基于支持向量机的克隆代码有害性评价方法
2016-09-26张凡龙苏小红李智超马培军
张凡龙 苏小红 李智超 马培军


摘 要:克隆代码是软件中彼此相似的代码片段。传统观点认为克隆代码是有害的,会降低软件质量,但最近研究发现克隆代码不一定是有害的。如何评估克隆代码的有害性是一个值得研究的问题。本文提出了一种基于支持向量机的克隆代码有害性评价方法,可以以较高的准确性和查准率评价其有害性。为验证方法有效性,本文在6个系统上进行实验,结果表明本文方法可以有效地评价克隆代码的有害性,并且所提出的静态度量和演化度量对评价克隆代码有效性具有积极意义。
关键词:克隆代码;克隆有害性评价;克隆度量;支持向量机;克隆演化
中图分类号:TP311.5 文献标识号:A文章编号:2095-2163(2015)06-
Abstract: Code clone (also known as duplicated code) has always been a popular research field in software engineering. Traditional view is that code clone is harmful, because clone can decrease the quality of software. However, considering the clone evolution, some studies find that not all the clones are harmful. So how to evaluate the clone harmfulness is a problem. This paper proposes a method which can evaluate the clone harmfulness based on support vectors machine, and makes several experiments on 6 open-source software system which were written in 3 kinds of programming languages. The results show that the proposed method has an applicability and higher accuracy. It is a meaningful attempt to evaluate the clone harmfulness.
Keywords: Code Clone; Harmfulness Evaluation; Clone Metrics; Support Vector Machine; Clone Evolution
0 引 言
克隆代码是软件系统中彼此相同或相似的代码片段。大多数克隆代码情况是通过拷贝粘贴活动产生的[1],编程语言局限、使用相似API和函数调用也会产生克隆代码。在大型软件系统中克隆代码约占代码总量的7-23%[2]。传统观点认为克隆代码是一种代码坏味,意味着软件质量较差,可能会引入缺陷,需通过重构消除克隆代码[3-5]。有研究者使用克隆代码信息进行缺陷预测,如用历史变化信息预测缺陷[6],用克隆代码上下文信息来预测缺陷[7],用信息熵的概念来定义代码变化复杂度来预测缺陷[8]。然而,通过对克隆演化模式的研究发现不是所有的克隆代码都是有害的[9-12]。不足一半的克隆代码在演化过程中发生变化,而导致额外维护开销的一致变化克隆比例则更少[13],并且只有在少数情况下不一致变化而导致缺陷[14-15]。研究者将克隆代码明确区分为有害和无害,采用启发式方法映射多版本间克隆,提出并使用克隆气味的概念帮助减少代码中的潜在威胁[16-17]。有人使用贝叶斯网络来预测克隆代码的有害性[18],可以评价克隆代码的有害性,该方法具有一定启发意义。
如何综合考虑克隆代码本身属性及其演化过程建立克隆代码有害性评价模型是亟待解决的问题。为了解决该问题,本文结合软件度量、克隆代码演化分析和机器学习方法,提取了克隆代码静态度量和演化度量,使用支持向量机建立克隆代码有害性的评价模型,快速地识别出有害的克隆代码,帮助开发人员对克隆代码进行维护。
1 克隆代码有害性分析
本文使用克隆家系和演化模式描述其演化过程。克隆群是某一个版本内彼此相似的克隆片段集合,克隆家系是软件所有的克隆群在演化过程中衍生的直系克隆的集合。一个克隆代码属于一个克隆群,一个克隆群属于一个克隆家系。演化模式(Evolution Pattern,EP)是前一版本的克隆群与下一版本的新克隆群间的关系。无变化是新克隆群中相对于原克隆群没发生任何变化;增加是新克隆群中至少增加了一个克隆代;减少是原克隆群中的至少一个克隆消失了;一致变化是原克隆群中所有的克隆发生同样的变化,而且仍然属于新克隆群;不一致变化是原克隆群中至少有一个克隆代码片段发生了不一致地变化。克隆家系如图1所示,图中描述了一个直系克隆的克隆代码、克隆群和克隆家系在连续四个版本间的演化情况。克隆组在图中第3个版本家系发生了分裂,一个新的克隆群出现了并在后续版本中继续演化下去。
本文给出一种克隆害性定义。克隆代码相关的缺陷是克隆代码有害的最直观表现,而克隆演化中的克隆群的不一致变化是导致缺陷的最重要原因,因此可利用克隆群的一致性变化来判定克隆有害性。根据是否发生一致性变化将克隆分为两类:
(1)克隆代码连同其隶属克隆群,在演化过程中从未发生过变化或一直发生不一致变化;
(2)克隆代码连同其隶属的克隆群,某一克隆片段发生变化,其它克隆片段并未改变。
对第一类克隆,在开发过程中不需要做一致性维护操作,可忽略其对程序的影响认为是无害的。对第二类克隆,每一次一致性修改操作都导致额外维护开销,而遗忘一致性修改会导致克隆群的不一致变化,会引入缺陷。从而认为第二类克隆代码是有害的。根据克隆演化情况,给出克隆代码有害性的定义:设在版本 中的克隆代码片段 ,且 隶属于克隆群 ,即 ,克隆群 从版本 至 的演化模式序列EP, ,其中 表示克隆群从第i-1版本到第i版本的演化模式,则克隆代码片段 的有害性H为:
2克隆代码有害性评价方法
2.1有害性评价模型
本文采用机器学习方法来评价克隆代码有害性,该方法将问题看成一个机器学习中的分类问题,通过算法训练已知样本来对未知的样本即克隆代码片段进行分类。基于支持向量机的有害性评价模型可分为三个步骤:预处理、数据集生成和有害性评价,具体则如图2所示。
由图2可知,模型中各部分的功能实现分析可概述如下:
(1)预处理。检测软件克隆代码,进行克隆群映射并构建克隆家系,获得克隆演化模式;
(2)数据集生成。从预处理结果中提取克隆代码的度量值,包括静态度量和演化度量,根据演化模式序列进行有害性标注,获得支持向量机的数据集。
(3)有害性评价。使用支持向量机模型在数据集上训练评价模型,并在测试集上测试模型的有效性。
2.2预处理
首先,获取连续多个版本的开源软件源代码,并使用NiCad工具对系统每一个版本都进行克隆代码检测,同时在此基础上本文使用克隆描述符描述克隆代码,包含了克隆代码的其它基本信息,再将结果保存于xml文件中后,则根据检测结果映射相邻版本的克隆代码和克隆群,生成克隆群映射文件和克隆家系文件。克隆群映射文件中包含了相邻版本的所有克隆群的映射和演化关系,包括演化模式。克隆家系文件则给出了该软件中所有克隆家系以及详细信息。
2.3 数据集生成
克隆代码片段无法作为支持向量机的输入,为向其提供数据集样本,同时也可以充分地表示克隆代码有害性信息,本文提取静态度量和演化度量两组度量值表示克隆代码。在此基础上生成表示克隆代码的向量,并根据其演化模式对其进行有害性标注获得本文的数据集。
静态度量是指仅通过单一版本的分析即可提取的克隆代码特征。可以从预处理的输出文件进行提取,预处理使用改进的克隆代码描述符表示克隆代码,该文件包含了克隆代码几乎所有的静态属性。具体来说,分别是:
(1)克隆粒度。克隆代码片段的代码行数。
(2)文件分布。研究表明分布在不同文件中的克隆代码更易于被开发人员疏忽而产生缺陷。克隆代码的文件分布情况会影响克隆代码的有害性。
(3)克隆相似度。是克隆群内克隆代码之间的相似度。
(4)上下文信息。完整包含该克隆片段的最近控制结构语句(条件分支、函数定义、循环等)。
(5)参数个数。克隆代码片段中函数包含的参数个数,体现着代码间的耦合度、函数体复杂性等。
(6)Halstead度量。从词法角度上表征克隆代码的复杂情况,共有13个Halstead度量,其实际对应内容为:不同操作符个数、不同操作数个数、所有操作符出现次数、所有操作数出现次数、程序词汇量、程序长度、计算程序长度、容量、难度、精力、程序时间、交付错误数量。
演化度量描述了克隆代码的演化属性,表示克隆的演化过程。克隆代码的演化特征从预处理中映射文件与克隆家系文件中提取,克隆群映射文件包含了相邻版本间克隆群和克隆代码的映射关系。包括:
(1)克隆寿命。寿命较长的克隆大多数都是无变化克隆,寿命较长的克隆长期存在于系统中,通常表明是无害的。克隆代码寿命可以反映克隆代码有害性。
(2)变化复杂度。为克隆代码在历史版本中经历的改变次数。本文选择两种变化复杂度:整体版本周期中该克隆代码片段经历改变次数与近1/2版本周期中该克隆代码片段经历改变次数。前者是历史整体变化次数在调整参数阶段。
度量值提取完成后,即获得了克隆代码有害性评价的数据集。支持向量机是有监督学习算法,需对数据集进行有害性标注,需通过人工行为将样本划分为有害或者无害,获得最后数据集。有害性的标注是依据有害性定义进行标注,根据克隆家系文件中演化模式人工标记所有的克隆代码是否有害,获得数据集。
2.4有害性评价
使用支持向量机在数据集训练评价模型,并进行有害性评价给出克隆代码有害性结果。将数据集划分为训练集和测试集:将软件系统中前4/5个周期版本的克隆代码用作训练集,后1/5个周期版本作测试集。使用SVM模型对其进行训练,经过交叉验证、调整参数等过程建立基于SVM的克隆代码有害性评价模型,为了对SVM模型的性能进行比较,同时加入了逻辑回归模型。
3 实验结果与结论分析
3.1实验设置
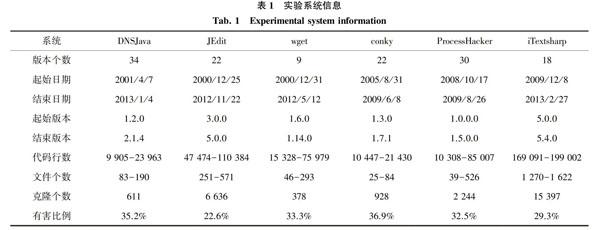
本文使用六个开源软件作为实验系统,系统信息如表1所示。DNSJava是Java语言实现的DNS协议,jEdit是Java语言实现的面向软件开发的文本编译器,wget是C语言实现的命令行下载工具,conky是C语言实现的用于X视窗系统的系统监视器,ProcessHacker是C#实现的windows系统进程管理程序,itextsharp是C#实现的用来生成PDF文档库。
本文使用台湾大学林智仁教授开发的支持向量机工具包LibSVM 3.14,核函数选择高斯核函数,在训练时调整惩罚因子 和高斯核函数的均方差 ,在训练集上执行10-交叉验证。分类器的分类情况可以用混合矩阵表示(如表2):实际正例P,实际反例N,实际正例数 ,实际反例数 ,实例总数 。根据混合矩阵,本文使用查准率、查全率、F值作为评价本文方法的指标。查准率为 。查全率为 。F值为 ,是查准率和查全率的综合指标,越高说明效果越好。
3.2实验结果
实验结果如表3所示。表3第6列是本文使用支持向量机的有害性评价结果。从表中可以看出,本文方法具有较高的查准率和查全率。全部6个系统的查准率都比较高,其中DNSJava、wget以及conky实验的查准率超过90%,JEdit和Proc超过了81%,查准率达到了较高的性能。同时,6个系统查全率也具有较好的结果,其中DNSJava最高达到93.75%,wget次之则达85%。
表3的第6和7列是支持向量机和逻辑回归方法的对比实验,结果表明支持向量机实验结果明显优于逻辑回归的实验结果。除Proc的查准率之外,支持向量机在6个系统上的查准率、查全率和F值均高于逻辑回归模型。表3的第3~6列是特征组对比实验,结果表明全部特征结果明显优于特征组合结果。首先是无内容组的对比。所有查全率和查全率值均低于全部特征组,表明内容组的度量值有积极作用。然后是无内容组的对比。除conky在查全率高于全部特征之外,6个系统的无容量组的查全率和查全率值均低于全部特征组,同样也表明内容组的度量值有积极作用。最后是无演化组的对比。JEdit、conky和iTextsharp无演化组的查全率和查全率值均低于全部特征组,也可以说明同样问题;DNSJava的查全率相近,但查准率却远低于全部组;wget和Proc情况类似,查准率稍微高于全部特征组,但查全率却远低于全部特征组;这表明演化度量同样具有积极的影响。
实验的F值如图3所示。从图中可以看出,各个系统的全部属性组的F值最高,说明本文提出的各种度量对有害性评价都有积极的影响。而无演化组F值最低,说明演化度量对有害性评价结果的影响最大。综上,本文的度量值对有害性评价都具有积极影响,演化组作用尤为突出,容量组和内容组作用次之。
4 结束语
本文提出了基于支持向量机的克隆代码有害行性评价方法,在6个软件上进行了实验表明该方法可以以较高的准确率评价克隆代码的有害性。提出一种基于演化的有害性评价标准:克隆代码在生命周期内发生过不一致性变化即是有害的。经实验验证该评价标准具有一定的可信性,可以指导克隆代码有害性评价。特征组对比试验中其实际结果表明本文所提出克隆代码度量可以有效地评价克隆代码的有害性,所提取的度量值可以表示克隆代码信息。考察F值实验发现,演化度量在评价克隆代码有害性方面的作用尤为突出,说明了克隆代码的演化对克隆代码的维护有指导意义。
参考文献:
[1] THUMMALAPENTA S, CERULO L, AVERSANO L, et al. An empirical study on the maintenance of source code clones[J]. Empirical Software Engineering. 2010,15(1): 1-34
[2] ROY C K, CORDY JR, KOSCHKE R. Comparison and evaluation of code clone detection techniques and tools: A qualitative approach[J]. Science of Computer Programming. 2009,74: 470-495
[3] CHOI E, YOSHIDA N, ISHIO T, et al. Extracting code clones for refactoring using combinations of clone metrics[C]//Proceedings of the 5th International Workshop on Software Clones, New York, USA: ACM, 2011: 7-13.
[4] BOUKTIF S, ANTONIOL G, MERLO E, et al. A novel approach to optimize clone refactoring activity[C]//Proceedings of the 8th annual conference on Genetic and evolutionary computation, New York, USA: ACM, 2006: 1885-1892.
[5] BALAZINSKA M, MERLO E, DAGENAIS M, et al. Advanced clone-analysis to support object-oriented system refactoring[C]//Reverse Engineering, 2000. Proceedings. Seventh Working Conference on, Brisbane: IEEE, 2000: 98-107.
[6] GRAVES T L, KARR A F, MARRON J S, et al. Predicting fault incidence using software change history[J]. Software Engineering, IEEE Transactions on, 2000, 26(7): 653-661.
[7] JIANG L, SU Z, CHIU E. Context-based detection of clone-related bugs[C]// Proceedings of the the 6th joint meeting of the European software engineering conference and the ACM SIGSOFT symposium on The foundations of software engineering,New York: ACM, 2007: 55-64.
[8] Hassan A E. Predicting faults using the complexity of code changes[C]// Proceedings of the 31st International Conference on Software Engineering,Washington: IEEE Computer Society, 2009: 78-88.
[9] AVERSANO L, CERULO L, DI P M. How clones are maintained: An empirical study[C]// Software Maintenance and Reengineering, 2007. CSMR'07. 11th European Conference on,Amsterdam: IEEE, 2007: 81-90.
[10] G?DE N, KOSCHKE R. Frequency and risks of changes to clones[C]//Proceedings of the 33rd International Conference on Software Engineering, New York, USA: ACM, 2011: 311-320.
[11] THUMMALAPENTA S, CERULO L, AVERSANO L, et al. An empirical study on the maintenance of source code clones[J]. Empirical Software Engineering. 2010,15(1): 1-34
[12] Cai D, Kim M. An empirical study of long-lived code clones[M]// Mauro Pezzè:Fundamental approaches to software engineering. Berlin Heidelberg : Springer , 2011: 432-446.
[13] BETTENBURG N, SHANG W, IBRAHIM W M, et al. An empirical study on inconsistent changes to code clones at the release level[J]. Science of Computer Programming, 2012, 77(6): 760-776.
[14] BAKOTA T, FERENC R, GYIMOTHY T. Clone smells in software evolution[C]//Software Maintenance, 2007. ICSM 2007. IEEE International Conference on,Paris: IEEE, 2007: 24-33.
[15] KIM M, SAZAWAL V, NOTKIN D, et al. An empirical study of code clone genealogies[C]//ACM SIGSOFT Software Engineering Notes,New York, NY, USA: ACM, 2005, 30(5): 187-196.
[16] G?DE N, HARDER J. Clone stability[C]//Software Maintenance and Reengineering (CSMR), 2011 15th European Conference on,Oldenburg: IEEE, 2011: 65-74.
[17] KAPSER C, GODFREY M W. " Cloning considered harmful" considered harmful[C]//Reverse Engineering, 2006. WCRE'06. 13th Working Conference on,Benevento: IEEE, 2006: 19-28.
[18] WANG X, DANG Y, ZHANG L, et al. Can I clone this piece of code here?[C]//Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering, New York, USA: ACM, 2012: 170-179.
[19] CORTES C, VAPNIK V. Support vector machine[J]. Machine learning, 1995, 20(3): 273-297.
