机器学习在构建移动终端用户兴趣模型的应用研究
2016-10-25黄良发马怡伟
[黄良发 马怡伟]
机器学习在构建移动终端用户兴趣模型的应用研究
[黄良发 马怡伟]
移动终端 机器学习 用户兴趣模型
黄良发
就读于重庆邮电大学,硕士,研究方向为智能终端技术与应用。
马怡伟
奇酷互联网络科技(深圳)有限公司,高级工程师,从事智能终端的研发及管理工作。
1 引言
随着移动通信技术的发展,智能手机等移动终端设备成为人们获取信息的主要载体。如何准确分析移动用户使用手机行为的关键特征,为用户提供更加精准的服务,是当下的互联网经济的研究热点。另一方面,机器学习技术在各个领域都得到了快速的发展。因而基于移动终端上的海量数据,研究利用机器学习构建移动终端的用户兴趣模型,对构建用户画像、提高移动推荐系统的准确性具有较高的实用价值。
2 机器学习概述
机器学习最早可以追溯到对人工神经网络的研究。1943年Warren McCulloch和Walter Pitts 提出了神经网络层次结构模型,确立为神经网络的计算模型理论,从而为机器学习的发展奠定了基础。 1950 年,“人工智能之父”图灵提出了著名的“图灵测试”,使人工智能成为了计算机科学领域一个重要的研究课题[1]。机器学习是一门致力于研究如何通过计算的手段,利用经验来改善系统自身的性能的学科。今天,机器学习已经与普通人的生活密切相关。例如在天气预报等方面,有效地利用机器学习技术对卫星回传的数据进行分析,是提高预报和准确性的重要途径;在商业应用领域,有效地利用机器学习技术对垃圾信息进行过滤,能够改善产品,提升用户体验。
机器学习一般分为监督学习和无监督学习两大类。监督学习利用已有标签的数据作为最终的学习目的,它的数据集包含初始训练数据和人为标注数据,希望根据标注特征从训练集中学习到对象划分的模型,并利用该模型在预测数据中预测结果,输出标记信息的数据。因此,监督学习的根本目标是是训练机器学习的泛化能力。监督学习的典型算法有:逻辑回归、朴素贝叶斯、卷积神经网络等;典型应用有:回归分析、任务分类等;在无监督学习中,其训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习揭示数据的内在性质及规律,为进一步的数据分析提供基础[2]。因此,无监督学习的根本目标是在学习过程中根据相似性原理进行区分。无监督学习的典型算法有k-means聚类、高斯混合聚类、深度置信网络等; 典型应用有:聚类和异常检测等。
3 机器学习方法在构建移动终端用户兴趣模型中的应用
用户兴趣模型是个性化推荐系统的基础,它不仅仅是对于用户兴趣的准确描述,更是指从有关用户兴趣和行为的信息中归纳出可计算的用户模型的过程[3]。
用户兴趣建模一般包括两方面内容:通过记录和分析用户行为及用户反馈等收集用户信息并从中挖掘用户兴趣; 用合适方法表示用户兴趣,即建立用户兴趣模型,并随用户兴趣变化动态更新用户兴趣模型[4]。 其一般流程如图1。
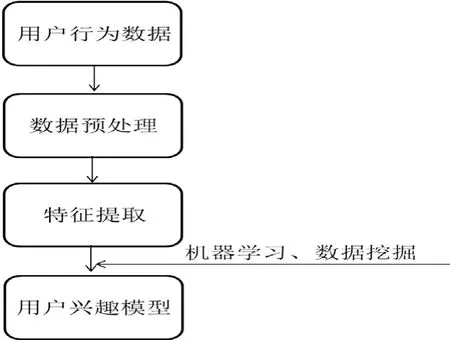
图1 用户兴趣建模流程
目前,用户在移动终端设备上的行为主要反映在对各种App的使用上,比如人们购物会使用专门的购物类App,聊天时会使用专门的社交类App等。因此,通过研究App的使用行为,便能够准确的反映该用户的兴趣所在。
3.1 数据预处理。
由于数据的获取来源多异,数据结构如图2。导致收集的数据含有杂乱无用的信息,需要预先进行处理。主要分为三种类型:(1)设置、桌面,手电筒等系统预装应用,不能反映该用户的兴趣所在,需要过滤掉该部分信息;(2)对于一些非常热门的App,如微信,支付宝等,由于每个用户都会使用,因此通过这些应用不能反映出用户的兴趣所在,也需要过滤掉;(3)针对原始数据的确实值,如果直接丢弃掉将会减少样本,因此我们通过统计该值所在的特征值的均值,然后用该均值填充丢失的值的方法处理缺失值。

图2 数据结构
3.2 特征提取
特征提取是从特征集合中挑选一组最具统计意义的特征,以达到减少数据存储和减少冗余的目的。由于各大应用商店上都有成千上万种应用,如果对每个应用都提取特征值,这将显得该特征矩阵相当庞大。因此,首先需要对每个应用进行分类映射。例如,通过对应用分类,把应用划分为社交,交通类等。通过该方法,能给对应的用户打上对应的标签。为了平衡取值范围不一致的特征,需要对特征进行归一化处理,将特征取值归一化到[0,1]区间。常用的归一化方法包括(1)函数归一化,通过映射函数将特征取值映射到[0,1]区间,例如最大最小值归一化方法,是一种线性的映射;(2)分维度归一化,可以使用最大最小归一化方法,但是最大最小值选取的是所属类别的最大最小值,即使用的是局部最大最小值,不是全局的最大最小值。(3)排序归一化,不管原来的特征取值是什么样的,将特征按大小排序,根据特征所对应的序给予一个新的值。为了便于表示和在模型中处理,需要对连续值特征进行离散化处理。常用的离散化方法包括等值划分和等量划分。等值划分是将特征按照值域进行均分,每一段内的取值等同处理。例如某个特征的取值范围为[0,10],我们可以将其划分为10段,[0,1),[1,2),...[9,10)。为了选取出真正相关的特征,主要分为‘子集搜索’和‘子集评价’两个环节。‘子集搜索’是给定特征集合,我们可将每个特征看作一个候选子集,对这d个候选单例特征子集进行评价,假定最优,于是将作为第一轮的选定集;然后,在上一轮的选定集中加入一个特征,构成包含两个特征的候选子集,假定在d-1个候选集中最优,且优于,于是将作为本轮的选定集。假定经过第k+1轮时,最优的候选(k+1)特征子集不如上一轮的选定集,则停止生成候选子集,并将上一轮选定的k特征集合作为特征选择结果。‘子集评价’是对特征子集进行评价,通过计算属性子集A的信息增益,其中信息熵定义为,信息增益,意味着对应特征子集A包含的分类信息越大,于是,对每个候选特征子集,将特征子集搜索和子集评价机制相结合,即可得到特征提取的方法[2],见表1 。

表1 类别映射表
3.3 算法选择
为了得出用户的兴趣模型,本模型采用基于聚类的分类学习算法。
首先,根据聚类结果将每个簇定义为一个类,然后再基于这些类训练分类模型,判别新用户的类型。主要采用的是k-means算法。给定样本集D=,该算法针对聚类所得簇划分C=,最小化平方误差,其中是簇[2]。
在聚类的基础上采用的是监督学习算法。决策树是一类常用的机器学习方法,决策树计算复杂度不高、便于使用、而且高效,决策树可处理具有不相关特征的数据、可很容易地构造出易于理解的规则。一般的,一颗决策树包含一个根结点,若干个内部结点和若干个叶结点;叶节点对应于决策结果,其他每个结点对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根节点包含样本全集,从根节点到每个叶节点的路径对应了一个判定测试序列。决策树最优划分属性时,有多种选择方式,其中ID3 决策树算法是以信息增益来进行决策树的划分属性选择。但以信息增益进行分类决策时,存在偏向于取值较多的特征的问题。为了解决这个问题,在该模型中,采用的CART决策树,区别就在于选取决断特征时选择信息增益比最大的。
3.4 模型评估
主要根据样本数据,模型结果反馈数据进行模型评估。比如通过精确率。精确度是分类正确的样本数占样本总数的比例。对于样例集D,精度定义为
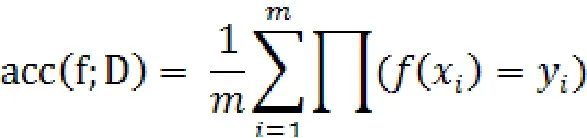
在应用中,我们结合交叉验证法,既先将数据集D划分成k个大小相似的互斥子集,然后每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,进行k次训练和测试,用于评估结果的稳定性和保真性。经实验证明,该模型的准确度达到86%左右,如图3。
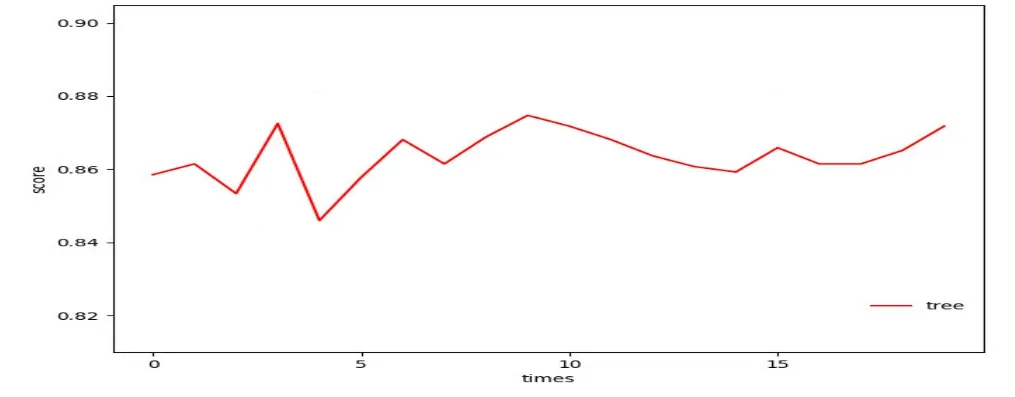
图3模型评估
3.5 模型优化
模型初步构建完成后,并不意味着一劳永逸,因为用户的兴趣经常随着时间发生变化[5]。因此,每个构建的模型都有一定的时效性。一种方法是为一个用户同时建立长期兴趣和短期兴趣模型,其核心就是处理好用户的两类兴趣,即用户的长期兴趣和用的短期兴趣。混合兴趣模型依靠用户的历史数据来挖掘用户稳定的、波动范围小的长期兴趣,依靠最近的数据挖掘用户个性化的、波动范围大的短期兴趣;另一种是采用窗口法,针对用户最近一段时间的信息进行建模。因为用户最后行为的观察能更准确地反映出用户当前的兴趣[7]。因此,对用户兴趣进行建模时只需要考虑用户最近一段时间内的数据记录。
4 结束语
本文讨论了数据预处理、选择特征值以及如何优化用户兴趣模型等机器学习在移动终端用户兴趣模型中的应用,它能够减少业务人员手工标记,标准难统一的问题,同时利用大数据平台,使得机器学习在研究移动终端兴趣模型上有更大的发展。
关于移动终端用户兴趣模型和移动上下文信息的结合,将是下一步研究工作重点。
1张润,王永滨.机器学习及其算法和发展研究[J].中国传媒大学学报(自然科学版),23(2):10-18,24
2周志华.机器学习.北京.清华大学出版社,2016.2
3孟祥武,胡勋,王立才等.移动推荐系统及其应用[J].软件学报,2013,24(1):91-108
4尹春晖.面向个性化信息检索的用户兴趣建模研究与实现[D].苏州:苏州大学,2008
5杨李婷,陈翰雄.用户兴趣建模综述[J].软件导刊,2015,10:20-23
6Billsusd,pazzanimj.A hybrid classifi- cation model[C].kayj.(ed.),proceedings of the seventh international-conference on user modeling(UM 99),Spring-Verlag.1999:99-108
7Widmer G,Kubat M.Learning in the presence of concept drift and hidden contexts[J].Machine Learning,2013,23(1):69-101
10.3969/j.issn.1006-6403.2016.09.001
2016-08-24)
目前,机器学习已在各个领域得到了大量的应用,因此研究机器学习在移动终端用户兴趣模型的应用也显得有必要。文章对机器学习进行了介绍,重点分析了机器学习算法在构建移动终端兴趣模型时的应用,并对目前应用中如何进行数据预处理、选择特征值以及如何优化用户兴趣模型进行了讨论。
