基于概率主题模型的景点知识挖掘及其可视化
2016-09-29徐洁范玉顺白冰
徐洁 范玉顺 白冰

摘要:针对旅游文本噪声多、景点多且展示不直观的问题,提出一种基于概率主题模型的景点主题模型。模型假设同一篇文档涉及多个具有相关关系的景点,引入“全局景点”过滤噪声语义,并利用Gibbs采样算法估计最大似然函数的参数,获取目的地景点的主题分布。实验通过对景点主题特征进行聚类,评估聚类效果从而间接评价模型训练效果,并定性分析“全局景点”对模型的作用。实验结果表明,该模型对旅游文本的建模效果优于基准算法TF-IDF与隐含狄利克雷分布(LDA),且“全局景点”的引入对建模效果有明显的改善作用。最后通过景点关联图的方式对实验结果进行可视化展示。
关键词:概率主题模型;旅游文本;噪声;Gibbs采样;可视化
中图分类号:TP391
文献标志码:A
0引言
Web 2.0技术及在线旅游代理(Online Travel Agent, OTA)的飞速发展导致旅游数据爆炸性增长。如何有效地从海量旅游数据中挖掘出有用的信息并以直观方式进行展示成为当前的迫切需求。
近年来,对旅游数据的挖掘工作多集中于对旅游照片及相应元数据、标签的研究,如文献[1-2]等利用Flickr网站用户上传的海量旅游照片及标签信息对景点进行聚类分析;文献[3]从Panoramio[4]网站采集照片聚成地标,并为每个地标找到最具代表性的照片与标签等。随着文本数据挖掘的快速发展,旅游文本数据相关的研究工作方兴未艾,相关研究工作通常可分为两类,即词频分析法和主题挖掘法。词频分析法利用词频统计结果进行文本分析,如文献[5]采用词频分析法刻画目的地旅游感知形象,文献[6]利用内容分析法(Content Analysis, CA)获取目的地语义网络分析图等。该类方法将单词视为单纯的文本符号,无法识别其中的语义信息。主题挖掘法采用或扩展隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)[7],利用潜在主题识别语义信息,从而提高文本数据挖掘的效果,如文献[8-9]提出一种地点主题(Location-Topic, LT)模型用于挖掘目的地的主题分布信息,以文本标签形式生成目的地概述。然而旅游目的地由景点组成,目的地特征由景点的类型与特征构成,同一文本可能涉及不同景点,这些景点间具有地理位置、主题等关联关系(如图1方框标注),上述方法对地点划分粒度较大且没有考虑景点关联关系。另外,旅游文本中常包含时间、门票、电话等与景点主题特征相关性不大的信息,即“噪声语义”(如图1椭圆标注),多数主题挖掘方法没有考虑噪声语义消除问题,LT模型虽可利用“全局主题”过滤噪声语义,但模型复杂度较高。为充分利用景点间的关联关系,有效消除噪声语义,本文提出一种简单的基于概率主题模型的景点主题模型(Scenic spots-Topic Model with Global Scenic spot,GS-STM)以无监督地从旅游文本中挖掘景点主题分布信息,并以景点关联图的形式展示旅游目的地的景点类型与主题特征。
1相关工作
1.1概率主题模型
概率主题模型是针对文本中隐含主题的一种建模方法。由于不需要对文档进行人工标注及可自动分析主题的特点,概率主题模型已被成功运用到多种文本挖掘问题中。它的主要思想是认为文档是若干主题的混合分布,而每个主题又是一个关于单词的概率分布。
自提出以来,概率主题模型经历了潜在语义分析(Latent Sematic Analysis, LSA)[11]、概率潜在语义分析(probabilistic Latent Sematic Analysis, pLSA)[12]、LDA、 分层狄利克雷过程(Hierarchical Dirichlet Process, HDP)[13]等阶段的发展,目前以LDA应用最为广泛。LDA是一种生成模型:对于新文档中的每个单词,通过主题的分布随机得到文档的某个主题,然后通过该主题中单词的分布随机得到一个单词。
如图2所示,LDA是典型的有向概率图模型[14],超参数α反映了文档集合中隐含主题间的相对强弱,超参数β刻画所有隐含主题自身的概率分布。
1.2可视化模型
可视化技术因具备直观、易理解的特点被广泛应用于各个领域,它用二维或三维图像的方式展现数据,便于发现数据的分布特征及其中蕴含的模式特征[15]。图是一种典型的数据结构,很多数据均可通过图来表达。
力导向模型(force directed model)是一种基于物理方法的可视化模型。该模型将图类比为一个虚拟的物理系统,图的各个节点看作系统中的质点,节点之间的边看作节点间的相互作用力(同时包括引力和斥力)。模型将胡克定律作为基本算法,每次迭代,节点向所受合力的方向移动,经足够的迭代后,系统达到平衡,此时系统中的能量达到最小,图的可视化显示最为美观。
力导向算法基本过程如下:
1)随机分布初始节点位置;
2)分别计算局部区域内边的引力和斥力所产生的两端节点的单位位移;
3)累加步骤2)得到的所有节点的单位位移;
4)重复步骤2)、3)直到达到理想效果。
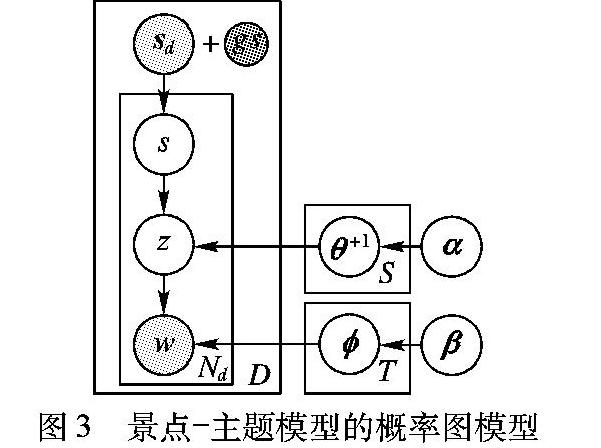
2景点主题模型
本章介绍GS-STM,并采用Gibbs采样[16]算法对模型进行求解,从而获得景点与主题、主题与单词之间的概率分布。
从图4可以看出,三种基于概率主题模型的方法——GS-STM、STM、LDA的DBI值均低于TF-IDF,说明基于概率主题模型的方法能够有效利用文档中的语义信息;不同主题数下,GS-STM、STM的DBI值均高于LDA,说明考虑文档中多个景点对提升模型建模效果是有效的;而GS-STM的DBI值总是高于STM,说明全局景点的引入能明显改善模型建模效果。
3.3.2定性分析
分别采用GS-STM、STM对旅游文本进行训练,结果显示当主题数为80时,训练效果最好。设定主题数为80,STM得到80个主题,而GS-STM方法得到68个有效主题、12个无效主题。
表2~4分别列出了GS-STM训练得到的5个“有效主题”“无效主题”及STM得到的5个主题,每个主题显示5个
最相关单词和5个最相关景点。
表2中,“有效主题”对应特定景点类型,如“运动”“购物”“电影”等主题。具有地理相关或主题相关关系的景点被列入同一主题,如Topic#38中,“鸟巢”“奥林匹克体育中心”等体育场馆被列入同一主题,同时与之地理邻近且主题相关的“奥林匹克森林公园”等也被列入同一主题。
表3中,从主题最相关单词角度看,各主题中单词多为“噪声语义”,如Topic#32中,“门票”“电话”“世界”等在多数景点介绍文档中均有出现;从主题最相关景点角度看,各主题中全局景点概率最大,且远高于其他景点,因而利用全局景点将该类主题设为“无效景点”是合理有效的。
表4中,Topic#8Ⅱ和Topic#19Ⅱ分别对应表5中的“购物”主题和“电影”主题,即Topic#4和Topic#75,对比主题相关单词构成可见,Topic#8Ⅱ和Topic#19Ⅱ中的“电话”“核心”等单词并不能准确描述并区分主题,GS-STM通过全局景点将这些词归属到“无效主题”(Topic#17,Topic#32)中,从而有效减少主题描述单词中的噪声语义,使得主题描述单词更准确有效;Topic#55Ⅱ、Topic#67Ⅱ、Topic#78Ⅱ所示主题中的单词并不能准确描述相关景点,实为“无效主题”,STM不能识别。
5结语
本文基于概率主题模型提出了一种景点主题模型,用以无监督地从海量的旅游文本中挖掘景点类型与主题特征。模型中引入“全局景点”以过滤噪声语义及无效主题。聚类实验表明,该模型可利用旅游文本中多景点关联关系更准确地捕捉景点主题特征,且“全局景点”的引入能明显改善模型训练效果。另外,本文利用复杂网络图对模型训练结果进行可视化展示,形成旅游目的地景点关联图。
由于概率主题模型发展迅速,本文后续研究拟基于HDP改进景点主题模型,自动计算主题变量个数,以期进一步提高模型效果。
参考文献:
[1]KOFLER C, CABALLERO L, MENENDEZ M, et al. Near2me: an authentic and personalized social media-based recommender for travel destinations [C]// WSM 11: Proceedings of the 2011 3rd ACM SIGMM International Workshop on Social Media. New York: ACM, 2011:47-52.
[2]CAO L, LUO J, GALLAGHER A, et al. A worldwide tourism recommendation system based on geotagged Web photos[C]// Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE, 2010: 2274-2277.
[3]JIANG K, WANG P, YU N. ContextRank: personalized tourism recommendation by exploiting context information of geotagged Web photos [C]// ICIG 11: Proceedings of the 2011 Sixth International Conference on Image and Graphics. Washington, DC: IEEE Computer Society, 2011: 931-937.
[4]Panoramio [EB/OL]. [2015-12-10]. http://www.panoramio.com/.
[5]王媛,许鑫,冯学钢,等.基于文本挖掘的古镇旅游形象感知研究——以朱家角为例[J].旅游科学,2013,27(5):86-95. (WANG Y, XU X, FENG X G, et al. Research on tourists percieved image of ancient town using Web text mining methods: a case study of Zhujiajiao [J]. Tourism Science, 2013, 27(5): 86-95.)
[6]方雅贤,宋文琴.基于网络文本分析旅游目的地形象——以大连为例[J].旅游世界·旅游发展研究,2014(4):24-31.(FANG Y X, SONG W Q. Research of tourism destination image based on Web text analysis:a case study of Dalian[J]. Journal of Tourism Development, 2014(4):24-31.)
[7]BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
[8]MA W-Y, WANG C, WANG J, et al. Mining geographic knowledge using a location aware topic model: US, US7853596[P]. 2010-12-14.
http://xueshu.baidu.com/s?wd=paperuri%3A%28f871f2037dbb26c8cbbe6bd3fe4751d5%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fwww.freepatentsonline.com%2F7853596.html&ie=utf-8&sc_us=11965384391652939608
Publication Date: 12/14/2010
Filing Date: 06/21/2007
[9]HAO Q, CAI R, WANG X-J, et al. Generating location overviews with images and tags by mining user-generated travelogues [C]// MM 09: Proceedings of the 2009 17th ACM International Conference on Multimedia.New York: ACM, 2009: 801-804.
[10]HAO Q, CAI R, WANG C, et al. Equip tourists with knowledge mined from travelogues [C]// WWW 10: Proceedings of the 2010 International Conference on World Wide Web. New York: ACM, 2010:401-410.
[11]LANDAUER T K, DUMAIS S T. A solution to Platos problem: the latent semantic analysis theory of acquisition, induction, and representation of knowledge [J]. Psychological Review, 1997, 104(2): 211-240.
[12]HOFMANN T. Probabilistic latent semantic analysis [C]// UAI 99: Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 1999: 289-296.
[13]TEH Y W, JORDAN M I, BEAL M J, et al. Hierarchical Dirichlet processes [J]. Journal of the American Statistical Association, 2006, 101(476):1566-1581.
[14]KOLLER D, FRIEDMAN N. Probabilistic Graphical Models: Principles and Techniques — Adaptive Computation and Machine Learning[M]. Cambridge, MA: MIT Press, 2011: 45-93.
[15]周宁,吴佳鑫,张少龙.基于图的Web信息可视化探析[J].情报学报,2008,27(5):714-720. (ZHOU N, WU J X, ZHANG S L. Research on graph based Web information visualization [J]. Journal of the China Society for Scientific and Technical Information, 2008, 27(5): 714-720.)
[16]CASELLA G, GEORGE E I. Explaining the Gibbs sampler [J]. American Statistician, 1992, 46(3): 167-174.
[17]百度旅游[EB/OL]. [2015-11-10]. http://lvyou.baidu.com/. (Baidu Travel[EB/OL]. [2015-11-10]. http://lvyou.baidu.com/.)
[18]WU H C, LUK R W P, WONG K F, et al. Interpreting TF-IDF term weights as making relevance decisions [J]. ACM Transactions on Information Systems, 2008, 26(3): Article No. 13.
[19]周志华.机器学习[M].北京.清华大学出版社,2016:198-199. (ZHOU Z H. Machine Learning [M]. Beijing: Tsinghua University Press, 2016: 198-199)
[20]ROSEN-ZVI M, GRIFFITHS T, STEYVERS M, et al. The author-topic model for authors and documents [C]// UAI 04: Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. Arlington, Virginia, US: AUAI Press, 2010: 487-494.
[21]文益民,史一帆,蔡国永,等.个性化旅游推荐研究综述[J].计算机科学,2014.(WEN Y M, SHI Y F, CAI G Y, et al. A survey of personalized travel recommendation[J]. Computer Science, 2014)
