基于Hadoop平台的内容相似度与PageRank的垃圾短信识别融合模型
2016-10-25叶志雄朱丽芳刘钢庭李启文王丹弘
[叶志雄 朱丽芳 刘钢庭 李启文 王丹弘]
基于Hadoop平台的内容相似度与PageRank的垃圾短信识别融合模型
[叶志雄 朱丽芳 刘钢庭 李启文 王丹弘]
垃圾短信 Hadoop 内容相似度 PageRank 贝叶斯
叶志雄
男,中国移动通信集团广东有限公司,主要从事垃圾短信治理工作。
朱丽芳
女,中国移动通信集团广东有限公司,主要从事不良信息治理工作。
刘钢庭
男,中国移动通信集团广东有限公司,主要从事信息安全管理工作。
李启文
男,中国移动通信集团广东有限公司,主要从事信息安全管理工作。
王丹弘
男,中国移动通信集团广东有限公司,主要从事信息安全管理工作。
1 引言
笔者所在省级运营商的客户数目已达1.2亿多,短信作为海量客户间传递信息的载体,为彼此间的沟通架起有效的通道。短信在创造经济效益和社会效益的同时,少数不法分子利用短信进行欺诈、传播不实信息,给运营商带来了严重的社会代价和文化损失。
文献[1]对语料分词和统计,通过选择信息增益较大特征进行降维,结合朴素贝叶斯算法,减少个别特征对结果的干扰。文献[2]首先分析垃圾短信的供需问题,基于短信内容和短信发送渠道2个方面,分别提出非对称二维评判矩阵和分层分级治理策略,发现垃圾短信中的广告类短信比重最大,诈骗和色情类短信的危害最严重。文献[3]构建垃圾短信用户识别指标体系,通过建立随机森林模型对垃圾短信用户精准识别。文献[4]构建基于独立空间布隆过滤器的垃圾短信过滤系统,并给出系统结构,实验说明在允许一定“假阳性”误报率的条件下,该系统可以有效节省资源,提升识别性能。文献[5]在短信中心采用CFS结合BayesNet和反向消除方法提取垃圾短信特征,使用人工免疫法进行检测和过滤,构建垃圾短信多技术融合模型,结果表明模型分类准确率较高、误报率较低。文献[6]基于依存文法的组合特征筛选的垃圾短信过滤方法,通过对短信进行句法分析,考虑词与词之间的关系,融合部分语义信息,实现对中文短信的有效过滤。文献[7]通过对关键字和短信的模糊化预处理,运用WM算法进行中文信息匹配和多模式匹配,构建中文多模式模糊匹配算法,实验结果优于传统算法。
上述研究从不同方面对垃圾短信识别做了大量的工作,然而上述研究存在下面几点不足:(1)简单的采用某一种模型进行独立识别,(2)没有考虑到客户之间的社交关系,(3)在单机上实现建模仿真。因此,笔者通过在传统的内容相似度模型的基础上,结合PageRank对客户间的短信发送行为的社交网络进行分析,构建垃圾短信融合模型,并在Hadoop大数据平台上进行实际部署,最后结果表明本文模型的效果较优。
2 相关技术
2.1 TF-IDF词加权技术
TF-IDF(Term Frequency-Inverse Document Frequency)技术是信息检索和数据挖掘中常用的一种加权技术,用以评价一个词对一个文件或语料库中某一文件的重要程度。词的重要性与它在文件中出现的次数(即词频)成正比,与它在语料库中出现的频率(即逆文档频率)成反比。大体思想是:如果某个词在一篇文章中出现的词频TF值高,且在其他文章中也很少出现,即IDF值也很高,则认为该词具备很好的区分能力,需要被赋予较大的权重。文档dj中词ti的词频TFi,j计算方式如下:

ni,j代表词ti在文档dj中出现次数,分母代表文档dj中所有词的次数之和。
逆文档频率IDFi的计算方式如下:
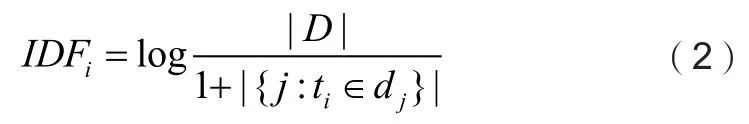
|D|表示语料库中的文档总数,分母表示包含词ti的文档数目+1,之所以加1,是为了防止出现所有文档都不包含词ti的极端情况。最后,词的加权值等于词频TF与逆文档频率IDF的乘积。
2.2 广义的Jaccard相似度
广义的Jaccard相似度可用来度量文档的相似程度[8,9],具体的计算公式如下:
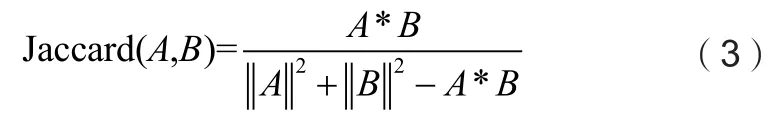
其中,A和B分别表示2个向量,向量中的每个维度为文档集合中的一个元素,向量中每个维度取值在[0,1]之间。A*B为向量乘积,
2.3 朴素贝叶斯
朴素贝叶斯算法(Naïve Bayes)是基于贝叶斯定理和特征条件独立性假设的分类方法,是影响最为广泛的分类模型之一。朴素贝叶斯算法通过学习联合概率分布,再计算后验概率分布,继而得到样本分类。
朴素贝叶斯算法的特征条件独立性假设如下:
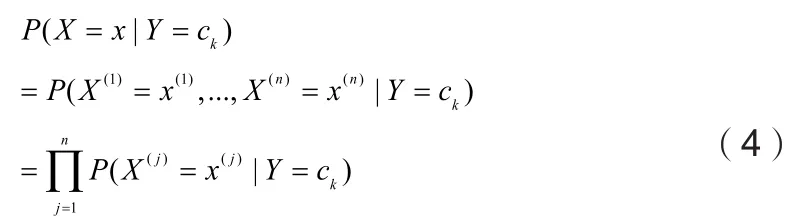
公式(4)中,n代表特征的数目,Y代表目标变量,ck代表目标变量的类别,X代表特征集合,X(j)代表第j个特征,x(j)代表第j个特征的特征值。
贝叶斯定理和最大后验概率如公式5,6:
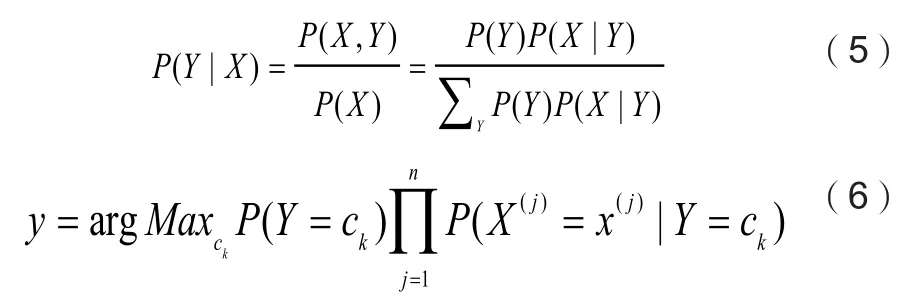
通过计算公式(6)的最大后验概率,将目标样本分类到后验概率最大的类中。
2.4 PageRank算法
PageRank算法是网页排序领域最著名的算法,是谷歌搜素引擎的核心算法[10,11]。PageRank算法基于节点之间的链接结构给出当前节点的重要性,即如果一个节点被很多重要的节点指向,则该被指向节点同样非常重要。其计算公式如下:
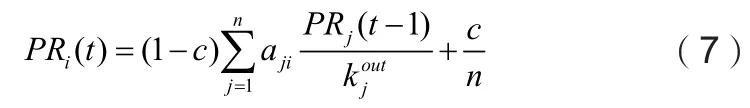
kjout是节点k的出度,即节点k指向的节点数目。常数c为随机跳转概率,保证没有被指向的节点同样有值,模拟现实生活中除通过超链接访问页面,也会直接输入网址进行访问的行为。图1是PageRank的算法示意图,节点的大小代表PageRank值大小,节点被指向的节点数目越多,节点越大。
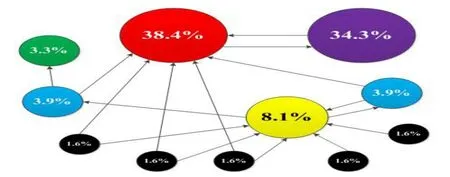
图1 PageRank算法
从图1可知,红色节点大小最大,对应的PageRank值最大;黑色节点最小,对应的PageRank值最小。
2.5 Hadoop平台
Hadoop是一个能够对海量数据进行分布式处理的框架,以一种高可靠、高效和可伸缩性的方式进行数据处理[12,13]。Hadaoop包含2个核心:分布式文件系统HDFS和分布式并行处理框架Map-Reduce。
与Hadoop集群相配合可使用的数据挖掘工具有Python和Mahout等,其中Python作为胶水语言,通过相关函数包可在Hadoop集群上实现数据分析,而Mahout提供了在Hadoop平台上直接将单机数据挖掘算法包转换为Map-Reduce模式的机制,可以极大的提升数据处理的规模和速度。
3 数据集和模型构建
3.1 数据集
实验数据来源于笔者所在单位,数据采集的时间周期为2015.10.12-2015.10.25,一共有5145万号码发送过3.2亿条短信,其中从省公司短信拦截系统和360举报的垃圾短信中抽样19 105条作为正样本;从其他正常短信中抽取60 792条作为负样本。
依据公司业务规则,我们设定正常短信号码需满足以下状态之一:集团关键人、集团联系人、VIP客户、境外漫游、对公托收、打印发票和拨打银行号码。
3.2 内容相似度模型
在文中,笔者采用IKAnalyzer作为短信内容的分词工具。IKAnalyzer是一个开源的Java轻量级分词工具包,具备字典分词和文法分析的功能。考虑公司的自身业务情况,笔者添加与公司自身业务相关的扩散词库,扩展词库的规模为150639。
在IKAnalyzer分词基础上,使用TF-IDF加权和Jaccard内容相似度算法,对短信话单进行相似度匹配,结合朴素贝叶斯算法对短信话单进行行为模式挖掘,挖掘内容相似短信的异常发送行为(包含多个主叫低频发送相似内容短信),圈出批量疑似号码。图2是内容相似度模型的整个流程。

图2 内容相似度模型
3.3 PageRank社交技术
3.3.1 短信发送行为的社交网络构建
用户短信发送行为包含用户之间的社交关系,若用户之间存在短信发送行为,则社交网络中存在一条边,若存在多次短信发送行为,则将多条边合并为一条。最后构建成的社交网络为有向、无权网络。图3是构建的短信发送社交网络的局部图。
PageRank分析技术过程如下:
step1:通过短信发送行为数据构建社交网络,再经过数据清洗,形成分析所用的网络。
step2:对网络节点和网络关系分别进行分析。(1)原始网络的节点分析:节点度、节点中心性、PageRank、节点集群特性。(2)原始网络的关系分析:用户间的沟通关系、关系类型。
step3:选择所需要的关注节点类型,重构网络,进一步分析。
图3是采用Gephi绘制的短信发送行为的社交网络示意图(19105个用户),节点代表客户号码,连边代表短信之间的发送行为,箭头代表短信的发送方向。图3(b)对应图3(a)中某一局部区域,而图3(c)是图3(b)左侧的红褐色的二次局部放大图,可知该中心节点具备大量的发送短信行为,而微弱的短信接收行为,我们可以认为是高疑似垃圾短信客户。

图3 短信发送行为的社交网络
3.3.2 社交网络的拓扑性质
为更好的理解短信发送行为的社交网络的拓扑性质,计算了由短信发送行为构建的社交网络的拓扑性质,如下表1。其中,C代表平均聚类系数,D代表网络直径,d代表平均最短距离,E代表连边数目,N代表节点数目,γ代表同配系数。
从表1可知,真实的短信发送行为的社交网络的平均聚类系数较小,网络直径较大,平均最短距离较大,同配系数为负,说明大度节点倾向与小度节点相连。

表1 短信行为的社交网络的拓扑性质
3.3.3 基于Hadoop的内容相似度与PageRank社交技术的融合模型
在融合模型中,每个模型均可以输出疑似号码集,为了综合考虑各个子模型,把各个模型通过因子分析训练各个模型的贡献度,计算出疑似号码的总和危险概率,从而根据综合危险概率值,排序输出高危疑似垃圾短信。最终融合模型部署在Hadoop大数据平台之上,具体架构如图4。
图4 融合模型的Hadoop大数据平台框架
4 实验结果与分析
4.1 评价指标
如何评价模型的好坏,对于分类模型,一般采用准确率和覆盖率评估,表2是数据挖掘模型中的分类情况,表中各个含义如下:
TP:将原始正类预测为正类的数目
FN:将原始正类预测为负类的数目
FP:将原始负类预测为正类的数目
TN:将原始负类预测为负类的数目

表2 数据挖掘分类情况
因此,模型正类的准确率定义为:

模型正类的覆盖率定义为:

4.2 实验结果分析
在实验过程中,对数据采用K折交叉验证训练模型和选择模型,其中K=10。建模所用的垃圾短信(原始正类)数目为19 100条,正常短信(原始负类)数目为60 792条。K折交叉验证发现模型在训练集和测试集合上表现一致、良好。表3和表4分别是内容相似度模型和PageRank社交技术的融合模型的最终结果。
4.2.1 内容相似度模型
从表3中可知,内容相似度模型的垃圾短信识别模型对垃圾短信的识别准确率达到34.57%,覆盖率达到37.61%。
4.2.2 PageRank社交技术的融合模型
表4是PageRank社交技术的融合模型结果。

表4 融合模型
从表4中可知,在内容相似度模型的基础上,结合PageRank社交技术的融合模型的垃圾短信识别率得到很大提升,准确率达到82.53%,覆盖率达到80.27%。图5是融合模型对应的垃圾短信前p%识别效果。
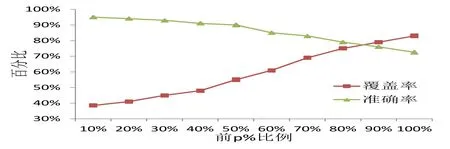
图5 前p%比例的融合模型效果
从图5可知,随着p值的增大,覆盖率不断增加,准确率不断下降,表5中的结果对应p=100的情况。
5 结论
近年来,垃圾短信日益猖獗,其社会危害性已引起社会的广泛关注。挖掘更全的潜在垃圾短信客户,提升确认疑似率,对于实现治理指标的客观管控成为垃圾短信治理的重中之重。论文通过融合内容相似度模型和PageRank社交技术模型,构建融合模型。在分析垃圾短信发送特征、场景和源头的基础上,搭建Hadoop大数据垃圾短信识别平台,实现持续精确的垃圾短信违规行为,并实现垃圾短信态势可感知。
1徐英慧,刘梅彦.基于内容的手机端垃圾短信过滤策略研究[J].北京信息科技大学学报(自然科学版),2013,1:011
2曾剑秋,杨光永,董豪.垃圾短信分类治理对策研究[J].北京邮电大学学报:社会科学版,2015,(6):39-44
3王睿,谭卫.基于大数据挖掘分析的垃圾短信治理方案[J].电信工程技术与标准化,2015,28(2):78-82
4张华,郑世珏.Bloom Filter 在手机垃圾短信过滤中的应用[J].安庆师范学院学报:自然科学版,2014,20(3):66-69
5汪健,黄大荣,吴鹏等.分布式处理下多技术融合的垃圾短信过滤模型[J].计算机测量与控制,2013,21(010):2811-2813
6易军凯,罗会明.基于依存文法的垃圾短信自动识别[J].北京化工大学学报:自然科学版,2013,40(B12):81-85
7秦建,孙秀锋,吴春明.“垃圾短信”监控的中文多模式模糊匹配算法[J].西南大学学报(自然科学版)ISTIC,2013,35(3):168-172
8程勇,黄河,邱莉榕等.一个基于相似度计算的动态多维概念映射算法[J].小型微型计算机系统,2006,27(6):975-979
9潘磊,雷钰丽,王崇骏等.基于权重的 Jaccard 相似度度量的实体识别方法[J].北京交通大学学报:自然科学版,2009,33(6):141-145
10刘建国,任卓明,郭强等.复杂网络中节点重要性排序的研究进展[J].物理学报,2013,62(17):178901-178901
11任晓龙,吕琳媛.网络重要节点排序方法综述[J].科学通报,2014,59(13):1175-1197
12Zikopoulos P,Eaton C.Understanding big data:Analytics for enterprise class hadoop and streaming data[M].McGraw-Hill Osborne Media,2011
13Shvachko K,Kuang H,Radia S,et al.The hadoop distributed file system[C]//Mass Storage Systems and Technologies(MSST),2010 IEEE 26th Symposium on.IEEE,2010:1-10
10.3969/j.issn.1006-6403.2016.09.002
2016-08-12)
垃圾短信是一种包含有欺诈、骚扰等内容的异常短信,不仅损害通信行业的形象,浪费通信卡资源,还会产生商业诈骗,引发客户不满。垃圾短信以商业、广告类和欺骗类信息为主要内容,其特征明显区别于正常短信;同时,客户之间的短信发送行为是一种真实的社交关系。基于此,论文对垃圾短信的识别采用基于Hadoop大数据平台的模型融合方法,在常规的内容相似度模型基础上,对短信发送行为构建PageRank社交技术模型,通过对上述模型加权融合,最后得出批量的高疑似垃圾短信,实验结果表明融合模型效果较优。
