面向电子商务平台的藏汉跨语言信息检索关键技术研究
2016-10-21朱琳戴玉刚李艾林郝大鹏
朱琳 戴玉刚 李艾林 郝大鹏


摘 要: 本文以电子商务为平台,以藏语和汉语语言特点为基础,以藏汉双语可比语料为资源,分析当前自然语言处理技术,把双语词典和主题空间模型相结合,搭建藏汉跨语言信息检索总体框架。为下一步把多语言电子商务、跨语言检索、民族自然语言处理技术进行结合提供了新的思路和途径。
关键词:电子商务 跨语言检索 双语词典 主题空间模型
中图分类号:TP391.3 文献标识码:A 文章编号:1003-9082(2016)06-0015-02
一、引言
跨语言信息检索(Cross Language Information Retrieval,CLIR),就是当用户用一种语言输入要检索的信息时,检索的信息也可以用另外一种语言进行呈现。它是一种打破语言障碍,涉及语言学、计算机科学、数学等多门学科知识进行检索信息的技术[1]。
1973年,G..Salton先生发表的《Experiments in multilingual information retrieval》,是对这项技术的最早研究。当时所研究的检索主要是对国际联机进行的,另外加上检索系统不普及等因素,并没有引起人们的关注。90年代后期,随着Internet的迅猛发展, Internet的全球化信息结构引发了人们对跨语言信息检索的迫切需要,此时这项检索技术真正成为了研究热点[2]。现在,许多公司都把检索技术应用到电子商务中,比如京东,雅虎,阿里巴巴等,但把跨语言技术应用到电商中却寥寥无几,这与民族自然语言的特点与难点有关,由于民族自然语言的特殊性,国外的一些自然语言处理技术研究成果也无法应用到对国内民族语言进行处理。而针对藏汉跨语言检索的研究成果更是甚少,所以把民族语言处理技术、跨语言检索技术等应用到面向电子商务中愈来愈重要。
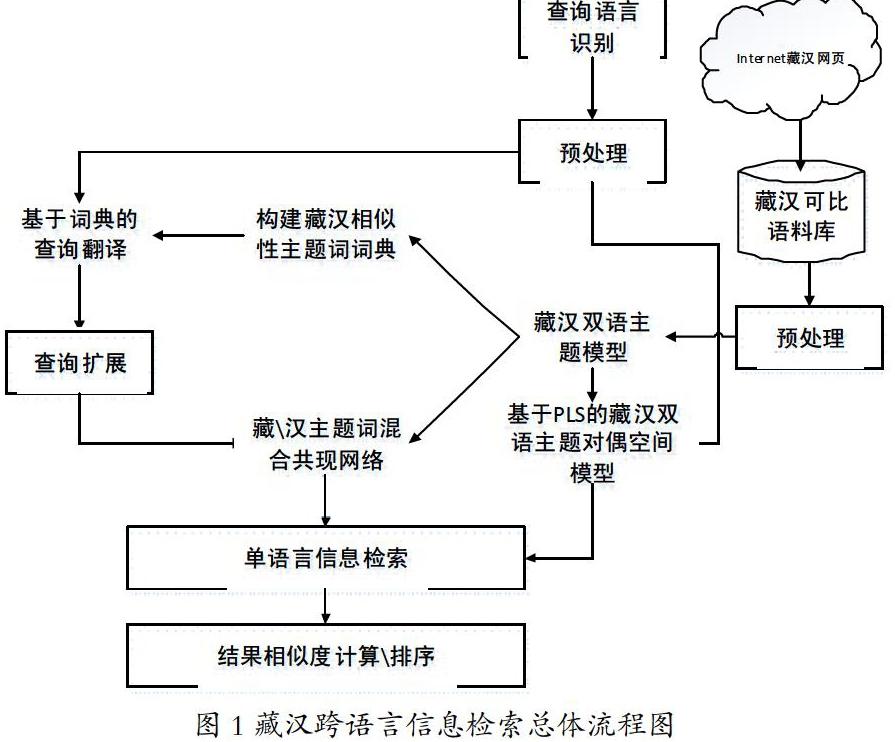
二、搭建面向电子商务平台的藏汉跨语言信息检索总体框架
用户输入查询语后,如何在查询语和检索语之间搭建有效的桥梁枢纽,就是跨语言信息检索技术研究的最核心最关键的问题[3]。本文拟融合字典和语料库两种技术来实现跨语言信息检索模型的研究,从而克服单种方法的不足。本文采用了一种基于翻译的技术进行CLTR,这种技术的一个显著特点就是将翻译过程和检索过程分离,即:先借助于跨语言的语义资源或者机器翻译系统将语言内容翻译成目标语言表示的内容,然后使用成熟的单语言信息检索模型进行检索[4]。其分离的翻译过程将导致目标语言的语义空间与原始语义空间的语义偏离。为了解决语义偏离问题,本文引入双语主题模型技术,将目标语言的语义空间与原始语义空间的语义进行相似性计算。
三、构建藏汉可比语料库
藏汉双语平行资源严重不足或没有是当前所面临的严峻问题,可比语料具有来源广、涉及领域全面、内容丰富、易获取等特点。本文拟建立面向跨语言信息检索的藏汉可比语料库,同时也可以为藏汉机器翻译、双语词对和术语抽取、构建语义词典等研究提供基础资源。主要从两个方面进行开展:1)从国内公开发布的双语电商网站搜集藏汉农产品双语语料;2)首先从互联网上搜集藏语农产品语料,然后进行聚类,识别出相应的主题,然后根据主题词,人工翻译成中文,据此采集相应的中文农产品语料。
本文主要从两个方面进行考虑:
(1)从支持藏汉双语的网站上进行采集
①搜集网页:确定藏汉双语主题相同的候选网站的平行网页,设计网页爬虫程序自动从这些网站尽可能提取藏汉双语主题平行的网页;
②提取网页内容:分析各网站的网页结构,并过滤非文本内容,主要提取网页的 Title、Body 和Time等内容,进行格式转换,添加标记,最后生成 XML 文件。
③XML 文件预处理:XML 文件进行初步的预处理,包括去除仅有单语言的文件、网页去重、非法字符过滤等。然后进行一些必要的人工检查和初的统计。如,删除每个文件中的图片标题、锚文本等不相关的文本内容;
④文档对齐:对预处理后的 XML 文件进行文档自动对齐,对结果进行人工检查和校对。
⑤文档类别标注:目的是为了后续进行跨语言分类分类和聚类的研究,从而建立跨语言文本分类语料库,先对部分藏汉双语文档使用 K-Means 算法聚类分析,确定文档的类别。使用 SVM 分类模型训练已标注类别的文档,然后对未标注的文档进行类别标注。根据文档内容进行人工类别标注进行校对和调整。
(2)先从互联网上的藏文网站采集有关藏文农产品新闻语料,然后对藏文新闻语料进行聚类分类,再找出类别主题词,将聚类出的所有类别的主题词翻译成中文,根据中文主题词搜索采集与之对应主题的中文可比语料。具体的可比语料存储举例如下所示:
1.双语相似性主题词抽取和共现主题词统计
本文针对文档主题对偶空间的表示和构建进行重点研究:综合考虑双语可比语料库的语义特性,即通过提取双语主题对构造主题对偶空间,由此构建词的语义关系和文档的语义关系。在信息检索中,一个主题(或者概念)可以理解为描述该主题的关键词项集合。本质上,除关键词项外的其余词与主题存在一定的相关性,在建模时赋予关键词更大的权重,而其余词赋予更小的权重。假如只考虑线性空间的方式,一个主题则表示为所有词项表的线性组合。
本文通过实验需设置一个阈值,并从双语主题中分别找出权重大于的词项(主题词),并根据这些主题词在文中的位置、上下文关系进行筛选,然后构建双语主题相关的主题词对应关系,本文称之为相似性主题词。根据抽取出的双语主题词,将其返回到与之对应的篇章结构当中,找出主题词所在句子中的上下文中的相关词,构建共现词网络。
2.基于藏汉双语电子词典的跨语言检索技术研究
本文采用基于词典的查询翻译策略,把藏汉双语电子词典与双语相似性主题词对进行结合。对于每个源语查询项,可以用电子词典中自动抽取的一种或多种目标语翻译进行替换[6],获取相应的正确目标语翻译知识,这样就在源语词典以及目标语词典之间建立起链接,对译词在目标语生成过程中就能获取。另外,为了提高搜索的召回率,在查询处理策略方面,根据现代同义词电子词典查询的扩展,再通过词共现网络进行消歧。
结语
中国是拥有56个民族语言的大国,把民族自然语言加入到现代科技信息技术中,促进了语言应用领域的拓展和原有应用领域的发展。本文通过分析研究自然语言处理的相关知识和技术,构建了面向电子商务平台的藏汉跨语言信息检索框架。本文研究工作还有很多不足之处,但为多种民族语言信息处理技术应用到其他领域提供了很好的实例和基础,进而打破语言障碍,增进各民族交流,加快社会经济发展和民族文化的进步。
参考文献
[1]王晓伟.基于机器翻译的查询结果Rerank技术[D].内蒙古大学,2011.
[2]郭宇锋.跨语言信息检索在机器人信息数据库中的应用研究[D].上海交通大学,2006.
[3]巩文婧.基于语言模型的跨汉蒙信息检索技术研究[D].内蒙古大学,2012.
[4]朱培焱,夏栋梁.汉英跨语言信息检索研究[J].计算机与现代化,2011,08:13-16.
[5]赵耀红.基于向量空间模型的信息检索系统的研究与實现[J].长春大学学报(自然科学版),2009,08:25-27.
[6]杨辉,张玥杰,张涛.基于词典的英汉双向跨语言检索方法[J].计算机工程,2009,16:273-277.
作者简介:朱琳(1990.9-),山东菏泽人,女,硕士研究生,研究方向为智能信息服务系统。
