一种基于SVM的博客大数据分类算法及应用
2016-10-18陈建峡朱季骐王鹰适倪一鸣
陈建峡, 朱季骐, 王鹰适, 倪一鸣
(1 湖北工业大学 计算机学院,湖北 武汉 430068; 2 湖北泰信科技信息发展有限责任公司, 湖北 武汉 430071)
一种基于SVM的博客大数据分类算法及应用
陈建峡1, 朱季骐1, 王鹰适2, 倪一鸣2
(1 湖北工业大学 计算机学院,湖北 武汉 430068; 2 湖北泰信科技信息发展有限责任公司, 湖北 武汉 430071)
提出了一种基于SVM的博客大数据分类算法BBD-SVM,根据RSS博客文本特点提取博客特征词,通过SVM模型参数寻优化SVM分类模型实现博客大数据分类。并设计了RSS博客爬虫,以互联网上各种计算机程序设计语言的技术博客为爬取对象,利用BBD-SVM算法对相关技术博客进行专业分类,为用户学习程序设计语言提供专业推荐服务。其中,博客文本特征的提取选用改进的TF-IDF作为权重计算函数,SVM分类模型的参数寻优很好地提高了分类效率。实验结果表明,BBD-SVM算法具有准确率高,耗时少的优势,能够实现快速准确的博客推荐服务。
支持向量机;博客;大数据;分类算法;社交网络;用户推荐
目前,博客文本分类方法主要有朴素贝叶斯法、K最邻近(kNN,k-Nearest Neighbor)方法和支持向量机(SVM, Support Vector Machine)方法。朴素贝叶斯法是通过假设各个单词之间两两独立,然后用条件概率模型进行分类。kNN方法是一种基于实例的文本方法,对一个测试文本计算它与训练样本中每个文本的相似度,找出k个最相似的文本,在此基础上给每一个文本类别打分,然后根据打分高低排序分类[1]。SVM方法通过对样本的学习寻找最优分类超平面,然后根据找到的最优分类超平面进行分类。在与朴素贝叶斯法和kNN方法的比较中,SVM方法取得了更好的分类效果,并且对于高维数据的处理表现出了 优良的性能[2]。
本文基于SVM,提出博客大数据分类算法BBD-SVM(Blog Big Data-SVM),通过SVM分类模型实现相关技术博客专业分类。在该模型中采用了改进的TF-IDF权重计算函数,提高了SVM的分类效率。
1 SVM分类模型
支持向量机(Support Vector Machine,SVM)是一种基于统计学习理论的通用学习方法。SVM的基本思想见图1,图中实心圆代表正样本,空心圆代表负样本,每一个样本点可以表示为(x,y),其中x代表该样本的特征向量,y代表样本类别。这里样本类别y∈{+1,-1}。需要找到一个分类超平面H(二维平面中为一条直线)将2类样本分开,这个分类超平面可以表达为w·x-b=0。过离H最近的正负样本点且平行于H的超平面分别为H1、H2,H1与H2之间的距离成为分类间隔。为了简化计算表达,对于样本集(xi,yi),i=1,…,n需要满足yi[(w·xi)+b]≥1,此时分类间隔等于2/‖w‖,所以在此基础上使‖w‖最小的超平面就是最优的分类超平面,H1和H2上的样本点就是支持向量[3]。根据最优化理论求得最优解的w*,再用一个支持向量计算出b*就可以得到最后的分类函数f(x)=sgn{(w*+x)+b*},最后根据分类函数f(x)就能对输入样本进行分类计算了。
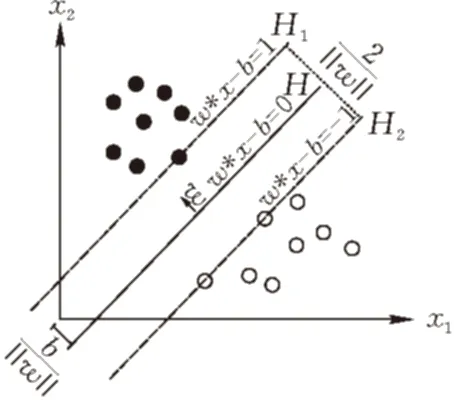
图1 SVM分类原理图
SVM模型的确定主要在于核函数与其参数选择,为了使SVM适用于大样本数据集的训练就需要加快参数寻优速度或缩小参数寻优范围,所以本文使用一种基于均匀设计的自调用SVR方法(UD-SVR)来解决这一问题[4]。
2 TF-IDF的改进
2.1传统TF-IDF
在博客文本特征的提取时,权重计算函数选用了目前应用较多、效果较好的TF-IDF函数,评估特征词的重要程度。TF-IDF的思想是:如果一个特征词在某个文档中出现次数很多,且其他的文档中包含该特征词较少,则该特征词能够很好地表示该文档。TF为词频,表示特征词m在博客文本d中出现的次数,反映博客文本的内部特征。IDF为逆文本频数,表示某一特征词m在整个博客文本集合中的分布情况,反映博客文本间的特征。
TF-IDF计算公式为:
(1)
其中,m为特征词在博客文本d中出现的次数,M为博客文本d中总词数。
(2)
其中:n为包含某项特征词的博客文本总数,N为总博客文本数。
TF-IDF将博客文本集作为整体处理,但是在IDF的计算中,存在很大的问题。往往一些生僻词的IDF会比较高,这些生僻词就会被误认为是文档关键词。
而且,传统TF-IDF函数中的IDF部分只考虑了特征词与它出现的博客文本数之间的关系,而忽略了当前类别中的特征词在不同的类别间的分布情况。
2.2改进的TF-IDF
现有待分类博客文本类别的集合Y={y1,y2,…,yj},在yi(yi∈Y)中,博客文本集合D={d1,d2,…,dn},n为博客文本数目。特征词集合M={m1,m2,…,mk},k为yi中出现的所有词语个数。针对传统的TF-IDF中存在的不足,本文选取了一种改进的TF-IDF函数,对TF和IDF的计算方面都做了改进[5]。
TF的改进:文档内的词频率更改为同一类文档内的词频率。
IDF的改进如下式:
(3)
其中,P(mk)表示特征词mk在当前类别中的频率,P(mk)′表示特征词mk在其他类别中的频率。从(3)式中可以看出,当P(mk)很大,IDF的绝对值反而小。对它取反,根据log函数的特性,自变量要大于0,IDF要为正值,则修正后的IDF公式为
(4)
实验中运用改进后的IF-IDF函数,提取训练博客文本集D中每个类别yi的特征词时,特征词与类别相关性相较于传统TF-IDF效果更好,分类效果也有了很大的改善[6]。
3 BBD-SVM分类算法
本文根据博客信息的特点,利用参数寻优的方法改进SVM模型,研究并实现了一种新的BBD-SVM(BlogBigData-SVM, 基于SVM的博客大数据)分类算法,以计算机程序设计语言为分类的实验对象,为用户提供专业的程序设计语言技术博客分类。实验表明,BBD-SVM分类算法具有较高的分类精度和训练速度。BBD-SVM分类算法的研究思路见图 2。
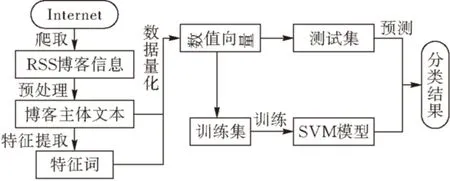
图2 BBD-SVM分类研究思路
3.1博客信息特征提取
利用项目组以前开发的博客搜索引擎中的爬虫工具[7],爬取各大技术博客网站的网页信息,由于爬取下来的信息均为网页标签文本信息,不能直接用于分类模型的训练和预测,所以必须要对文本信息进行特征提取的预处理过程。具体步骤如下:
步骤一:通过爬虫工具爬取到标准的RSS格式的博客信息,RSS是一种基于XML的标准格式,规则且解析容易。
步骤二:按照RSS格式将标题、标签和正文内容解析保存为纯文本,并在此过程中进行一些特殊符号等的过滤处理。
步骤三:本文选用性能和准确率都比较出众并带有词性分析功能的中文分词器Ansj,对博客文本信息进行分词与统计。
步骤四:根据分词后每个词的词性再对分词后的结果进行一次过滤,得到最终的处理语料。
步骤五:根据改进后的TF-IDF公式计算每个词的TF-IDF的值,根据TF-IDF值的高低选择每个类别的特征词。
本文针对计算机程序设计的技术博客进行了爬取,获得相应的博客信息特征提取结果见图3样例所示。

图 3 特征词提取结果样例
3.2SVM模型参数寻优
3.2.1传统参数寻优传统的SVM参数寻优的流程见图4,寻优需要对参数c,g(c表示惩罚系数,g表示核函数参数)组合在给定范围内进行穷尽搜索。搜索次数为两个参数向量长度的乘积,总的搜索时间为搜索次数乘训练样本个数。对于小样本数据穷尽搜索算法运行时间尚能接受,但随着样本数目的增大,所需的计算时间会呈几何级数增加,致使SVM无法有效适用于大数据集。一般情况下,g的选取需要根据实际的分类情况把握其范围。由于本文研究的是博客文本分类方面,且博客文本分类量化后向量比较稀疏,g的最优参数一般偏小。所以,文中c和g这两个参数的范围定为:log2c=-1:1:14,log2g=-8:-1:-23。
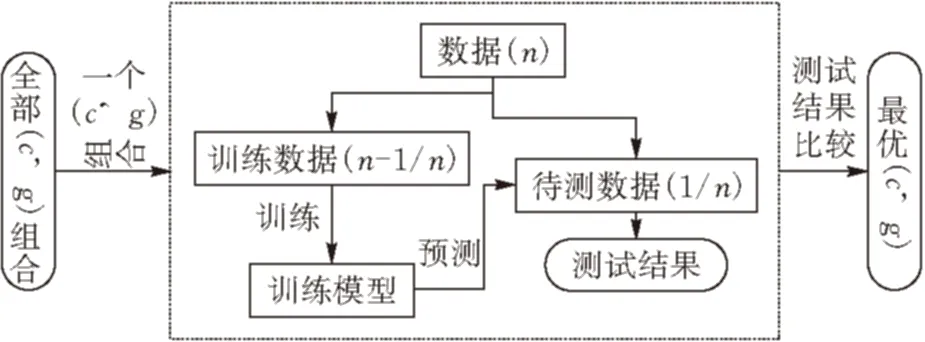
图 4 传统的SVM参数寻优过程
3.2.2UD-SVR算法寻优本文运用UD-SVR算法[8],对传统的SVM寻优方法进行了优化。该算法以基于均匀设计的自调用SVR代替传统参数寻优过程,并从两个方面对传统SVM寻优方法进行了优化。一方面,基于均匀设计仅从全部256组参数组合中选取16组具有代表性的组合,有效降低搜索范围,大幅度缩短了寻优时间。另一方面,基于此16个参数组合及其评价指标(准确率)以自调用SVR建立评价指标与参数组合之间的关系模型,并以此对全部参数组合进行预测,以预测的评价指标代替传统SVM寻优方法中的交叉测试评价指标,有效提升了寻优效率。UD-SVR参数寻优的流程见图5。
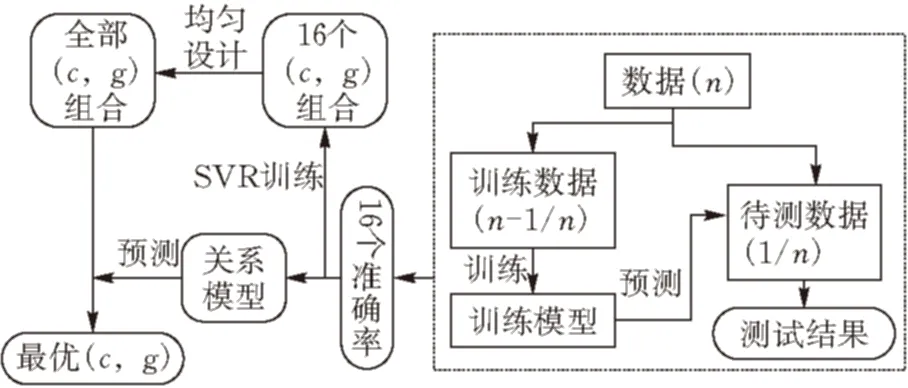
图 5 UD-SVR参数寻优过程
均匀设计(UniformDesign),是只考虑试验点在试验范围内均匀散布的一种试验设计方法。它由方开泰[9]教授和数学家王元共同提出,是数论方法中的“伪蒙特卡罗方法”的一个应用,它能提高试验点“均匀分散”的程度,使试验点具有更好的代表性,能用较少的试验获得较多的信息。由于c,g因素水平不同,根据混合水平均匀设计表生成n个(c,g)组合(本文中n等于16)。
将16组(c,g)组合对训练样本进行交叉验证得到对应的16个准确率值,然后将这16组参数组合和准确率作为训练样本进行SVR训练,得到一个SVR预测模型,利用这个模型本文 可以对全部256组参数组合预测其准确率,从预测的准确率中选取准确率最高的一组参数做为本文 的最优参数组合,最后将这组最优参数组合作为训练SVC的参数进行训练就得到了最终的分类模型。
本文使用三个方面的数据集进行对比试验,数据集1为UCI酒类数据集、数据集2为搜狗开放的新闻语料数据集,数据集3为本文 爬取的博客数据集,实验结果见表1。

表1 传统参数寻优与UD-SVR算法寻优对比试验
从表1中可以看出:采用UD-SVR寻优算法和不采用的精度差别不大,但是训练耗时则有着数量级的差别,所以UD-SVR寻优算法可以在几乎不损失分类精度的前提下大幅度提升训练寻参速度,非常适合用于纬度高、计算量大的文本多分类问题。
3.3BBD-SVM算法表达
将BBD-SVM算法用伪代码形式表达如下:
webcrawling;
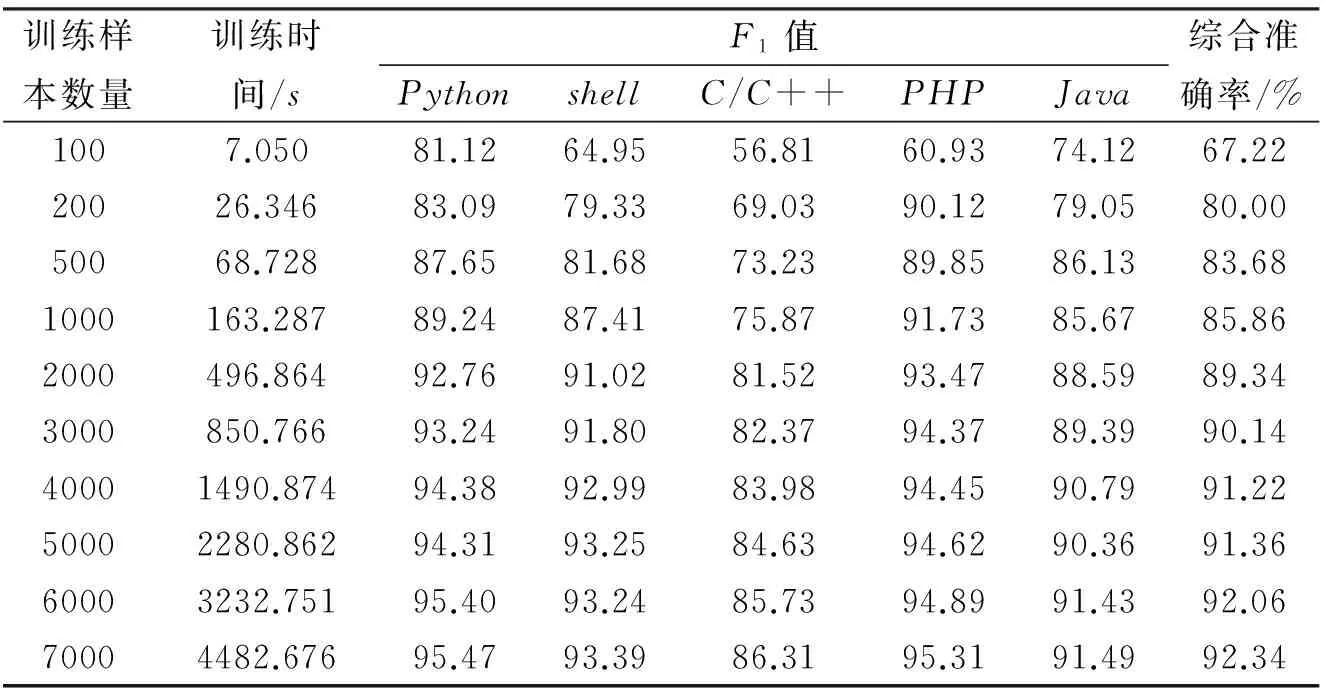
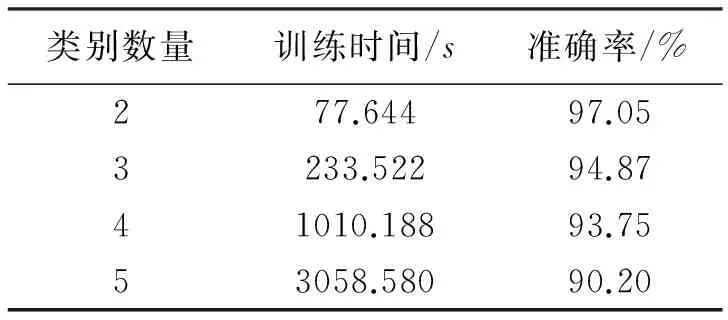
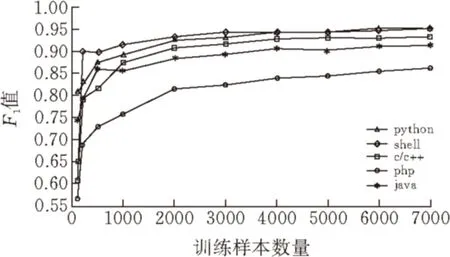
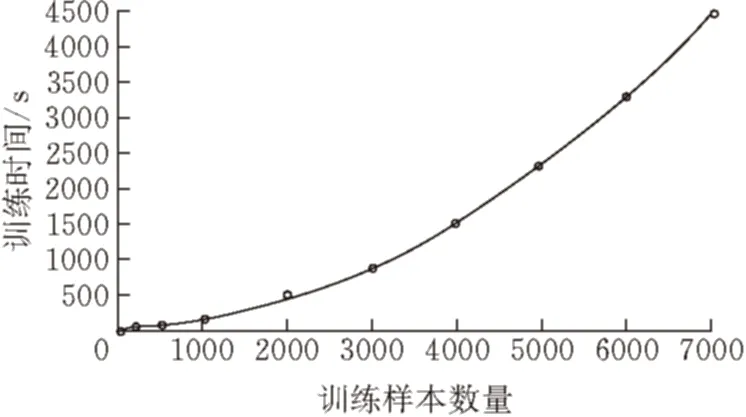
for(i=0,i pretreatment; for(i=0,i wordsegment; for(i=0,i wordcount; for(i=0,i {for(everyword) tfidf-tf*idf sortbytfidf; } for(i=0;i getfeatureword; for(i=0;i (j=0;j { if(bloghasfeatureword vector[j]=countoffeatureword; } if(totrain( svmtrainwithud-svr; if(topredict) svmpredict; 如上所述,本文从互联网上获取真实数据进行实验,利用Heritrix爬虫工具[7]从网络中爬取博客信息。然后运用改进的TF-IDF函数进行特征词的提取,并将每篇博客的文本信息量化为数值信息, 进行训练样本数量和分类类别数量的实验。 本文选择的是CSDN等技术博客网站进行的数据爬取,所以实验以多种编程语言为分类类别进行。训练样本数量实验中, 类别数为5,样本维度为1000,预测样本数量为5000;分类类别数实验中训练样本数量为2000/类,测试样本数量为2000/类,样本维度为100维/类。训练样本数量实验结果见表2,对应的分类类别数量实验的结果见表3。 表2 训练样本数量实验 表3 分类类别数量实验 由表3可以看出分类类别的增加会使得分类准确率有所下降,而且由于分类类别的增加,训练样本的增加和样本维度也需要随之增加,导致训练时间大幅增加。 图 6 训练样本数量与各类F1值关系图 图6中,查准率(precision)表示检出相关文档与检出全部文档的百分比,查全率(recall)表示检出相关文档与所有相关文档的百分比,这里相关即指同类别。综合查准率和查全率,F1=2×查准率×查全率/(查准率+查全率),用F1值作为分类好坏的指标,F1值越高,说明分类效果越好,分类精度越高。 由图6可以看出分类结果的精度会随着训练样本的数量增加而增加,但是增长速度会随之下降,由图7可以看出训练时间会随训练样本数量的增加而增加,并且增长的速度越来越快。所以,为了提高分类精度,大量的训练样本是必须的,但伴随大量样本,训练时间会迅速增长。 图 7 训练样本数量与训练时间关系图 试验中均使用了UD-SVR参数寻优算法进行样本训练,如果使用传统寻优,表1的实验结果可以看出,在面对大量多类别的训练样本时,训练所花费的时间将是极高的。 提出了一种运用SVM分类模型进行博客分类的BBD-SVM算法,该算法使用改进的TF-IDF进行特征提取,并采用改进的参数寻优算法对SVM中的c和g参数做了寻优处理。实验结果表明,该方案在面对大量训练样本和高样本维度时,呈现出了较高的准确率和较少的样本训练时间,取得了一定成果。 对于类别过多的情况,准确率还是差强人意,而且多分类问题中特征提取的维度还是较高,如何更好地适应分类类别数量较大的应用环境和如何缩小特征提取维度将会是未来研究的重点。 [1]陈建峡,李志鹏. 基于移动终端的博客搜索引擎系统研究与应用[J].湖北工业大学学报,2015,30(2):89-94. [2]崔彩霞, 冯登国. 文本分类方法对比研究[J]. 太原师范学院学报(自然科学版), 2007, 6(4): 52-54. [3]成艳洁. 基于SVM的多类文本分类算法及应用研究[D].西安:西安理工大学图书馆, 2011. [4]CohenE,KrishnamurthyB.AshortwalkintheBlogistan[J].ComputerNetworks,2006,50(5):615-630. [5]覃世安, 李法运. 文本分类中TF_IDF方法的改进研究[J].现代图书情报技术, 2013, 238: 27-30. [6]卢中宁, 张保威. 一种基于改进TF-IDF[J]. 河南师范大学学报(自然科学版), 2012, 40(6): 158-160. [7]吴伟, 陈建峡 . 基于Heritrix的web信息抽取优化与实现[J]. 湖北工业大学学报,2012, 27 (2):23-26. [8]龚永罡, 汤世平. 面向大数据的SVM参数寻优方法[J]. 计算机仿真, 2010, 27(9): 204-207. [9]方开泰.均匀设计与均匀设计表[M].北京:科学出版社,1994:18-23. [责任编校: 张岩芳] A SVM-based Blog Big Data Classification Algorithm and Its Application CHEN Jianxia1, ZHU Jiqi1,WANG Yingshi2,NI Yiming2 (1.SchoolofComputerScience,HubeiUniversityofTechnology,Wuhan, 430068,China; 2HubeiTaixinInformationDevelopmentCo.,Ltd.,Wuhan, 430071,China) The paper proposes a blog big data classification algorithm based on Support Vector Machine (Blog Big Data-SVM, namely BBD-SVM). It completes blog texts’feature extraction according to the RSS blogs characteristics, and optimizes SVM classification model via improving its to realize blog big data classification efficiently. The paper designs a crawler for the RSS blogs especially, takes a variety of technology blogs about computer programming languages over the Internet as objects. Therefore, the proposed algorithm can provide the users with relevant professional classifications of technology blogs accurately. In particular, the proposed approach utilizes the improved TF-IDF as the weight calculation function when extracting blog text features, and the improved SVM model has been verified to be a good way to improve the classification efficiency. The experimental results show that BBD-SVM algorithm has high accuracy and less time-consuming advantages, so that it is able to achieve fast and accurate information referral blog services for the users. SVM; blog; big data; classification algorithm; user recommenation 2015-09-15 2013年国家大学生创新项目(41301371)(Q20141410) 陈建峡(1971-), 女,湖北丹江口人,湖北工业大学副教授,研究领域为数据挖掘,搜索引擎 朱季骐(1994-),男,湖北潜江人,湖北工业大学本科生,研究领域为数据挖掘 1003-4684(2016)04-0070-05 TP393 A4 实验结果与分析
5 总结与展望
