大数据信息处理的MinMapReduce算法
2016-10-21杨茂保九江学院江西九江
□文/杨茂保(九江学院江西·九江)
大数据信息处理的MinMapReduce算法
□文/杨茂保
(九江学院江西·九江)
[提要]M apReduce对于大数据来说是主要的并行计算模型,理想情况下,M apReduce系统要在机器之间实现高度的负载均衡,并且最小化空间使用、CPU和I/O时间和每个机器上的网络传输。本文提出最小算法的概念,也就是算法能保证同一时间在多个方面的最好并行化,对于一组基本数据库问题来说,我们说明了最小算法的存在,通过实验我们证明了良好的性能。
M apReduce;M i nM apReduce;负载均衡
原标题:大数据信息处理的M i nM apReduce算法设计与实现
收录日期:2016年9月13日
一、引言
随着大数据时代的到来,数据以空前的速度在积累,对大数据信息处理提出了迫切的需求,级别达到T字节或者更高规模的巨大数据库、大数据具有规模巨大、分布广泛、动态演变、模态多样、关联复杂、真伪难辨等特性。对复杂数据的直观理解为挖掘出可靠而更有价值的信息,当前处理有限规模数据的计算体系已然失效。近年来,数据库研究人员对这一挑战做出来回应:构建巨大的并行计算平台,其使用数百甚至数千台商用机器,吸引了大量研究人员注意的著名的平台是MapReduce。MinMapReduce算法是一种新兴的有极大发展潜力的算法,MinMapReduce算法与许多传统数学分支相比具有很强的实时性,将其应用于大数据处理具备一定的理论和实践意义。
在一个高的级别,一个MapReduce系统包含很多无共享的机器,它们只通过在网络上发送消息来进行通信,一个MapReduce算法命令这些机器协作地来执行一个计算任务。最初,输入数据集被分布在这些机器上,主要是以非复制的方式,也就是,每个对象在一个机器上,算法以循环(有时在一些文献中称为jobs)的方式执行,每一个都有三个阶段:map,shuffle,和refuce,前两个使机器来交换数据:在map阶段,每个机器准备把消息传递给其他机器,在shuffle阶段,进行实际的数据传输,在reduce阶段没有网络通信发生,在此阶段每个机器执行来自本地存储的计算,在reduce阶段完成后,当前循环结束,如果计算任务没有结束,另一个循环开始。
MapReduce的目标是高的负载均衡,最小化空间、CPU、I/O和每个机器的网络开销,以前的做法相对少地关注在不同的性能指标上执行严格的限制,本文旨在研究算法,在多方面同时来突出效率。
二、M i nM apReduce算法的定义
最小MapReduce算法(MinMapReduce算法),S表示相关问题的输入对象的集合,n表示问题基数,即S中的对象个数,t表示系统中使用的机器数,定义m=n/t,即m表示每个机器上的对象个数(S均匀地分布在机器上),考虑解决S上的一个问题的算法,如果一个算法具有如下特性我们就说这个算法是最小的。
(1)最小占有空间:每个机器始终使用O(m)的存储空间。
(2)有限的网络通信:在每一个循环中,每个机器通过网络最多发送或者接收O(m)个字。
(3)常数个循环:算法必须在常数个循环之后终止。
(4)优化计算:每个机器总共只执行O(Tseq/t)数量的计算(也就是所有的循环求和),其中Tseq是在一个序列机上解决相同问题的时间。首先,每个机器总是占有数据集S的O(1/t),这可以有效地防止分区倾斜,分区倾斜会使一些机器被迫处理超过m个对象,这是在MapReduce中低效率的一个主要原因;其次,有限网络通信时间保证,每个循环的shuffle阶段转移至多O(mt)=O(n)个字,这个阶段的持续时间大致等于一个机器发送或者接收O(m)个字的时间,因为机器间的数据传送是并行的;第三,常数循环,这个不是新的性质,因为这也是先前的MapReduce算法的目标,优化技术重复了最初的MapReduce动机,t时间完成一个计算任务,比使用单个机器要快。
本文的核心包括最小算法的两个问题:
排序:输入是取自一个有序域的n个对象的一个集合S,当这个算法结束,所有的对象必须按排序的方式分布在t个机器上,也就是,我们可以从1到t来命令机器,以使机器i上的对象领先于机器j上的对象,其中,1≤i≤j≤t。
滑动聚合,输入包含:
——来自一个有序域的n个对象的一个集合S,其中每个对象o∈S与一个数值权重有关
——一个整数ι≤n
——一个分布聚合函数AGG(比如,sum,max,min)
用window(o)表示S中ι个不超过o的最大对象的集合,o的window聚合是将AGG应用于window(o)中的对象权值,滑动聚合是用来报告S中的每一个对象的window聚合。
在图1中,ι=5,黑点表示S中的对象,黑点上面的数值表示与对象相关的权值,图中的window(o),对于AGG=sum和max,window聚合分别为55和20。(图1)
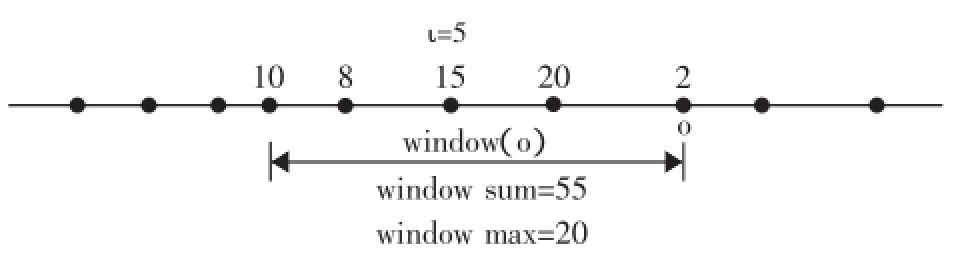
图1 Sl i di ng aggregat es
排序的重要性是很明显的:这个问题的一个最小算法可以导致几个基本数据库问题(包括排名、分组、半连接和分类属性)的最小算法。
第二个问题的重要性需要一点解释,滑动聚合在时间序列的研究中很重要,例如,考虑记录纳斯达克股市的历史指标中,需要每分钟一个数值,用来检验动态统计很有意义,也就是,汇总来自于一个滑动窗口的统计。例如,关于某一天的一个6个月的平均/最大值等于正好在那一天结束的6个月期间的平均/最大纳斯达克指标,6个月的所有天的平均/最大值可以通过解决一个滑动聚合来获得(注意,一个平均值可以通过使用周期长度ι来除以window sum来得到)。
作为排序,在MapReduce的发展中已经取得了一些进展,目前最先进的是TeraSort,当一个重要的参数设置适当,Tera-Sort接近于最小,这个算法需要人工调节这个参数,一个不当的选择可能导致严重的性能代价,Beyer等人在MapReduce中已经研究过滑动聚合,然而这个算法远没有达到最优,只有当window的长度ι很短时,这个算法才是有效的,有作者评论到,这个问题“非常困难”。
三、技术概括
首先,本文从理论上证明TeraSort为什么使用2个循环能实现优良的排序时间,在第一个循环中,算法从S中取一个随机样本集Ssamp,然后选择t-1个抽样对象作为边界对象,概念上,这些边界对象把S分成t段。在第二个循环中,t个机器中的每一个取得一个不同分段中的每一个对象,然后对它们进行排序,Ssamp的大小是效率的关键,如果Ssamp太小,边界对象可能不够分散,这可能会在第二个循环中引起分区倾斜,相反,如果Ssamp过大,会导致昂贵的抽样开销,在TeraSort的标准实现中,样本大小被留作一个参数,虽然它似乎总是承认一个不错的选择,提供了优异的性能。
本文中,我们对上面的现象给出了严格的说明,我们的理论分析阐明了如何设置Ssamp的大小来保证TeraSort的最小化,同时我们还弥补了TeraSort的一个概念上的缺陷,严格地说,这个算法在MapReduce中不很适合,因为它要求,(除了网络消息之外)机器应当能够通过读/写一个普通(分布)文件来进行通信,一旦一个循环失效,算法需要另一个循环。我们给出了一个解决办法,以使这个算法仍然能在2个循环内解决,即使是最严格的MapReduce。考虑到在MapReduce程序中排序的重要作用,我们的TeraSort调查结果有直接的实践意义。
关于滑动聚合,困难在于,ι不是一个常数,但是可以是任何值,直到n,直观地,当ι≫m,window(o)非常大,以至于window(o)中的对象不能在最小占有空间限制下在一个机器上发现,反而window(o)可能跨越很多机器,这必须要明断地进行机器搜索,以避免灾难性的开销放大,实际上,这个缺陷已经引出了的现有算法,它的主要思想是确保,每一个滑动窗口被发送到一个机器来进行聚合(不同的窗口可能到达不同的机器),当window的长度很长的时候,这会遭受到高昂的通信和处理成本,但是,我们的算法使用新的想法(在机器之间完美地均衡输入对象,同时保持它们的顺序)实现了最小化。
四、相关工作
Map阶段产生一系列的key-value对(k,v);Shuffle阶段把key-value对分布在各个机器上;Reduce阶段合并得到的所有key-value对。
算法的简化。我们把Map和Shuffle合并,这个简化只是逻辑层面的,物理上我们的算法还是按标准的MapReduce模式。
无状态容错。一些MapReduce实现(比如,Hadoop)要求,循环结束后,每个机器应当把它的存储中的所有数据传送给分布式文件系统(DFS),在我们这里可以理解为“磁盘在云中”,保证一致性存储(也就是,从来都这样),目标是,在算法执行中一个机器崩溃的情况下,来提高系统的鲁棒性,在这种情况下,系统会用另一个机器来代替这个机器,在前一个循环结束的时候,会要求这个新机器来下载旧机器上的所有存储,重新做当前的循环(发生故障的那个机器的),这样的一个系统被称为无状态,因为直观上没有机器负责记住算法的任何状态。
在定义的四个最小化条件保证无状态的高效执行,特别是最小化占用空间保障了,在每一个循环,每一个机器发送O(m)个单词给DFS,这与有限的通信是一致的,MapReduce的研究分为两类,提高框架的内部工作,和应用MapReduce来解决具体问题,S是来自一个有序域的n个对象的一个集合,S分布在t个机器上,每个机器排序O(m)个对象,其中m=n/t,排序结束后,机器i上的对象领先于机器j上的对象,其中,1≤i≤j≤t。
五、结论
虽然有很多的MapReduce的算法提出,但是很少能够实现理想的并行化的目标:机器间的负载均衡、线性于机器数量的一个顺序算法上的加速比,特别是,当且在概念层级上,关于什么是一个“好的”MapReduce算法,还是一个空白。
我们用一个新的概念“MinMapReduce算法”填充了上述的空白,最小化的条件似乎相对严格,然而,我们证明了简单而高超算法的存在性,它最低程度地解决了一些重要的数据库问题,我们的实验说明了通过最小化带来了直接效果。
主要参考文献:
[1]李建江,崔健,王聃,严林,黄义双.M apReduce并行编程模型研究综述[J].电子学报,2011.11.
[2]秦军,童毅,戴新华,林巧民.基于M apReduce数据密集型负载调度策略研究[J].计算机技术与发展,2015.4.
[3]李士刚,胡长军,王珏,李建江.异构多核上多级并行模型支持及性能优化[J].软件学报,2013.12.
[4]刘义,陈荦,景宁,熊伟.利用M apReduce进行批量遥感影像瓦片金字塔构建[J].武汉大学学报(信息科学版),2013.3.
[5]孔祥勇,高立群.求解大规模可靠性问题的改进差分进化算法[J].东北大学学报,2014.35.3.
[6]常耀辉,隋莉莉,汪传建.一种基于M apReduce可公开验证数据来源的水印算法[J].电子技术与软件工程,2015.6.
[7]毕晓君,张永建.高维多目标多方向协同进化算法[J].控制与决策,2014.29.10.
九江学院校级科研课题(2014K JY B030);江西省高校省级教改项目(JX JG-14-17-10);江西省高等学校大学生创新创业计划项目(8891209)
F49
A
