应用非负矩阵分解的社交网络好友推荐
2016-10-24贺超波付志文石玉强钟松林
贺超波, 付志文, 石玉强, 钟松林
(仲恺农业工程学院信息科学与技术学院,广州 510225)
应用非负矩阵分解的社交网络好友推荐
贺超波*, 付志文, 石玉强, 钟松林
(仲恺农业工程学院信息科学与技术学院,广州 510225)
现有好友推荐方法只利用用户关系或内容信息进行推荐,难以获得较好的推荐质量. 针对该问题,在利用非负矩阵分解模型适合数据聚类以及数据约简的基础上,提出一种基于非负矩阵分解的好友推荐方法:FRNMF. 该方法采用基于非负矩阵分解的用户聚类为核心的好友推荐框架,利用用户好友关系网络信息和内容信息分别进行用户聚类,然后基于聚类结果计算用户间的综合相似度并进行好友推荐;不仅可以综合集成利用用户关系和内容两类信息,而且具有线性时间复杂度,还可以解决数据稀疏引起的推荐质量下降问题. 实验开发了FRNMF的原型系统,并在真实的新浪微博和学者网社交网络数据集进行对比实验,结果表明FRNMF比传统的好友推荐方法具有更好的推荐质量. 此外,对用户关系和内容两类信息的权重参数设置进行实验分析,分析表明适当提高用户关系信息的权重对于提高好友推荐质量具有促进作用.
非负矩阵分解; 社交网络; 好友推荐
目前社交网络发展日益迅速,Facebook、Twitter、微博以及微信等国内外大型社交网络服务平台已吸引了大量用户使用. 根据有关资料统计,全球最大的社交网络Facebook的用户数在2015年初超过13亿,而国内的微信也超过了5亿的用户数量[1],并且保持着很高的用户增长率. 社交网络能够不断吸引用户使用的重要原因在于用户不仅能通过社交网络维护现实中的好友关系,而且能够通过社交网络发现更多感兴趣的好友并扩大自己的社交圈子[2]. 由于大规模社交网络用户数量庞大,用户主动查找好友很容易遇到“信息过载”的问题,所以社交网络需要提供好友推荐服务功能帮助用户快速准确地发现感兴趣的好友. 目前对于社交网络的好友推荐问题已提出了不少解决方法,其中包括基于社交圈[3]、基于角色协同[4]、基于用户Profile相似度计算[5]、基于链接预测[6]以及基于协同过滤[7]的好友推荐方法. 总的来说,现有好友推荐方法都需要在计算用户间相似性或者好友链接关系建立概率的基础上进行推荐,但往往都只单一使用用户好友关系信息或者内容信息,并不能综合利用这2类信息提高推荐质量. 此外,这2类信息都存在很高的稀疏度,如用户的平均好友数远远小于用户总数量,这将引起推荐质量的下降. 针对以上问题,本文提出了一种基于非负矩阵分解的好友推荐方法:FRNMF(Friend Re-commendation using Nonnegative Matrix Factorization),所做的主要工作包括:(1)设计了FRNMF的好友推荐框架,该框架可以利用用户好友关系网络信息和内容信息分别进行用户聚类,通过基于2类信息的聚类结果进行用户相似度计算和好友推荐;(2)在真实的社交网络数据集上进行实验验证,结果表明FRNMF不仅可以综合利用用户关系和内容这2类信息,而且可以通过NMF的维度约简解决数据稀疏问题并提高推荐质量.
1 基于NMF的好友推荐方法:FRNMF
1.1NMF模型
NMF是一种低秩矩阵近似逼近模型,适合于分析非负值矩阵的主要组成部分[8]. 该模型的数学描述为:给定一个矩阵X和期望的秩r≪min(m,n),可以将X分解为2个矩阵F和G,且满足X≈FGT,其中+为非负值元素集合. F和G可通过求解以下目标函数获得:

(1)
其中目标函数J用于量化矩阵X和FGT的近似逼近程度.LEE和SEUNG[9]提出了2种常用的目标函数:Frobenius范数和Kullback-leibler离散度,并指出这2个函数对于单独的F或G均是凸函数,同时对于F和G却不是凸函数,因此要找到一个解决上述2个目标函数的全局最优解是非常困难的. 现实中,往往使用优化算法得到局部最优解作为矩阵分解结果,较为常用的方法为迭代更新求解方法[10].
NMF已被证明可等价于经典的K-means聚类算法以及具有强大的聚类结果可解释能力,此外,NMF可以将1个高维的矩阵分解为2个或多个低维矩阵的乘积实现维度约简,不仅可以解决矩阵数据稀疏问题而且不会丢失原有信息的主要特征,因此在个性化信息推荐领域也得到广泛应用[11]. 例如,基于正则化NMF的协同过滤方法RSNMF[12]、基于联合概率矩阵分解的推荐算法UPMF[13]、基于受限约束NMF的协同过滤方法BNMF[14]以及基于结构投影NMF的协同过滤算法CF-SPNMF[15]等均通过实验证明基于NMF可以解决项目评分矩阵存在的高度稀疏问题并且具有较高的推荐精度. 本文利用NMF具有的数据聚类以及数据约简特点,研究应用NMF进行社交网络好友推荐的方法FRNMF. 1.2FRNMF推荐框架
社交网络中包含丰富的用户好友关系网络信息和用户内容信息(如用户标签、微博以及简介等),这些信息隐含着用户的兴趣特征,可以加以利用进行好友推荐. FRNMF具有基于NMF的用户聚类为核心的好友推荐框架(图1),可以综合利用这2类用户信息进行好友推荐. 该推荐框架首先通过数据预处理从社交网络中抽取用户好友关系网络信息和内容信息并构建相对应的链接矩阵X和内容特征矩阵Y,然后分别对X和Y应用NMF进行用户聚类挖掘,最后基于2类用户信息的聚类结果进行用户综合相似度计算以及好友推荐排序.

图1 FRNMF推荐框架
1.3基于NMF的用户聚类
社交网络中的用户好友关系网络以及内容信息都可以进行用户聚类挖掘,首先对于用户好友关系网络信息,可以构建一个n×n用户链接矩阵X,其中n为用户总数,X中的各元素值xij=xji=1(当用户i和j有好友关系时)或者xij=xji=0(当用户i和j没有好友关系或者i=j时),可知X为对称矩阵. 由于∀xijX,均有xij≥0,所以适合采用NMF进行分解. 文献[16]指出用户链接矩阵X可以分解为三分解(Tri-Factorization)形式X≈HSHT,由于X为对称矩阵,所以S也为对称矩阵,假设H←HS1/2,那么基于X的矩阵三分解形式可以进一步简化为X≈HHT,其中H为用户节点聚类归属强度矩阵,且H+n×p,p为基于好友关系网络信息的用户聚类数目. 采用Frobenius范数作为目标函数,则X的NMF分解模型为:
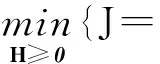
(2)
根据矩阵Trace和Frobenius范数的关系,目标函数J可以重写为:
J=tr(XXT)-2tr(XHHT)+tr(HHTHHT).
(3)
由于∀hijH均有hij≥0,那么最小化J可以转化为典型的受限约束求极值问题,可以应用拉格朗日乘数方法进行求解. 设αij为受限条件hij≥0对应的拉格朗日乘数,且α=[αij],则J对应的拉格朗日乘数函数L为:L=J+tr(αHT),为优化求解函数L,可以引入Karush-Kuhn-Tucker(KKT)条件,首先求得:
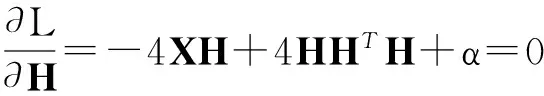
(4)
然后根据KKT的平滑条件,要求αijhij=0,则由式(4)可得到如下新的等式:
(4XH)ijhij-(4HHTH)ijhij=0.
(5)
由式(5)可得到hij的迭代更新规则为:

(6)
由于hij表示用户i属于聚类j的强度,所以用户i在基于关系网络信息的聚类中可以划入归属强度最大的聚类中.
社交网络用户的内容信息主要来自于用户标签、微博动态以及简历等文本类型的数据,可以首先应用经典的词袋模型TF/IDF进行文本内容特征信息提取,并构建n×m的用户文本内容特征矩阵Y,其中m为词典词项总数,Y中的任一元素yij为用户所关联词项的TF/IDF值,可知Y同样为非负值矩阵,所以也适合基于NMF进行分解. 基于NMF模型,可以将Y近似分解为2个矩阵U、VT的乘积:Y≈UVT,其中U,V,q为基于内容信息的用户聚类数目. 采用Frobenius范数作为目标函数,Y的NMF分解模型为:
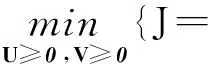
(7)
根据与X的NMF分解模型相同的求解方法,可以得到U和V各元素的迭代求解规则为:
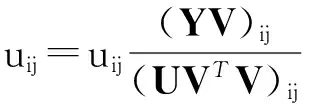
(8)

(9)
其中,uij同样可表示为用户i属于聚类j的强度,所以用户i在基于内容信息的聚类中可以划入归属强度最大的聚类.
1.4好友推荐
用户聚类步骤中分别得到2类信息的聚类结果指示矩阵H和U,H和U均为NMF进行维度约简后的矩阵,稀疏度远小于原始矩阵X和Y,所以基于H和U计算用户相似度更加准确. 首先对于H,任意2个用户i和j在H中对应的行向量分别为hi和hj,那么用户i和j的基于H的相似度simH(i,j)可以采用hi和hj的点积进行计算:
simH(i,j)=hi·hj=(HHT)ij.
(10)
同理,用户i和j的基于U的相似度simU(i,j)也可以按照相同方法计算获得.simH(i,j)为用户好友关系网络信息特征相似度,simU(i,j)为用户内容信息特征相似度,为此可以设计一种带权重信息的用户综合相似度sim(i,j)的计算方法:
sim(i,j)=αsimH(i,j)+(1-α)simU(i,j),
(11)
算法1基于NMF的好友推荐算法
输入:用户集合V={v1,v2,…,vn},用户好友关系矩阵X,用户内容信息特征矩阵Y,聚类数目p、q,权重参数α;
输出:好友推荐Top-K列表;
过程:
Step1. 随机初始化H、U、V;
Step2. 分别应用迭代更新规则6和规则8获得H和U;
Step3. 基于H计算两两用户相似度simH(i,j);
Step4. 基于U计算两两用户相似度simU(i,j);
Step5. 根据式(11)计算两两用户相似度sim(i,j);
Step6. ∀viV返回与其相似度处于Top-K范围内的用户.
可以分析算法1的计算时间消耗都集中在Step2,即分别迭代应用更新规则6和规则8获得H和U. 由于X和Y均为稀疏矩阵,假设X和Y的非0元素个数分别为μX和μY,迭代次数为t,则可计算规则6的时间复杂度为O(μXp+2np2+2np)t,规则8的时间复杂度为O(μYq+(n+m)q2+2nq)t. 由于p≪n以及q≪m,可知算法1的时间复杂度跟n和m是线性相关的.
2 实验分析
2.1数据集和评价准则
选择了2个真实的社交网络作为实验数据来源,分别为新浪微博Weibo(http://d.weibo.com/)和学者网SCHOLAT(http://www.scholat.com/). 新浪微博为大众类的社交网络,用户可以互相加为好友以及分享最新动态,学者网则是面向科研教学工作者的垂直社交网络,提供管理个人科研教学信息以及学术社交网络服务. 实验开发了FRNMF的原型系统(图2).通过该原型系统的Web爬虫程序首先分别爬取了新浪微博和学者网部分用户公开的好友关系网络、个人简历、标签以及微博动态数据等,然后再通过数据预处理和文本分词程序得到实验用数据集,数据集特征信息见表1.

图2 FRNMF原型系统

数据集用户数好友关系对用户内容特征词数新浪微博49453310714670632学者网5683358957591
为度量好友推荐的质量,采用了信息推荐领域常用的查准率P和召回率R作为度量标准. 假设为目标用户推荐的好友集合为A,目标用户已有的好友集合为B,各标准的具体计算规则如下:
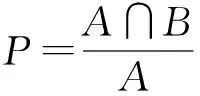
(12)

(13)
2.2实验对比分析
为验证本文FRNMF的推荐质量,实验选择了与3种常用的社交网络好友推荐方法进行对比分析,这3种方法分别是:(1)FoF[2]:即friend-of-friend,该方法需要首先计算用户间具有共同好友的数量,然后为目标用户推荐具有共同好友较多的用户. (2)Profile-based(PB)[5]:该方法需要首先计算用户间Profile的相似度,然后为目标用户推荐相似度较高的用户. (3)协同过滤[7]:该方法直接利用好友关系链接矩阵X计算用户间的相似性,然后为目标用户推荐前K个最相似的用户. 实验过程中随机抽取新浪微博和学者网用户80%的好友关系数据作为训练集,20%的好友关系数据作为测试集,各种对比方法分别进行Top 2、Top 4、Top 5、Top 8以及Top 10的推荐,并都进行了10次实验,取得P和R的平均值作为最终度量结果(图3~图6).

图3 Weibo的查准率对比

图4 Weibo的召回率对比
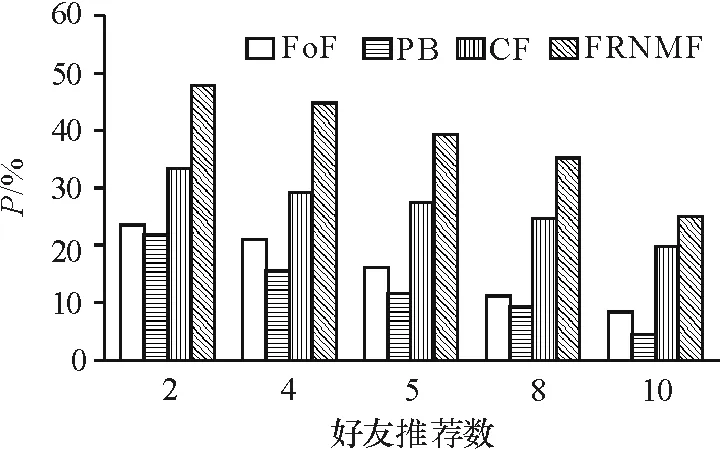
图5 学者网的查准率对比

图6 学者网的召回率对比
从图3~图6可以看出,本文提出的FRNMF方法与其他方法相比具有更好的推荐质量,其原因在于:(1)综合利用用户关系和内容信息比利用单一信息进行好友推荐更能反映用户选择好友的偏好;(2)2类信息本身存在噪音数据,两者集成可以起到互为补充的作用;(3)2类信息都存在很高的稀疏度,这在进行Profile相似度计算以及协同过滤用户相似度计算过程会产生较大误差,进而影响最终推荐的质量.
2.3权重参数α设置分析
式(11)的参数α可以起到控制2类信息对于综合相似度计算的影响程度,在现实应用中可以通过实验评估FRNMF的推荐质量来确定α的值. 通过设置α值在[0,1]范围内按0.1递增,并分别计算FRNMF在新浪微博和学者网进行Top 2、Top 4、Top 5、Top 8以及Top 10推荐获得的Precision和Recall平均值,结果见图7、图8,可以看出,α值设置在[0.5,0.7]范围内,FRNMF在2类数据集上都具有较好的推荐质量,表明适当提高用户关系信息的权重对于提高好友推荐质量具有促进作用.
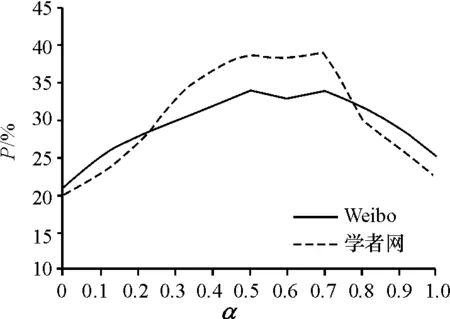
图7 查准率与α

图8 召回率与α
3 结束语
本文基于NMF提出了一种社交网络好友推荐方法:FRNMF,设计了相应的好友推荐框架和好友推荐算法,其优势在于:可以综合利用用户关系信息和内容信息推荐好友;利用NMF维度约简克服了数据稀疏问题,提高了用户相似性的准确度,进而提高了社交网络好友推荐准确性. 实验验证表明FRNMF与传统方法相比具有更好的推荐质量. 由于现实中的社交网络用户数量巨大,将带来大数据处理问题,所以,下一步工作将重点研究如何提高FRNMF在进行好友推荐时的计算效率.
[1]中文互联网数据资讯中心. WeAreSocial: 2015年全球移动&社交报告精华解读[EB/OL]. (2015-02-02)[2015-10-19]. http:∥www.199it.com/archives/326417.html.
[2]贺超波,汤庸,陈国华,等.面向大规模社交网络的潜在好友推荐方法[J].合肥工业大学学报(自然科学版),2013,36(4):420-424.
HE C B, TANG Y, CHEN G H, et al. Potential frined recommendation method for large-scale social network [J]. Journal of Hefei University of Technology (Natural Science Edition), 2013, 36(4):420-424.
[3]王玙,高琳.基于社交圈的在线社交网络朋友推荐算法[J].计算机学报,2014,37(4):801-808.
WANG Y, GAO L. Social circle-based algorithm for friend recommendation in online social networks [J]. Chinese Journal of Computers, 2014, 37(4):801-808.
[4]刘冬宁,刘艳,滕少华,等. 基于角色协同的在线社交网络好友推荐机制[J].广西大学学报(自然科学版),2014,39(6):1316-1323.
LIU D N, LIU Y, TENG S H, et al. The friend recommendation on social network based on role cooperation [J]. Journal of Guangxi University (Natural Science Edition), 2014, 39(6):1316-1323.
[5]AKCORA C G, CARMINATI B, FERRARI E. User similarities on social networks [J]. Social Network Analysis and Mining, 2013, 3(3):475-495.
[6]DONG Y X, TANG J, WU S, et al. Link prediction and recommendation across heterogeneous social networks[C]∥Proceedings of the 12th International Conference on Data Mining. Chicago: IEEE, 2012:181-190.
[7]AGARWAL V, BHARADWAJ K K. A collaborative filtering framework for friends recommendation in social networks based on interaction intensity and adaptive user similarity [J]. Social Network Analysis and Mining, 2013, 3(3):359-379.
[8]LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization [J]. Nature, 1999, 401(10):788-791.
[9]LEE D D, SEUNG H S. Algorithms for non-negative matrix factorization[C]∥Proceedings of 2000 Annual Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2000:556-562.
[10]LIU H W, LI X L, ZHENG X Y. Solving non-negative matrix factorization by alternating least squares with a modified strategy[J]. Data Mining and Knowledge Discovery, 2013, 26(3):435-451.
[11]陈洁敏, 汤庸, 李建国, 等.个性化推荐算法研究[J].华南师范大学学报(自然科学版),2015,46(5):8-15.CHEN J M, TANG Y, LI J G, et al. Survey of personali-zed recommendation algorithms [J]. Journal of South China Normal University (Natural Science Edition), 2015, 46(5):8-15.[12]LUO X, ZHOU M C, XIA Y N, et al. An efficient nonnegative matrix factorization-based approach to collaborative filtering for recommender systems [J]. IEEE Tran-sactions on Industrial Informatics, 2014, 10(2):1273 - 1284.
[13]涂丹丹,舒承椿,余海燕.基于联合概率矩阵分解的上下文广告推荐算法[J].计算机学报,2013,24(3):454-464.TU D D, SHU C C, YU H Y. Using unified probabilistic matrix factorization for contextual advertisement recommendation [J].Journal of Software, 2013, 24(3):454-464.
[14]KANNAN R, ISHTEVA M, PARK H. Bounded matrix factorization for recommender system [J]. Knowledge and Information Systems, 2014, 39(3):491-511.
[15]居斌,钱沄涛,叶敏超.基于结构投影非负矩阵分解的协同过滤算法[J].浙江大学学报(工学版),2015, 49(7):1319-1325.
JU B, QIAN Y T, YE M C. Collaborative filtering algorithm based on structured projective nonnegative matrix factorization[J]. Journal of Zhejiang University (Engineering Science Edition) , 2015,49(7):1319-1325.
[16]ZHANG Y, YEUNG D Y. Overlapping community detection via bounded nonnegative matrix tri-factorization[C] ∥Proceedings of the 18th ACM International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2012:606-614.
【中文责编:庄晓琼英文责编:肖菁】
Friend Recommendation in Social Network Using Nonnegative Matrix Factorization
HE Chaobo*, FU Zhiwen, SHI Yuqiang, ZHONG Songlin
(School of Information Science and Technology, Zhongkai University of Agriculture and Engineering, Guangzhou 510225, China)
Most of existing friend recommendation methods only utilize user friendship or content information, and hence they are hard to obtain better recommendation quality. Aiming at this problem, Friend Recommendation using Nonnegative Matrix Factorization (FRNMF) for friend recommendation based on Nonnegative Matrix Factorization (NMF) is proposed, which is fit for data clustering and data reduction. FRNMF adopts user clusters as the core component of its framework. It firstly clusters users by utilizing user friendship network and user-generated content information respectively, and then calculates user pairwise similarities for recommendation based on the cluster results. It can use both user friendship and content information, and it has linear time complexity. FRNMF can alleviate the problem of data sparsity, which can result in the low recommendation quality. By developing protosystem of FRNMF and conducting comparative experiments on Weibo and Scholat social networks, the results show that our method performs better than traditional friend recommendation methods. Moreover, by experimental analysis, moderate increase of the weight of user friendship information can further improve the recommendation quality.
nonnegative matrix factorization; social network; friend recommendation
2015-11-10 《华南师范大学学报(自然科学版)》网址:http://journal.scnu.edu.cn/n
广东省科技计划项目(2016A030303058,2015A020209178);广州市云计算安全与测评技术重点实验室开放基金(GZCSKL-1407);国家级大学生创新创业训练计划项目(201511347005)
贺超波,副教授,Email:hechaobo@foxmail.com.
TP391
A
1000-5463(2016)04-0100-06
