网页抓取中爬虫控制器的研究分析
2016-10-21孙海涛
孙海涛
(中移全通系统集成有限公司,河北 石家庄 050000)
网页抓取中爬虫控制器的研究分析
孙海涛
(中移全通系统集成有限公司,河北 石家庄 050000)
随着互联网的日益壮大,网页抓取技术飞速发展。网页抓取已成为人们在浩瀚的网络世界中获取信息必不可少的工具,如何有效进行网页抓取成为专业搜索引擎中网络爬虫研究的主要问题。文章介绍了爬虫控制器和工作原理,并讨论了爬虫控制器的URL队列管理、页面抓取线程、索引队列管理等的抓取策略,并对其未来发展趋势进行了展望。
爬虫控制器;队列管理;线程;索引
爬虫控制器是把网页抓取和网页分析用多线程的方式执行,并管理多线程之间的数据共享和通信;加上索引相关模块,爬虫控制器大致可以分为4个部分:(1)统一资源定位符(Uniform Resource Locator,URL)队列管理;(2)页面抓取线程;(3)索引队列管理;(4)索引线程。
其中两个队列管理需要处理资源共享问题,线程部分需要处理线程间通信问题。
1 URL队列管理
因URL队列须保证URL的唯一性,以保证每个链接指向的页面只抓取一次;而抓取页面的工作是由多个线程同时进行,所以URL队列需要保证线程操作安全。所以该队列还必须包含唯一性判断和线程安全。URL队列管理如图1所示。
在向队列中追加URL时,把数据写到URL尾部,而读取URL时,从队列头部开始以保证先进先出队列(First Input First Output,FIFO)规则,追加数据完成后需要通过所有的页面抓取线程,使没有工作的线程可以启动抓取数据。若URL的值为空时,读取线程进入等待状态。
2 页面抓取线程
页面抓取涉及http下载、GZip解压缩和编码转换的问题,单个线程的主要功能如图2所示。

图1 URL队列管理示意图
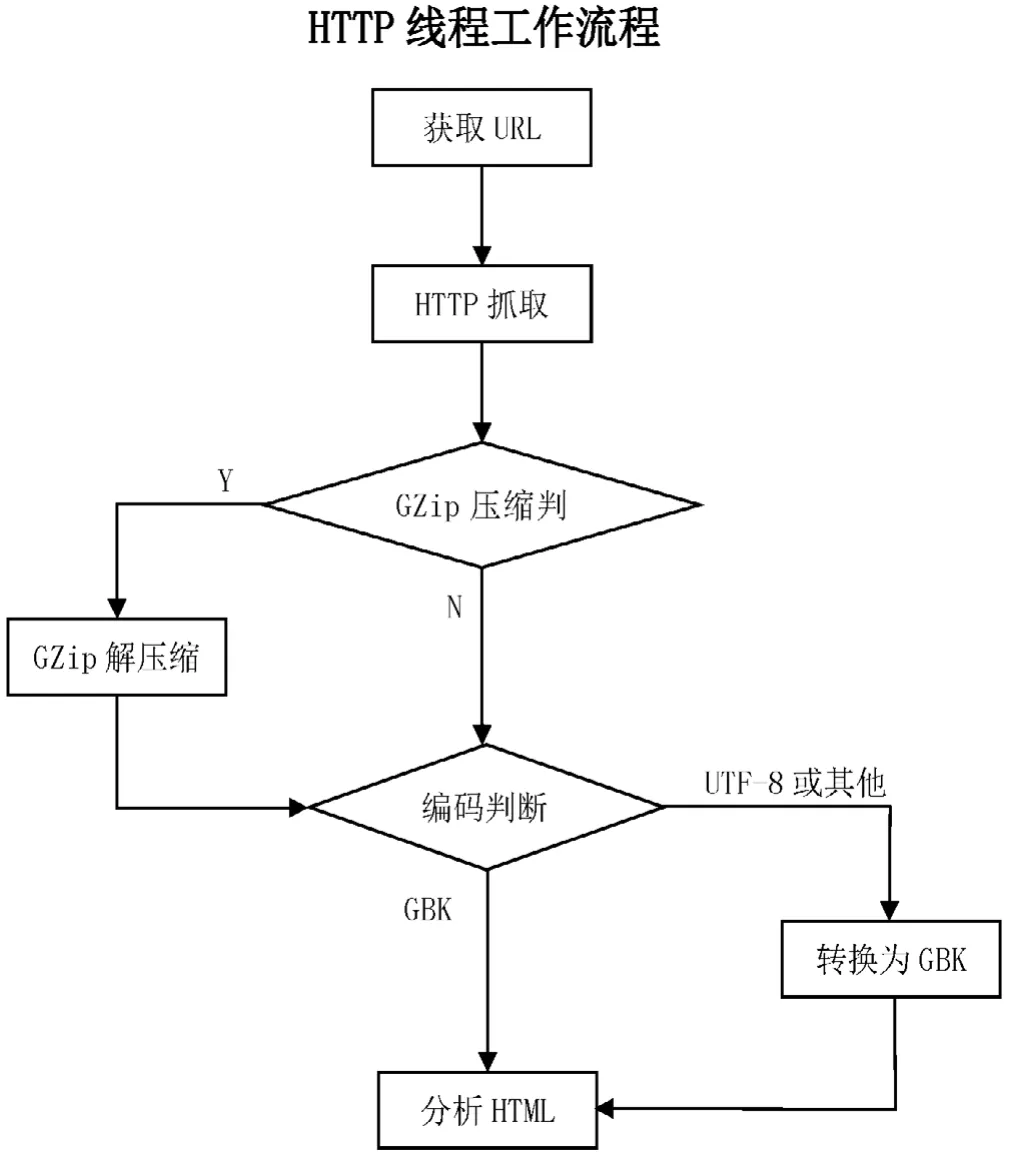
图2 HTTP抓取线程流程图
因URL队列可能提供的数据为空,此时页面抓取线程就必须等待通知,此通知由URL队列模块发出,以被告知URL已经有数据可用,则线程继续执行下一步操作。
3 索引队列管理
索引队列作为Http抓取线程与索引线程交换数据的媒介存在,是典型的生产者—仓库—消费者模型的仓库模块部分。该队列涉及多线程互斥、线程间通信等内容,如图3所示。
索引队列为索引线程和抓取线程提供数据交换媒介,抓取线程在往队列中追加数据的同时会通知索引线程。索引线程在等待状态时,收到通知则继续工作;若索引线程正在工作中,则通知被抛弃。
4 结语
在如今信息爆炸的社会中,网络成为人们生活中不可或缺的工具,而搜索引擎又在其中扮演着至关重要的角色。网页抓取是一个实用性很强的研究领域,无论是网络爬虫、数据库管理、中文分词还是索引的建立方法,都值得深入了解。但近年来,随着良莠不齐的各类爬虫频繁出没,一些网站也承受着由爬虫带来的困扰,这些都是今后有待解决的问题。
Analysis on Web crawler controller
Sun Haitao
(China Mobile Quantong System Integration Co., Ltd., Shijiazhuang 050000, China)
With the growing of the Internet, the Web crawler technology develops rapidly. Web crawling has become an indispensable tool for people to obtain information in the vast network world. How to effectively make web crawler become the main problem in the research of Web crawler in professional search engine. Crawler controller and the principle of work is introduced in this paper, and it discusses the crawler controller URL queue management, page thread crawl, index queue management crawling strategy, and looks forward to its future development trend.
crawler controller; queue management; thread; index

图3 索引队列工作示意图
孙海涛(1978— ),男,河北石家庄。
