基于改进TF-IDF算法的文本分类方法研究
2016-10-17贺科达朱铮涛
贺科达, 朱铮涛, 程 昱
(广东工业大学 信息工程学院,广东 广州 510006)
基于改进TF-IDF算法的文本分类方法研究
贺科达, 朱铮涛, 程昱
(广东工业大学 信息工程学院,广东 广州 510006)
类别关键词是文本分类首先要解决的关键问题,在研究利用类别关键词及TF-IDF算法对文本进行分类的基础上,提出了一种改进的TF-IDF算法.首先建立类别关键词库,并对其进行扩充及去重,克服了向量空间模型不能很好调节权重的缺点.通过加入文档长度权值修正文档中关键词的权重,有效地解决了原有特征词条类别区分能力不足的问题.采用贝叶斯分类方法,结合实验验证了该算法的有效性,提高了文本分类的准确度.
提取; 特征选择; 文本分类; 预处理
随着网络技术的不断发展,全球信息化以惊人的速度快速发展.近年来更是在全球范围内掀起了传播数据信息的浪潮,企业积累了大量的数据,这是它们最为宝贵的财富.对海量数据的获取、汇总、聚类[1]、分类显得尤为重要,其中文本分类的作用也越来越重要.文本分类[2]指对于所给出的文本集合,将每篇文档归入到按照预先定义的一个或者多个主题类别当中.而文本自动分类则是通过计算机程序来实现文本的准确、高效的分类.文本分类是数据挖掘中的一个重要内容.中文文本分类的基本步骤是中文分词、特征提取、训练模型、预测类别等步骤.在众多的文本分类算法中,主要有Rocchio算法、朴素贝叶斯分类算法[3]、决策树算法[4]、K-means算法、神经网络算法和SVM(Support Vector Machine)算法[5].
文本分类的研究可以追溯到20世纪60年代, 1957年美国IBM公司的卢恩(H.P.Luhn)提出的基于词频统计的抽词标引法[6],在这一领域进行了开创性的研究.对于TF-IDF算法,国内外学者做了大量的改进工作,研究内容主要围绕IDF计算方法展开,对其进行改进.TF-IDF算法源于Salton在文献[7]中提出的TFDF算法.此后,Salton多次论证TFDF算法在信息检索中的有效性[8].在此基础上,国外学者Forman[9]运用概率统计方法度量并比较关于类别分布的显著性,对IDF的计算方法采用二元正太分割(Bi-Nor-mal Separation)计算方法.Lan等[10]提出TF-RF算法,用相关性频率(RF)方法代替IDF计算方法,在这一领域进行了卓有成效的研究.国内学者张玉芳等[11]提出增加在某一个类中频繁出现的词条的权重,结合遗传算法[12]使得分类准确率有所提高.张瑾[13]通过加入位置权值及词跨度权值来避免单纯采用TF-IDF算法产生的偏差.虽然还有一些学者对TF-IDF方法进行了其他方面的一些改进,但是还存在特征词权值波动,对信息增益、信息熵、相关性频率等计算量大,复杂度高等问题[14].针对这些问题,本文研究TF-IDF改进算法,解决向量空间模型问题,通过加入文档长度权值,修正文档中关键词的权重,有效地解决了因为权值问题使得特征词条的类别区分能力不足的问题.
1 文本预处理
1.1文本分词及关键词选取
文本分词是文本处理中最基本的过程,在中文文本中可以选择字、词或者词组作为文本的特征项,相比较而言,词比字和词组具有更多优势,具有更强的表达能力,更加容易切分.因此,在对文本进行预处理时采用的方法通常是分词处理.本文采用ICTCLAS[15]对每篇文章进行中文分词,根据特征权重计算方法构建VSM(Vector Space Model)模型.如果把所有的词都作为特征项,则特征向量维数过大,计算量也随之变大,故需要减少词的数量以此来降低向量空间维数,从而减少计算量,提高计算速度和精准度.本文采用选取关键词对文章进行降维,对于每一个类别的文章都有其对应的关键词,而每篇文章都是围绕相应的主题展开的,各个主题之间都有相对明显的区别,每个类可以通过类别关键词来表示.所以,文本中的关键词对文本分类具有特殊的作用.例如,一篇关于环境的文章中可能会出现“海啸”、“大气污染”、“温室效应”等词汇.根据类别关键词可以组成关键词词库,这样使得分类效率和速度得到很大的提升.关键词库组建主要包括以下几个方面:
(1) 通过分词软件得到类别关键词词汇列表;
(2) 根据人工分类体系将每个类别中的文章主题词组成一个类别词库;
(3) 根据关键词的同义词对其进行拓展,然后去掉重复词汇.
1.2文本表示
在对文本进行分类时,需将文本转化为向量,能够被计算机处理,其中向量空间模型是文本表示的常用模型之一.VSM[16]模型概念简单,把文本内容转化为向量运算,并且以空间上的相似度表达语义相似度,直观易懂.文档被看作为一个多维向量,特征项当作其中的一维,特征项的TF-IDF值作为向量分量的值,通过余弦距离来表达文本相似性度量.
2 TF-IDF算法及其改进
2.1传统的TF-IDF及其存在的问题
TF-IDF是一种统计方法,广泛应用于文本分类, TF指的是一个词或者词组在文档中的频率,其主要思想[17]是:若在一篇文章中某个词或词组的TF值高且其在其他的文章中的TF值小,那么就认为该词或者词组的类别区分能力强,和其他的词或词组相比,其更适宜用于分类.TF-IDF实际上是:TF×IDF,TF词频(Term Frequency) 表示词条在文档d中出现的频率,IDF反文档频率(Inverse Document Frequency)是一个词或者词组的普遍重要性的度量,常用计算公式为式(1)、(2)[18]:

(1)
其中t表示特征词条在文档w中出现的次数,s表示文档w中出现的总词条数.

(2)
其中D表示语料库中文档总数,d表示包含特征词条的文档总数.
由式(2)[19]可知,如果语料库中的某一类文档C中包含特征词条t的文档数为n,而在其他类中包含t的文档总数为m.所以,在文档集中所有包含特征词条t的文档数d=n+m,当n增大的时候,d也会增大.当d增大时,按照式(2)得到的IDF的值会变小,则说明该特征词条t的对于文档类别来说,它不能很好地区别于其他的文本类别,表明它的类别区分能力不是很强.但是在实际文本分类中,如果特征词条t在文本类别Ci中的文档中频繁出现,那么就说明特征词条t能够很好地代表类别Ci的文本的特征,具有较好的类别区分能力.对于类似特征词条t这样的词条,在进行权重赋值时,相较于其他的特征词条应该赋予更高的权重,并应当选来作为Ci类文本的特征词,便于与其他类的文档有所区别.当关键词在其他类频繁出现时,原有IDF计算方法造成了分类能力的下降,这就是TF-IDF算法的不足之处.
2.2改进后的TF-IDF算法
在多数文本分类中,特别是多类别文本分类中,对于某个特征词条,该词条可能会出现在该类别的多个文本中,也有可能出现在其他类别中,故而会使得特征词条的权值不同.而权值的不同对分类的稳定性产生很大的影响,在一定程度上会有波动现象.
针对权值波动现象,本文提出了IDF的改进算法.在所选的数据集中有待分类文档的类别集合C={C1,C2,…,Cm},Cm(Cm∈C)中的文档集合D={d1,d2,…,dn},其中n为文档的数目.文档中出现的特征词集合I={i1,i2,…,ik},其中ik为Cm中所有出现的特征词以及根据其拓展后的特征词集合.针对传统TF-IDF算法的不足,计算IDF时,以特征值的频率与对应文档的长度乘积比代替特征值的频率比,对其进行了均值化,这样可以修正文档中的关键词权重,减少文档长度对权值的影响.改进的IDF权重计算公式:
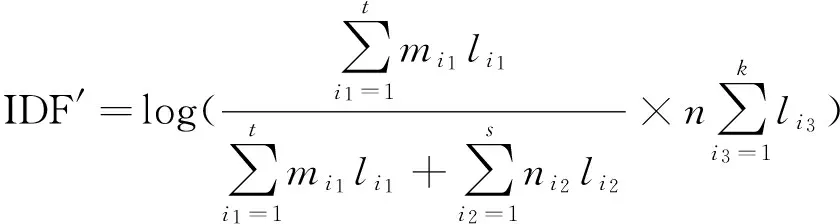
(3)
其中mi1表示特征词条i在Ci类文本i1中出现的次数,li1表示文本i1的长度,t表示所属类别中包含特征词条i的文本数目,ni2表示除了Ci类外,在其他类文本i2中特征词条i出现的次数,li2表示文本i2的长度,s表示所属类别中包含特征词条i的文本数目,n表示文本中特征词条i的总数目,li3表示文本i3的长度,k表示包含特征词条i的文本总数.
2.3分类算法
本文描述了文本预处理的方法并分析了TF-IDF算法的不足之处,据此本文对其进行了优化,在此基础上本文利用贝叶斯算法[20]对文本进行分类,并通过实验来评价TF-IDF算法的性能.其主要步骤如下:
(1) 通过分词软件对数据集中的文本进行关键词提取并对其进行扩展得到关键词库;
(2) 对得到的关键词库建立VSM模型,把文本内容转化为向量运算;
(3) 利用优化后的TF-IDF算法分别计算每个关键词的TF-IDF值;
(4) 将获得的TF-IDF值作为特征向量,采用贝叶斯算法对文本进行分类,结合实验评估改进算法的性能.
3 实验及分析
3.1评价标准
对于优化后的算法需对其性能进行评估,评估文本分类系统的性能,国际上有通用的评估指标,包括召回率(Recall)、查准率(Precision)和F1评估值3项.本实验采用这3项指标对改进的后的TF-IDF算法进行测试.其对应的公式[21]分别如下:

(4)
召回率是衡量文本分类系统从数据集中分类成功度的一项指标,体现了分类的完备性,A表示分类正确的文本数,(A+B)表示总的文本数.
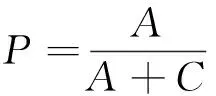
(5)
查准率是衡量文本系统中分类的准确程度,A表示分类正确的文本数,(A+C)表示总的文本数.
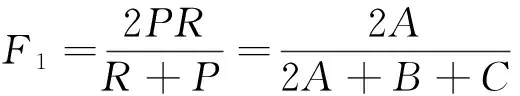
(6)
召回率和查准率之间具有互逆关系,它们反映了分类准确性的两个不同方面,当P的指标上升时,会导致R的指标下降.所以取两者的调和均值,由此可知,F1的值越大,分类效率也就越好.
3.2实验数据
数据集采用复旦大学计算机信息与技术系国际数据库中心自然语言处理小组的语料库,选取了其中6个主题作为本文的数据集,其中包括计算机、环境、农业、经济、政治、体育.经过选取关键词后,将文本分为训练文本和测试文本,两者彼此不重叠.各主题类的实验文本数如表1所示.
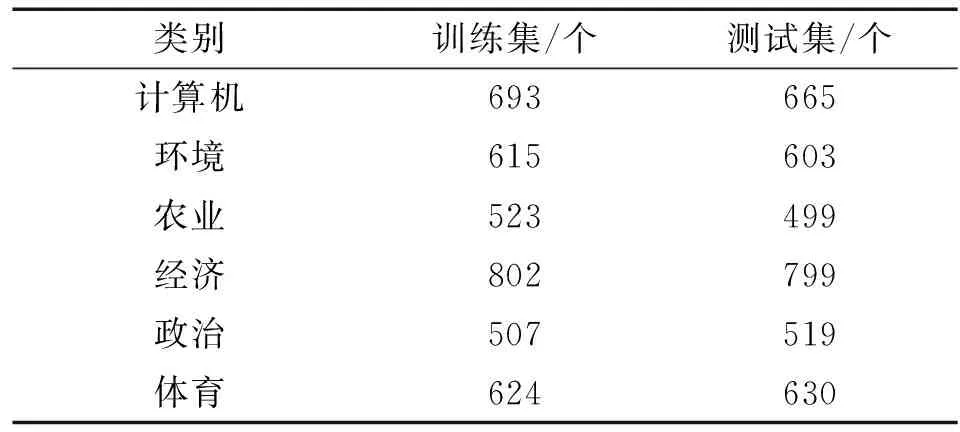
表1 实验数据
3.3实验结果及分析
实验分别对文本进行关键词提取,根据2.2提出的方法分别计算每个关键词的TF-IDF值,采用贝叶斯算法对文本进行分类,把经本文改进的TF-IDF的分类效果与引入位置权值及词跨度权值的TF-IDF的分类效果进行比较,得到的分类结果如表2所示.
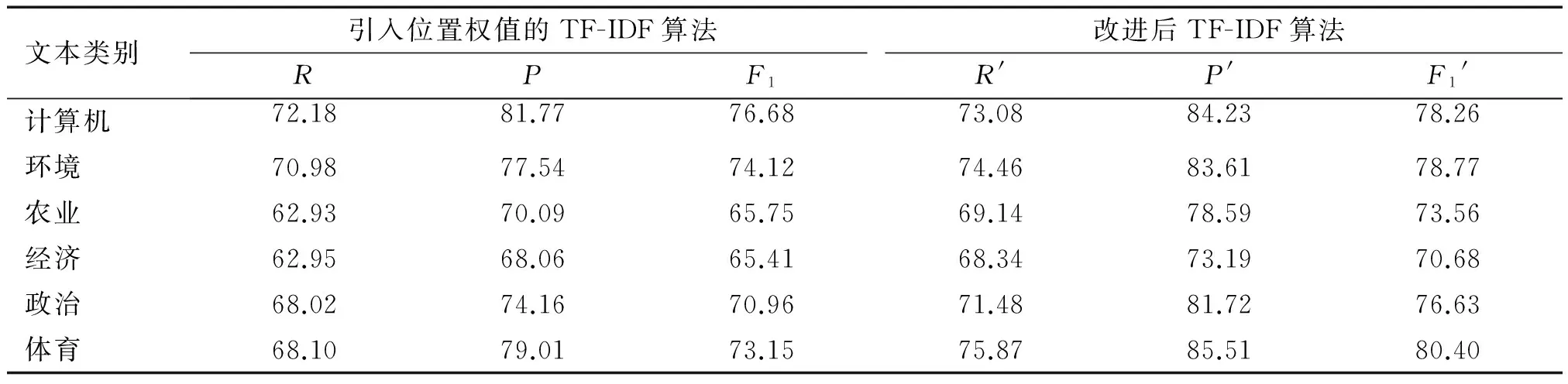
表2 改进方法的比较实验结果
表2中R、P和F1,R′、P′和F1′分别指的是引入位置权值及词跨度权值的TF-IDF算法以及经本文改进后的TF-IDF算法计算得出的召回率、查准率及F1值.从表2的实验结果可以看出,经过本文改进的TF-IDF,不管是召回率、查准率还是F1值,相比于引入位置权值及词跨度权值的TF-IDF算法都有一定的提升.可以分析得出本文改进的TF-IDF算法在文本分类领域中有一定的优势.
4 结语
本文针对类别关键词改进了TF-IDF算法,首先对文本进行关键词提取,然后通过计算其改进后的TF-IDF值形成特征向量,最后根据贝叶斯算法对文本进行分类.性能对照实验结果表明,经过对TF-IDF算法进行优化后,分类准确率得到了一定的改善.也就是说改进后的TF-IDF方法优于引入位置权值及词跨度权值的TF-IDF的分类效果.本文通过提取类别关键词,减少了特征向量维数,使得分类的时间效率有了一定的提高,可以减少约3%.因此改进后的TF-IDF方法是有效且可行的.
关键词的选取工作还有待进一步完善:当两个类别相近时,其关键词也有很多同义词,故而会使得分类效果不好,比如实验中容易将农业类的文章划分到环境类中.
[1] 蒋盛益,王连喜.聚类分析研究的挑战性问题[J]. 广东工业大学学报, 2014, 31(3):32-38.
JIANG S Y, WANG L X. Some challenges in clustering analysis[J]. Journal of Guangdong University of Technology, 2014, 31(3): 32-38.
[2] 谭学清,周通,罗琳.一种基于类平均相似度的文本分类算法[J].现代图书情报技术, 2014, 250 (9): 66-73.
TAN X Q, ZHOU T, LUO L. A text classification algorithm based on the average category similarity[J].New Technology of Library and Information Service, 2014, 250 (9): 66-73.
[3] GENG X L, GAO X Y, ZHAO B. Research on Chinese text classification based on Naive Bayesian method[C]∥Proceedings of the Fifth International Symposium on Test Automation & Instrumentation (Vol.1).[S. l.]:[s. n.], 2014: 226-230.
[4] KATZ G, SHABTAIA, ROKACH L. CONFDTREE O N: A statistical method for improving decision trees[J].Data Management and Data Mining, 2014,29(3):392-407.
[5] 陈培文,傅秀芬.采用SVM 方法的文本情感极性分类研究[J].广东工业大学学报,2014,31(3):95-101.
CHEN P W, FU X F. Research on sentiment classification of texts based on SVM[J]. Journal of Guangdong University of Technology, 2014, 31(3): 95-101.
[6] 沈志斌,白清源.文本分类中特征权重算法的改进[J].南京师范大学学报, 2008, 8(4): 95-98.
SHEN Z B, BAI Q Y. Improvement of feature weighting algorithm in text classification[J]. Journal of Nanjing Normal University, 2008, 8(4): 95-98.
[7] SALTON G, YU C T. On the construction of effective vocabularies for information retrieval[J]. ACM Sigplan Notices, 1975, 9(3): 48-60.
[8] SALTON G. Extended boolean information retrieval[J].Cornell University, 1983, 11(4): 95-98.
[9] FORMAN G. BNS feature scaling: an improved representation over TF-IDF for SVM text classification[C]∥Proceedings of the 17th ACM Conference on Information and Knowledge Management. USA, California: ACM, 2008: 263-270.
[10] LAN M, TAN C L, LOW H B, et al. A comprehensive comparative study on term weighting schemes for text categorization with support vector machines[C]∥Special Interest Tracks and Posters of the 14th International Conference on World Wide Web.[S.l.]: ACM, 2005: 1032-1033.
[11] 张玉芳,彭时名,吕佳.基于文本分类TFIDF方法的改进与应用[J].计算机工程, 2006, 32(19): 76-78.
ZHANG Y F, PENG S M, LYU J. Improvement and application of TFIDF method based on text classification[J] Computer Engineering, 2006, 32(19): 76-78.
[12] 谷小青,易当祥,刘春和.遗传算法优化神经网络的拓扑结构与权值[J].广东工业大学学报,2006, 23(4): 64-69
GU X Q, YI D X, LIU C H. Optimization of topological structure and weight value of artificial neural network using genetic algorithm[J]. Journal of Guangdong University of Technology, 2006, 23(4): 64-69.
[13] 张瑾.基于改进TF-IDF算法的情报关键词提取方法[J].情报杂志, 2014, 33(4): 153-155.
ZHANG J. A method of intelligence key words extraction based on improved TF-IDF[J]. Journal of Intelligence, 2014, 33(4): 153-155.
[14] 王清毅,张波,蔡庆生.目前数据挖掘算法的评价[J].小型微型计算机系统, 2000, 21(1): 75-78.
WANG Q Y, ZHANG B, CAI Q S. Evaluation of current data mining algorithms[J] Mini- Micro System, 2000, 21(1): 75-78.
[15] ZHANG H P, YU H K, XIONG D Y, et al. HHMM-Based Chinese lexical analyzer ICTCLAS[C]∥Proceedings of the second SIGHAN workshop on Chinese language processing-Volume 17. PA: Association for Computational Linguistics, 2003: 184-187.
[16] 郭庆琳,李艳梅,唐琦. 基于VSM的文本相似度计算的研究[J].计算机应用研究2008, 25(11): 3256-3258.
GUO Q L, LI Y M, TANG Q. Similarity computing of documents based on VSM[J]. Application Research of Computer, 2008, 25(11): 3256-3258.
[17] 覃世安,李法运.文本分类中TF-IDF方法的改进研究[J].现代图书情报技术, 2013, 38(10): 27-30.
TAN S A, LI F Y. Improved TF-IDF method in text classification[J]. New Technology of Library and Information Service, 2013, 38(10): 27-30.
[18] GERARD SALTON,CHRISTOPHER BUCKLEY.Term-weighting approaches in automatic text retrieval[J]. Information Processing & Management,1988, 24( 5) : 513 -523.
[19] 徐山,杜卫锋.不可靠语料库的提纯及词权度量指标IDF的改进[J].微型机与应用, 2013, 32(4): 61-63.
XU S, DU W F. The purification of unreliable corpus and the improvement of word weight index IDF[J]. Microcomputer & Its Applications, 2013, 32(4): 61-63.
[20] 骆桦,张喜梅.基于贝叶斯分类法的股票选择模型的研究[J].浙江理工大学学报, 2015, 33(3): 418-422.
LUO H, ZHANG X M. Research on stock selection model based on bayesian classifier[J]. Journal of Zhejiang Sci-Tech University, 2015, 33(3): 418-422.
[21] YIMING Y. An evaluation of statistic approaches to text categorization[J]. Information Retrieva, 1999, 1(12): 69-90.
A Research on Text Classification Method Based on Improved TF-IDF Algorithm
He Ke-da, Zhu Zheng-tao,Cheng Yu
(School of Information Engineering, Guangdong University of Technology, Guangzhou 510006, China)
Establishing category keywords is the key problem in text classification, which should be solved first. On the basis of the classification of text by using the category keywords and TF-IDF algorithm, an improved TF-IDF algorithm has been proposed to overcome the shortcomings of the vector space model, which cannot well adjust the weights. Firstly, category keyword library should be established, and the expansion and duplication be carried out. The weight of keywords in the document is modified by the addition of the length of the document, and the shortage of the original features of the entry class distinction ability is solved effectively. By using Bayesian classification method, combined with the experiments, the effectiveness of the algorithm is verified, and the accuracy of text classification improved.
extraction; feature selection; text classification; pretreatment
2015- 09- 22
国家自然科学基金资助项目(11204043)
贺科达(1989-),男,硕士研究生,主要研究方向为数据与文本挖掘.
朱铮涛(1967-),男,副教授,博士,主要研究方向为计算机视觉检测技术.E-mail:511972136@qq.com
10.3969/j.issn.1007- 7162.2016.05.009
TP393
A
1007-7162(2016)05- 0049- 05
