基于用户聚类的微博话题推荐算法
2016-10-12张世尧张顺香
张世尧,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
基于用户聚类的微博话题推荐算法
张世尧,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
微博话题推荐算法的作用是当用户面临微博信息过载时,结合用户的基本信息,帮助用户找到对自己有价值的微博话题。微博推荐算法的核心任务是以用户信息为基础,分析用户的偏好,并推荐给其他信息相似的用户。本文提出的基于用户聚类的微博推荐算法包括三个层次,即用户微博话题特征提取、用户聚类、微博话题推荐。实验表明该系统的准确率达到50.2%,可准确地为用户进行微博话题推荐,并提高了用户浏览微博的效率。
微博话题;用户聚类;推荐
推荐系统的作用是当用户面临信息过载时,结合用户的基本信息,帮助用户找到对自己有价值的信息[1]。近年来,微博飞速发展,据最新统计,仅新浪微博的注册用户人数就已达到5亿,日活跃用户达到4 700万,据文献[2]统计,118万用户的平均关注数为469个,这些用户每天会产生大量的微博信息。这些微博信息是否每一条都对用户有价值?用户对于微博构成的数据集是否能有效的判别[2]?也就是说,用户面临着非常严重的信息过载。
为解决这一问题,本文提出了基于用户聚类的微博话题推荐算法。推荐算法的核心任务是以用户信息为基础,分析用户的偏好话题,并推荐给其他信息相似的用户。目的是帮助用户在浩如烟海的微博话题中快速、有效的找出自己感兴趣的微博话题。
本文提出的基于用户聚类的微博话题推荐算法包括三个层次:
(ⅰ) 用户话题特征提取,将用户过往微博进行分词,特征词提取,获取用户兴趣话题特征矩阵。
(ⅱ)结合(ⅰ)利用凝聚层次聚类算法对用户进行聚类。
(ⅲ)结合(ⅱ),对聚类簇中的每个用户,推荐给同一聚类簇内,当前用户关注而其他用户没有关注的话题,具有一定的准确性。
1 相关工作
关于微博话题推荐算法,国内外已有大量学者对其进行研究,大多都是根据用户的行为(评论,过往微博,关注)建立用户模型,并根据模型通过聚类或者计算相似度等方法,对用户进行微博推荐。文献[3]利用概率主题模型挖掘用户潜在的主题信息,根据用户之间的转发、评论情况,计算用户的互动系数,过滤信息熵低的微博,通过微博的评分公式,给每条待推荐微博打分,并将分数高的微博推荐给用户,从而实现微博的推荐功能。文献[4]通过用户过往微博为用户建立兴趣模型,在此基础上聚类,并将同一类中与用户过往微博相似度高的微博推荐给用户。文献[5]利用自然语言处理工具建立一个以命名实体和核心项的形式自动提取用户兴趣的系统,从而根据用户兴趣推荐给有相似兴趣的朋友。文献[6]通过深入研究用户的互联网行为,如转发,评论,并通过研究用户行为和用户兴趣,根据电容放电原理,提出了一种基于兴趣流的动态模型。文献[7]提出了Twittomender系统,根据用户及其粉丝和好友发布的tweet、用户在twitter上的关系网络,对用户进行建模,同时利用Lucene的TF-IDF衡量关键词的权重。文献[8]提出了一种结合用户评论的内容推荐算法,通过LDA对用户评论内容特征项进行降维,计算产品之间的相似度,然后结合用户的打分权重得到综合相似度,最后为其推荐可能感兴趣的产品。文献[9]提出了一种预测算法来推算概率模型的参数,并且使用MapReduce来处理大规模数据。文献[10]提出一种基于两阶段聚类的推荐算法GCCR,将图摘要方法和基于内容相似度的算法结合,实现基于用户兴趣的主题推荐。
2 用户话题特征提取
2.1基本概念
定义1用户话题特征向量(Topic Feature Vector)。
用户微博中有很多出现频次较高,但是对话题提取无意义的词,比如“的”,“很”,如果都记为话题会造成很大的冗余信息,同时使推荐算法难以准确工作。本文依照文献[11-12]对用户过往微博分词,特征词提取,去除多余词,并根据词的权重,找出每一个用户的兴趣的话题列表,这些话题列表可以用向量表示,本文把这种向量记为用户话题特征向量TFV,TFV描述如下:
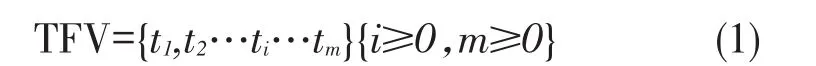
其中,ti为话题关注表示符号,当用户关注话题时,ti的值为1,如果不关注,则值为0,m为所有用户关注话题的总个数。
定义2用户话题特征矩阵(Topic Feature Matrix)。
根据定义1,我们得到了用户话题特征向量TFV,假设用户的数量为n,则n个话题特征向量就构成了一个用户话题特征向量矩阵TFM。单个用户的话题特征向量的长度为m,则用户话题特征向量矩阵TFM的大小就为n*m,用户话题特征向量可描述为如下形式:
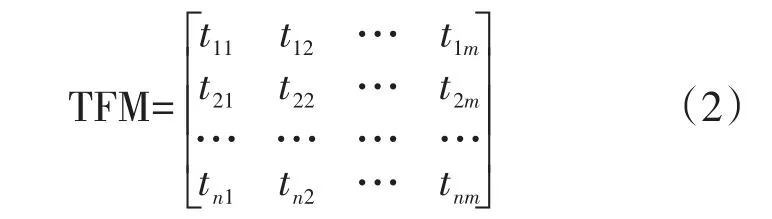
其中t在定义一里已经说明,为话题特征表示符号,n为用户数量,m为话题的总个数。表1给出了话题矩阵的一些实例。

表1 用户话题特征矩阵矩阵实例图
定义3用户微博话题集合T(Topic Grounp)。
对于所有微博用户关注的话题,我们定义一个用户话题集合T,用来保存用户关注的所有话题,用户微博话题集合T的定义描述如下:
T={tpi|i=1,…,m}(3)
tp为单个微博话题,m为所有用户关注的微博话题的总个数。
2.2用户微博话题特征数据结构
获得用户话题列表后,需要一种数据结构对用户话题列表进行保存,本文选择用链表保存单个用户的话题列表,用链表表示的好处是,因为每个用户的话题列表的长度是不固定的,用链表大大节省了所需空间,而且链表长度可以随着用户话题列表的长度变化而变化。链表的数据结构如下所示。
表头:

ID为用户的id,name为用户昵称,address为用户地址,sex用户性别,age为用户年龄,node为话题指针域。
话题结点:

user-ID为此话题的用户ID,content为内容,time为发表时间,topic-hot为话题热度,node为话题指针域。
2.3获得用户话题特征矩阵TFM
根据用户的话题链表集合,可以生成用户话题特征向量TFV和用户话题特征矩阵TFM,方面下一步在用户聚类中计算用户邻近度dist。
算法1:用户话题特征矩阵生成算法
输入:用户话题链表集合U={U1,U2,…,Uk},话题数目m,用户数目n,话题列表集合T={tp1,tp2,…,tpm}
输出:用户话题特征矩阵TFM


算法说明:
(ⅰ)步骤1新建了用户话题特征矩阵TFM;
(ⅱ)步骤3到步骤9将用户话题特征矩阵TFM初始化;
(ⅲ)步骤14找到话题t在话题列表里的位置,并将用户话题关注表示符号置1;
(ⅵ)步骤12到18对每个用户关注的话题户话题关注表示符号置1。
该算法主要的时间复杂度在于两个双重循环,第一个循环(步骤3到9)的时间复杂度为O (n*m),第二个循环(步骤12到18)的时间复杂度为 O(n*m2),所以该算法的时间复杂度为 O (n*m2)。该算法的主要用到n*m的二维矩阵存储TFM,所以算法的空间复杂度为O(n*m)。
3 用户聚类
根据上文得到的用户话题特征矩阵TFM,我们可以对话题兴趣相似的用户进行聚类,得到话题兴趣相似的用户聚类簇。同一个聚类簇内的用户关注的话题相似,从而可以为下一步对用户进行微博话题推荐做好铺垫。
凝聚层次聚类是一种自底向上的策略,首先将每个对象作为一个簇,根据邻近度和并这些簇,直至满足条件或者只剩下一个簇为止,根据邻近度选择的不同可以把凝聚层次聚类划分为单链,全链和组平均,本文使用全链计算邻近度。使用用户话题特征矩阵TFM作为聚类的输入。
两个A,B用户之间的距离dist为两个用户之间的余弦距离,
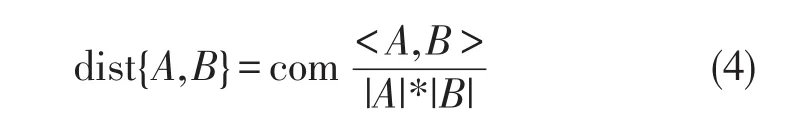
则用户聚类算法如下。
算法2:用户聚类算法
输入:用户话题特征矩阵TFM
输出:用户聚类簇集合C

9: 计算出C中每个聚类簇之间的邻近度,
则邻近度可以构成一个矩阵M
10:else
11:repeat
12:选取max(dist(Ui,Uj)),使Ui=Ui∪Uj,
则C={C1,…,Cn-1}
13:更新邻近度矩阵M
14:until达到聚类数目
15:end
算法说明:
(ⅰ)将每个用户看成是一个簇(步骤1到8);
(ⅱ )计算每对用户之间的相似度dist(A,B),计算出初始相似度矩阵;(步骤9)
(ⅲ)选取具有最大相似度的簇对max(dist(Ui,Uj)),并将Ui和Uj合并为一个新的簇类Uk=Ui∪Uj,从而构成U的一个新的簇类C={C1,…,Cn-1};
(ⅳ )更新相似矩阵;(步骤13)
(ⅴ)到聚类数目达到为止。(步骤14)
该算法使用了邻近度矩阵,假设邻近度矩阵是对称的,且有m个用户,则需要存储m2/2个邻近度,因此总的空间复杂度为O(m2)。步骤4的时间复杂度为当前簇个数的平方O(m2),步骤5同样复杂度为O(m)则总共需要O(m3)的复杂度,如果使用有序表存储聚类簇,则时间复杂度可以降为O(m2log m)
4 微博话题推荐算法
结合用户话题特征矩阵TFM,用户聚类的结果集,我们可以设计微博话题推荐算法,算法的大概思想是,推荐给同一聚类簇内,当前用户关注而其他用户没有关注的话题,具有一定的准确性。
4.1微博话题推荐算法
微博话题推荐算法的思想是,当用户A和B都同属于一个聚类簇时,推荐给用户B用户A关注,而用户B没有关注的话题。推荐算法如下:
算法3:微博话题推荐算法
输入:用户簇集合C={C1,C2,…,Cm}
输出:用户微博话题推荐
1:for用户簇c in C
2: for用户u in c
3:for话题t in u
4:if t=1
5:判断t可在当前c中的其他用户u中,如果不存在,则推荐给当前c中其他用户u。
6:endif;
7:endfor;
8: endfor
9:endfor
10:end
算法说明:
用户簇集合中的每一个用户簇(对应步骤1 到9),每一个用户簇中的用户(对应步骤2到8),每一个用户关注的话题(对应步骤3到7),用户关注值t为1时(步骤4),判断用户簇中的其他用户是否关注该话题(步骤5),对没关注该话题的同一用户簇中的用户推荐当前话题。
该假设用户簇集合中的用户簇数目为m,单个用户簇中的用户数目为n,单个用户关注的话题数目为p,则该算法需要的空间复杂度为O (m*n*p),时间复杂度也为O(m*n*p)。
5 实验分析
5.1实验结果
本文使用信息检索系统常用的准确度率(精度)来评价系统的效果。准确率计算方法为:P=|C⋂R|/|R|,其中R为系统推荐给用户的条目,C为用户感兴趣的条目。简单来说,就是用户感兴趣的条目数与总的推荐的条目数的比率[13]。
微博话题推荐算法和其他算法不同,必须要获得用户反馈才能评判算法推荐的准确度,实验分为以下几个步骤:
(ⅰ)搭建实验环境;
本次推荐算法实验的环境为dell xps 13笔记本电脑,MySql 5.0和Python 2.7,以及另外10台个人笔记本电脑用来查阅推荐结果。
(ⅱ)准备基本数据;
选取10名用户微博作为实验数据,分别用爬虫获取他们的历史微博,并分别用user表保存用户数据,weibo表保存微博历史数据。
(ⅲ)算法实际运行;
通过每名用户的历史微博,提取出用户兴趣话题,并建立用户话题特征矩阵TFM,对用户进行聚类,分别获得对10名用户推荐的话题。
(ⅳ)收集统计结果。
微博话题推荐算法经过运行,得出推荐结果,然后通过微博私信的方式由程序自动推荐给10名用户,10名用户的反馈如表2所示

表2 用户反馈表
由表2可知,用户被推荐的话题数目数量不同,被推荐话题数目和感兴趣的话题数目也不相同,但是准确率一直稳定50.2%附近,取得了不错的推荐效果。
5.2实验对比
将本文提出的推荐算法与基于协同过滤的推荐[14]、基于内容的推荐[15]进行对比,在试验中,三个推荐系统(算法)均使用相同的用户数据,得出的对比情况如表3所示。

表3 算法比较表
从表3可以看出,三种推荐系统(算法)都能实现对用户进行微博(话题)推荐,后两种推荐系统(算法)的最高准确率较高,但是平均准确率低于本文提出的推荐算法,说明本文提出的算法比较稳定,在最好和最坏的情况都能稳定的为用户推荐微博话题。
6总结
本文针对用户面临微博信息过载的问题,为了让用户能省时省力的获取到自己感兴趣的微博话题,设计了基于用户聚类的微博话题推荐算法。本文首先将用户过往微博进行分词,特征词提取,确定用户兴趣话题,建立用户话题特征矩阵,然后对用户进行聚类,接着对聚类簇内的每个用户,推荐给同一用户聚类簇内当前用户关注,而簇内其他用户没有关注的话题,最后给出微博话题推荐算法的试验效果分析,证明本文提出的算法是有效可行的。
[1] 项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2] 慕福楠.面向微博用户的推荐多样性研究[D].哈尔滨:哈尔滨工业大学,2013.
[3] 谢昊.基于主题模型的微博话题推荐算法研究[J].华东师范大学,2013.
[4] 蒋超.基于用户聚类和语义词典的微博推荐系统[D].杭州:浙江大学,2013.
[5] Piao S,Whittle J A feasibility study on extracting twitter users'interests using NLP tools for serendipitous connections[C]//Proceedings of the 3rd IEEE International Conference on Social Computing,2011:910-915.
[6] 赵钕森.基于用户行为的动态推荐系统算法研究及实现[D].成都:电子科技大学,2013.
[7] Hannon J,Bennett M,Smyth B.Recommending twitter users to follow using content and collaborative filtering approaches.[J].In NIPS*17,2010:199-206.
[8] 刘英.基于用户评论的个性化产品推荐系统[D].北京:北京邮电大学,2015.
[9] Kim Y,Twitobi S K.A recommendation system for twitter using probabilistic modeling[C]//IEEE 13th International Conference on Data Mining,2011:340-349.
[10] 陈克寒,韩盼盼,吴健.基于用户聚类的异构社交网络推荐算法[J].计算机学报,2013,36(2):349-359.
[11]Luo X F,Fang N,Hu B,et al.Semantic representation of scientific documents for the e-science Knowledge Grid[J].Concurrency and Computation-Practice&Experience,2008,20(7):839-862.
[12]Liang Z,Jing H N,Zhi A S.Algorithm design for personalization recommendation systems[J].Journal of Computer Research&Development,2002,39(8):986-991.
[13]Sakaguchi T,Akaho Y,Takagi T,et al.Recommendations in Twitter using conceptual fuzzy sets[C].IEEE,FuzzyInformationProcessingSociety(NAFIPS),2010 Annual Meeting of the North American.2010:1-6.
[14]Sebastiani F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-47.
[15]Miyahara K,Michael J P.Collaborative filtering with the simple bayesian classifier[Z],2000:679-689.
A recommendation algorithm of Micro-blog topic based on user clustering
ZHANG Shi-yao,ZHANG Shun-xiang
(School of Computer Science and Engineering,Anhui University of Science and Technology,Huainan Anhui 232001,China)
The recommendation algorithm of micro-blog topic aims to help users find valuable micro-blog topic based on the users'basic information when overload information of micro-blog has occurred.The main tasks of the micro-blog recommendation algorithm are analyzing the users'p
and recommending a special micro-blog topic to other users with similar information.This paper proposes a user clustering-based micro-blog topic recommendation algorithm which includes three levels,namely the users micro-blog topic features extraction,users clustering,and users recommendation.Experimental results show that the accuracy of the proposed system is up to 50.2%.It can accurately recommend micro-blog topic for users.Thus,the efficiency of browsing the micro-blog can be improved greatly.
Micro-blog topic;user clustering;recommendation
TP391,TP393
A
1004-4329(2016)02-074-06
10.14096/j.cnki.cn34-1069/n/1004-4329(2016)02-074-06
2016-03-10
安徽省教育厅自然科学基金重点项目(KJ2015A111);上海市信息安全综合管理技术研究重点实验室(上海交通大学)开放课题(AGK2013002)资助。
张世尧(1991-),男,硕士研究生,研究方向:信息提取与推荐系统。
