网络民航事件虚假评论的识别研究
2016-09-26董松月陈润雨刘西菩赵颖莉马晓宁
董松月 陈润雨 刘西菩 赵颖莉 马晓宁


摘 要:互联网的开放性使得当前对于互联网上用户的评论内容没有质量控制机制,用户发表的内容中存在大量虚假评论,如何识别这些虚假评论信息成为重要问题。运用信息增益(Information Gain,IG),支持向量机(Support Vector Machine,SVM)等方法对民航事件的评论进行特征提取和分类,识别虚假评论。通过对比四种不同的核函数,本文选定基于RBF核函数的SVM分类器进行虚假信息的分类识别,其 F-measure值为90%,具有较优的分类效果。
关键词:虚假评论;信息增益;支持向量机;特征提取;核函数
Abstract: For the reason of internets openness, users are allowed to comment freely without quality control system, the published content includes many false reviews. How to identify these fake comments become an important issue. Based on Information Gain and SVM, this research identify the false reviews through feature extraction and classification. By comparing four kernel functions, RBF kernel function of SVM classifier is selected for the identification of the false information. The F-measure value is 90%, with qualified classification results.
Key words: false review; information gain; support vector machine; feature extraction; Kernel Function
0 引 言
随着Web广泛使用以及用户深入参与,出现社会热门事件后,用户会通过网络发表事件相关评论,但由于用户评论时的随意性,导致其中必然包含不实信息。自2007年起,虚假信息识别这一课题受到关注。国外研究成果已获一定进展,而国内研究仍处于探索时期,同时虚假信息识别大多数研究却只是集中于电子商务产品、互联网销售等新式专用领域,而关于民航事件评论中的虚假信息识别研究却仍亟待起步。基于如上背景需求,针对如何从海量民航事件评论信息中识别出虚假评论,本文将展开详尽论与阐析。
本文以民航事件(马航370事件)评论信息为研究对象,提出评论描述上述特征,并采用信息增益(Information Gain, IG)方法对各个特征计算权重,再使用支持向量机(Surpport Vector Machine,SVM)的4种核函数模型分别对训练集评论进行训练,得出四种分类器,对比性能后壳优选基于RBF函数的分类器,能够对真实评论和虚假评论进行更佳分类,从而高效、准确地识别出民航事件评论信息中的虚假评论。
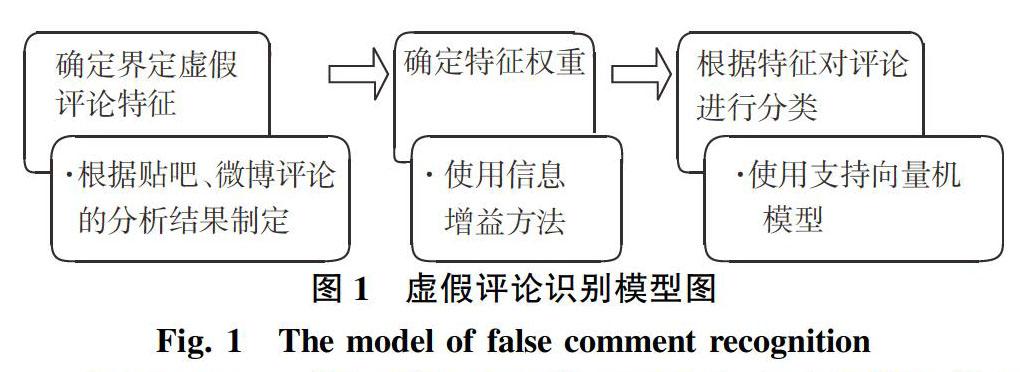
1 虚假评论识别模型
虚假评论识别模型中展示了识别虚假评论的步骤及流程。模型构建表示如图1如下。
模型图中主要方法介绍如下:
1.1 虚假特征的确定
本文通过支持向量机(SVM)模型对贴吧、微博用户关于民航事件的评论进行虚假评论识别,在这一过程中,特征的选取会直接影响到模型的识别效果。通过对评论的分析研究,本文分别从评论者、评论本身、评论内容3个方面进行虚假评论特征的选择,特征如下:
1)以评论者为中心的特征
评论者是否匿名(F1):本文关注的事件样本是受到国内乃至国际广泛关注的民航重大事件,多数情况下,非匿名评论比匿名评论真实性强,可信度更高。其中,蓄意误导价值观,或具有反社会倾向的评论者,以引导舆论,扰乱社会为目的,通常会隐藏身份,选择匿名的可能性较大。
2)以评论本身为中心的特征
评论是否重复出现(F2):普通评论者发表评论目的较为直接,重在表达意见,提出见解。而发布虚假信息的评论者,其重点在于误导民众情感,以达到引导舆论的目的。在这一前提下,通常认为虚假评论者希望尽可能扩大网络影响力,在各类贴吧论坛微博中重复发表语气、情感、甚至语句十分相似的评论,尤其是重复评论。因此本文研究认为,重复出现的评论可以作为识别虚假评论的重要特征。
(3)以评论内容为中心的特征
评论中是否出现主要评论对象的名称(F3):经过对大量评论的统计分析可知,虚假评论通常针对国家、政府、政党组织或非政府机构,在引导民众对其产生负面情感的过程中,评论者会忽略评论对象本身。例如马航事件中,评论者会忽略“马航”而着重强调政府词汇。
评论中正面情感词出现次数/评论中所有情感词出现次数(F4),评论中负面情感词出现次数/评论中所有情感词出现次数(F5):虚假评论制造者擅于使用情感倾向度较大的词汇,在整体评论中情感倾向十分一致(持中间态度的虚假评论则较少出现)。
评论中政府部门的出现次数/评论中所有评论对象的出现次数(F6):经过对大量评论的研究统计可得,在民航重大事件的评论中,大多虚假评论内容均围绕贬低污蔑国家政府,这一特征已成为大多虚假评论的共性。
本文利用支持向量机识别评论时,每条评论均设定上述6个特征来构成核心表示,并对支持向量机模型分类器进行训练。
1.2 信息增益
在文本分类问题中,信息增益方法用于衡量虚假特征是否出现于某类别文本中、以及对于评论的虚假性预测能提供多少信息,是一种基于熵的评估方法。具体定义就是虚假特征为整个分类所能提供的信息量,即不考虑该特征时文档的熵与考虑该特征后的文档熵的差值。通过对数据的开发训练,计算出每个特征的信息增益值,按照信息增益从大到小排序,这一排序究其本质也代表着不同特征对文本信息影响程度的排序。某个特征的信息增益值越大,表示其贡献越大,对分类也就更为重要。本次研究中利用信息增益方法,对区分虚假评论的特征进行影响力大小排序。
其中, 是虚假评论训练集的类别, 表示第 类文档出现的概率, 表示在第 类文档中特征 的出现的概率。 表示不含 特征的文档概率, 表示不含有 的文档在 中的条件概率。 为真实类或虚假类评论文档。
1.3 支持向量机
(1)本实验使用支持向量机的方法对评论的真假性进行预测分类。首先通过特征选择与提取的方法,选用评论是否匿名、评论是否重复出现、评论中是否出现主要评论对象的名称、评论中正面情感词占比、评论中负面情感词占比、评论中政府部门相关词汇占比这 6 项数据作为区别评论真假性的特征,这里用小写字母 表示,把这 6 个特征表示为向量形式,特征向量具体表示为 。
(2)接着将 6 维的评论真假性预测结果特征向量映射为 6维空间内的一个点,分别选取30个真实评论和虚假评论作为训练集来对应配入 6 维空间,同时利用这些数据训练计算机形成 SVM 分类器,通过线性支持向量分类机算法计算出5 维的超平面(将 6 维空间一分为二的超平面比 6维空间少一维)作为分类边界将 6 维空间进行二分, 二分后的2个空间分别代表真实评论特性向量的集合和虚假评论特征向量的集合。
(3)对于一个未知真假性的评论,只需通过评论测试,得出测试结果。提取测试结果的特征,再将测试结果特性以向量的形式给出表示,并将数值代入训练后的 S V M 分类器超平面的数学表达式即可分析该评论的真假性性 :结果为0,则表示该评论为虚假性评论;结果为1,则表示该评论为真实性评论。评论真假预测结果特征向量在 6 维空间内对应的点距离超平面的距离越远,则代表其特征越明显,即虚假性越高或越低。
1. 实验结果与分析
2.1 实验分析
2.1.1 信息增益
本实验以马航370事件为实验样本,由于数据集会直接影响实验的准确性与科学性,为使数据集更具代表性和真实性,本文从贴吧、微博中随机选取150条评论。选择8名实验者,分别对所有评论进行虚假评论与真实评论的人工标注,选择结果中相同的评论作为本部分实验的数据集。最终数据集共103条评论,其中虚假评论40条,非虚假评论63条。本实验中将评论划分为2类,T:虚假评论,F:非虚假评论。其特征计算方法如下:
F1=n,(n=0,1)(0:匿名评论者;1:非匿名评论者);
F2=n,(n=0,1)(0:评论出现次数超过3次;1:评论出现3次以下);
F3=n,(n=0,1)(0:评论中不存在主要评论对象的名称;1:评论中存在主要评论对象的名称);
F4=评论中正面情感词的次数/评论中出现所有情感词的次数;
F5=评论中负面情感词的次数/评论中出现所有情感词的次数;
F6=评论中政府部门出现的次数/评论中所有评论对象出现的次数。
本实验对6个特征2个类别的100条评论进行了信息增益的特征权重计算。权重计算结果如表1所示。
计算结果表明,6个特征为虚假信息识别提供的信息量由大到小依次为:F6, F4,F5,F2,F1,F3。信息增益值越大,表明该特征对识别虚假信息的影响力越强。由实验结果可知,评论中是否出现针对政府部门的攻击性词汇是评判虚假信息的重要依据。情感词汇也成为虚假信息的重要特征,含有浓厚正面或负面感情色彩的评论使虚假信息的可能性显著提高。评论是否重复出现的影响力则相对较小。匿名特征权值小是当今网络平台(例如微博、贴吧等)强制要求必须注册账号才能发表评论等限制因素造成的。由于评论都围绕特定民航事件发表观点,几乎均存在评论对象名称,故该特征权值相对最小。
2.1.2 SVM的训练与预测
本实验使用Matlab实现SVM分类,用训练集对SVM分类器进行训练,利用所得模型预测测试机标签值。实现使用libsvm工具箱。
首先建立数据集和类别集。数据集包括上文确定的6个特征,类别集含有虚假、真实2个类别。
评论属性矩阵集如图2所示。
3 结束语
总体而言,互联网虚假评论研究是较新领域,具有广阔的应用前景。目前国内外虚假评论研究集中在商品垃圾评论,尚未发现针对贴吧、微博用户关于社会热门事件所发表的虚假信息的筛选及研究。本文以马航370事件作为研究对象,从信息的真实性角度对民航舆情评论的特征进行概述,利用信息增益的方法计算特征权重,基于文本分类的思想,比较验证SVM机器模型对虚假评论的识别效果。实验结果证明,本文实验所选取的特征及采用的方法能够对虚假评论与真实评论进行分类,进而识别虚假评论。未来需要在进一步研究虚假评论的特征、深入分析其产生机理的基础上,研究更有效的分类及检测方法。
参考文献:
[1] 李霄,丁晟春. 垃圾商品评论信息的识别研究[J]. 现代图书情报技术,2013(1):63-68.
[2] 陈晓美. 网络评论观点知识发现研究[D].长春:吉林大学,2014.
[3] 莫倩,杨珂. 网络水军识别研究[J]. 软件学报,2014,25(7):1505-1526.
[4] 杨风雷,黎建辉. 用户生成内容中的垃圾意见研究综述[J]. 计算机应用研究,2011,28(10):3601-3605.
[5] 韩晓晖. Web社会媒体中信息的质量评价及应用研究[D].济南:山东大学,2012.
[6] JINDAL N,LIU B.Analyzing and detecting review spam[C]//Proceeding of the 7th IEEE International Conference on Data Min-ing ( ICDM07 ).Omaha,Nebraska, USA:IEEE Computer Society, 2007: 547-552.
[7] JINDAL N, LIU B. Review spam detection[C]//Proceedings of the 16th International Conference on World Wide Web.Banff, Al-berta, Canada:ACM, 2007: 1189 -1190.
[8] LIM EP, NGUYEN VA, JINDAL N, et al. Detecting product review spammers using rating behaviors[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Man-agement( CIKM10).Toronto, ON, Canada:ACM, 2010: 930 -948.
[9] MUKHERJEE A, LIU B, WANG J, etal. Detecting group review spam[C]//Proceedings of the 28th ACM International Conference on Information andKnowledge Management.Hyderabad, India:ACM, 2011:1123 -1126.
[10] BHATTARAI A, RUS V, DASGUPTA D. Characterizing comment spam in the blogosphere through content analysis[C]//Proceedings of IEEE Symposium on Computational Intelligence in Cyber Security (CICS). Nashville, TN:IEEE Computer Society, 2009:37 -44.
[11] WU G, GREENE D, SMYTH B, etal.Distortion as a validation criterion in the identification of suspicious reviews[C]//Proceedings of the 1st Workshop on Social Media Analytics. Washington, DC, USA: ACM, 2010:10 -13.
