如何将这些海量数据作为历史记录进行有效保存同时可以实现对其深层次的分析与利用,传统的数据库方法已经无法满足要求。此时,大数据存储技术的优势则脱颖而出。NoSQL数据库具有高水平扩展能力和低端硬件集群,可以很好地应对海量数据的存储问题。利用数据迁移技术,即通过不同的接口函数访问不同的数据库,实现历史数据从传统数据库向NoSQL大数据库的迁移。而将数据存储在NoSQL数据库后,可利用大数据分析技术实现历史记录的分析处理。例如MapReduce[6-7],它是一种并行编程模型,用于大规模数据集的并行运算,其特点是简单易学,适用广泛,能够降低并行编程难度,程序员只需实现其中的map函数和reduce函数,而具体操作则交由MapReduce自身的框架来处理。
3 多表架构与NoSQL大数据存储策略的实现与应用分析
为了验证本文所提出方案的正确性和有效性,本文结合了某智能制造厂在生产过程中机器产生的大量数据来对其进行分析与应用。根据对智能制造厂生产现场的分析,得知其存在多个车间,且每个车间都有上千台机器,每台机器在工作时都会产生大量的数据。为了能够充分利用这些数据,首要的任务就是要解决如何把这些数据实时地存储下来。通过比较分析,最终采用传统的SQL Server数据库对实时数据进行存储,而对于历史数据的存储与分析则采用NoSQL数据库中的MongoDB数据库。
3.1实时数据的存储与分析
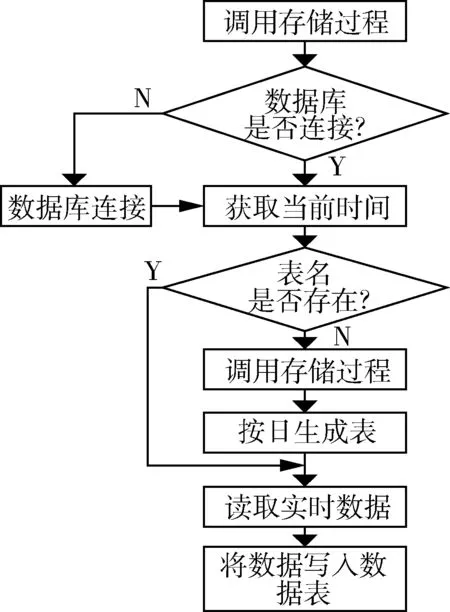
图3 实时数据多表存储的处理流程
在数据的实时存储方面,采用SQL Server数据库多表架构的存储方法。该方法首先将预先定义好的存储过程存储在SQL Server数据库中,在对数据进行存储之前,先调用存储过程检测数据库是否连接,若未连接,则要求连接;连接以后获取当前时间检测数据表是否存在,若不存在则调用其他存储过程生成当前时间的数据表;当数据表存在后则可进行数据的实时性读写与插入。数据的整个存储过程都是调用预先定义好的语句,通过存储过程实现多表的按日生成,避免了传统数据存储时的繁琐语句。同时若需要对数据进行实时查询与显示,同样可通过定义好的SQL语句生成存储过程实现对批量数据的增删改查。图3所示为利用存储过程实现实时数据多表方式的存储流程。
3.2历史数据的迁移与存放
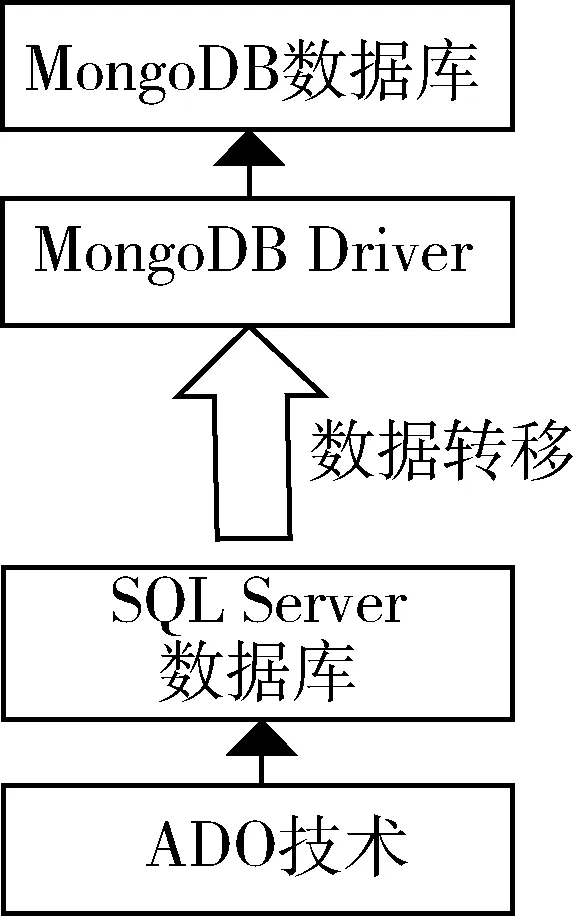
图4 历史数据的迁移与存放处理流程
对实时数据进行SQL Server多表存储和实时分析后,利用数据迁移技术将数据迁移至NoSQL数据库进行存储和分析。MongoDB[8]数据库是NoSQL数据库的一种,其存储结构为典型的key-value键值对型,而且它最大的特点是具有强大的查询功能,支持通用辅助索引和复合索引,能够进行多种快速查询,同时还支持各种分析工具,可以很好地对数据进行统计分析。因此,可以通过传统数据库的ADO技术来访问SQL Server数据库,将SQL Server中的数据转移到MongoDB数据库中,实现海量历史数据的存储。如图4所示,首先进行SQL Server的连接,其连接形式为:
string conStr = "server=(local); Initial Catalog = Textile; Integrated Security = true";
SqlConnection connection = new SqlConnection(conStr);
SqlCommand cmd = connection.CreateCommand();
connection.Open();
在连接数据库后可自行设置SQL命令将数据库中的数据转移到MongoDB中,在此之前需要利用MongoDB Driver 进行MongoDB数据库的连接,其实现方式为:
string connString = "mongodb://127.0.0.1:27017";
MongoServer server = MongoServer.Create(connString);
MongoDatabase mydb = server.GetDatabase("mydb");
MongoCollection test = mydb.GetCollection("test");
3.3基于MapReduce的大数据分析
MongoDB作为NoSQL大数据库的一种,其除了可以实现海量历史数据存储以外,还提供了多种灵活和强大的数据聚合工具,其中就包括MapReduce。图5所示为MapReduce在MongoDB数据库中的操作流程。
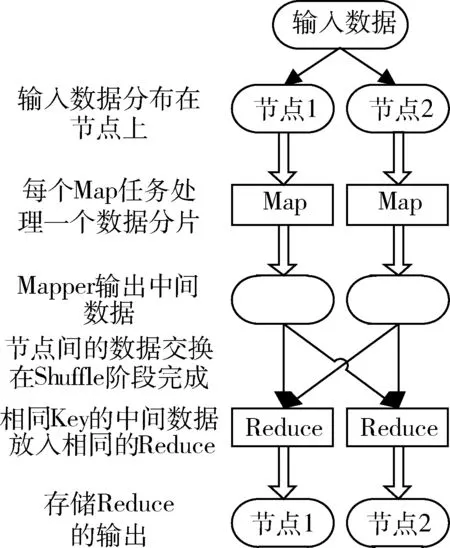
图5 MapReduce的处理流程图
为了更清楚地了解MapReduce编程模型的强大之处,本文结合智能制造厂生产现场的监测数据,利用MapReduce,通过设备在10天内的开关机状态计算出设备的生产效率值,从而帮助企业更加合理地调度生产资源实现资源的最大化利用。图6所示为处理流程图。
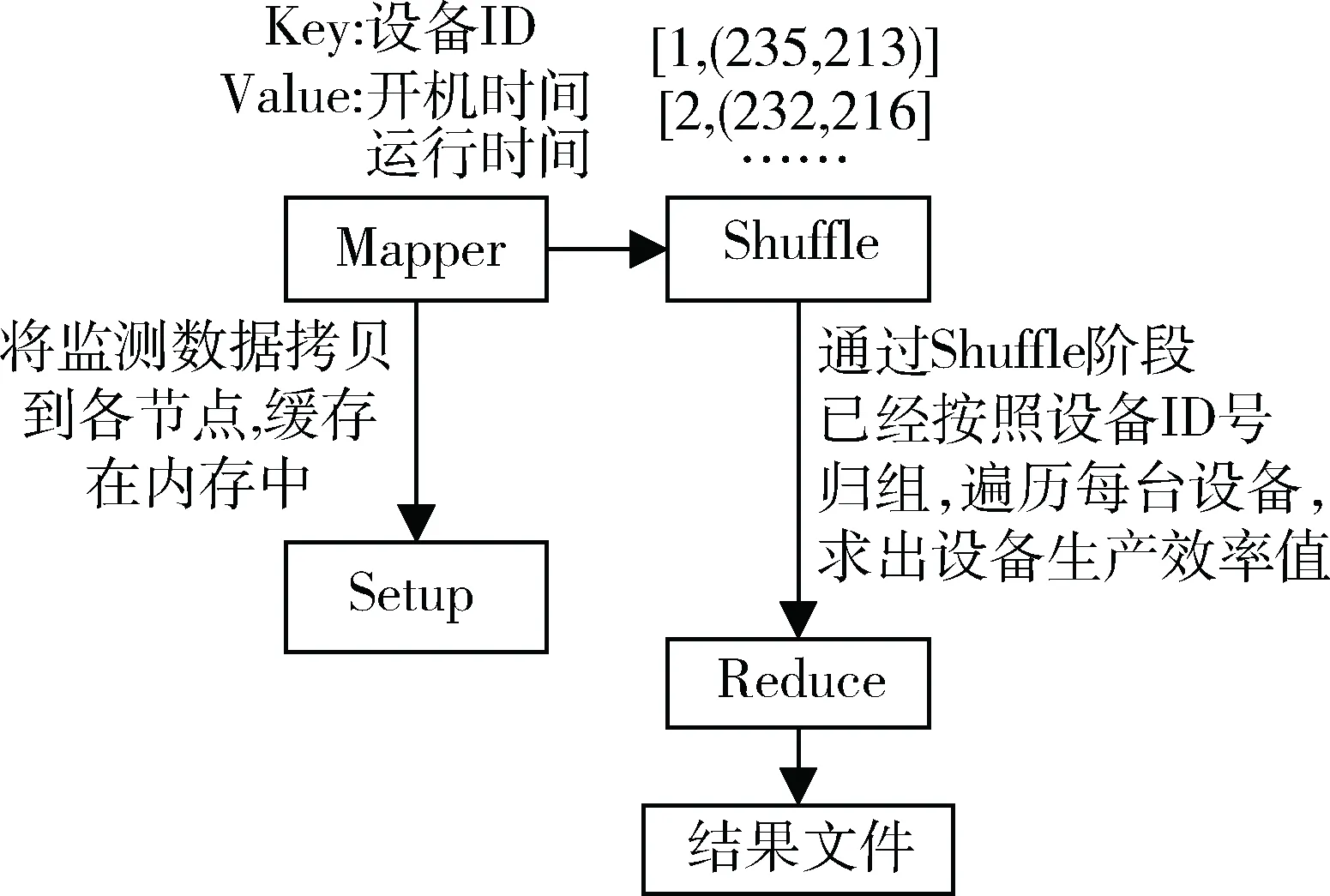
图6 MapReduce计算设备生产效率处理流程图
4 结论
本文针对在工业4.0环境下生产过程中产生的大量数据,提出一种基于传统数据库多表架构和NoSQL大数据结合的新型存储策略,不仅完成了生产数据的实时存储与实时访问,而且利用数据转移技术将历史数据转移至NoSQL大数据库,解决了海量历史数据的存储问题,同时通过大数据分析技术实现对历史数据的有效分析。最后通过某智能制造厂生产现场的监测数据,验证了本文提出方法的正确性和有效性。
[1] 程晓蕾. 工业4.0架构下的工业大数据的需求、环境及服务化[J].赤峰学院学报, 2015,31(4):14-15.
[2] 沈雁, 戴瑜兴, 汤睿. 基于嵌入式数据库的分布式大坝监测数据汇聚器设计[J].电子技术应用, 2011,37(5):39-41.
[3] FAZIO M, CELESTI A, PULIAFITO A, et al. Big data storage in the cloud for smart environment monitoring[J]. Procedia Computer Science, 2015(5):500-506.
[4] 潘洪志. 高性能NoSQL存储系统的研究与实现[D].长春: 吉林大学, 2014.
[5] 丌文娟. 对SQL Server存储过程的研究与应用[J].廊坊师范学院学报, 2010,10(6):34-37.
[6] 谢桂兰, 罗省贤. 基于Hadoop MapReduce模型的应用研究[J].微型机与应用, 2010,29(8):4-7.
[7] MAITREY S, JHA C K. MapReduce: simplified data analysis of big data[J]. Procedia Computer Science, 2015(7):563-571.
[8] 吕林. 基于MongoDB的应用平台的研究与实现[D]. 北京:北京邮电大学, 2015.
Research on data storage strategy for Industry 4.0 using multi-table schema and NoSQL big data technique
Wen Bangbang1,2,Zeng Xianhui1,2
(1.College of Information Science and Technology, Donghua University, Shanghai 201620, China;2.Engineering Research Center of Digitized Textile &Apparel Technology, Ministry of Education, Shanghai 201620, China)
In Industry 4.0 environment, the monitoring data of production site needs to be real-timely displayed and analyzed, and also needs to be saved as a historical record. In the face of massive production data, the existing database technology is difficult to meet the requirements. This paper proposes a new data storage solution based on the combination of traditional database multi-table schema and NoSQL large database. It can not only implement the distributed storage of real-time data based on the traditional database multi-table schema, but also migrate the historical data to the NoSQL large database to solve the problem of massive data storage under Industry 4.0. Finally, through a practical application of an enterprise based on SQL Server and MongoDB, the validity and effectiveness of this method is verified.
multi-table schema; NoSQL large database; data migration; MapReduce analysis
TP392
ADOI: 10.19358/j.issn.1674- 7720.2016.18.001
2016-03-29)
文棒棒(1992-),通信作者,男,硕士研究生,主要研究方向:数据库应用技术、大数据分析。E-mail:1043967181@qq.com。
曾献辉(1974-),男,博士,副教授,主要研究方向:大数据挖掘、智能优化问题、决策与分析。
