基于Prank算法的推荐技术研究与应用
2016-10-18张栩晨
张栩晨
基于Prank算法的推荐技术研究与应用
张栩晨
随着互联网的普及与发展,网络上信息与日俱增,但用户却越来越难以在有限时间内找寻到想要的信息。推荐系统是解决这一问题的重要方法之一,推荐系统可以根据用户历史行为分析出用户需求来进行推荐,使用户快速的、准确的做出选择。研究在推荐系统上应用Prank算法,Prank算法是信息检索领域经典的排序学习算法。它可以快速地训练一组特征与排序的关系,做出准确的预测。本文将Prank算法改进以适应Top-N推荐问题,与推荐系统上著名的Item-based,User-based,SVD model算法进行横向比较,通过大量实验给出各算法的优缺点。Prank算法在推荐准确度,推荐多样性问题上取得了较为不错的实验结果。
推荐系统;Prank算法;推荐模型;排序学习
0 引言
随着互联网的普及和发展,互联网上的信息与日俱增。用户喜欢从海量信息中挖掘自己感兴趣的信息,但负面效果是用户很难从过于庞大的信息当中找到想要的信息,所花费的时间精力也与之相应增加。推荐系统是解决这一问题的切实可行的方法。从定义上说,推荐系统在电子商务网站上决定着给用户提供哪些商品的信息,给用户提供应该购买什么产品的建议,一定程度上是现实中商店售货员给客户推荐物品过程的模拟。推荐系统可以根据用户不同的需求来进行推荐,推荐还可以根据用户历史购买记录所呈现出的兴趣对每个用户建立不同的模型。一个成功的推荐系统是能够发现用户的潜在兴趣,对用户提供最优质的推荐服务,进而使用户对推荐系统产生依赖感。另一方面,好的推荐系统并不一定为了提高用户的购买量而只推荐那些热门的商品,而同时考虑冷门商品带给用户的惊喜的可能性,进而提高用户体验,这被称为推荐的多样性[5]。
个性化推荐是推荐系统的核心,对于不同的用户,用户兴趣千差万别,用户需求随之存在巨大差距,为此个性化推荐系统应运而生。个性化推荐系统可以根据不同的用户建立不同的模型,建模可以用到用户自己填写的兴趣、爱好等,也可以利用用户的购买记录及评分、浏览记录、搜索记录、客户所在城市等等。个性化推荐系统是真正意义上的推荐系统,可以根据用户历史行为为用户量身定制推荐,所以,个性化推荐系统较以往的非个性化推荐系统有着更好的推荐效果。
本文所做工作是将排序学习的经典算法Prank[1-2]应用到推荐系统上,并加以改进进而实现个性化推荐。在推荐系统中,对用户进行Top-N推荐是研究的热点,Top-N推荐可以理解为根据用户历史行为给用户以一定序列推荐N个物品。它实质上是排序问题,将待推荐商品进行评估、排序后推荐。以这个点出发,本文将在信息检索与排序学习领域热门算法Prank应用到推荐系统上来,并予以改进应用。Prank算法的特点是可以较为清晰的描述用户特征,能够对排序做很精确的预测。本文首先改进应用Prank算法,以用户历史购买记录作为商品特征进行训练出模型,利用模型推荐以达到个性化推荐的目的。其次,将Prank算法与当下流行的Item-based[3],User-based[4],SVD model推荐算法进行横向比较,Prank算法在Top-N推荐多样化问题上得到了较为不错的结果。本文的核心贡献如下:
1)实现Prank算法并设计其应用到推荐系统的方式。
2)利用大量实验分析Prank算法在推荐准确度与推荐多样性上的效果,Prank算法在个性化推荐上取得了不错的效果。
1 相关工作
1.1 协同过滤
协同过滤[7]算法是推荐系统中最早的方法之一,直到今天推荐效果仍然很好,广泛被工业界采用。它可以首先找出与此用户兴趣相似的用户,这些兴趣相似的用户被称为此用户的近邻,近邻感兴趣的内容会被推荐给此用户。这与现实中接受亲朋好友的推荐购买商品道理上是相通的。或者通过找出与此商品相似的被用户历史评价过的商品,来完成对此物品评分的估计。协同过滤往往利用该用户的邻居用户(或该物品的邻居物品)对商品的评价进行加权平均来获得用户对该商品的好感度,而这一好感度可以被用来排序,排在前面的商品会被推荐。
协同过滤会隐式地分析用户的兴趣,分析商品的特征,一些不符合用户口味的商品就被过滤掉。另外,协同过滤与其他推荐算法相比,能够潜在的发现用户的兴趣。典型的协同过滤算法分为Item-based算法和User-based算法,它们分别计算物品与物品、人与人之间的相似度,利用邻居帮助预测用户打分。
2.2SVD model算法
SVD model算法是基于模型的推荐算法中很重要的部分,它利用机器学习算法对每个用户与商品训练出一个向量,利用向量的积来表示用户对该商品的喜爱程度,进而进行推荐。在用户电影的数据集中,某一隐藏维度可能代表动作片,用户向量在该维度上代表着他对此类电影的喜爱程度,而电影向量在该维度上代表着这个电影属于动作片的程度。
SVD首先确定用户与物品向量的维度k,对每个用户u和物品i生成一个初始的向量pu和qi。对于每一个预测评分Rui=bu+bi+pTu∗qi。其中bu是用户u的偏好,q_i是物品i的被喜爱偏好。例如某一用户喜欢比其他用户平均分打出略低的分数,bu=-0.2。而《泰坦尼克号》特别受欢迎,qi=0.5。所有参数通过最小化损失函数,进行训练,进而拟合模型。损失函数如公式(1):
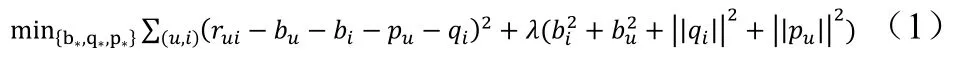
最小化损失函数使用随机梯度下降方法,最小化上式,以达到拟合模型的目的,其中λ为防止过拟合参数,公式右侧整项是为防止过拟合设置的惩罚项。
参数更新法则如公式(2-5)

其中a为学习速率。
2 Prank算法在推荐系统上的应用
2.1排序学习与Prank算法
Prank算法具体过程如图1所示:

图1 Prank算法流程
2.2Prank的应用
模型训练过程:
对任何一个用户u进行如下过程
Top-N推荐预测过程:
3 实验
3.1数据集与Top-N推荐测试方法
实验数据集为MovieLens,包含大小为100k,1M,10M 3个部分,本文主要采用100k,1M的数据集进行实验与分析。每个数据集包含用户对物品的评分。
对推荐系统进行评价的方法中,Top-N推荐是一个重要的研究方向,其含义是对用户推荐N个物品,观察用户对这N个物品的态度。具体方法是对每个用户购买过的物品,从中抽取10%放入测试集合,另外90%作为训练集合,剩下的未购买物品与测试集合共同输入给算法,算法从中挑选出N个物品作为Top-N推荐给用户,观察这Top-N个物品与测试集合的交集的数目与N的比值即为对该用户的precision。将所有用户的precision取平均数即为该算法的效果衡量指标。
在信息检索领域,准确度precision是衡量系统准确性的重要指标。定义如下:
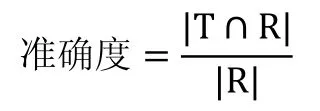
其中T代表实际用户购买的商品,R代表所有做出的推荐。
2)推荐准确度的比较
通过对本文实验数据的总结,在Top-N=10,20,数据集大小为100k,1M情况下,可以对4种算法做推荐取得的准确度进行对比,结果如图2至图3所示:
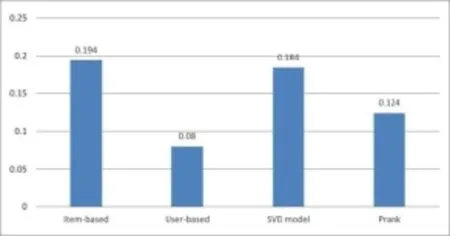
图2 4种算法在100k数据集上Top-10推荐准确度比较
在100k数据集上做Top-N=10推荐,Prank算法准确度达到0.124,低于Item-based算法的0.194和SVD model算法的0.184。在Top-N=20推荐上,Prank算法准确度达到0.095。
在1M数据集上做Top-N=10推荐,Prank算法准确度达到0.119,而Item-based算法准确度达到0.177。在Top-N=20推荐上,Prank算法准确度达到0.096,SVD model算法达到0.109,略高于Prank算法。如图4、图5所示:

图4 4种算法在1M数据集上Top-10推荐准确度比较
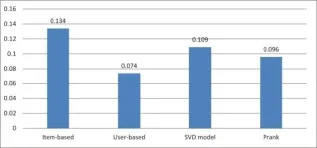
图5 4种算法在1M数据集上Top-20推荐准确度比较
3)推荐多样性的比较
关于推荐多样性,我们观察在Top-N=10,100k数据集上,Prank算法与Item-based算法在推荐商品被购买次数区间与推荐次数的关系图表。如表1所示:

表1 Prank算法与Item-based算法100k数据集Top-10推荐多样性比较
由表1可以看出,在[41,80],[81,140],[141,200],[201,300]这些相对被购买数较少的物品区间,Prank算法能较多的推荐,在这些小众物品上,Item-based算法由于其算法相似度公式的局限性,这些物品很难被推荐,如表2所示:

表2 Prank算法与Item-based算法在100k数据集Top20推荐多样性比较
由表2可以看出,在Top-20推荐问题上,prank算法更多的推荐那些被购买数在[41,200]的商品,而Item-based算法对被购买区间在[0,140]的商品几乎不推荐,而更多的推荐那些最受欢迎的产品。
4 总结
与现有推荐算法相比,Prank算法在推荐准确度方面上处于中游,但仍有改进空间。Prank算法在推荐多样性上优势较大,能够给用户带来惊喜。
关于推荐准确性:Prank算法在训练过程中,是针对不同的用户训练不同的模型,而该模型的训练数据完全是用户购买过的物品的集合。对该训练数据特征的选取,除了可以采用评分向量以外,还可以采取物品本身特征等特性,这将是提高Prank算法推荐准确度的途径。Prank算法在训练迭代中不断缩小预测排位与实际排位的差,以达到准确预测排位的目的。
从实现推荐的原理上看,Prank算法的应用与User-based算法在道理上极为相似。Prank算法训练出的w向量中的每一维度恰好对应了一个用户和自己的相似度,而预测值是由该相似度线性组合而成的,但它与User-based算法的区别在于它在训练过程中是不断拟合该用户与自身的相似度的。而User-based算法是通过他们共同购买的物品向量的相似度而计算他们之间的相似度。所以,在最后推荐准确度上,Prank上要高于User-based算法。利用此想法,因为Prank算法能够训练出该用户(物品)对未知物品(用户)的评分是由哪些邻居加权而来的。用户和物品在评分矩阵上只是维度不同,如果将所有物品和用户的位置互换做Prank,对每个物品建模,势必会取得比Item-based更好的推荐准确度,这将是以后可以尝试的工作。而Prank算法在训练过程中,为了使训练能更为迅速,更为准确,要采用合适的训练参数,以防止出现训练无法达到最佳精度与训练次数过多导致模型过拟合等问题。这些问题同样值得深入研究。
关于推荐多样性:由于Prank算法训练的独特性,它推荐的物品与存在严重单一化推荐的Item-based算法相比具有更强的多样性。这是因为Prank算法采用的是将所有用户的意见加权听取意见的方式,而有的意见有正面效果,有的意见有负面效果,所以并不会出现Item-based算法中被购买多的物品之间的距离往往更小带来的连带推荐效应而降低推荐多样性。
[1] Crammer K, Singer Y. Pranking with Ranking[J]. Advances in Neural Information Processing Systems, 2002,14:641--647.
[2] Koren Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model.[C]// Acm Sigkdd International Conference on Knowledge Discovery & Data Mining. 2008:426-434.
[3] Deshpande M, Karypis G. Item-Based Top-N Recommendation Algorithms[J]. Acm Transactions on Information Systems, 2004, 22(1):143--177.
[4] 任看看, 钱雪忠. 协同过滤算法中的用户相似性度量方法研究[J]. 计算机工程, 2015, 41(8):18-22.
[5] Zhang M, Hurley N. Avoiding monotony: improving the diversity of recommendation lists.[C]// Proceedings of the 2008 ACM conference on Recommender systems. ACM,2008:123-130.
[6] 曾玮. 文献排名预测算法及作者影响力评估算法研究[D]. 西南大学, 2014.
[7] 黄梅娟. 协同过滤算法在个性化就业推荐系统中研究[J]. 电脑知识与技术, 2015(08).
Prank Algorithm-based Research and Application for Recommender System
Zhang Xuchen
(Fudan University, Shanghai 201203, China)
With the development of Internet, the information on the Internet grows with each passing day, but users are hard to get the wanted information in limited time. One way of solving this question is Recommender System, Recommender System could get users' requirements by users' history behaviors, and make user select quickly and accurately. In this essay, the main point is to apply the Prank algorithm to Recommender System, Prank algorithm is a classic learning-to-rank algorithm in Information Retrieval. It could train the relations between a set of features and rank, and make accurate predictions. In this essay, we make a slight improvement of Prank algorithm to adjust to top-N recommendation problem, compare Item-based algorithm, User-based algorithm, SVD model algorithm in Recommender System with Prank algorithm, and give the advantages and disadvantages between them. The Prank algorithm gets good experiment results on recommendation precision and recommendation diversity problem.
Recommender System; Prank Algorithm; Recommender Model; Learning to Rank
TP311
A
1007-757X(2016)06-0058-04
2015.12.22)
张栩晨(1990-),男,复旦大学,硕士研究生,研究方向:推荐系统与机器学习,上海,201203
