基于FPU的高速卡尔曼滤波器公式推导法硬件设计
2016-10-14刘超严伟
刘超 严伟
基于FPU的高速卡尔曼滤波器公式推导法硬件设计
刘超 严伟†
北京大学软件与微电子学院, 北京 100871; † 通信作者, E-mail: yanwei@ss.pku.edu.cn
基于卡尔曼滤波器的传统硬件实现方式, 根据滤波模型和矩阵运算, 将滤波公式进行推导和化简, 然后利用“自底向上”的设计思路, 设计滤波公式需要的底层FPU (float point unit), 从而实现整个卡尔曼滤波系统。以这种方法设计的卡尔曼滤波器, 不仅摆脱了传统实现方式对于平台的依赖性, 增加了系统的可移植性和应用范围, 并且滤波速度比传统矩阵运算法有明显提升。对于匀加速滤波模型, 给出公式推导法和矩阵运算法的详细数据对比, 采用该方法设计的卡尔曼滤波器, 滤波精度保持原来的水平, 滤波速度提升为传统矩阵运算法的2.1倍。
卡尔曼滤波器; 目标跟踪; IEEE754; 浮点数运算; 实时性
卡尔曼滤波理论[1]在 20 世纪 60 年代提出后, 在雷达跟踪、导航和控制等领域获得广泛应用。多维卡尔曼滤波算法的实现需要复杂的矩阵运算, 在卡尔曼滤波器的实际应用中, 软件实现方式很难满足系统对高实时性的要求, 硬件实现方式可以利用并行处理的优点, 加快滤波速度。在卡尔曼滤波器的传统硬件实现方式中, 通常利用第三方开发平台, 如借助LABVIEW FPGA和DSP Builder的图形化开发工具或者 QuartusⅡ的浮点数运算 IP 核[2-4], 或者通过构建矩阵运算模块来实现滤波算法[5], 不仅增加了滤波算法对平台的依赖性, 降低了系统的可移植性和应用范围, 而且复杂的浮点数矩阵运算成为进一步提升滤波速度的瓶颈。
本文基于卡尔曼滤波器的传统实现方式, 首先根据滤波变量之间的关系将高维模型拆分为低维滤波模型; 再根据低维滤波模型的滤波参数设置情况, 将组成卡尔曼滤波器的5条滤波公式进行彻底推导并化简, 以降低滤波算法的时间复杂度; 然后设计基于IEEE754标准的浮点数运算单元FPU[6], 并利用“自底向上”的设计思路, 以FPU作为底层模块, 对推导后的滤波公式加以实现, 进而构成整个滤波系统。
1 卡尔曼滤波器介绍和算法优化
卡尔曼滤波器用于估计离散时间过程的状态变量, 这个离散时间过程由一个线性随机差分方程描述[7], 称为系统方程:

系统的测量方程为

矩阵,,,由实际滤波模型决定, 可以是确定的, 也可能随时间变化[8],和分别是系统噪声和测量噪声, 为相互独立的高斯白噪声。
从形式上看, 卡尔曼滤波器由 5 个公式组成。其中式(1)完成状态预测, 式(2)完成协方差预测, 式(3)用来计算卡尔曼增益, 式(4)完成状态的滤波估计, 式(5)用来更新滤波协方差。
状态预测方程:
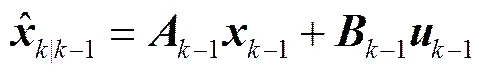
协方差预测方差:
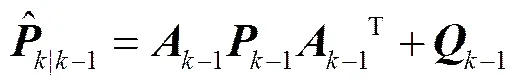
卡尔曼增益方程:
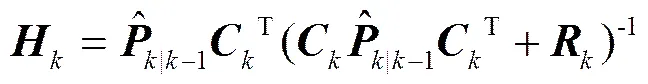
滤波估计方程:
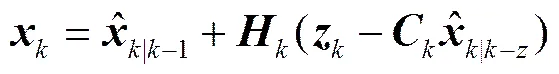
协方差更新方程:
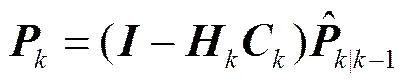
我们考虑一个雷达实时跟踪系统, 假设有一个在三维空间--内运动的飞行器, 设,和分别为的距离、方位角误差和仰角误差。考虑,Dq和Dj是时间的函数, 并且一阶导数和二阶导数分别表示为,,和,,,为采样时间单位。对该系统有
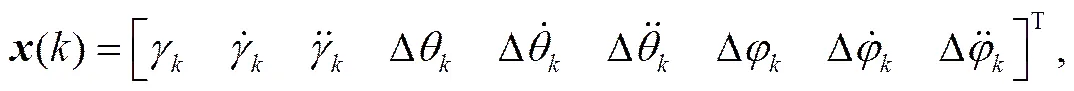
对于该模型, 系统无额外控制量输入, 即有控制量为零矩阵, 此处基于算法完整性考虑, 假设控制矩阵的维度为×1, 控制量为1×1矩阵。所以有
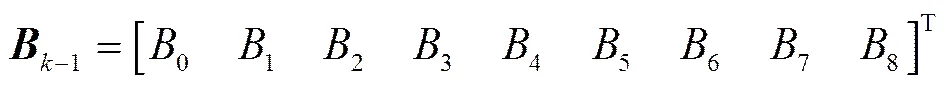
假设原点位置有一雷达对飞行器进行目标跟踪, 有
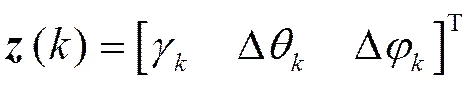
。
容易证明该系统可以分解为3个具有相似状态空间描述的子系统[9], 即这个九维滤波问题可以拆分成3个三维滤波模型: 距离跟踪模型、方位角跟踪模型和仰角跟踪模型, 并且每个滤波模型的转换矩阵和测量矩阵都相同, 分解之后的三维模型为

,

,
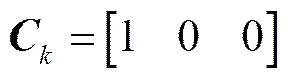
根据矩阵运算的性质, 将上述滤波参数带入滤波公式, 对三维滤波模型的 5 个公式做彻底推导并简化, 从而将矩阵运算转化为加、减、乘、除运算, 这里给出式(1)的推导结果, 其余 4 个公式可做类似推导:
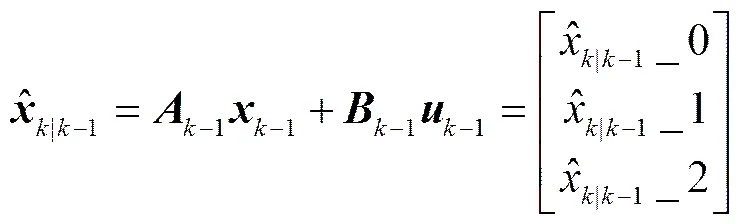
将矩阵运算展开得各元素如下:

,
2 电路设计
2.1 系统结构
系统的结构如图 1 所示, 需要说明的是, 图中所有与滤波算法有关的变量或者信号均是矩阵形式, 此处为方便表示, 只用一个信号引脚表示整个矩阵。
CLKGEN 模块利用外来时钟信号生成系统时钟信号, 并产生系统初始化信号。CAL_1, CAL_2, CAL_3, CAL_4和CAL_5分别完成滤波算法 5 个公式的内容, 即状态预测, 协方差预测, 卡尔曼增益的计算, 状态的滤波估计以及滤波协方差的更新。MUX_X和MUX_P分别用来控制算法迭代过程中的状态更新和协方差更新。寄存器组 REGS_X和 REGS_P 由若干寄存器构成, 用来完成不同模块之间的数据寄存和时序调整。AFIFO 为异步 FIFO (first in first out), 用来缓存输入数据, 匹配数据输入速度和滤波速度[10]。
FPU 的结构如图 2 所示, FPU 模块完成基于IEEE754标准的32位浮点数的加、减、乘、除运算, 支持对两个操作数的加、减、乘、除运算, 是卡尔曼滤波器的底层基础运算模块。
2.2 系统设计思路
系统采用“自底向上”的层次化设计方法, 首先设计滤波算法所需的浮点数运算单元FPU,然后以 FPU 为底层模块分别构建5个滤波公式模块CAL_1, CAL_2, CAL_3, CAL_4和CAL_5, 进而构成最顶层的卡尔曼滤波系统。
以矩阵乘法运算为例, 一个×与×的矩阵相乘, 如果所有元素参与运算的话, 需要的乘法运算次数是××, 需要的加法运算次数是×× (–1)。针对传统矩阵运算法的不足, 我们根据滤波模型的具体参数设置和矩阵运算的性质, 将构成滤波算法的 5 个公式进行推导和简化, 并用 FPU 直接实现推导、简化后的滤波公式, 从而减少滤波算法所需的运算次数, 提升硬件处理速度。
卡尔曼滤波器5个公式的数据传递情况如图3所示, 根据滤波公式之间的数据引用情况, 可以将5个公式分成3个执行状态和时序。其中, CAL_1和 CAL_2 组成第 1 个执行时序, CAL_3 组成第 2个执行时序, CAL_4 和 CAL_5 组成第 3 个执行时序。
系统各模块的处理速度与 FPU 的运算速度紧密相关, 在设计FPU时, 我们综合考虑浮点数运算的速度和精度, 设计的FPU执行一条加、减、乘、除运算需要的初始化时间是4个时钟周期, 完成初始化之后, 每个时钟周期即可完成一次加、减、乘、除运算。
由 FPU 构建的上层滤波运算模块 CAL_1, CAL_2, CAL_3, CAL_4和CAL_5初始化所需时间由各模块运算最慢的元素决定, 具体计算各个公式的各个元素时, 暂不参加计算的数据采用模块内部的寄存器组暂时保存。表1是使用公式推导法和传统矩阵运算法时, 组成卡尔曼滤波器的5个滤波公式模块完成模块初始化需要的时间对比。
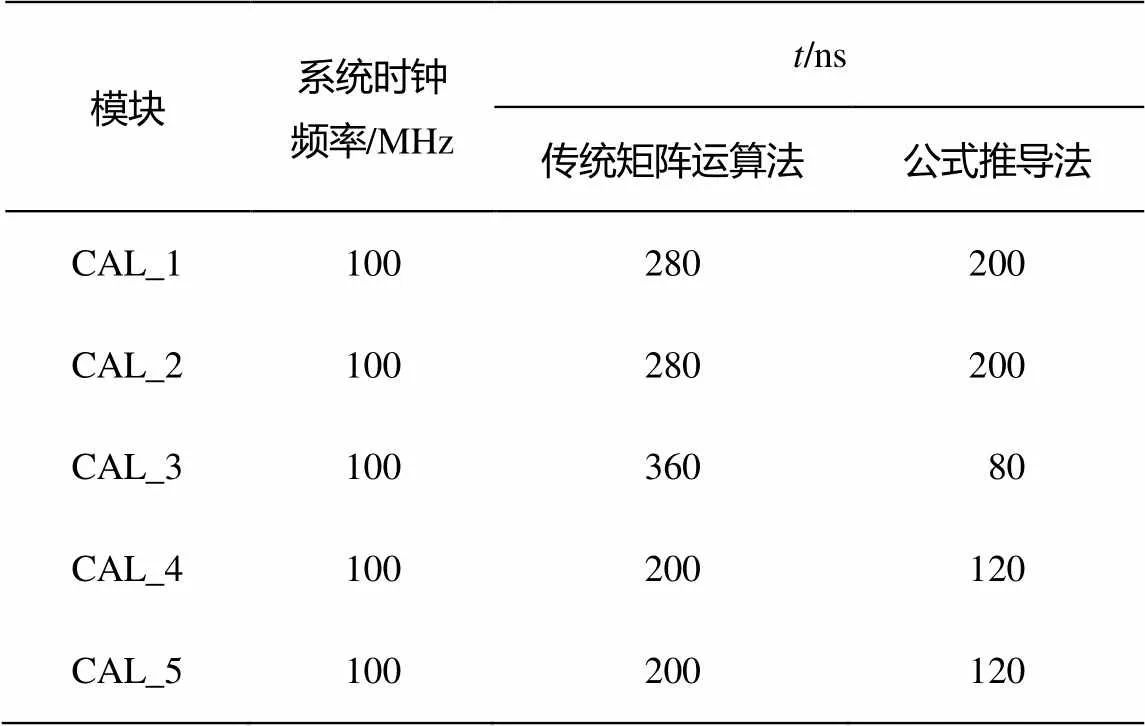
表1 初始化时间对比
各个滤波模块的初始化时间会影响系统的整体滤波速度。在系统时钟频率为 100 MHz的情况下, 使用传统矩阵运算法设计完成的卡尔曼滤波器, 完成一次滤波运算需要 840 ns; 运用公式推导法设计完成的卡尔曼滤波器, 完成一次滤波仅需 400 ns。可以看出, 使用本方法是使用传统矩阵运算法速度的2.1倍。
2.3 FPGA平台参数评估
图 4 为利用Quartus Ⅱ软件, 对系统进行分析和综合后得到的在FPGA平台下的参数评估结果, 显示该系统的组合逻辑、时序逻辑等参数的资源占用情况。
3 应用结果
图 5 是卡尔曼滤波器的系统输入值 measure_ input, 包含系统噪声和测量噪声。从图中可以看出, 该输入信号包含一定的噪声干扰, 需要通过卡尔曼滤波器对其进行滤波处理。
图 6 是经过卡尔曼滤波算法滤波优化之后的原变量输出值x_now_0及其一阶导数值x_now_1和二阶导数值x_now_2。可以看出, x_now_0, x_now_1和x_now_2在经过一定次数的滤波算法迭代后, 都得到很好的去噪效果。
图 7 是预测误差矩阵p_pred_00, p_pred_11和p_pred_22 的曲线图, 可以看出, 误差随滤波算法迭代次数的增加而变化。
4 总结
本文根据滤波变量之间的关系将高维模型拆分为低维滤波模型, 再根据低维滤波模型的滤波参数设置情况, 将组成卡尔曼滤波器的5个滤波公式进行彻底推导和简化, 然后设计浮点数运算单元FPU, 并利用“自底向上”的设计思路, 以FPU作为底层模块对推导后的滤波公式加以实现, 进而构成整个滤波系统。采用此方法设计的卡尔曼滤波器在保证滤波精度的同时, 还摆脱了滤波平台的依赖性, 增加了系统的可移植性和应用范围, 并且提升了滤波速度,可以更好地满足实际工程应用中对卡尔曼滤波器的高实时性要求。
参考文献
[1]Kalman R E. A new approach to linear filtering and prediction problems. Transaction of the ASME —Journal of Basic Engineering, 1960, 82: 35–45
[2]Fonseca J V, Oliveira R C L, Abreu J A P, et al. Kalman filter embedded in FPGA to improve tracking performance in ballistic rockets // 2013 UKSim 15th International Conference on Computer Modelling and Simulation. Cambridge, 2013: 606–610
[3]杨丹. 卡尔曼滤波器设计及其应用研究[D]. 湘潭: 湘潭大学, 2014
[4]Wu Panlong, Zhang Lianzheng, Zhang Xinyu. The design of DSP/FPGA based maneuvering target tracking system. Wseas Transactions on Circuits and Systems, 2014, 13: 75–84
[5]赵大建, 赵伟, 张兆亮, 等. 基于FPGA的Kalman滤波器实现研究. 现代电子技术, 2012, 35(6): 67–70
[6]ANSI/IEEE Std 754-1985, IEEE Standard for Binary Floating-Point Arithmetic[S]. Piscataway, NJ: IEEE Standards Board, 1985
[7]Welch G, Bishop G. An Introduction to the Kalman filter. University of North Carolina at Chapel Hill, 1995(7): 127–132
[8]Auger F, Hilairet M, Guerrero J M, et al. Industrial applications of the Kalman filter: a review. IEEE Transactions on Industrial Electronics, 2013, 60(12): 5458–5471
[9]Chui C K, Chen G. Kalman filtering with real-time applications. 4th ed. Berlin: Springer, 2008: 45–48
[10]王凯, 孙锋. 异步FIFO的设计分析. 电子器件, 2014(3): 431–434
High-Speed Hardware Design of Kalman Filter Based on FPU with Formula Derivation Method
LIU Chao, YAN Wei†
School of Software and Microelectronics, Peking University, Beijing, 100871; † Corresponding author, E-mail: yanwei@ss.pku.edu.cn
Based on the traditional hardware implementations of Kalman filter, the authors derive and simplify the filtering formulas according to the filtering model and matrix operations, and then design underlying FPU (float point unit) needed by the filtering formulas according to the “bottom-up” design thinking, to implement the complete Kalman filter system. The Kalman filter designed by this method not only gets rid of dependence on third-party platforms and increase the portability and application areas of filtering system, but the filtering speed improves significantly than traditional matrix operation method. For a constant acceleration filtering model, this paper provides detailed data comparison between formula derivation method and traditional matrix operation method, the Kalman filter designed by this method maintains the accuracy of the previous level and achieves the computing speed 2.1 times, compared with the traditional matrix operation method.
Kalman filter; target tracking; IEEE754; floating-point operation; real-time
10.13209/j.0479-8023.2015.135
TN492
2015-04-22;
2015-06-04; 网络出版日期: 2016-04-07
江苏省产学研联合创新资金——前瞻性联合研究项目(BY2013018)资助
