基于java的分库数据专利技术在工业离散式数据库中的应用
2016-10-13张捷
张捷
(凯迈〔洛阳〕机电有限公司,河南 洛阳 471000)
基于java的分库数据专利技术在工业离散式数据库中的应用
张捷
(凯迈〔洛阳〕机电有限公司,河南 洛阳471000)
分库数据专利技术是将集中存放、管理的数据离散式存放,解决大数据,减轻数据库负载,提高系统响应速度,满足大型系统需求的技术之一。工业生产数据大多是离散式存放于各个工控机当中,目前鲜有在集中管理工业数据方面的应用。而分库数据技术本着逆向思维,将原本离散的数据进行逻辑上的集中管理,并通过相关逻辑判断,进行数据管理、分析与运算,实现了离散式数据的统一管理。本论文首先就此工业数据与分库数据技术的应用现状进行了详细论述,并针对性研究实现工业数据统一管理的具体方式和算法,还对该技术在工业领域的应用前景作了分析。
分库数据;工业数据;离散式;分布式;云存储
随着工业信息化程度的提升,对于网络、数据库等技术的应用也逐渐深入。越来越多的工业软件习惯采用Oracle、SQLServer、Mysql等数据库进行数据存储,认为一方面促使工业数据结构化,同时也便于日后数据的管理。然而,其中也存在一定的问题。比如,多个工业数据库中的数据如何统一管理。尤其是针对相同设备、数据格式相同、需要就数据进行管理、分析与比对等等情况,这些工业设备往往都离散放置在各处,便给数据管理造成了极大的困难。
目前,一般的解决方案是利用第三方软件或利用数据库同步数据功能来实现数据同步。第三方软件将离散式的数据集中存放在统一的数据库当中,而后再进行相关数据处理,如syncnavigator,rsync,HASH Tree……,其所基于的思想是数据的同步、备份、高可用性等,但这往往也会并存一定的问题。最棘手的是当工业终端数据库的表在不断增加的情况下,以上两种方案均无法自动解决,仍需人工手动去变更配置程序。况且,同步后集中存放于同一服务器中的数据依然是分库存放,没有改变其原有架构,只是将离散的数据从物理形式上同一存放、管理而已。
此外,在大型系统中,数据库中的数据量未必是可控的。在未进行分库分表[1]的情况下,随时间和业务的堆积,库中的表会愈发增多,表中的数据量也会相应增大,难免会悄然增加数据操作、增删改查的开销。此外,由于无法进行分布式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)也是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。因此,在大型数据库中,分库技术应用非常广泛。而在工业设备相对离散的情况下,传统的解决方案可靠性较低,可操作性也不强。
随着企业信息化的深入,企业中相关的应用系统也基本已经上线,可以利用现有系统,增加工业数据管理模块,管理相关工业级数据,并进行相关数据处理。
分库数据专利技术基于数据的分布式管理与云存储,在离散式数据库[2]中的应用属于一种可从本源上解决离散数据集中管理的问题,旨在从逻辑上灵活地管理离散的数据库数据,降低用户的软件维护成本,切实提高用户的体验度。它将分布式存储的理念逆向思维使用在工业数据管理上,一定程度上也促进了互联网技术与工业技术的互相融合,有助于提高工业设备数据分析效率。
1 工业数据管理现状及分库分表的思想
1.1 工业数据管理现状
工业数据与其他领域数据不同,有着数据量大、结构复杂、离散式分布等特点。然而,由于工业领域的计算机技术的迟后性,一部分工业数据往往仍采用记事本、excel等方式存储,对数学的管理办法无非是将数据集中存放在一处,很难进行统一管理,这不仅导致数据没有结构化,更难对数据进行系统的统计、分析和处理。随着信息化的逐步深入,工业数据逐步采用数据库的存储方式,渐变式将数据结构化[3],但这些数据仍分散存放于工业的各个设备中,不便于充分利用已有数据,发挥其应有的潜在价值。正所谓没有统一的数据管理,更谈不上对数据的统计、分析和挖掘。
部分企业在信息化的过程中已经意识到这点,逐步推进采用数据库同步、主从同步、第三方软件等模式来解决工业数据离散式存放的问题,但使用以上解决方案均存在以下问题:
①终端设备较多,如每个终端都安装数据同步软件,故障点大量增加;
②根据终端设备的一致性,存储在集中数据库中需创建多个与之对应的数据库表,在集中数据库中也是分表存储,难以实现集中存储管理的要求;
③如果终端设备的数据库表不断变化,相应第三方软件也需不断配置,增加了管理的复杂度;
④由于终端设备数据库较多,采购第三方软件也是一笔不小的开支。
1.2 分库分表的思想
分库分表(sharding)[4],是指把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题。对于海量数据的数据库,如果是因为表多而数据多,这时候适合使用垂直切分,即把关系紧密(比如同一模块)的表切分出来放在一个server上。如果表本身并不多,而每张表的数据又非常多,这时候适合水平切分,即把表的数据按某种规则(比如按ID散列)切分到多个数据库(server)上。
分库分表原是为解决大数据集中存放在一处,致使硬件、网络、数据库负载过高等问题而产生。针对工业数据的特点,分库分表欲将原有已分散的数据集中管理,通过逆向思维[5]解决工业数据现存的问题,利用云存储的分布式数据管理思维,从逻辑上将离散式的数据进行统一管理。
2 基于现有系统引入分库分表管理模块
随着信息化程度的提高,企业会出现大量的信息系统,在业务上、设备上、资源上……进行相关管理,而往往与工业设备、业务相关的系统又不止一个,如果能基于现有系统,将离散式的工业设备数据管理起来,进行设备、设备数据的整合,即可达成即可切实提高设备使用率,深度挖掘现有数据的隐含信息,又能实现将多条数据进行对比,从逻辑上将分布式的离散数据统一管理起来。
现有管理系统有90%以上都采用java编程语言,针对此现状,以下将基于java语言的流行框架SpringMVC[5]提出一套工业数据集中管理解决方案。根据分库数据库的结构和java语言的程序特点,解决方案过程如图1所示.
具体步骤如下:
①终端设备并入网络
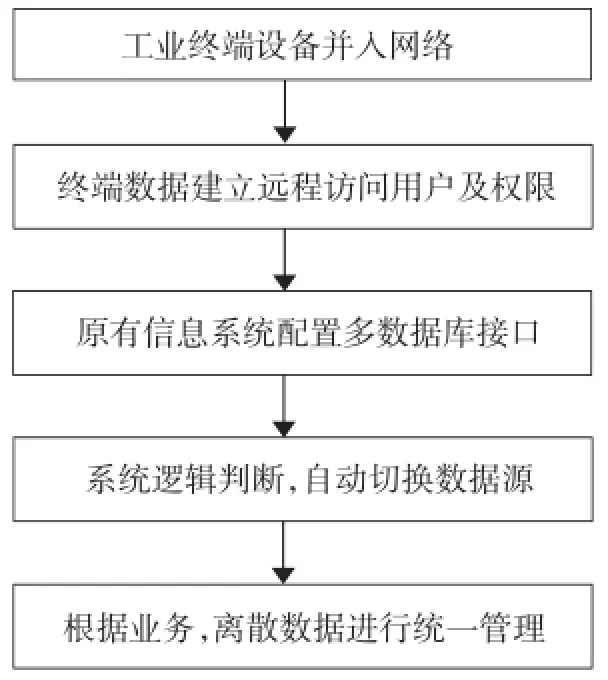
图1 离散数据库采用分库技术过程
终端设备基于TCP/IP技术[6](安装了TCP/IP协议),网线接口需遵循RJ45,RJ45是10BASE-T网络标准中的接口形式,已被广泛使用,其内部有8个线槽,线槽含义遵循EIA/TIA 568国际标准[7],在10BASE-T网络中1、2线为发送线,3、6线为接收线。在双机进行连接的时候,其中的1、3、2、6线需要对调。采用A类或B类双绞线并入企业局域网或互联网,在网卡中配置相应的网络IP,以使现有管理系统与终端设备进行通信。
②终端设备数据库准备
在数据库中,往往会配置多个用户,每个用户不同的相应权限来对数据库系统进行管理。现有的管理系统若需访问终端数据库,将离散的数据在逻辑上进行统一管理,终端设备数据库则需要做以下准备工作:创建数据库用户,为其设置密码;开放其用户对于数据库远程访问权限,以便于数据的访问管理;设置TCP/IP端口与系统远程访问系统设置相对应。
③管理系统程序中数据库接口配置
由于企业中当前使用的管理系统,大部分采用java语言的编程方式,而web系统中框架技术[8]有很多,如Struts、Spring、Hibernate、Mybatis……,下面将根据较为流行的框架技术SpringMVC,在管理系统中配置数据源,设置对应的数据库访问驱动、用户名、密码、数据库IP地址,及数据传递的编码方式,而真正的数据库访问的配置参数写入相对应的ini文件中,使之能访问工业设备中离散的数据库。SpringMVC架构配置多数据源文件如图2所示。
④根据逻辑判断自动切换至相应数据库
每个设备的数据库存放数据时,根据业务需求,存储数据的表名是根据设备编号而命名或没有具体区分的标示,这样在查询数据的时候系统会根据逻辑判断,自动切换相应的数据库中查询数据,进行数据管理。相关思路类似于腾讯、阿里企业系统中对大数据“取模”[9]的思维方式:首先需要根据输入信息进行分类判断,判断其应该切换链接至相应的数据库,然后再去做相应业务处理,而后需关闭数据库链接,释放资源,切换至默认数据源,以防止干扰原有系统的正常使用。切换数据源的代码如图3所示。

图2 SpringMVC架构多数据源配置文件
⑤工业数据的管理
根据相关的业务需求,管理相应设备数据库,在系统中以多种形式进行数据显示,自动获取数据形式,并可根据数据进行相关数据分析、挖掘、导出报表等……可以根据查询命令进行数据的简单查询,例如(以SQL Server数据库为例)
查询数据库所有表的表名:

查询表名查询表结构:

以上是查询数据库表名和根据表名查询表结构的sql语句,可根据业务需求进行数据的统计分析,深度挖掘等。

图3 切换数据源代码
3 使用后的效果验证
原有工业设备的数据管理为离散式数据管理,设备数据之间无法进行比较、统计分析等横向操作,孤立存放使得数据很难进行有效的数据管理,设备数据不仅仅形成一个个数据孤岛,无法发挥其潜在作用,还会导致设备额外使用,增加设备损耗,给企业带来巨大的成本。本方法利用互联网技术,将互联网技术与工业设备相融合,不仅符合国家大力倡导的“中国制造2025”和“工业4.0”概念,也确实解决了工业设备中数据孤立存储,无法进行统一管理的问题,极大程度上减少了不必要的设备使用,提高设备使用率,减少设备损耗。
使用分库数据技术后,离散、孤立的设备数据通过网络得到统一管理。而且,可以根据不同的数据库,在配置文件中配置不同的数据库驱动,以实现不同设备、不同数据库之间的数据统一管理,不仅可以根据查询条件查询不同数据库中的数据,导出查询数据的报表等一些简单数据操作,而且可以对离散数据进行统计分析以及对数据的深度挖掘。由于管理系统为web架构,使用人员可以在任意联网计算机中对设备中的数据进行管理,不仅提高工作效率,结束了原始人工导出数据,移动存储设备进行数据迁移的工作模式,也极大降低了设备感染病毒的概率。
下面为统计设备8类使用状态分析结果,如图4所示。

图4 设备8类使用状态的分析结果
4 结语
本系统基于现有管理系统,将独立的工业设备通过客制化的方法,利用大型系统中分库的思想,逆向地对离散的设备数据进行统一管理,以达到就多次设备数据进行统计分析、数据挖掘。将设备数据管理挂载在现有的系统中,可以利用当前系统的安全机制与管理模式,减小系统开发周期,提高系统的稳定性与可靠性。开发中利用数据源自动切换,设置默认数据源,数据源切换处理数据后,自动恢复到默认数据源,避免影响原有系统。该技术将工业技术与互联网技术巧妙融合在一起,解决了工业设备数据离散存放,无法集中管理的问题,使离散的数据进行统一管理,这不仅提高了工作效率,也大大降低设备的重复使用及损耗。
[1]王英杰,温沁润,刘秀海.摄影评审系统中数据库的分库设计[J].统计与管理,2013(2):166-167.
[2]孙晓东.基于物联网的离散制造车间制造数据管理关键技术的研究[D].南京:南京航空航天大学,2012.
[3]胡珊珊.面向云存储的非结构化数据存储研究与应用[D].广州:广东工业大学,2014.
[4]李海磊.垂直划分分布数据的多维关联规则挖掘研究[D].秦皇岛:燕山大学,2013.
[5]刘汉民.论逆向思维[J].重庆工学院学报,2005(9):96-100.
[6]王晓华.基于TCP/IP和数据库技术的远程监控系统的研究[D].杭州:浙江工业大学,2007.
[7]冯驰,赵旦峰,张宇,刘昕.综合布线标准EIA/TIA-568A [J].黑龙江电子技术,1996(4):29-31.
[8]王凤岭.基于MVC的主流Web框架技术研究[J].南宁职业技术学院学报,2011(3):94-97.
[9]许鑫,李顺东.大整数取模的快速运算[J].计算机工程与应用,2014(22):136-140.
The Application Based on the Java Sharding Technology Patent in Industrial Discrete Data
Zhang Jie
(CAMA〔LuoYang〕Electromechanic Co.LTD,Luoyang Henan 471000)
The data bank technology patent is the centralized storage management, data discrete storage, big data, alleviating database load and improve the response speed of the system, meet the system requirements. One of the large-scale industrial production data are stored in each discrete IPC, the little in the centralized management of industrial data and data bank application. Through the technology of reverse thinking, the original discrete data, central - ized management logic, and through the relevant logic, data management, analysis, operation, to achieve a unified discrete data management.Discusses the application status of the industrial data and the data bank technology, on the way to realize the unified management of the industry the data and algorithm, and the application prospect of the technology in the industrial field.
datasharding;industrial data;discretetype;DDBS;cloudstorage
TP311.13
A
1003-5168(2016)06-0081-04
2016-5-24
张捷(1988-),男,本科,工程师,研究方向:信息技术在工业领域中的应用。
