基于网络资源的kNN网络流量分类模型的研究
2016-10-19程珊,钮焱,李军
程 珊, 钮 焱, 李 军
(湖北工业大学计算机学院, 湖北 武汉 430068)
基于网络资源的kNN网络流量分类模型的研究
程珊, 钮焱, 李军
(湖北工业大学计算机学院, 湖北 武汉 430068)
为了快速有效的识别网络流量中的攻击行为,根据同一类应用对网络资源的消耗具有相似性,不同类应用对网络资源的消耗具有差异性,提出了一种基于网络资源的kNN流量分类模型。该模型可以从多种网络资源中选取三种属性作为特征,采用改进的 kNN 算法进行流量检测,对网络中的各种流量特别是攻击类流量尽可能快速并有效的识别,给网络防御的启动提供重要依据。实验结果表明:改进的kNN算法在保证识别率的同时有效提高分类的速度。
流量识别 ; kNN; 网络资源; 网络攻防
随着网络应用不断丰富,以及各种隐藏在网络流量中的恶意威胁,网络的各种资源变得紧张,导致网络性能不断下降甚至崩溃。由于各种网络行为的表现形式是流量,各种网络行为隐藏在流量中,因此需要对网络流量进行识别:一方面,可以识别出需要占用大量资源的正常流量,调用相应的资源提高网络的服务质量。另一方面,大部分的攻击表现为对网络资源的争夺,可以通过网络资源的占用情况识别出网络攻击流量,作为启动防御措施的重要依据。因此,有必要寻求一种网络流量识别模型对网络中的各种流量特别是攻击类流量尽可能快速并有效地加以识别,以便采取措施预防网络崩溃。
目前国内外提出了很多关于流量的识别与分类的方法。传统的网络流量识别技术主要有基于端口识别与深层数据包检测的协议识别方法[1]。但是随着动态端口以及协议加密技术的应用,上述方法的应用范围越来越窄。近几年机器学习方法广泛应用于流量分类,主要有贝叶斯[2]、k-means[3]、支持向量机SVM[3-4]、C4.5决策树[5]、神经网络[6]、kNN[7-9]等。
相比较其他的方法,kNN算法有很多优点:它简单易实现,可以处理大量的类别,而且kNN算法还能支持流量的更多特征的高维计算,而特征的数量会直接影响分类的效果。但是kNN算法也存在不足。kNN算法在对未知样本分类时,时间消耗很大。本文尝试应用改进的kNN算法与网络资源结合进行流量分类,以期在保证分类效果的同时有更低的时间消耗。
1 kNN算法
k-最近邻分类法(kNN)最初由 Cover 和 Hart提出,此后它广泛应用于模式识别领域。kNN算法是基于类比学习,即通过将给定的检测样本与和它相似的训练样本进行比较来学习。kNN算法的基本思想是:先计算待分类样本与已知类别的训练样本之间的相似度,相似度一般使用欧氏距离测量,依据相似度找到与待分类样本数据最相似的k个邻居,再根据这些邻居所属的类别来判断待分类样本数据的类别,将待分类样本指派到它的k个邻居中权重最大的类别。
待分类样本d(x1,x2,…,xn)和训练样本di(y1,y2,…,yn)的相似度计算公式为:
(1)
待分类样本d和每一类cj的权重的计算公式为:
y(di,cj)是类别属性函数,如果di属于cj,那么函数值为1,否则为0。
最后的分类决策函数
f(θ)=argmaxcj(p(d,cj))
将待分类样本d归属于权重最大的那个类别。
通过上述算法介绍我们可以看出,kNN的分类思想和过程比较简单,但是当训练样本集较大时,相似度的计算量很大,算法的时间开销过大。因此可以对其进行改进。
2 改进的kNN算法
kNN算法简单易实现,支持高维计算,分类效果明显,但是在寻找k个最近邻样本的时候,需要将测试样本逐一与训练样本比较相似度,因此计算量庞大,会直接影响分类的速度[10]。而网络流量识别在很多应用场合需要有较高的实时性。减少需要比较的训练样本数量不失为提高分类效率的有效方法。
2.1基本思想
根据kNN算法的近邻规则可知,测试样本的最近邻主要分布在靠近测试样本的区域内。与测试样本距离较远的训练样本,对分类结果影响较小,基于此,可以将训练样本进行适当的裁剪,只需保留位于测试样本附近区域的训练样本。但是随意确定裁剪区域的大小是不合适的。如果裁剪区域太小,会裁减掉过多的训练样本,影响分类效果。裁剪后的范围过大,需要比较的训练样本数量依然很多,不会明显提高分类效率。
根据样本类别的不同可分为多个样本子集,每个样本子集是一个聚类。对于一个聚类,它的所有样本都围绕着一个类中心分布。由kNN算法选取出来的k个邻居,只会分布在靠近类中心和测试点之间的空间上, 可以根据类中心和测试样本的位置来确定裁剪区域的位置和大小。
2.2样本集裁剪规则
为每一个类指定一个类中心,类中心为每一个聚类的中心点。计算公式如下:
第j类样本的类中心
且
(i=1,2,…,n;j=1,2,…,g)
(2)
Nj是第j类样本的数量,ymi是第m个样本的第i个属性值。
样本集的裁剪规则如下:为每一个聚类确定一个类中心O,利用公式(1)欧氏距离公式计算测试样本到每一个类中心的距离r。然后确定剪裁区域的位置。将测试样本点d(x1,x2,…,xn)作为球心,将最短距离rmin作为半径,做球体的外接立方体。对于每一个训练样本di(y1,y2,…,yn),如果位于立方体区域内,即
则这个训练样本保留。否则,予以去除,即裁减掉位于立方体区域外的训练样本。可将保留的所有训练样本定义为一个新的训练样本集合S,用裁剪后的样本集S代替大量的原始样本,进行kNN分类。
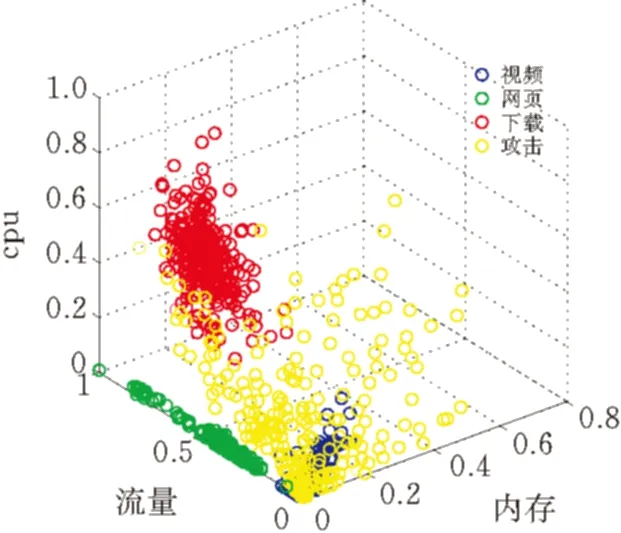
为了更清楚的说明裁剪规则,下面以具有三维特征的样本为例说明样本裁减方法。
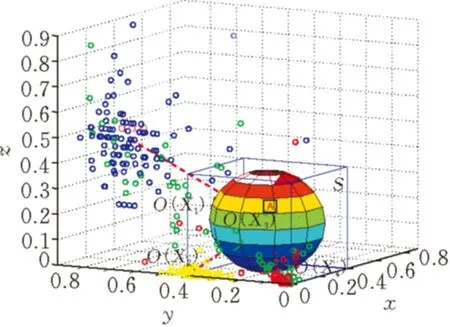
图 1 样本集裁减示意图
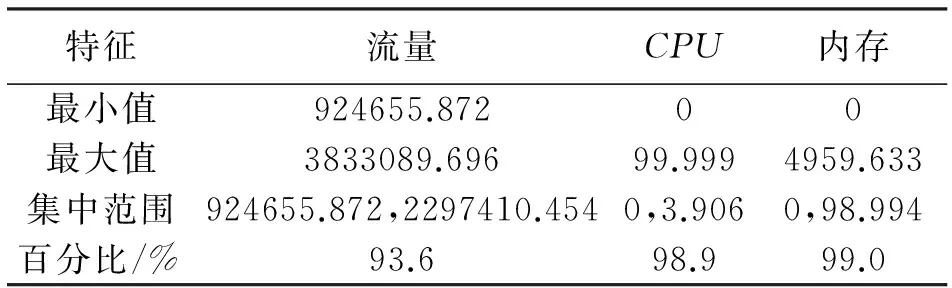
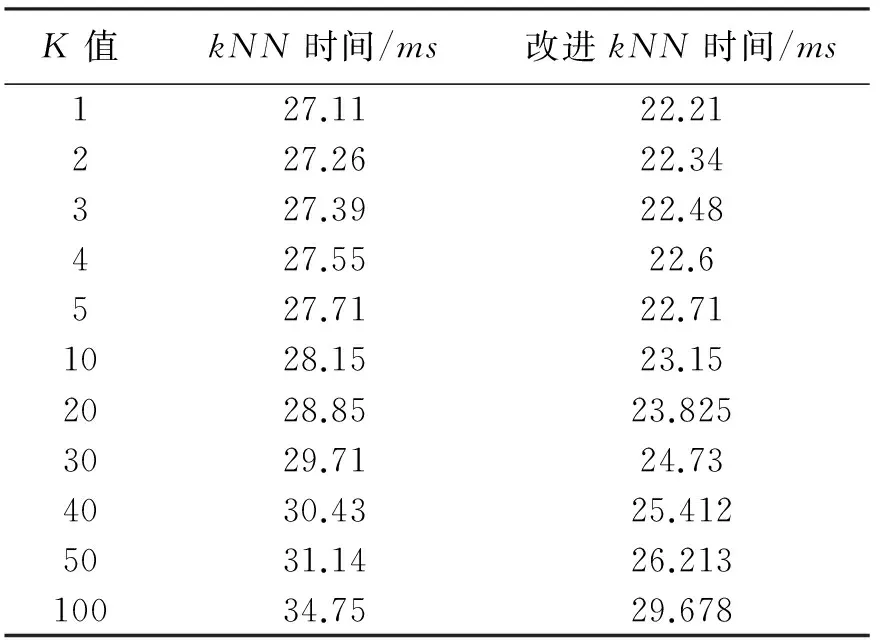
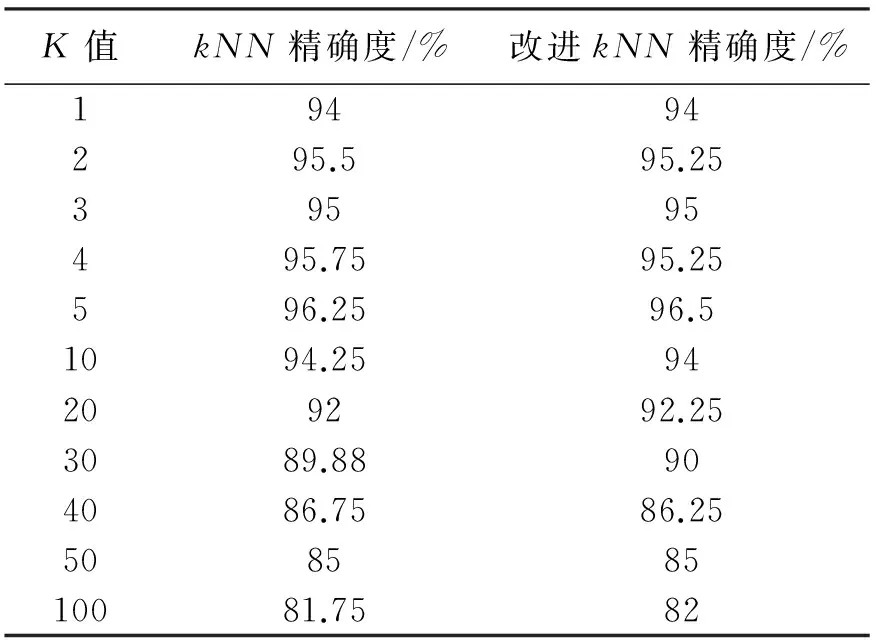
设某个训练集的分布如图1所示,其中有4个类别X1、X2、X3和X4,由公式(2)可计算出它们的类中心分别为O(X1)、O(X2)、O(X3)和O(X4)。A(a,b,c)是测试样本。A到类中心点O(X1)、O(X2)、O(X3)和O(X4)的距离分别是r1、r2、r3、r4(r3 则这个训练样本保留。裁减掉位于矩形区域外的训练样本。通过以上方式的裁剪,得到裁剪区域S。显然,对比分布在裁剪区域S内部和外部的样本与A的相似度,内部的相似度更大。此时,分布在S中的训练样本数量远少于原始的训练样本数量。只需比较A点与S中的训练样本的相似度,而不是整个训练样本。在S而不是整个空间中选出k个最近邻,再根据选出的k个最近邻所属的类别来判断待分类样本数据的类别,将待分类样本指派到它的k个最近邻中权重最大的类别,完成A点的分类。 2.3时间复杂度分析 设训练样本集为D,其中包含α个训练样本,由β种类别的样本组成。设测试样本集为T,其中包含γ个测试样本。每个训练样本和测试样本都是由n维特征属性组成。传统的kNN算法的时间复杂度是O(α×γ)。用改进的kNN算法,先计算β个类中心,针对每一个测试样本都要进行一次训练样本集D的裁剪,假设裁剪后的训练样本集的规模的平均值为μ,μ≪α。裁剪样本的时间可以忽略不计。再将γ个测试样本和裁剪后的μ个训练样本进行比较,改进后的kNN算法时间复杂度是O(μ×γ)。由于μ≪α,所以很明显,改进后的kNN算法比传统kNN算法更有效率。 3.1流量分类模型 流量分类模型由数据收集及预处理模型、特征选择模型、流量分类模型组成(图2)。 数据收集及预处理模块定期向服务器发送网络资源数据收集请求,服务器将回复的资源使用情况的数据传送给数据收集节点。 特征选择模块负责接收数据收集模块收集到的数据,提取出与网络行为相关的3个特征组成三元组,每个三元组都以网络行为作为标识。 流量分类模块负责将收集到的三元组通过改进的kNN算法进行分类,以此来区分某时刻的流量是否是攻击流量或者是来自于哪种应用的流量。特征选择和流量分类模块是此模型尤为关键的部分。 图 2 流量分类模型 3.2特征提取 网络资源包含吞吐量、带宽、时延、CPU资源、存储资源、磁盘资源等。同一类应用对网络资源的消耗具有相似性,不同的应用会消耗特定的网络资源[11]。 表1、表2和表3中的数据采集于实验室,分别说明了视频播放、网页浏览、DDOS攻击三种行为对网络资源消耗的相关性。表中分别列出了收集到的网络流量的3个特征:流量、CPU和内存的最小值和最大值,通过分析数据,发现这些特征值都集中在某个范围内。 表1 播放视频产生的流量的相关性 表2 浏览网页产生的流量的相关性 表3 模拟DDOS攻击产生的流量的相关性 从数据集中可以观察到:相同行为消耗的资源,有很大的相似性和相关性,特征值大部分集中在很小的范围内。例如,表1中流量的值的范围是391.998到8983565.233,但是大约98.1%的样本在[391.998,2985979.052]内。CPU的值的范围是0到99.999,但是大约98.5%的样本在[0,16.797]内。 将表1、表2中的数据进行比较,播放视频消耗的内存的范围是[0,548.546],产生的流量的范围是[391.998,2985979.052];浏览网页消耗的内存的范围是[0,98.994],产生的流量的范围是[924655.872,2297410.454]。明显地,和浏览网页相比,播放视频对内存的消耗更大,同时会产生大量流量。不同的应用对资源的消耗具有差异性。 对比表1、表2和表3的数据,三种网络行为对CPU和内存的消耗存在极大的不同。例如,播放视频消耗的CPU集中范围是[0,16.797],消耗的内存集中范围是[0,548.546];浏览网页消耗的CPU集中范围是[0,3.906],消耗的内存集中范围是[0,98.994];DDoS攻击消耗的CPU集中范围是[0.007,27.739],消耗的内存集中范围是[12.976,3970.914]。对比发现,DDoS攻击行为会消耗大量的CPU和内存资源。由此可见,网络行为中,CPU和内存资源尤为重要。 针对同一类应用对资源的消耗存在很大的相似度和相关性,不同的应用对资源的消耗存在明显的差异性,可以网络资源的联合分布作为特征属性,对流量进行分类,从而在必要时调集所需的资源优化网络性能改善用户的体验,或者在识别出攻击行为时,及时启动防御措施,保护网络的安全。 在众多的网络资源中,CPU与内存尤为重要,网络中的CPU资源和内存资源是网络中重要的资源,网络行为基本上离不开这两个资源的支持,很多时候交换机、路由器会因为这两个资源的耗尽导致网络性能下降直至崩溃,可以依据CPU与内存的特征属性,对网络流量进行分类。网络行为通常隐藏在流量中,故选择流量、CPU和内存作为特征属性,反映网络性能的变化。 3.3基于改进kNN算法的网络流量分类 根据改进的kNN算法,按照以下步骤构建网络流量分类模型。 依次输入不同类型的样本流量作为训练样本集合。 其中,Nj是第j类流量的样本数目。 Step2:分别计算新流入的网络流量fx到每一个类中心的距离。 Step3:将β个距离由小到大依次排列,选择最小的距离作为半径r。 r=min{dist(fx,oj)} Step4:以fx所在位置为圆心,以r为半径,作一个球体的外接立方体。确定集合D中的流量是否分布在立方体区域内。判断方法如下: 满足条件即位于立方体区域内,反之位于立方体区域外。 Step5:裁剪掉位于立方体区域外的流量样本点,形成一个有γ个流量样本点的新的流量集合S。 Step6:设定k值。 Step7:计算待分类的流量fx与集合S中的γ个流量样本点的相似度。 其中, Step8:将相似度从大到小依次排列,选出k个相似度最大的流量。 Step9:在这k个流量中,依次计算每个类别的权重。流量fx属于Cj类的权重计算公式为: y(fi,cj)是类别属性函数,如果fi属于cj,那么函数值为1,否则为0。 Step10:比较类的权重,将流量fx分到权重最大的那个类别中。 f(θ)=argmaxcj(p(fx,cj)) 先构造一个网络,通过服务器对互联网分别进行网页浏览、文件下载和视频播放访问,另外,可以使用LOIC进行基于HTTP的DDOS攻击来模仿异常流量的产生。通过服务器性能监视器的数据收集器,分别收集以上4种行为所消耗的流量、CPU和内存的数据。将收集到的样本数据分成四大类:网页类、下载类、视频类和攻击类,按照每个类别随机选取500个样本点,一共2000个样本点。因为kNN算法要求训练样本集的类型分布尽可能平均,因此每个类别的训练样本数目应保持一致。四种类别的样本数据各取前300个样本点作为训练样本集,后200个样本点作为待分类样本集。分别采用kNN和改进kNN对待分类流量进行分类。四种行为的训练样本分布见图3。 图 3 四种行为的训练样本分布 本文采用精确度对模型的分类能力进行评估以及使用分类时间来评估分类模型的开销。 分类时间是指分类模型对网络流量所属类型进行判别的时间。 最终测试结果见表4和表5。 表4 kNN和改进的kNN时间比较 表5 kNN和改进的kNN精确度比较 从表4中可以看到,改进kNN的分类时间比传统kNN的要短。改进kNN花费平均24.12ms进行分类,然而传统的kNN需要花费平均29.19ms进行分类。从表5中可以看到,改进kNN算法的精确度和传统kNN算法精确度相差不大。因此,裁剪数据集并未影响分类的精确性。实验结果表明,改进kNN算法有效提高分类的速度。 提出了一种基于网络资源的kNN流量分类模型,该模型从多种网络资源中选取流量、cpu、内存作为特征,采用改进kNN算法进行流量检测,对网络中的各种流量特别是攻击类流量尽可能快速并有效地识别,给网络防御的启动提供重要的依据。实验结果表明:方法有效可行,在保证精确度的前提下提高了分类的速度。 [1]Qosmos.Deeppacketinspectionandnetworkintelligencetools[EB/OL]. [2016-01-05]http://www.qosmos.com/. [2]AuldT,MooreAW,GullSF.BayesianneuralnetworksforInternettrafficclassification[J].IEEETransactionsonNeuralNetwork, 2007,18(1) :223-239. [3]刘三民,孙知信,刘余霞. 基于K均值集成和SVM的P2P流量识别研究[J]. 计算机科学,2012(4):46-48,74. [4]顾成杰,张顺颐. 基于改进SVM的网络流量分类方法研究[J]. 仪器仪表学报,2011(7):1507-1513. [5]周剑峰,阳爱民,刘吉财. 基于改进的C4.5算法的网络流量分类方法[J]. 计算机工程与应用,2012,48(5):71-74. [6]谭骏. 基于自适应BP神经网络的网络流量识别算法[J]. 电子科技大学学报, 2012, 41(4):580-585. [7]SuM.UsingclusteringtoimprovethekNN-basedclassifiersforonlineanomalynetworktrafficidentification[J].JournalofNetworkandComputerApplications,2011,34(2): 722-730. [8]DuM,ChenX,TanJ.AnovelP2PtrafficidentificationalgorithmbasedonBPSOandweightedkNN[J].ChinaCommunications, 2011,8(2): 52-58. [9]WuD,ChenX,ChenC,etal.Onaddressingtheimbalanceproblem:acorrelatedkNNapproachfornetworktrafficclassification[C]// 8thInternationalConferenceNetworkandSystemSecurity.Xi’an,China:Springer, 2014: 138-151. [10]卜凡军.kNN算法的改进及其在文本分类中的应用[D].苏州:江南大学,2009. [11]PengX,WenyuQ,HengQ,etal.DetectingDDoSattacksagainstdatacenterwithcorrelationanalysis[J].ComputerCommunications, 2015, 67: 66-74. [责任编校: 张岩芳] A Study on Network Traffic Classification Model of kNN Based on Network Resources CHENG Shan,NIU Yan, LI Jun (SchoolofComputerScience,HubeiUniversityofTechnology,Wuhan430068,China) With the substantial growth of network users and network applications, the attack behavior which is hidden in thetraffic seriously affects the quality of network service. How to identify the networktraffic quickly and effectively is one of the keys in network security. According to similarities in the consumption of the network resources by the same sort of applications, and the differences in the consumption of the network resources by different applications, this paper proposes a networktraffic classification model of kNN based on network resources. The model can be used to select three attributes as its own feature from a variety of network resources, and it uses improved kNN algorithm to detecttraffic. It can also identify all kinds oftraffic in network as fast and effectively as possible, especially the attacktraffic. It can be used as an important basis for the enablement of network defense. The experimental results show that the improved kNN algorithm can improve the speed of the classification effectively while ensuring the recognition rate. traffic classification;kNN;network resources;network attack and defense 2015-09-25 湖北省教育厅科学研究计划资助项目( D2014403) 程珊(1992-),女,湖北孝感人,湖北工业大学硕士研究生,研究方向为网络安全 1003-4684(2016)04-0075-06 TP393 A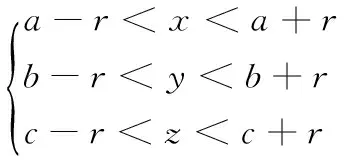
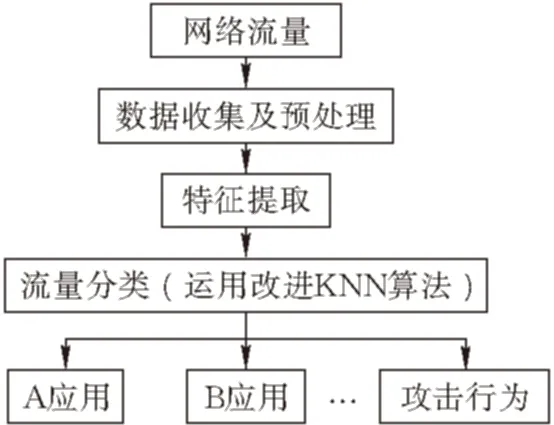
3 基于改进kNN算法的网络流量分类模型
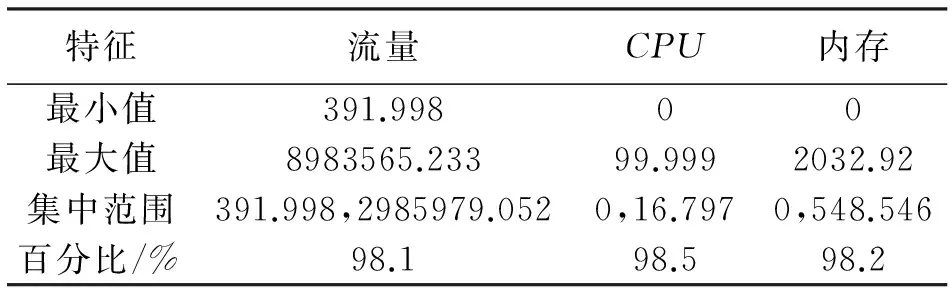

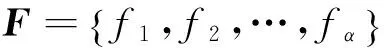
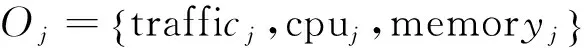
4 实验及分析
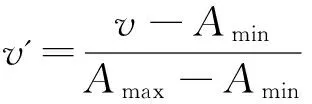

5 结论
