基于多图学习的情感图像检索研究
2016-09-27段晓东王存睿李泽东
逯 波,段晓东,王存睿,2,李泽东,2
(1.大连民族大学 计算机科学与工程学院,辽宁 大连 116605;2.东北大学 系统科学研究所,沈阳 110819)
基于多图学习的情感图像检索研究
逯波1,段晓东1,王存睿1,2,李泽东1,2
(1.大连民族大学 计算机科学与工程学院,辽宁 大连 116605;2.东北大学 系统科学研究所,沈阳 110819)
构建了一个统一的多图学习框架,来验证在不同类别情感图像中,使用不同级别特征在情感图像检索上的性能表现。首先,提取每个图像在不同层级上的共有特征,其中,从元素级别提取的一般特征作为底层特征;可解释的属性特征作为中层特征;而情感图像的语义感念描述作为高层特征。其次,为每种类型的特征构建一个图模型来验证情感图像检索的性能。最后,将多个图模型合并在一个规范化的框架内来学习每个图模型的优化权重。通过在5个不同数据集上得到的实验结果验证了所提方法的有效性。
情感图像检索;图像情感;多图学习
随着社交网络的快速发展,人们倾向于通过在线网络上传文本和图像来表达和分享他们的情感和意见。因此,在线网络上的具有情感语义的图像和文本数据量呈指数级增长。针对情感图像进行有效地分析和检索是在线社交网络研究领域中一个重要的分支。目前,由于客观的评价机制和“情感鸿沟”等问题的存在,使得对图像中的情感进行有效分析还处于起步阶段[1]。最近几年的研究主要集中在情感图像的分类任务,即找到能够更好的区分情感的有效特征。通常,图像中的情感能够通过不同层级的特征进行表达,例如,具有抽象含义的情感图像可以通过可视化底层特征来表达;具有具体含义的情感图像可以通过高层语义特征来表达[2]。
本文的研究内容主要关注于情感图像检索以及利用不同级别的特征来分类不同类型情感图片的性能表现。首先,从每个情感图片中提取3种不同级别的特征和2种不同的泛性特征。其次,将提取到的特征数据合并到一个统一的多图学习框架中,用来执行情感图像的检索任务。本文提出方法的主要框架如图1。
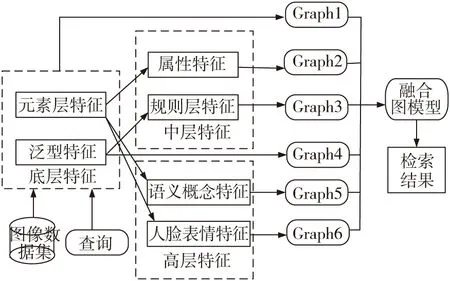
图1 情感图像检索框架
1 不同层级的情感特征提取
1.1底层特征
对情感图像进行底层特征的提取,通常会遇到可解释性特征化的问题。在底层特征提取环节,选择使用方向梯度直方图HOG 2*2(Histogram of Oriented Gradient,HOG)[3],以及几何上下文颜色直方图作为泛性特征。同时从元素层级抽取了特定特征,包括情感图像的颜色和纹理特征。其中底层颜色特征包括平均饱和度、亮度、色彩向量等;底层纹理特征包括Tamura纹理、小波纹理和基于纹理的灰度共生矩阵[4]。
1.2中层特征
情感图像的中层特征通常要比底层特征具有更多的语义化和解释性的情感含义。针对中层特征中泛性特征的提取,选择用于描述场景的5种不同类型的属性:(1)物质属性;(2)表层属性;(3)功能可见属性;(4)空间属性;(5)对象属性。基于阶梯检测准则,共选取了102个属性,通过使用SUN数据库[5]中14 340张图像的4种泛性底层特征来训练属性分类器,最终得到一个102维的二值向量作为属性特征(即泛性特征)。
1.3高层特征
高层特征通常是包含在情感图像中的语义内容。通过合理的组织语义内容可以容易的理解图像所传达的情感表达。这里选择1 200个语义概念作为高层特征中的泛性特征,即1 200个形容词-名词对(adjective noun pairs, ANPs)。这些语义概念特征通过使用256维的颜色直方图、53维的LBP描述符为输入特征向量并训练语义概念检测器得到。同时,在情感图像中抽取8种不同的人脸表情(愤怒、轻蔑、厌恶、恐惧、高兴、悲伤、惊喜、中性)作为特殊的高层语义特征,如果图像中没有检测到人脸的出现则被标记为中性表情。从而可以得到一个8维向量,每一维向量表示在图像中与人脸表情相关联的数量。
2 多图学习框架
多图学习[6]是单一图模型学习的扩展,同时被广泛应用在类别重排序的不同领域中。多图学习框架中,针对每个构建的图模型,其顶点表示每一个情感图像,边表示情感图像之间的相似度。
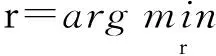
(1)
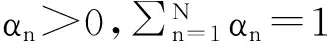
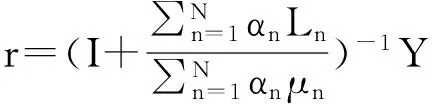
(2)

(3)
当处理完每个种类的单一特征,多图学习即可转换单一图模型学习过程,此时N=1,α=1,不需要再对参数α进行优化。可以直接将α=1代入式(2)中进行计算。由于本文的目标是根据查询图像,检索出相似的情感图像,因此,设置如果Yi=1,则图像i为查询图像,否则Yi=0。
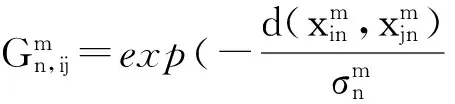
3 实验与分析
为了验证本文所提出的情感图像检索方法的有效性,我们在多个数据集上进行了实验。
3.1数据集
(1)IAPSa数据集:包括395张标准心理学领域的情感图像。
(2)ArtPhoto数据集:包括从图像共享网站上通过情感分类标签所标识的806张艺术图像。
(3)Abstract数据集:包括228张没有任何上下文内容的独立抽象图像。
以上三个数据集中的情感图像被分类成8个具体的类别:愤怒、厌恶、恐惧、伤心、娱乐、惊叹、满足、兴奋。
(4)GAPED数据集:包含了520张消极图像、121张积极图像和89张中性图像。
(5)Tweet数据集:包含了从twitter网站上根据21个不同的类别标签获取的470张积极图像和133张消极图像。
3.2评估准则
(1)Nearest Neighbor Rate(NNr):表示近邻分类器的准确率,即查询图像和具有相同情感描述的检索结果之间的比率。
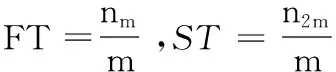
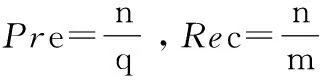
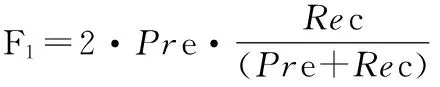
(5)Discounted Cumulative Gain(DCG):度量了返回的相关图像结果中不同位置和区域的重要性。
(6)Average Normalized modified Retrieval Rank(ANMRR):是一个基于度量的排序准则,评估了在得到的检索图像结果中,与查询图像相关的图像结果的排序序列。
上述6种不同的评估准则的度量范围为0到1,其中度量值越高表示前5种的评估准则的性能越好,度量值越低表示最后一种评估准则ANMRR的性能越好。
3.3实验结果
数据集中每个图像被选择作为查询图像,同时度量每种方法的平均性能。不同方法的查准率-查全率曲线如图2,其中‘LowGen’‘LowArt’‘MidAtt’‘MidArt’‘HighANP’和‘HighExp’分别表示基于底层泛性特征、底层特定特征、中层泛性特征、中层特定特征、高层泛性特征及高层特定特征。同时Fusion表示本文所提出的多图学习方法。其他评估准则的性能对比如图3。
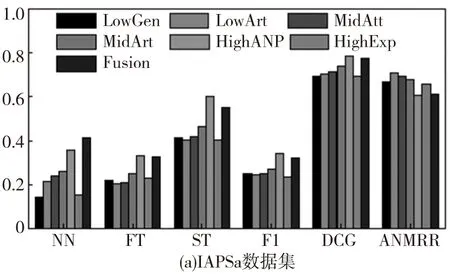
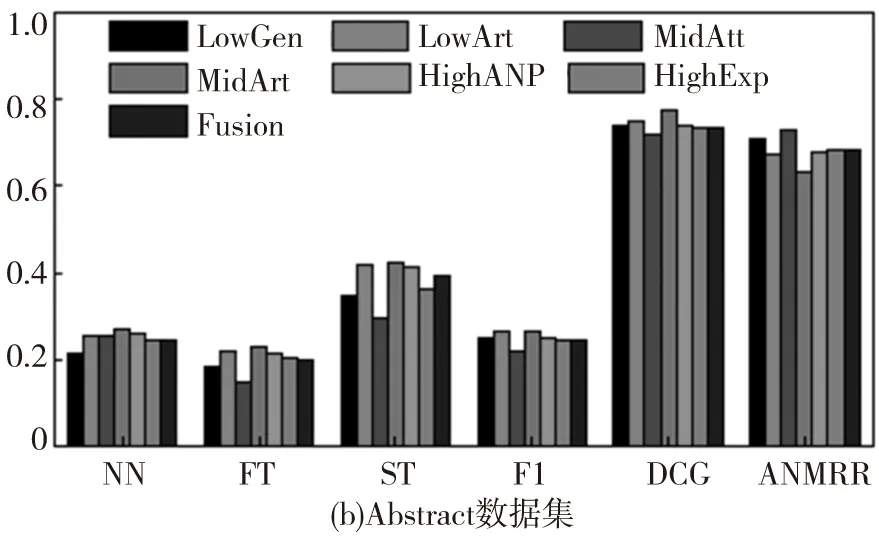
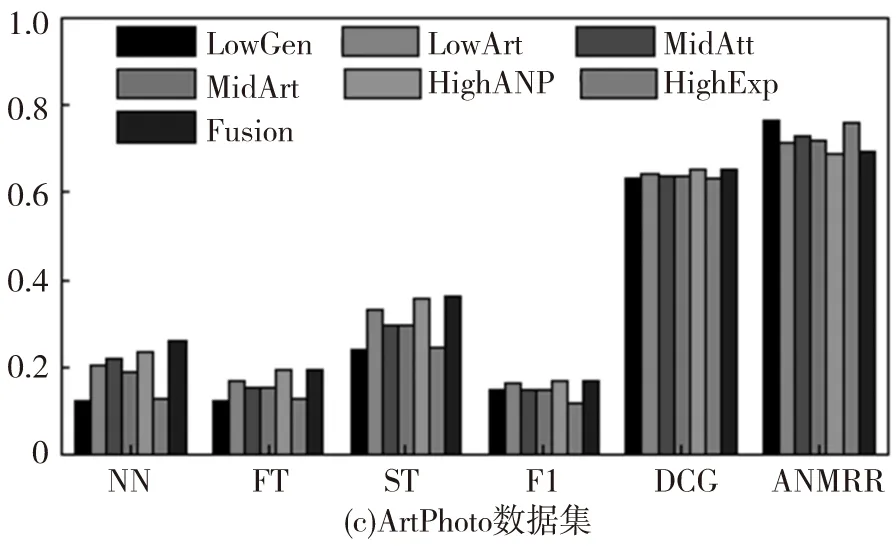
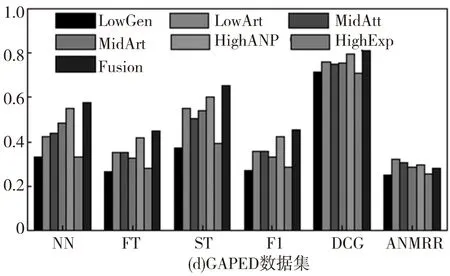

图2 基于不同数据集使用7种方法并进行评估得到的平均性能对比
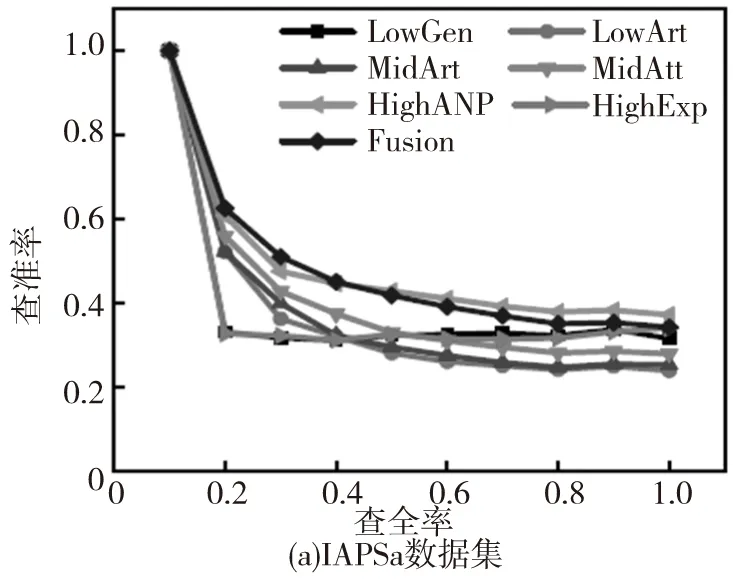
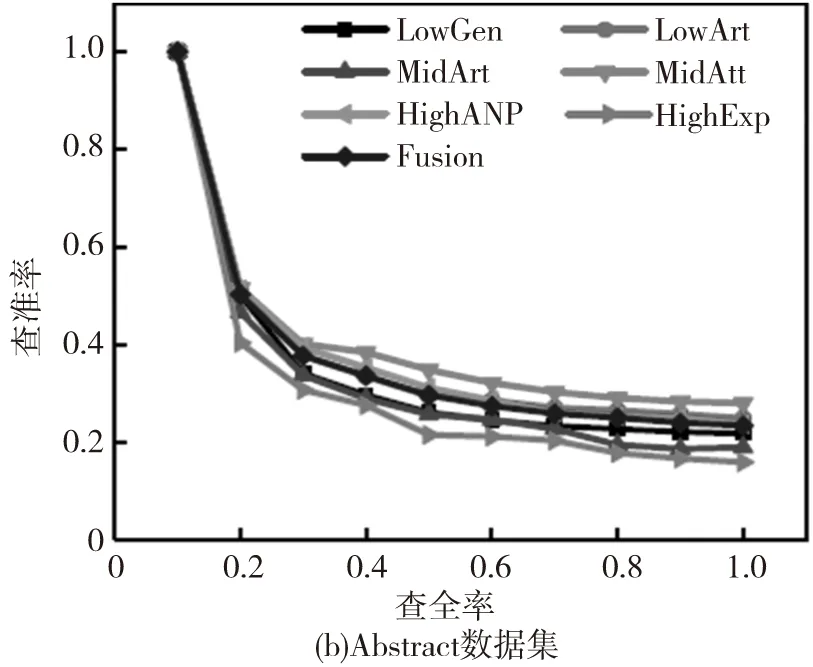
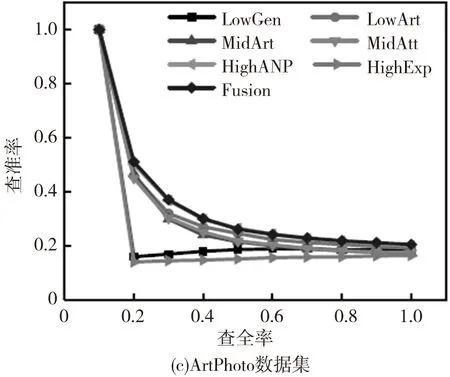
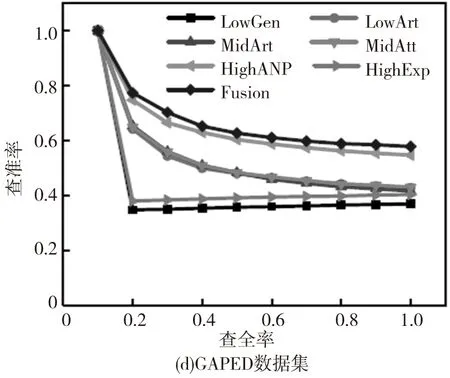
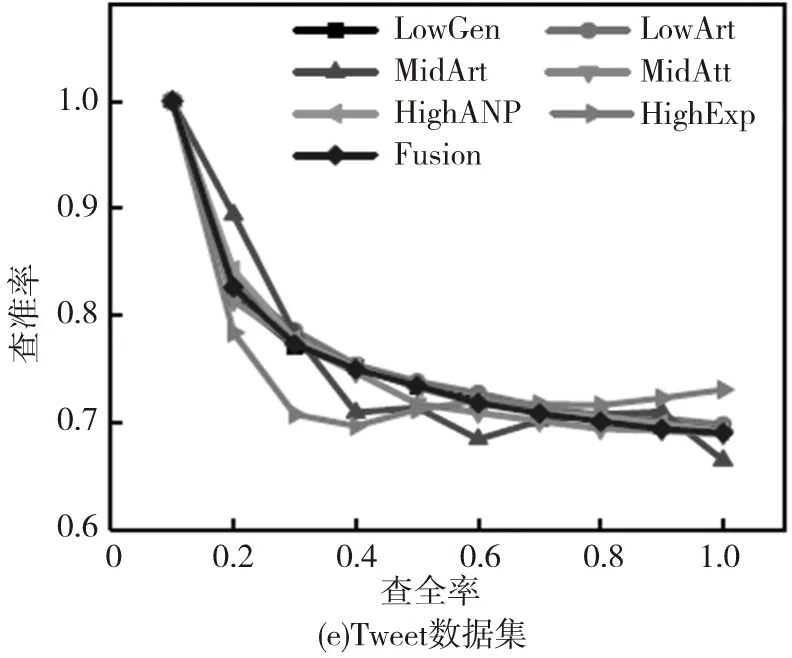
图3 基于不同数据集使用7种方法并进行评估得到的平均性能对比
根据图2和图3,可以观察到:(1)针对多种类型的情感图像使用三种层级的特征所得到的性能表现是不同的。尽管使用底层可视化特征在传统的基于内容的图像检索任务中有着很好的表现,但在情感图像检索中却不是一种好的选择;(2)通常,融合不同层级的特征所得到的结果比使用单一特征有着更好的性能表现,因为多图学习方法能够利用不同层级特征之间的互补信息;(3)对于Abstract数据集,其特征由于缺少上下文关联信息,几乎没有任何属性、概念等信息的体现,因此在使用不同的评价标准时所得到的结果是最低的;(4)在IAPSa、GAPED和Tweet数据集中的情感图像有着丰富的上下文关联信息,更容易包含高层语义概念特征,因此在不同的评估标准下的性能表现是最好的。
4 结 语
本文提出一种基于不同层级特征的多图学习框架进行情感图像检索任务,其中不同层级特征包含了底层特征、中层特征和高层语义特征,同时将不同层级的特征细化为泛性特征和特定特征两类,同时三种不同层级的特征被合并到多图学习框架中。通过在5种不同的数据集上的执行实验,所得到的结果展现了本文所提出的方法能够有效检索出与查询图像相似的情感图像结果。
[1] HANJALIC A. Extracting moods from pictures and sounds: Towards truly personalized tv[J]. IEEE Signal Processing Magazine, 2006,23(2):90-100.
[2] ZHAO S. Exploring principles-of-art features for image emotion recognition[C]//Proceedings of ACM Multimedia.New York:Publicatico, 2014.
[3] PATTERSON G,HAYS J.Sun attribute database:Discovering, annotating, and recognizing scene attributes[C]//Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE Computer Society,2012.
[4] MACHAJDIK J, HANBURY A. Affective image classification using features inspired by psychology and art theory[C]// Proceedings of ACM Multimedia.New York:Publicatico, 2010.
[5] XIAO J. Sun database: Large-scale scene recognition from abbey to zoo[C].Conference on Computer Vision and Pattern Recognition[S.l.]:IEEE Computer Society, 2010.
[6] WANG M, HUA X S, HONG R, et al. Unified video annotation via multi-graph learning[J]. IEEE TCSVT, 2009,19(5):733-746.
(责任编辑邹永红)
Affective Image Retrieval Based on Multi-graph Learning
LU Bo1, DUAN Xiao-dong1, WANG Cun-rui1,2, LI Ze-dong1,2
(1.School of Computer Science and Engineering, Dalian Minzu University, Dalian Liaoning 116605, China;2.Insitute of Systems Science, Northeastern University, Shenyang 110819, China)
In this paper, we concentrate on affective image retrieval and investigate the performance of different features on different kinds of images in a multi-graph learning framework. Firstly, we extract commonly used features of different levels for each image. Generic features and features derived from elements-of-art are extracted as low-level features. Attributes and interpretable principles-of-art based features are viewed as mid-level features, while semantic concepts described by adjective noun pairs and facial expressions are extracted as high-level features. Secondly, we construct single graph for each kind of features to test the retrieval performance. Finally, we combine the multiple graphs together into a regularization framework to learn the optimized weights of each graph to efficiently explore the complementation of different features. Extensive experiments are conducted on five datasets and the results demonstrate the effectiveness of the proposed method.
affective image retrieval; image emotion; multi-graph learning
2096-1383(2016)05-0509-04
2016-06-21;最后
2016-07-29
国家自然科学基金项目(61370146,61672132,61602085);辽宁省科技计划项目(2013405003)。
逯波(1982-),男,内蒙古赤峰人,讲师,博士,主要从事多媒体检索领域研究。
TP391
A
