错题管理系统中个性化推荐练习算法的设计与实现
2016-10-18王文泉
王文泉
(深圳信息职业技术学院 信息中心,广东 深圳518172)
错题管理系统中个性化推荐练习算法的设计与实现
王文泉
(深圳信息职业技术学院 信息中心,广东 深圳518172)
文章针对错题管理系统中最为重要的一个组成部分——巩固练习,设计个性化推荐练习算法,采用Java语言进行模拟实现,通过算法分析发现推荐结果较为理想。算法设计在网络错题管理系统中得到功能上的实现,并应用于实际教学中。
错题管理;个性化推荐;算法分析
一、引言
网络学习者作为众多Web用户之一,有其独特的特征。在错题管理系统中,更正错题作为最重要的环节,其中主要的策略是巩固练习的实施。如何为学习者推荐个性化的练习,消除学习者知识缺陷,最大程度做到“错题不错”,其推荐技术及算法值得研究。
一般来说,个性化推荐可采用基于规则的技术、基于内容过滤的技术和协作过滤技术。基于内容的过滤技术主要依靠关键词匹配技术,过滤掉那些相关度不高的项目。基于内容过滤通过“资源——用户”关系,利用信息资源与用户兴趣之间相似性来过滤信息,把符合用户兴趣的新的资源推荐给用户,简单有效。
错题管理系统要为学习者推荐的试题应该具有与学习者做错的试题具有相同知识点、类似难度的特征。所以,本研究采用内容过滤方法为学习者筛选出合适的试题资源。
二、算法设计
1.推荐试题特征分析
错题的巩固练习作为错题管理系统中最为重要的一部分,其主要目的在于根据学习者需要,为学习者推荐一定数量相关知识的练习题,以用于练习和巩固知识。在错题管理系统中,推荐给学习者的试题应具有以下三个特征:
(1)与学习者做错的试题同属一个知识点
作为学习者“巩固练习”而推荐的试题,其首先要具备的特征就是要与学习者做错的题目具有相同的知识点属性,只有这样,才能达到巩固该知识的目的。
(2)试题具有尽可能高的质量
试题的质量高低取决于两个方面:一是试题资源的得分,系统用户对试题的评分越高,说明试题质量越好,该题越值得推荐,反之亦然;二是试题被收藏次数,由于错题管理系统有着不同于普通学习系统的特点,它的主要目的在于消除学习者错误。所以,决定试题质量高低的第二个因素是试题被收藏次数。试题被收藏次数越多,说明该题目被做错的次数越多或者该题目极具经典试题的特征,该试题对于当前学习者的质量也就越高,试题也就越值得推荐。
(3)与学习者做错的题目具有类似的试题难度,兼顾基础巩固和能力提升
为维持学习者的学习积极性,保证学习者掌握知识,系统尽量为学习者推荐相同试题难度的试题。但是,当前的推荐是发生在学习者已经发生错误,并且进行了初步的分析之后,所以为起到巩固基础知识和进一步提高能力的作用,系统可以为学习者推荐相邻试题难度的试题。例如,学习者当前出错试题难度为“理解”,那么系统为其推荐的试题集可能包含 “识记”、“理解”、“应用”三个难度等级;而如果学习者当前出错试题难度级别为“识记”,那么系统为其推荐的试题则可能包含“识记”和“理解”两个难度级别。
2.算法的设计思路
该部分依据上一小节的讨论,针对错题管理系统中推荐试题所应具有的三点特征进行分析,设计推荐算法。
(1)知识体系的建立
系统采用知识结构树建立知识体系,知识结构树的建立按照“课程——章/单元——节——知识点”的次序依次建立,效果如图 1所示,该图为初二《科学》课程的知识结构树,包含三个级别:课程——章——知识点,这是因为:根据科目的不同,知识结构树的建立所作的取舍也不同。

图1 学习内容树结构图
知识结构树建立完毕后,题目入库将绑定到相应的知识点(可以绑定为“课程”、“章”、“节”、“具体定理、公式、单词等”其中的某一项或者某几项)。当系统为学习者推荐试题时,系统将首先检索出与错题具有相同知识点的题目。
(2)试题质量的确定
根据上一小节的讨论,被推荐的试题质量由两部分决定:试题资源的得分和试题被收藏的次数。
系统采用“5”、“4”、“3”、“2”、“1”评分的形式区分不同质量的资源,将试题分为五个等级。试题得分越高,说明试题资源的质量越好。试题评分者可以是学生或者教师,试题得分取所有评分者评分的平均值,计算公式如公式1所示。假如试题是新加入到系统中,那么会出现试题没有得分的现象。为避免这种现象的发生,将新加入系统中的每道试题得分默认设为“3”,也即设为中等水平。伴随着系统的使用,试题评分逐渐增多,系统将自适应地计算和更改试题得分。筛选出的试题按照试题得分由多到少排序。

其中,S表示试题得分,Si表示第i个评分用户对试题的评分,n表示对试题评分的用户总数。
被收藏次数是指一道试题被所有学习者收藏到错题本中的总次数。试题被收藏次数越多,说明试题质量越高,越具有知识点代表性,越值得学习者去做。系统为学习者推荐的试题按试题被收藏次数由多到少排序。
由于试题质量要综合考虑试题得分和被收藏次数两方面因素,而且两个因素没有权重区别 (即同等重要),试题得分已经界定取值范围为1~5。所以,为了消除由于被收藏次数单方面过多或者过少而引起的试题质量得分偏高或者偏低的现象发生,试题被收藏次数采取与试题得分相同的五等级划分方法。由此而得出的结果称为试题收藏度,其计算公式如公式2所示。

其中,F表示试题收藏度,CTmax表示所有试题中被收藏最多的试题的被收藏次数,CT表示试题的实际被收藏次数。
综上讨论,试题质量的最后得分取试题得分和试题收藏度的均值,其计算方法如公式3所示。试题质量得分越高,说明试题质量越高。
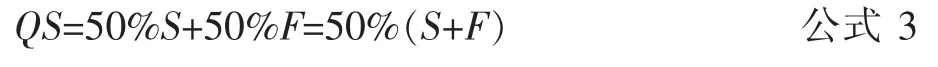
其中,QS表示试题质量得分,S表示试题资源评分,F表示试题收藏度。
(3)试题难度的划分
为指导教育测量和评价,美国教育心理学家布鲁姆发表《教育目标分类学》,将认知领域目标由低到高依次分为知道、领会、运用、分析、综合和评价。不同层次的教育目标代表着不同的知识结果和认知水平。
系统借鉴布鲁姆教育目标分类方法,将试题标记为识记、理解、运用(包含原始分类的运用、分析、综合和评价)三个难度等级。
内容过滤技术的基本过程如下:在同一特征空间下,建立资源特征向量和用户描述文件;依据用户描述文件,比较系统内所有资源特征向量与用户描述文件之间的相似度;把相似度高的资源推荐给用户。余弦相似度计算公式如公式4所示。
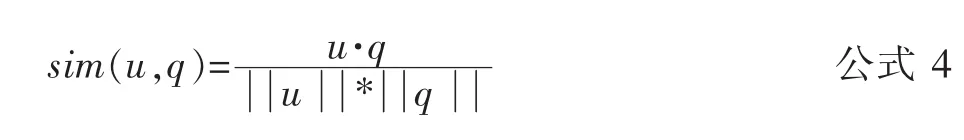
其中,u表示用户向量,q表示资源向量。
结合第二部分第一节的讨论,试题难度特征值按照其难度级别,依次将识记、理解、运用记为“1”、“2”、“3”。由于跟学习者做错的试题不属于同一知识点的试题是不希望被选出的,试题难度级别最大特征值为“3”,所以为了区别出试题知识点属性,将知识点特征值按照是否为所需要知识点设为“5(任意一个大于5的值)”或者“-5”。
3.个性化推荐流程
根据以上讨论,确定系统整体推荐流程如下:
(1)获取用户描述文件,对学习者做错的题目和试题资源进行特征向量构建。
(2)通过比较资源特征向量与用户描述文件,筛选出与学习者错误试题具有相同知识点、类似试题难度的试题集C1。
(3)C1按照试题质量由高到低排序,形成试题集C2。
(4)C2按照实际需要选出top(N)推荐给学习者。
以上内容过滤算法推荐流程中的关键步骤是特征向量的构建,其思想如下:
IF出错
THEN获取出错试题属性信息
SELECT试题FROM试题库
IF试题知识点属性值=出错试题知识点属性值
THEN试题知识点特征值=5
ELSE试题知识点特征值=-5
SET试题难度级别特征值=1,2,3WHERE试题难度级别=识记,理解,应用
试题特征向量=(试题知识点特征值,试题难度级别特征值)
三、算法分析与实现
1.算法分析
为验证推荐算法的有效性,现假定有10道试题,它们的属性信息如图2所示。采用本文讨论的个性化推荐方法,为学习者推荐3道试题。其详细推荐步骤如下:
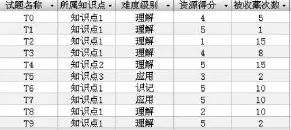
图2 试题数据库
(1)假定t0为当前学习者出错试题,按照“试题(知识点,难度)”获取所有试题特征向量值如表1所示。
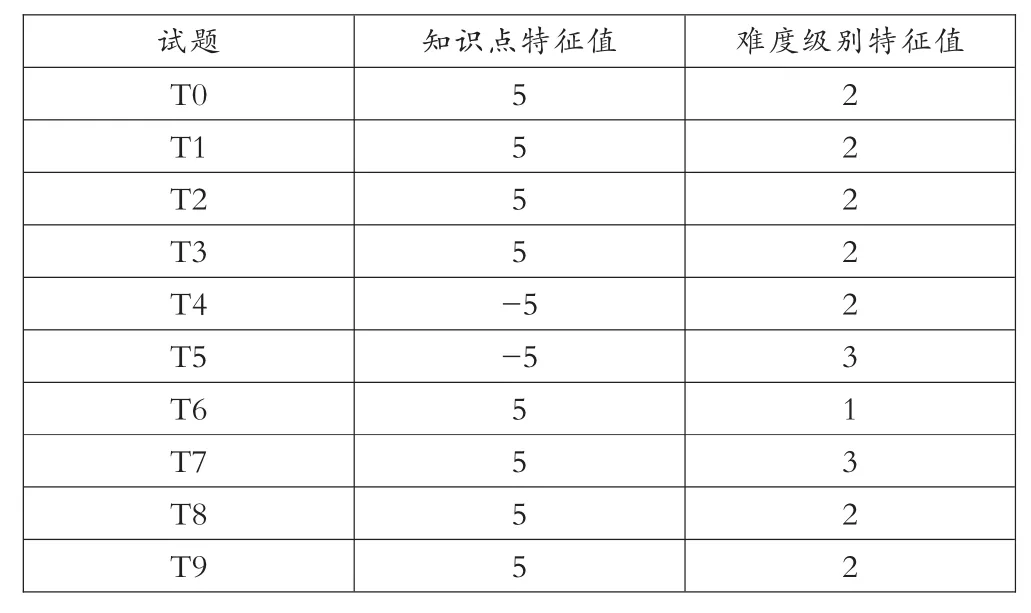
表1 试题特征向量构建
采用JAVA实现该部分代码如下:

//构建特征向量questionsset难度特征值=1where难度级别='识记'");//设置难度级别为“识记”的试题难度特征值为1
intb=stmt.executeUpdate("updateexamquestionsset难度特征值=2where难度级别='理解'");//设置难度级别为“理解”的试题难度特征值为2
intc=stmt.executeUpdate("updateexamquestionsset难度特征值=3where难度级别='应用'");//设置难度级别为“应用”的试题难度特征值为3
intd=stmt.executeUpdate("updateexamquestionsset知识点特征值=-5");//初始化所有试题的知识点特征值为-5
inte=stmt.executeUpdate("updateexamquestionsset知识点特征值=5where试题名称='T0'");//将当前出错试题的知识点特征值设为5
System.out.println(a+"条记录难度特征值被设为1"+";"+b+"条记录难度特征值被设为2"+";"+c+"条记录难度特征值被设为3"+"。");
System.out.println("所有试题难度特征值构建完毕!");
System.out.println(d+"条记录知识点特征值初始化为-5。");
System.out.print("当前出错试题T0的知识点特征值已被设为5;");
rs=stmt.executeQuery("select*fromexamquestionswhere 试题名称='T0'");
T0.tname=rs.getString("试题名称");
T0.tknowledge=rs.getString("所属知识点");
T0.tdifficulty=rs.getString( "难度级别");
T0.knowledgevalue=Integer.parseInt(rs. getString("知识点特征值"));
T0.difficultyvalue=Integer.parseInt(rs. getString("难度特征值"));
currentknowledge=T0.tknowledge;//将T0所属知识点设为当前知识点
System.out.println("当前出错知识点为" +"“"+currentknowledge+"”;"+"难度特征值为"+ T0.difficultyvalue+"。");
}
intf=stmt.executeUpdate("updateexamquestionsset知识点特征值=5where所属知识点='知识点1'");//将与T0具有相同知识点的试题的知识点特征值设为5
System.out.println(f+"条记录知识点特征值被设为5。");
System.out.println("所有试题知识点特征值构建完毕!");
System.out.println("所有试题特征向量构建完毕!");
该部分输出结果如图3所示。

图3 构建特征向量过程的输出结果
(2)接下来,根据公式4计算T1~T9与T0的余弦相似度,计算结果如表2所示。
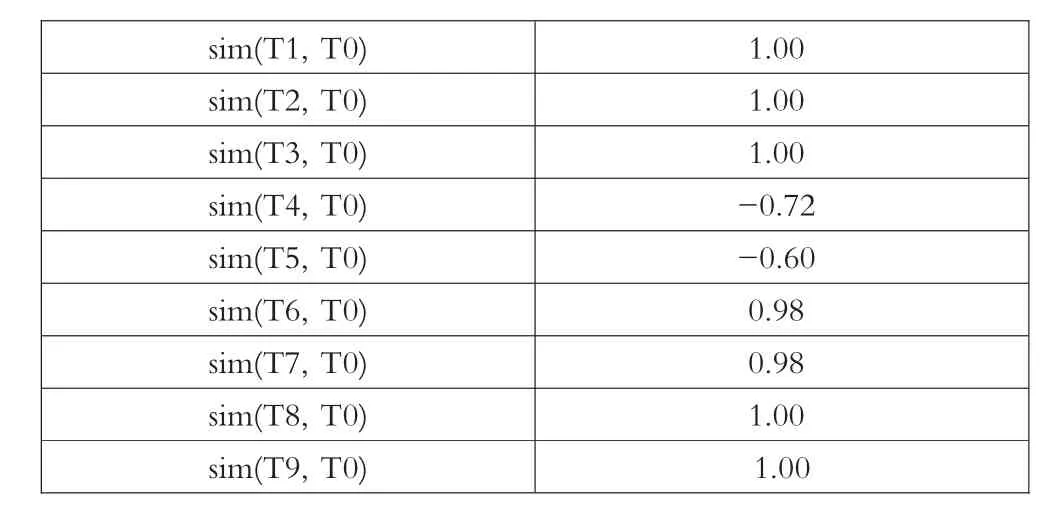
表2 余弦相似度
舍弃与T0不属于同一知识点(即与T0之间的余弦相似度小于0)和与T0难度级别相差大于1(即与T0之间的余弦相似度小于等于0.94)的题目,也就是只取sim值大于0.94的试题,形成试题集C1={T1,T2,T3,T6,T7, T8,T9}。
(3)按照公式2和公式3计算C1中各试题质量得分如表3所示。
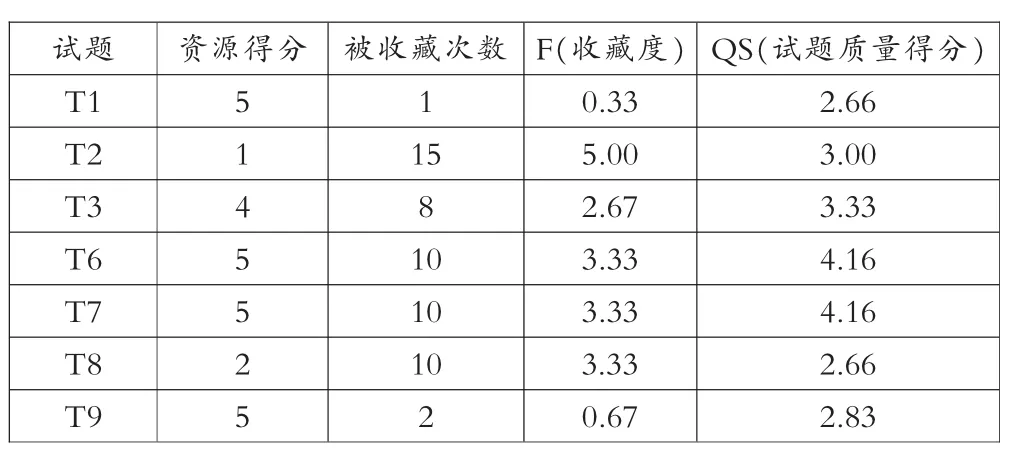
表3 试题质量得分
C1按照资源质量得分由高到低排序,形成试题集C2={T7,T6,T3,T2,T9,T1,T8}。
该部分代码输出结果如图4所示。
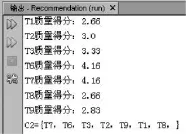
图4 C1按照试题质量由高到低排序生成C2过程的输出结果
(4)根据需要,从C2中选出3道试题,即T6,T7和T3,推荐给学习者。
根据上一部分的讨论,可以看出,为学习者推荐的三道试题,符合被推荐试题所应具有的特征。
2.算法功能实现
根据个性化推荐练习算法的设计,在系统功能上予以实现。当学习者做错题目时,点击 “举一反三”按钮,则弹出推荐试题练习窗口,学习者可以进行巩固练习。
四、结束语
为考察个性化推荐练习算法的应用效果,进一步指导错题管理系统设计和开发,笔者在深圳市福田区南华中学某两个班进行了教学实验。在后续的研究中,笔者将第一时间公布实验结果;并进一步优化个性化推荐练习算法,检验其效果。
[1]StellanOhlsson.Learningfromperformanceerrors [J].PsychologicalReview,1996,103(2):241-262.
[2]Tzu-HuaWang.Web-baseddynamicassessment:Takingassessmentasteachingandlearningstrategyforimprovingstudents'e-Learningeffectiveness[J].Computers& Education,2010(54):1157-1166.
[3]StevenJ.Lorenzet,EduardoSalas,ScottI.Tannenbaum.BenefitingfromMistakes:TheImpactofGuided ErrorsonLearning,Performance,andSelf-Efficacy[J].Human ResourceDevelopmentQuarterly,2005,16(3):301-322.
[4]王文.个性化推荐算法研究[J].电脑知识与技术,2010,6(16):4562-4564.
[5]王智.E-learning环境中个性化推荐系统研究[D].重庆:西南大学,2009.
[6]尤秀梅.教学平台中基于知识点的个性化推荐学习的研究与实现[D].天津:天津师范大学,2010.
[7]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[8]尤秀梅.教学平台中基于知识点的个性化推荐学习的研究与实现[D].天津:天津师范大学,2010.
[9]刘博.智能教学系统中个性化题库的设计与实现[J].中国电化教育,2010(284):110-114.
[10]陈敏,余胜泉,杨现民,黄昆.泛在学习的内容个性化推荐模型设计[J].现代教育技术,2011,21(6):13-18.
[11]郑婕.个性化推荐技术在网络教学中的应用研究[D].江西:南昌大学,2011.
[12]MarkoBalabanovic,YoavShoham.Fab:Content-Based,CollaborativeRecommendation[J].CommunicationsofTheACM,1997,40(3):66-72.
[13]郭丽丽.E-learning个性化推荐系统研究[D].山东:山东科技大学,2008.
[14]JohnS.Breese,DavidHeckerman,CarlKadie. EmpiricalAnalysisofPredictiveAlgorithmsforCollaborativeFiltering[C].ProceedingUAI's98Proceedingsof theFourteenthconferenceonUncertaintyinArtificialintelligence,1998,SanFrancisco:43-52.
[15]NicholasJ.Belkin,W.BruceCroft.Information FilteringandInformationRetrieval:TwoSidesofthe SameCoin[J].CommunicationofTheACM,1992,35(12):29-38.
[16]曾春,刑春晓,周立柱.基于内容过滤的个性化搜索算法[J].软件学报,2003,14(5):999-1004.
[17]张开飞.个性化推荐学习系统的模型研究与设计[D].上海:华东师范大学,2009.
[18]叶海琴,尹世君.个性化推荐预测模型性能指标研究[J].软件导刊,2010,9(8):31-32.
[19]李高敏.基于协同过滤的教学资源个性化推荐技术的研究及应用[D].北京:北京交通大学,2011.
[20]张炜.教育信息共享系统中个性化推荐服务研究[D].陕西:西安电子科技大学,2008.
(编辑:杨馥红)
G434
B
1673-8454(2016)11-0067-05
