利用二次归并的Deep Web实体匹配方法
2016-09-29陈丽君

摘要:针对权重边剪枝(WEP)方法在准确率和匹配效率等方面的不足,通过引入自匹配和归并概念,提出一种基于二次归并的Deep Web实体匹配方法。首先,提取各对象的属性值,并按属性值重组对象,使具有相同属性值的对象聚集在一起,实现块的有效划分;其次,计算块内各对象间的匹配度,并据此进行剪枝、自匹配检测、归并,输出初步类簇;最后,以初步类簇为基础,利用簇内对象间传递的消息以及对象属性相似值,进一步挖掘匹配关系,触发新一轮的类簇归并与更新。实验结果表明,与WEP方法相比,所提方法通过自匹配检测,自动区分匹配关系并采取合适的匹配策略,使归并过程逐渐精化,提高了匹配准确率;通过分块、剪枝,有效缩减了匹配空间,提高了系统运行效率。
关键词:二次归并;Deep Web;实体匹配; 类簇;相似值
中图分类号:TP391; TP311
文献标志码:A
0引言
与Surface Web相比,Deep Web资源具有数量更大、质量更优、内容更精确、使用价值更高、增长迅速等特点。接口集成是访问Deep Web资源的主要途径,但由于Web的自治性和动态性,使得Web数据库的数据冗余度高,异构现象严重,给接口集成造成较大困扰。实体匹配(也称实体识别、记录匹配等)是一种在数据集合中发现同一实体不同描述的技术,可用于数据库记录的错误检测、重复检测、不一致数据发现等,以消除数据重复、数据不一致等异构现象。
与模式匹配类似,实体匹配的关键要做好两项工作:评判依据的选择和匹配方法的运用[1];同时,鉴于Deep Web的海量数据,有效的匹配空间缩减策略也非常重要。早期的实体匹配主要专注于实体对间的匹配(见文献[2]),近年来已逐渐发展为实体集间的匹配(collective entity matching)[3-6],相关技术研究应用也延伸到了知识库、全球信息库自动构建等众多领域。评判依据方面,目前主要还是选用实体对象的属性,并以自动或半自动方式迭代计算各属性的权重[7-8]。匹配方法主要涉及机器学习、图理论和启发式思想等,如徐红艳等[9]利用反向传播(Back Propagation, BP)神经网络的自主学习特性,将语义块相似度值作为输入,训练习得实体匹配模型;Liu等[10]基于马尔可夫逻辑网络推理来发现属性间内在的相似依赖关系,以此提升记录相似性判断。匹配空间缩减主要有分块和剪枝两种方法,如李亚坤等[11]通过构建属性节点表实现块的划分,再用Max-Merge算法进行聚类;Efthymiou等[12]设计了权重边剪枝方法(Weighted Edge Pruning, WEP)
,其基于MapReduce思想,多次映射重构块图以删减冗余边,再计算边权重并以平均边权重为阈值,对块图进行剪枝。另外,寇月等[13]则利用文本属性特征、语义信息、约束规则等多种信息,以逐步求精的方式进行Deep Web实体匹配。
综观现有实体匹配方法,仍存在人工干预较多、匹配效率不高等问题。本文借鉴前人研究思路并结合聚类思想与WEP方法,
提出一种利用二次归并进行Deep Web实体匹配的方法(Deep Web Entity Matching Method based on Twice-Merging, DWEMM-TM)。
提出一种利用二次归并技术进行Deep Web实体匹配的方法TMM(【deep Web entity matching based on Twice-Merging Method)。
1.2基本思想
DWEMM-TM模型借鉴聚类思想,将实体匹配过程看作类簇归并的过程,同时,综合考虑以下研究发现而提出:
1)匹配关系可以分为三种:匹配(Y)、不匹配(N)和可能匹配(P)(以下分别简称为Y匹配、N匹配和P匹配),而前两者往往可以通过一些有效且高效的方法快速判定。
2)描述现实世界中同一个实体的不同数据对象很难在所有属性上的取值都不同[11]。
3)如果将对象间相似值参照tf-idf(term frequency-inverse document frequency)思想进行计算并排序,那么匹配对象和不匹配对象往往分布于该排序的两端[8]。
4)通过对象间的消息传递机制能有效提高实体匹配的查全率[4]。
因此,从实现目标上可以将DWEMM-TM模型分成两个阶段:第一阶段,利用简单有效的方法,快速找出对象间的Y匹配和N匹配,归并Y匹配关系,删除N匹配关系,形成簇内相似值极高的小型类簇集,其目标是准确、高效;第二阶段,利用簇内对象间的消息传递以及对象间属性相似值的计算,进一步确定P匹配关系的最终结果并更新类簇集,其目标是提高系统的查全率。
1.3系统框架
DWEMM-TM模型的系统框架如图1所示,由结构转换器(Structure Converter,SC)、关系识别器(Matching Identifier,MI)和属性匹配器(Attribute Matcher,AM)三部分组成。DWEMM-TM模型的输入为按实体对象组织的对象集R(O),经结构转换器SC转换后,输出按对象属性组织的属性集R(A),由此,具有相同属性值的对象就被聚集到同一个对象列表Ai里;随后关系识别器MI通过扫描对象属性集R(A)中的每个对象列表Ai,统计计算对象间的匹配度,获得初步匹配关系,并滤除N匹配,归并Y匹配,从而产生实体类簇集R(C);属性匹配器AM则对P匹配关系进行判断,借助于类簇集R(C)内部的消息传递,以及对象属性值间的相似值,重新确立P匹配关系的最终取值,同时更新类簇集R(C),当判断完所有P匹配关系后便可获得模型的最终输出,即实体类集R(E)。
2结构转换器
在Deep Web中,一个实体往往用有限的属性,并以结构化的形式进行描述。例如,要描述一篇论文,通常会用到标题、作者、日期等属性。结合文献[11]的观察,代表相同实体的对象在属性取值上也容易趋向相同,因此,具有相同属性取值的对象,就更有可能描述着同一个实体。结构转换器的作用是把按对象组织的集合转变为按属性组织,以使具有相同属性值的对象聚合在一起,其目标是让匹配计算只在潜在的对象间进行,有效降低时间复杂度。
不难看出,结构转换器实质上是将R(O)中的对象进行分块,一个对象Oi可以被分到多个块(也就是对象列表Ai)中。同时,分块处理只需判断属性值是否相同,不涉及到属性间的模式匹配问题,大大降低了计算复杂度。
3关系识别器
关系识别器的作用是通过计算对象间相同属性值的相对共现次数获取匹配度,并依此划分匹配关系,将取值较低的N匹配关系滤除,取值较高的Y匹配关系进行初步归并,形成模型的粗略类簇集,其目标是通过简单、高效的方式快速区分匹配关系,收缩匹配空间,提高系统的运行效率。
关系识别器的处理可以分为匹配度计算、剪枝、初步归并三个过程。
3.2剪枝
如前所述,一个对象虽然具有与其他对象共现的属性值,但却有可能并不代表同一个实体,比如,一篇论文的刊出年份、出版单位可能与其他论文相同,但它们有可能并不指向同一篇论文;同时,这些对象间的匹配度往往很低,通常也都属于N匹配关系,为此,在计算完匹配度值后,用阈值θ对匹配度列表进行剪枝,以删减N匹配关系。剪枝阈值θ的值由实验最终确定为0.2。
3.3初步归并
剪枝环节处理的是N匹配关系,初步归并环节处理的则是Y匹配关系,基本思想是:对象间匹配度高的往往属于Y匹配关系;当匹配度值低于一个对象与一个已经自匹配对象的匹配度值时,匹配关系会变得不确定起来,也即匹配关系进入P匹配区域,还需要获取更多的信息来进一步分析判断。
关系识别器的输入是结构转换器的输出,即对象属性集R(A),其输出为实体类簇集R(C)={C1,C2,…,Cn},每一个类簇Ci={O1,O2,…,Om}代表着一个初步的实体类,其中包含着已匹配且指向同一个实体的对象Oi,|Ci|表示该类簇所匹配到的对象个数。
初步归并算法roughMerge通过引入自匹配概念实现Y匹配与P匹配的自动划分,同时达成与后续类簇归并环节的自动转接;其输出R(C)仅包含已经匹配的对象,其他未匹配对象将通过数据列表共享方式传递给属性匹配器作进一步判断处理。
4属性匹配器
关系识别器的输出是一个粗略的实体类集,包含着还未充分归并的类簇,需要属性匹配器的再次归并。属性匹配器主要处理P匹配关系,其通过对象各相应属性相似值的计算,以及类簇内的消息传递,进一步挖掘潜在匹配对象,聚合相同的类簇,形成最终的匹配结果R(E)输出,其目标在于提高匹配的查全率。
4.1属性权重计算
一个实体通常由多个属性描述,不同属性的辨识区分能力也不尽相同,越常见的属性往往区分能力越强,应该赋予更高的权重。为此,先统计每个属性的出现频率ti,再选取其中的最高频率tmax进行归一化处理,可得每个属性的权重:
在算法3的输入参数中,limit是一个用来判断两个比较对象是否相匹配的阈值(其值由实验经验确定),当对象间的相似值超过该阈值时,则认为匹配,并进入相应的归并环节。在算法3的返回结果中,Clusters是由多个对象构成一个类簇的类簇集,selfCluster则表示只有一个对象的类簇集(即自匹配集),两者共同组成实体集R(E)。
5实验结果与分析
采用实体匹配常用的Cora数据集[14]作为实验测试数据。Cora是一个描述论文引用的数据集,其中含有utgo-labeled、kibl-labeled、fahl-labled三个子集数据文件,共计1882条记录。每个文件记录着论文的author、title、date等信息,并已做好是否为相同论文的标注,共计有203篇论文。评价指标采用信息检索领域的查准率、查全率和F值。
5.1阈值limit对DWEMM-TM的影响
类簇归并中判断对象相似性的阈值limit对系统性能有重要影响。直觉上,阈值越高,要求越严,性能会更好。图2显示了不同阈值对DWEMM-TM性能的影响。
从图2可以看出,随着limit取值的增大,查准率逐渐上升,查全率有所下降;当limit=0.85时,两者有较好的平衡,F值最大,DWEMM-TM性能最优;当limit=1时,由于阈值过高,原本匹配的对象未能匹配,导致查全率有明显下降。
5.2DWEMM-TM性能评测
1)初步归并:初步归并的目标是快速、精准。在完成匹配度值计算以后,需要对匹配度值较小的N匹配关系进行剪枝,剪枝阈值θ的选取原则是:能加快匹配速度且又不太会降低查全率和查准率。实验最终确定θ的值为0.2,相应地,fahl、kibl、utgo三个数据子集的剪枝率(=剪掉的枝数/剪枝前的总枝数)分别为59%、54.7%和63.3%。各数据子集经初步归并后的查准率、查全率和F值如表1所示。
2)类簇归并:类簇归并的目标是提高系统的查全率。fahl、kibl、utgo三个数据子集中出现频率最高的3个属性分别是date、author和title,它们的出现频率值将作为相应子集属性权重归一化的标准;而算法3中所涉及的相似性判断阈值limit,根据对图2的分析,最终设置为0.85。各数据子集的评测结果如表2所示。
从表1、2可以看出,负责初步归并的关系识别器MI具有很高的查准率,但查全率却不够理想;其结果经运行类簇归并的属性匹配器AM处理后,查全率有较大提高,但查准率有所下降。进一步深入分析可知:1)MI的查准率并没有达到100%,这是因为测试数据集本身含有脏数据,仍存在一小部分实际为同一个实体,却被标注为不同实体的情况;2)有部分数据虽然描述着不同实体,但其相似值极高,给利用属性相似值进行匹配的AM带来明显干扰,降低了查准率;3)fahl数据子集的整体性能要低于其他两个,原因是其中的〈date〉属性出现频率较高,部分对象的年和月份分成两次出现,根据式(3)的计算会降低其他重要属性的权重值,导致部分匹配关系误判,从而影响了整体性能。
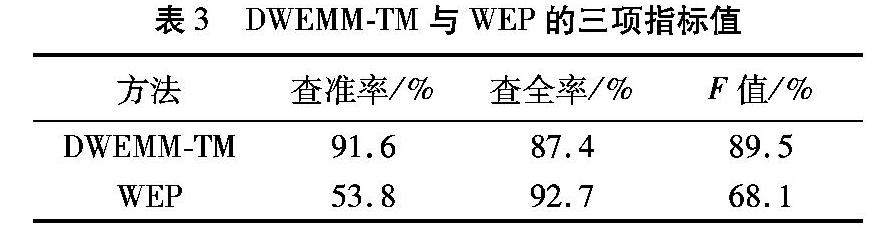
5.3DWEMM-TM与WEP方法的比较
为了验证DWEMM-TM方法的有效性,将其与文献[12]中的WEP方法进行比较,WEP方法的边权重采用JS(Jaccard Scheme)计算方式。
DWEMM-TM与WEP的查准率、查全率和F值如表3所示。从表3可以看出,DWEMM-TM模型的查全率不及WEP方法,但查准率明显高于WEP方法,从综合指标F值来看,DWEMM-TM仍然优于WEP方法。
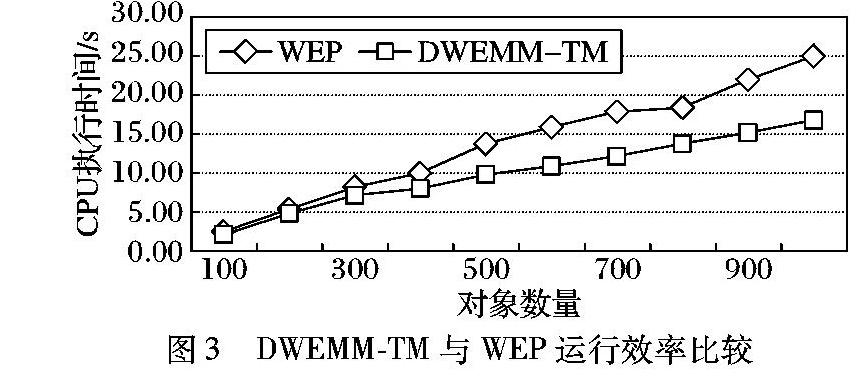
DWEMM-TM与WEP的CPU执行时间如图3所示。从图3可以发现,DWEMM-TM和WEP均随着匹配对象数量规模的扩大而呈线性增长,但DWEMM-TM模型的增长速度更加缓慢一些,其原因主要是由于DWEMM-TM模型的关系识别器MI采用了高效的删减策略与匹配方法,有效地缩减了匹配空间,大大减少执行代价相对较高的属性匹配器AM需要处理的数据量,从而获得了较好的运行效率。
6结语
Deep Web数据的迅速增长对实体匹配的效率和性能提出了更高要求。本文借鉴聚类思想,将实体匹配看作类簇归并过程,提出基于二次归并的Deep Web实体匹配方法DWEMM-TM,将不同的匹配关系分阶段交予不同的处理模块,使匹配逐渐精化,并通过引入自匹配,实现两次归并间的自动转接和不同匹配策略的自动选择。实验结果表明,DWEMM-TM方法在缩减匹配空间、降低复杂数据处理量和提高匹配精度方面有不错表现,达到了性能与效率的双重提高。
参考文献:
[1]陈丽君,林怀忠.一种用于深层网接口集成的模式匹配方法[J].计算机工程,2012,38(12):42-44. (CHEN L J, LIN H Z. Pattern matching method for Deep Web interface integration [J]. Computer Engineering, 2012, 38(12): 42-44.)
[2]KPCKE H, RAHM E. Frameworks for entity matching: a comparison [J]. Data & Knowledge Engineering, 2010, 69(2): 197-210.
[3]HAN X, SUN L, ZHAO J. Collective entity linking in Web text: a graph-based method [C]// SIGIR 11: Proceedings of the 34th Annual ACM SIGIR Conference on Research and development in Information Retrieval. New York: ACM, 2011: 765-774.
[4]RASTOGI V, DALVI N, GAROFALAKIS M. Large-scale collective entity matching [J]. Proceedings of the VLDB Endowment, 2011, 4(4): 208-218.
[5]WANG Z, LI J, WANG Z, et al. Cross-lingual knowledge linking across Wiki knowledge bases [C]// WWW 12: Proceedings of the 21st International Conference on Word Wide Web. New York: ACM, 2012: 459-468.
[6]FAN J, LU M, OOI B C, et al. A hybrid machine-crowdsourcing system for matching Web tables [C]// Proceedings of the 2014 IEEE 30th International Conference on Data engineering. Washington, DC: IEEE Computer Society, 2014: 976-987.
[7]崔晓军,肖红宇,丁立新.基于距离的自适应Web数据库记录匹配方法[J].武汉大学学报(理学版),2012,58(1):89-94. (CUI X J, XIAO H Y, DING L X. Distance-based adaptive record matching for Web database [J]. Journal of Wuhan University (Science Edition), 2012, 58(1): 89-94.)
[8]LIU W, MENG X. A holistic solution for duplicate entity identification in deep Web data integration [C]// SKG 10: Proceedings of the 2010 Sixth International Conference on Semantics, Knowledge and Grids. Washington, DC: IEEE Computer Society, 2010: 267-274.
[9]徐红艳,党晓婉,冯勇,等.基于BP神经网络的Deep Web实体识别方法[J].计算机应用,2013,33(3):776-779. (XU H Y, DANG X W, FENG Y, et al. Method of Deep Web entities identification based on BP network [J]. Journal of Computer Applications, 2013, 33(3): 776-779.)
[10]LIU W, MENG X, YANG J, et al. Duplicate identification in Deep Web data integration [C]// WAIM 10: Proceedings of the 11th International Conference on Web-age Information Management, LNCS 6184. Berlin: Springer-Verlag, 2010: 5-17.
[11]李亚坤,王宏志,高宏,等.基于实体描述属性技术的XML重复对象检测方法[J].计算机学报,2011,34(11):2131-2141. (LI Y K, WANG H Z, GAO H, et al. Efficient entity resolution on XML data based on entity-describe-attribute [J]. Chinese Journal of Computers, 2011, 34(11): 2131-2141.)
[12]EFTHYMIOU V, PAPADAKIS G A, PAPASTEFANATOS G, et al. Parallel meta-blocking: realizing scalable entity resolution over large, heterogeneous data [C]// Proceedings of the IEEE 2015 4th International Conference on Big Data. Piscataway, NJ: IEEE, 2015: 411-420.
[13]寇月,申德荣,李冬,等.一种基于语义及统计分析的Deep Web实体识别机制[J].软件学报,2008,19(2):194-208. (KOU Y, SHEN D R, LI D, et al. A Deep Web entity identification mechanism based on semantics and statistical analysis [J]. Journal of Software, 2008, 19(2): 194-208.)
[14]MCCALLUM A. Cora citation matching [EB/OL]. (2004-02-09) [2015-08-22]. http://www.cs.umass.edu/~mccallum/data/cora-refs.tar.gz.
