随机森林倾向性评分方法及其在药品不良反应信号检测中的应用*
2016-10-26第二军医大学卫生统计学教研室200433
第二军医大学卫生统计学教研室(200433)
张新佶 张天一 许金芳 叶小飞 钱 维 贺 佳△
随机森林倾向性评分方法及其在药品不良反应信号检测中的应用*
第二军医大学卫生统计学教研室(200433)
张新佶张天一许金芳叶小飞钱维贺佳△
【提要】目的探讨利用随机森林倾向性评分法控制混杂因素的基本思想和步骤,及其在药品不良反应信号检测中的应用。方法利用随机森林计算给定危险因素的条件下研究对象服用双膦酸盐的概率,而后分别通过倾向性评分1:1匹配,1:M匹配和回归调整法控制性别、年龄等混杂因素,分析服药双膦酸盐与骨折发生风险的关系,并与logistic回归倾向性评分法对应结果进行比较。结果随机森林倾向性评分法与logistic回归倾向性评分方法的结果是一致的。其中,倾向性评分1:1匹配样本量损失较大,且与1:M匹配和回归调整法的结果相差较大。结论随机森林倾向性评分法能有效控制药品不良反应信号检测过程中的混杂因素,可以与logistic回归倾向性评分法所得结果相互验证,提高结果的可靠性;但1∶1匹配可能不适用于药品自发呈报系统数据。
倾向性评分随机森林不良反应检测混杂因素
药品上市后不良反应信号监测主要依赖于药品自发呈报系统数据,由于药品上市流通后,无法像随机对照试验那样对观察对象进行随机分配,在分析过程中难免受到混杂因素的影响,导致药品不良反应分析结果的准确性面临挑战。
近年来,倾向性评分(propensity score,PS)作为一种新兴的控制观察性研究中混杂因素的方法,越来越受到研究者的重视[1-3]。倾向性评分法是在1983年由Rosenbaum和Rubin提出的一种均衡组间协变量的方法[4]。它首先计算出在给定协变量的条件下观察对象被分到暴露组的概率,将其作为倾向评分值,然后根据得出的倾向评分值作为匹配或分层的依据从而实现对观察对象的事后随机化。由于倾向性评分值综合了所有已观测到的混杂因素,能够去除这部分混杂因素带来的偏倚,故在不存在未观测到的混杂因素的前提下,倾向性评分法能够实现对观察性研究中暴露因素的处理效应的无偏估计[5]。目前最常用计算个体倾向评分值的方法仍然是logistic回归模型,该方法具有模型简单、容易实现、结果易于解释等明显优势。然而,logistic回归模型有其特定的适用条件和局限性,因此,在利用logistic回归模型计算倾向评分值时应充分考虑数据是否满足相应条件[6]。近年来,很多国外的研究者开始探索采用机器学习方法计算倾向性评分值,常用的方法有神经网络、支持向量机、随机森林和Boosting等。Lee等研究者比较了各种方法在倾向性评分时的性能,认为综合的分类算法例如随机森林、Boositng等具有一定的优势,特别是在变量较多而样本量偏小或变量间存在多重共线性时,使用综合的分类算法计算倾向性评分值产生的偏倚更小,结果更为稳定[7]。
由于药品自发呈报系统的数据量巨大,且在药品不良反应信号检测过程中缺乏金标准,单一的方法进行数据挖掘时很容易得到大量的有统计学意义的药品-不良反应组合,给进一步的临床评价实施带来困难。因此,有必要采用不同方法进行相互验证以排除假阳性信号,提高信号检测的效率。本文拟介绍利用随机森林计算倾向性评分值的基本思想,以FDA不良事件报告系统中的实际数据为例,介绍随机森林倾向性评分法在药品不良反应信号检测过程的应用步骤及实现代码。该方法能控制药品不良反应信号检测过程的混杂因素,可与logistic回归倾向性评分进行相互验证,以减少假阳性信号;或者作为logistic回归倾向性评分的一种补充,在数据不满足其适用条件时进行有效分析。
随机森林倾向性评分法的基本思想
1.随机森林的构建[8-10]
(1)如图1所示,应用自助法(bootstrap)重抽样技术有放回地随机抽样N次,每次从原始数据中抽取约2/3的数据生成一个自助样本集,作为一棵分类树的训练数据,并由此数据构建分类树,每次未被抽到的1/3样本组成N个袋外数据,作为测试数据,用于估计分类误差。
(2)每个自助样本集用于建立一棵决策树或者条件树。在生成每棵树的过程中,一般在每个节点处从全部变量中随机抽取M个变量,然后在M中选择一个最具有分类能力的变量对数据进行分类。分裂准则可采用Gini不纯度、熵不纯度等等方式。变量分类的阈值通过检查每一个分类点确定。
(3)利用每棵分类树对数据进行分类与判别,随机森林总的分类结果按每棵分类树的投票多少而定。袋外数据为测试集,用于评价每棵树的性能。
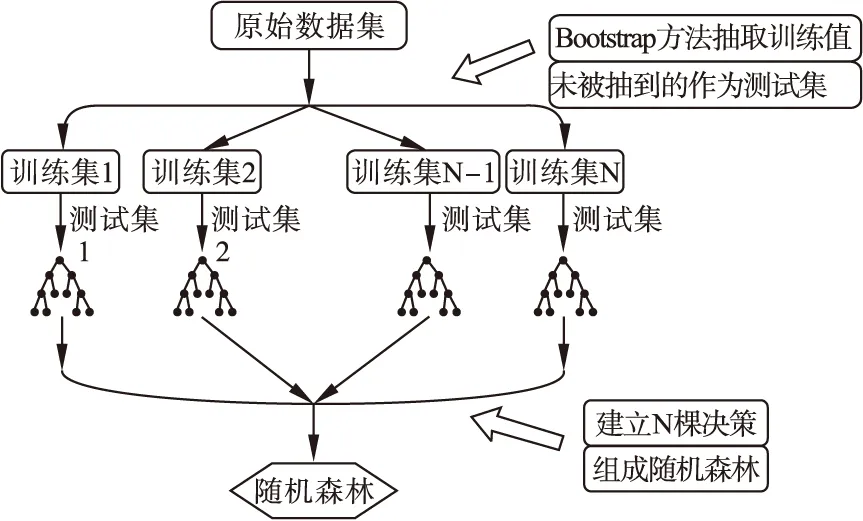
图1 构建随机森林示意
2.利用随机森林计算倾向性评分值
(1)随机森林是由树组成,根据生成方式的不同可以将树分为决策树和条件树。“树”其实就是一种树型分类方法,目的是将研究人群通过设定的危险因素分成若干个相对同质的亚人群。其结构类似一棵倒置的树,由主干和许多分支组成。在树中有许多节点即树结。如图2所示,椭圆形框为中间结,表示各项危险因素(或协变量)。长方形框为终止结。每个树结中的数字为分类结果,树结间有实线连接,在椭圆形框下方标有判别条件。终止结内为判别到该类别的例数。每棵树都给出一定条件下研究对象被分配到暴露组(如感染乙肝组)或对照组(如未感染乙肝组)的分类。
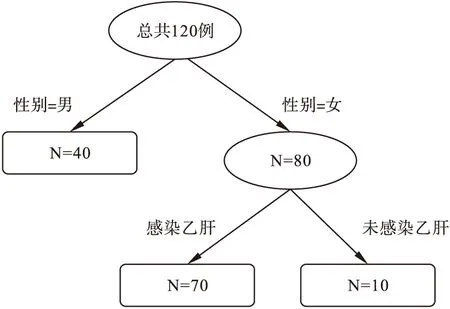
图2 随机森林中单棵树对人群的分类示例
(2)随机森林根据某个研究对象的特征(即协变量的取值),将所有单棵树的分类结果综合起来进行判定,计算其被分到暴露组或对照组的概率,得到一个综合倾向性评分值。如图3所示,随机森林中总共建立了n棵树,每棵树都根据该研究对象的特征进行了一次判定,共判断了n次。其中n2棵树判断某个研究对象属于1类(假设1类代表被分到暴露组),那么该研究对象被分到暴露组的概率(即倾向性评分值)为n2/n,同理,可计算该研究对象被分到对照组的概率为n1/n。
由于随机森林法是综合分类器得出的结果,因而比一般的分类树或决策树具有更高的准确性,得出的分类概率也相对较可靠。同时,随机森林对数据的样本量不作限制,在小样本时同样能发挥较好的作用。
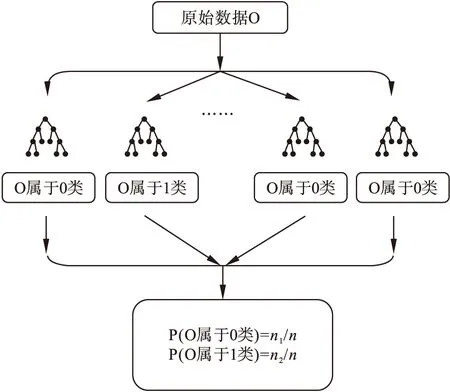
图3 随机森林计算倾向性评分值
实例应用及代码实现
1.实例采用FDA不良事件报告系统中2011年1月1日至2012年12月31日两年内上报的有关“双膦酸盐-骨折”不良反应监测数据。本实例中,拟研究双膦酸盐与骨折之间的关系,暴露因素为是否服用双膦酸盐,结局变量为是否发生“骨折”,二者皆为二分类变量。由于每份报告中包含多个“药品-不良事件”的组合,进行单药分析时有些报告可能被拆成了几例甚至几十例进行分析。进行拆分无疑增加了对照的例数,并且对照之间不独立。因此,本研究将每份报告作为1例进行分析,如果报告了目标药品双膦酸盐则作为1例暴露进行分析,反之则作为1例对照。从FDA不良事件报告系统中选择与结局或暴露变量有关的协变量,结合数据填写完整情况,选择5个协变量用于演示随机森林倾向性评分法的应用过程,包括年龄、性别、体重和报告地区和不良反应触发时间。分析数据集中共4942份报告,其中暴露组样本量为916份,对照组为4026份。
2.分别利用logisitic回归和随机森林算法计算倾向性评分值,并将结果输出到数据集中。随机森林计算倾向性评分的R软件代码如下(#后文字为注释):
> dataset <-read.table(“H:/data.txt”,header=T)#导入数据集
> y_c<-factor(dataset$Y,levels=0:1)#将暴露变量设置为0-1变量
> dataset<-cbind(dataset,y_c)
>result<-randomForest(y_c~ X1+X2+…X5,data=dataset,ntree=500,mtry=1,replace=FALSE,nodesize=5,importance=TRUE)#用随机森林计算倾向性评分值,X1~X5分别代表年龄、性别、体重、报告地区和不良反应触发时间等5个协变量
> ps<-result$vote #将PS值导出到数据集
> write.table(ps,file=“H:/ps.txt”,row.names=F,quote=F)
3.利用倾向性评分控制混杂因素后,应用logistic回归分析 “双膦酸盐-骨折”是否为潜在不良反应信号。控制混杂因素的方法包括倾向性评分1∶1匹配,1∶4匹配,回归调整(表1)。
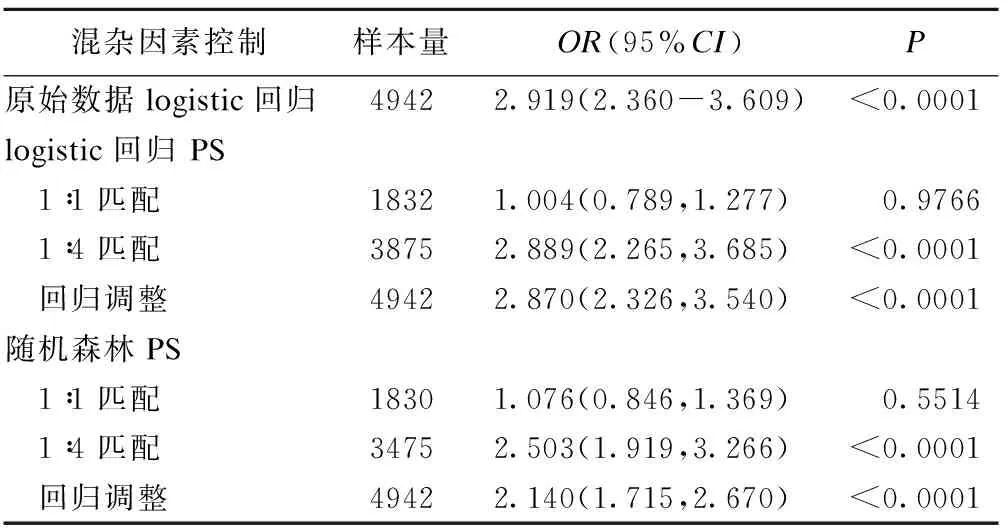
表1 双膦酸盐与骨折之间的关系分析
利用logistic回归倾向性评分和随机森林倾向性评分控制混杂因素后进行分析的结果是一致的,两种方法的计算结果可以相互验证,为进一步的分析提供更加稳健的结果。值得注意的是,1∶1匹配后数据提示双膦酸盐与骨折之间没有关系,而1∶4匹配和回归调整均提示“双膦酸盐-骨折”为可疑信号。这可能是由于自发呈报系统数据中暴露组与对照组的比例悬殊较大,采用1∶1匹配法不仅造成样本的大量损失,甚至可能改变样本结构,影响处理效应的估计。
讨 论
本文针对观察性研究数据,介绍了控制混杂因素的随机森林法倾向性评分法,并以FDA不良事件报告系统的数据为实例展示了该方法在不良反应信号检测过程中的实施步骤和程序实现。随机森林作为一种组合分类方法,已经越来越多地应用在生物医学和医药卫生领域[11]。在基因表达数据领域,许多微阵列数据的分析均采纳了随机森林算法,包括基因筛选和对微阵列数据进行分类。在研究疾病的保护及危险因素方面,随机森林也能较好地识别疾病的危险或保护因素。随机森林是一种非参数的机器学习算法,它对变量之间的关系不作任何要求,且对样本量不作限制,能够分析线性、非线性以及具有交互作用的复杂数据,是一种有效的预测工具。随机森林与倾向性评分的结合,可以对传统logistic回归倾向性评分的分析结果进行相互验证,提高结果的稳定性;还能作为一种补充分析方法,弥补传统的logistic回归倾向性评分法对样本量和数据完整性及变量间关系的限制,可作为其补充或验证,有一定推广应用价值[12-13]。
计算出倾向性评分后,可以采用匹配法、分层法或回归调整法对混杂因素进行控制。在实际应用中,由于药品不良反应自发呈报系统数据库中暴露组和对照组的样本量差别很大,1∶1匹配的样本量损失过多且有可能改变样本特征,因此,并不建议在药品不良反应信号检测中使用匹配法。1∶M匹配也会损失一定的样本量,而且M取值多少最合适也没有定论。因此,在药品不良反应自发呈报系统数据中使用倾向性评分时,建议采用不损失样本量,保留原有信息的方法,如回归调整法。
随机森林倾向性评分作为一种控制混杂的有效方法,近年来其应用呈逐年上升趋势,然而,在实际运用时仍然需要注意其局限性。首先,倾向性评分只能调整观察到的协变量,对于未观察到的协变量,倾向性评分是无法处理的。其次,随机森林作为一种非参数的机器学习算法,其稳定性和可靠性在模拟研究中被评估过,其实际应用效果尚需大量实践验证。在数据满足logistic回归的应用条件时,建议仍用logistic回归计算倾向性评分,随机森林倾向性评分方法可作为其验证和补充。最后,计算倾向性评分时协变量的选择也十分重要。只有选择了真正的混杂因素,才能提高后续效应估计的精度。若协变量选择不当,则有可能造成矫正过正。选择协变量的常用方法有四种:①只考虑与暴露因素有关的协变量;②只考虑与结局有关的协变量;③考虑既与暴露因素又与结局有关的协变量;④考虑测量的一切协变量,不管其与暴露因素和/或结局是否相关。目前应用较广的是第②种。
[1]Grosse-Sundrup M,Henneman JP,Sandberg WS,et al.Intermediate acting non-depolarizing neuromuscular blocking agents and risk of postoperative respiratory complications:prospective propensity score matched cohort study.British Medical Journal,2012,345:e6329.
[2]Charlot M,Grove EL,Hansen PR,et al.Proton pump inhibitor use and risk of adverse cardiovascular events in aspirin treated patients with first time myocardial infarction:nationwide propensity score matched study.British Medical Journal,2011,342:d2690.
[3]吕军陈,王素珍.倾向性指数匹配法在肺癌化疗效果评价中的应用.中国卫生统计,2014(2):190-192.
[4]Little RJ,Rubin DB.The central role of the propensity score in observational studies for causal effects.Biometrika,1983,70(1):41-55.
[5]Luellen JK,Shadish WR,Clark MH.Propensity Scores:An Introduction and Experimental Test.Evaluation Review,2005,29(6):530-558.
[6]吴美京,吴骋,王睿,等.倾向性评分中评分值的估计方法及比较.中国卫生统计,2013,30(3):440-444.
[7]Lee BK,Lessler J,Stuart EA.Improving propensity score weighting using machine learning.Statistics in Medicine,2010,29(3):337-346.
[8]钱维,王超,吴骋,等.运用随机森林分析药品不良反应发生的影响因素.中国卫生统计,2013,30(2):209-213.
[9]钱维.药品不良反应监测中随机森林方法的建立与实现.第二军医大学硕士论文,2012.
[10]Breiman L.Random forests.Machine learning,2001,45(1):35-32.
[11]Moorthy K,Mohamad MS.Random forest for gene selection and microarray data classification.Bioinformation.2012,7(3):142-146.
[12]Sturmer T,Joshi M,Glynn RJ,et al.A review of the application of propensity score methods yielded increasing use,advantages in specific settings,but not substantially different estimates compared with conventional multivariable methods.Journal of Clinical Epidemiology,2006,59(5):437-447.
[13]Westreich D,Lessler J,Funk MJ.Propensity score estimation:neural networks,support vector machines,decision trees(CART),and meta-classifiers as alternatives to logistic regression.Journal of Clinical Epidemiology,2010,63(8):826-833.
(责任编辑:邓妍)
Random Forest Propensity Scores Method and its Application in Drug Adverse Reaction Signal Detection
Zhang Xinji,Zhang Tianyi,Xu Jinfang,et al
(Department of Health Statistics,Second Military Medical University(200433),Shanghai)
ObjectiveThe aim of this paper is to describe the basic ideas and algorithms of random forest propensity scores method for controlling confounders and apply it in detecting drug adverse reaction signals.MethodsFirst,we used random forest to calculate a patient′s probability of taking bisphosphonates.Then,we analyzed the association of bisphosphonate intake with risk of fracture by controlling potential confounders with propensity score method.The controlling confounders methods included 1∶1 matching,1∶Mmatching and regression adjustment by using the propensity score calculated by random forest.The results were compared with those from logistic propensity score.ResultsThe results of random forest propensity score and logistic propensity score were comparable.One to one propensity score matching cause a lot of sample lost and its results were quite different from those based on other methods.ConclusionRandom forest propensity score method can reduce the confounding bias.Hence,it could be used as an alternative to and verification of the logistic propensity score in controlling confounders.However,1∶1 propensity score matching may not be suitable for adverse drug reaction data from a spontaneous reporting system.
Propensity score;Random forest;Adverse reaction detection;Confounder
国家自然科学基金(No.81373105,81502895)
贺佳,E-mail:hejia63@yeah.net
