利用时长信息提高说话人确认系统的鲁棒性
2016-09-26胡群威吴明辉
胡群威,吴明辉,李 辉
(中国科学技术大学 电子科学与技术系,安徽 合肥 230027)
利用时长信息提高说话人确认系统的鲁棒性
胡群威,吴明辉,李辉
(中国科学技术大学 电子科学与技术系,安徽 合肥 230027)
在文本无关说话人确认领域,基于总差异空间的说话人确认方法已成为主流方法,其中概率线性判别分析(Probabilistic Linear Discriminant Analysis, PLDA)因其优异的性能受到广泛关注。然而传统PLDA模型没有考虑注册语音与测试语音时长失配情况下的差异信息,不能很好地解决因时长失配带来的说话人确认系统性能下降的问题。该文提出一种估计时长差异信息方法,并将此差异信息融入PLDA模型,从而提高PLDA模型对时长差异的鲁棒性。在NIST数据库上的实验表明,所提出的方法可以较好地补偿时长差异,性能上也优于PLDA方法。
说话人确认;I-Vector系统;概率线性判别分析;时长失配;时长差异信息
引用格式:胡群威,吴明辉,李辉. 利用时长信息提高说话人确认系统的鲁棒性[J].微型机与应用,2016,35(11):51-55.
0 引言
说话人确认技术作为生物特征识别领域重要的研究热点,在身份识别、人机交互和移动支付等领域具有广阔的应用前景。近年来,在高斯混合模型-通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[1]基础上,基于因子分析的方法因其优异的性能得到研究者的广泛关注。
在GMM-UBM框架下,说话人信息主要包含在GMM的均值超矢量[2]中。由于均值超矢量也包含信道等扰动信息,KENNY P等人提出联合因子分析(Joint Factor Analysis,JFA)[3]方法,将均值超矢量分解为说话人与信道两部分之和,进而可以削弱信道的干扰。然而,均值超矢量维度过高,计算代价较高,不仅如此,JFA在进行信道补偿时也损失了一部分说话人信息[4]。鉴于JFA的缺点,DEHAK N等人提出基于总差异空间的I-Vector[5]系统,此系统直接将均值超矢量压缩成一个更加紧致的低维的矢量,同时尽可能地保留说话人信息。由于I-Vector中依然存在信道等扰动信息,参考文献[6]提出概率线性判别分析(PLDA)应用于总差异空间,可以较好地削弱信道扰动的影响,取得优异的性能。
目前基于I-Vector的说话人确认多集中在长时语音(一般为几分钟),即使用长时语音注册,长时语音测试。但实际应用中考虑到使用的便捷性,注册语音往往使用长时语音,当进行测试时,测试语音只有几十秒或者几秒钟。然而I-Vector作为极大后验(MAP)的点估计[7],其提取依赖于充足的统计量,时长越短,统计样本相对越少,估计得越不准确。参考文献[8]指出,当语音时长足够长(通常大于2 min),I-Vector的区分性已接近饱和,此时估计的I-Vector可认为是准确的。但是当语音时长较短(几秒钟),估计得相对不可靠,其区分性能会严重下降。I-Vector估计不准确将直接导致基于I-Vector的PLDA系统的性能下降。针对时长带来的性能问题,国内外学者展开了一系列的研究。参考文献[9]研究了时长失配情况下时长对系统性能的影响。参考文献[10]研究了不同语音时长的I-Vector的分布,指出时长带来的I-Vector的估计偏差,等价于加性噪声。参考文献[11]提出短时差异规整算法(Short Utterance Variance Normalization,SUVN),对短时语音的I-Vector进行补偿,取得了一定的性能提升。
受到上述文献启发,本文针对实际应用中训练测试时长失配的情况,同时考虑传统的PLDA系统没有考虑注册语音与测试语音时长失配情况下的差异信息,提出估计短时语音I-Vector的时长差异信息的方法,并将此信息融入到PLDA系统进行补偿。本文方法较好地利用时长信息,增加系统对时长差异的鲁棒性,进而提高系统的整体性能。
1 基于I-Vector的说话人确认系统
1.1I-Vector基线系统
在传统GMM-UBM中,说话人的区分信息主要集中在目标说话人GMM模型的均值超矢量中。GMM均值超矢量中既包含了说话人的信息,同时也包含了信道等干扰信息。JFA技术被用于对说话人与信道建模,然而研究表明[4],JFA中的信道因子中也包含了说话人信息。鉴于上述存在的缺点,参考文献[5]提出总差异空间,将说话人与信道作为整体建模。给定目标说话人的一段语音,则基于总差异空间的目标说话人的GMM均值超矢量可以用式(1)表示:
M=m+Tω
(1)
其中,M为说话人的GMM均值超矢量;m为UBM均值超矢量;T为总差异空间矩阵,低秩的、矩阵的列组成总差异空间的基底;ω为总差异因子,先验服从标准正态分布,对于每个说话人的语音段,对应的I-Vector的提取过程即为计算总差异因子ω的极大后验点估计。总差异空间矩阵的训练以及I-Vector计算参见参考文献[12]。
通常,提取完I-Vector后,采用余弦评分,也就是将测试语音的I-Vector与事先注册的说话人模型I-Vector进行余弦值计算,如式(2)所示。
(2)
其中,ωtar表示为说话人模型的I-Vector,ωtest表示测试语音的I-Vector。
1.2高斯概率线性判别分析
忽略I-Vector的提取机制,PLDA可看作是由生成型模型产生的声学特征,其生成过程可以用说话人因子与信道因子描述,不同的因子先验假设构成了不同的PLDA模型[6],若假设说话人因子以及信道因子均服从高斯分布,相应的模型称为高斯线性判别分析(GaussianPLDA,GPLDA)[6,12]。
假定第i个说话人的第j个I-Vector表示为wij,标准的GPLDA模型假设如式(3)所示:
wij=μ+Φyi+Uxij+εij
(3)
yi~N(0,I)
(4)
xij~N(0,I)
(5)
εij~N(0,Σ)
(6)
其中,μ为所有说话人的I-Vector均值,矩阵Φ表示说话人子空间,矩阵U表示信道子空间,矢量yi和xij为对应的子空间因子,两者统计独立,并且均服从标准高斯分布,εij表示残差,服从均值为零、协方差为对角阵Σ的高斯分布。
GPLDA模型最初用于人脸识别[12],由于其输入特征维度较高,需要大数据样本才能有效地估计出相应的参数,否则容易陷入过拟合。在说话人确认中,输入特征为I-Vector矢量,维度一般为100~600,维度相对较小,考虑模型的复杂度,简化GPLDA模型如下:
wij=μ+Φyi+εij
(7)
这里,只是将信道部分合并到残差中,此时εij服从均值为零、协方差为全角矩阵的高斯分布,这样,残差便可以包含更多的扰动信息,以此弥补合并信道因子所带来的损失。
由于GPLDA为线性高斯模型[13],因此边缘分布、条件分布均为高斯分布,其中边缘分布为:
wij~N(μ,ΦΦT+Σ)
(8)
相应的条件分布为:
wij|yi~N(μ+Φyi,Σ)
(9)
GPLDA模型参数{μ,Φ,Σ}可由EM算法训练得到,详细训练过程参见参考文献[12]。
使用GPLDA建模的前提是假设I-Vector先验服从高斯分布。然而,由于I-Vector的行为并不是服从高斯分布,而是服从长尾分布(heavy tail)[6],考虑到高斯分布经过线性变化依然为高斯分布,所以必须对I-Vector进行非线性变化,以削弱I-Vector的非高斯的影响。参考文献[14]指出对I-Vector进行长度规整与Whitening规整可以有效削弱其非高斯行为,从而提高GPLDA对I-Vector分布建模能力。
1.3GPLDA确认得分计算
说话人确认的问题可以看成一个二元假设检验问题,即给定两个I-Vector:w1、w2,存在以下两个假设:
Hs:假设w1、w2是由同一个说话人生成的,则它们共享同一个说话人因子y,即:
(10)
此时的协方差为:
(11)
所以:
(12)
Hd:假设w1、w2是由不同的说话人产生的,则它们具有不同的说话人因子y1、y2,即:
(13)
此时的协方差为:
(14)
所以:
(15)
对于上述二元假设检验可以使用两个高斯函数的对数似然比作为最后的得分:
(16)
2 改进系统
使用GPLDA对说话人以及其他扰动进行建模,其中残差项刻画了扰动因子的行为。由式(16)可以看出,得分函数是对称的,即注册语音与测试语音是可以交换位置的,不会影响得分,主要原因为注册语音与测试语音是在相同的扰动假设下而得出的[15]。然而,对于注册语音为长时语音,测试为短时语音的时长失配的情况,显然直接使用GPLDA评分是不够精确的。考虑到I-Vector只是总差异因子的极大后验点估计,估计的准确度取决于后验分布的协方差。对于同一个说话人,其长时语音段的I-Vector估计得相对准确,也就是说,由时长引起的扰动较小,而短时语音段的I-Vector估计得相对不可靠,由时长引起的扰动较大,总之,对于同一个说话人,语音时长越短,对应I-Vector的GPLDA模型将趋向于产生越大的残差协方差。
2.1融入时长差异信息的GPLDA
由于注册语音为长时语音,其对应的I-Vector估计相对准确,而当测试语音为短时语音时,其估计的I-Vector存在相对较大的不确定度,假设服从如下分布:
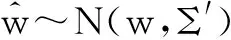
(17)
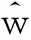
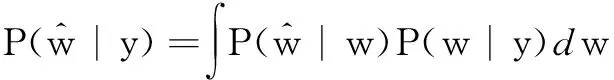
=∫N(w,Σ′)N(w;μ+Φy,Σ)dw
=N(w;μ+Φy,Σ+Σ′)
(18)
假设长时注册语音与短时测试语音对应的I-Vector分别为w1、w2,当它们是由同一个说话人生成的,则由式(11)和式(18)可得此时的协方差为:
(19)
当它们是由不同说话人生成的,则由式(13)和式(18)可得此时的协方差:
(20)
由式(19)和式(20)重写对数似然比得分公式:
(21)
此时的得分公式(21)针对短时语音的I-Vector融入了时长差异信息,更加精确地刻画了短时语音的行为,而且从式(21)可以看出,注册语音与测试语音的I-Vector是不可交换的,这是因为刻画两者扰动行为的残差项不再是同一假设。
2.2时长差异信息的估计
为了捕捉短时语音的时长差异信息,本文使用了大量开发集数据以及从中截短得到短时语音,将长时语音对应的I-Vector与短时语音对应的I-Vector的差异作为时长差异信息的度量,即式(22)所示:
(22)
其中,wfull为长时语音的I-Vector,wshort为从长时语音截短的短时语音的I-Vector,使用式(22)可以近似估计短时语音的时长差异信息,并将此信息融入GPLDA模型。
3 实验结果与分析
本文分别构建了I-Vector余弦评分的基线系统、GPLDA系统以及改进的GPLDA系统。实验所用到的语料均来自NIST[16]数据库的电话信道语音。
3.1训练数据及参数配置
实验采用39维美尔倒谱系数(MFCC)作为特征参数。训练UBM的数据取自NIST05和NIST06男性电话信道数据集,共5 200条5min时长的训练语音,切过静音后大约2min,UBM采用512个高斯混合,每个高斯的协方差矩阵为对角阵。使用相同的数据训练总差异矩阵T,采用随机初始化矩阵,迭代8次,最终得到19 968×200维的矩阵T。训练PLDA的数据取自NIST08中共300个说话人,每人10段语音,训练PLDA前,要对I-Vector进行Whiten规整以及长度规整,说话人因子数为100。使用NIST08中的300个说话人,并从中截短至30s、10s和5s三种情况以及全时长(full),用于估计对应的时长差异信息。
3.2系统性能评估标准
实验的评测标准采用等误识率(EqualErrorRate,EER)和NIST评测中检测代价函数(DetectionCostFunction,DCF)。EER是错误拒绝率(FalseRejectionrate,FR)和错误接受率(FalseAcceptancerate,FA)相等的值。检测代价函数定义为FA和FR的加权和:
DCF=Cfr×FR×Ptar+Cfa×FA×(1-Ptar)
(23)
其中Cfr和Cfa分别是错误拒绝和错误接受的代价,Ptar为真实说话人出现的先验概率,在NIST的评测任务中的定义为Cfa=1,Cfr=10,Ptar=0.01,以最小检测代价函数(minDCF)作为系统性能的评测标准。
3.3实验结果
表1给出了基线系统在不同测试时长下的EER和MinDCF。从表1的数据可以发现,基线系统在测试时长为全时长时,性能最佳,随着测试时长变短,性能会大幅下降。
表2给出了GPLDA在不同测试时长的EER和MinDCF。从表2的数据同样可以看出,GPLDA系统性能随着时长变短而下降,与表1的数据作对比,当测试时长为全时长时,GPLDA系统性能相对提高了57%,当测试时长变短,GPLDA系统的性能平均相对提升了40%,特别是当测试时长为5 s时,性能相对提升只有32%,远小于全时长的性能提升。这表明GPLDA并不能很好地对时长信息进行建模。
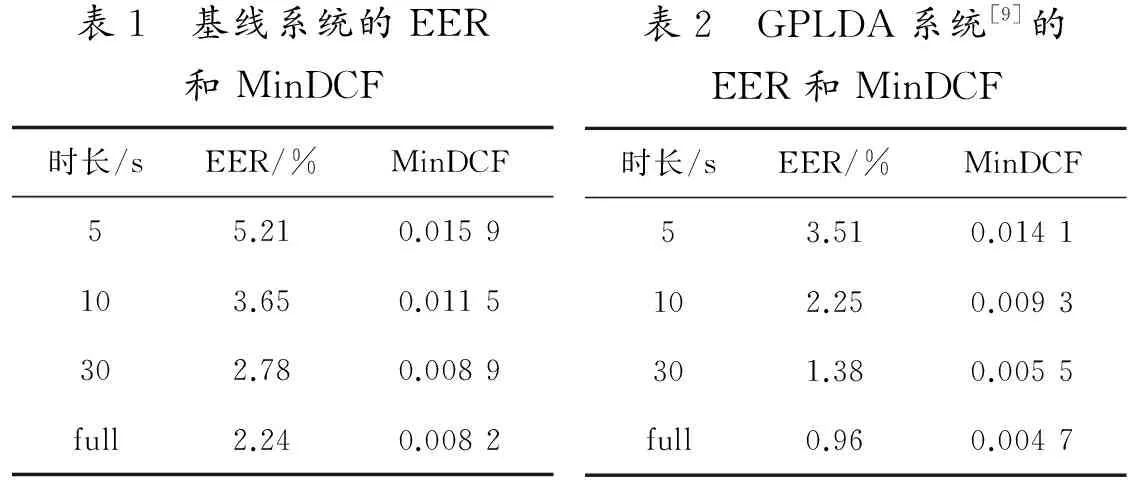
表1 基线系统的EER和MinDCF时长/sEER/%MinDCF55.210.0159103.650.0115302.780.0089full2.240.0082表2 GPLDA系统[9]的EER和MinDCF时长/sEER/%MinDCF53.510.0141102.250.0093301.380.0055full0.960.0047
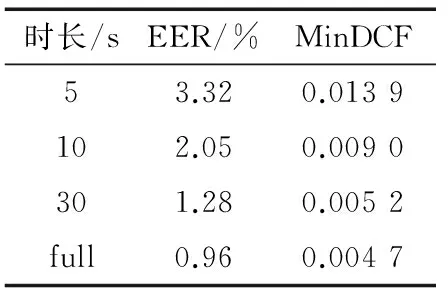
表3 改进系统的EER和MinDCF
表3给出了本文改进系统在不同测试时长下的EER和MinDCF。表3与表2作对比可以发现,当测试时长为全时长时,改进系统与传统GPLDA系统的性能几乎没有发生变化,当测试语音时长变短,改进系统相对于传统GPLDA系统,性能平均提升7.2%,这表明改进系统利用时长信息可以有效地对时长失配进行补偿。
4 结论
本文考虑到注册语音与测试语音时长失配情况下的差异信息,提出估计时长差异信息的方法,并将此差异信息融入PLDA模型,从而提高PLDA模型对时长差异的鲁棒性。在NIST数据集上的实验证实,本文的方法相对于基线系统性能平均提升47.5%,相对于PLDA模型系统也有平均7.2%的提升。
[1] REYNOLDS D A, QUATIERI T F, DUNN R B. Speaker verification using adapted Gaussian mixture models [J]. Digital Signal Processing, 2000, 10(1): 19-41.
[2] CAMPBELL W M, STURIM D E, REYNOLDS D A. Sup port vector machines using GMM supervectors for speaker verification[J]. Signal Processing Letters, IEEE, 2006, 13(5): 308-311.
[3] KENNY P, BOULIANNE G, OUELLET P, et al. Joint factor analysis versus eigenchannels in speaker recognition[J]. Audio, Speech, and Language Processing, IEEE Transactions on, 2007, 15(4): 1435-1447.
[4] DEHAK N. Discriminative and generative ap proaches for long-and short-term speaker characteristics modeling: application to speaker verification[D]. Canada: Ecole de Technologie Superieure, 2009.
[5] DEHAK N, KENNY P, DEHAK R, et al. Front-end factor analysis for speaker verification[J]. Audio, Speech, and Language Processing, IEEE Transactions on, 2011, 19(4): 788-798.
[6] KENNY P. Bayesian speaker verification with heavy-tailed priors[C].Odyssey Speaker and Language Recogntion Workshop, 2010: 14.
[7] CUMANI S, PLCHOT O, LAFACE P. On the use of i-vector posterior distributions in Probabilistic Linear Discriminant Analysis[J]. Audio, Speech, and Language Processing, IEEE/ACM Transactions on, 2014, 22(4): 846-857.
[8] RAO W, MAK M W. Boosting the performance of i-vector based speaker verification via utterance partitioning [J]. Audio, Speech, and Language Processing, IEEE Transactions on, 2013, 21(5): 1012-1022.
[9] SARKAR A K, MATROUF D, BOUSQUET P M, et al. Study of the effect of i-vector modeling on short and mismatch utterance duration for speaker verification[C].Interspeech, 2012: 2662-2665.
[10] HASAN T, SAEIDI R, HANSEN J H L, et al. Duration mismatch compensation for i-vector based speaker recognition systems[C].Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013: 7663-7667.
[11] KANAGASUNDARAM A, DEAN D, SRIDHARAN S, et al. Improving short utterance i-vector speaker verification using utterance variance modelling and compensation techniques[J]. Speech Communication, 2014, 59: 69-82.
[12] PRINCE S J D, ELDER J H. Probabilistic linear dis criminant analysis for inferences about identity[C].Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on. IEEE, 2007: 1-8.
[13] BISHOP C M. Pattern recognition and machine learning [M]. springer, 2006.
[14] GARCIA-ROMERO D, ESPY-WILSON C Y. Analysis of i-vector length normalization in speaker recognition systems[C].Interspeech, 2011: 249-252.
[15] CHEN L, LEE K A, MA B, et al. Channel adaptation of plda for text-independent speaker verification[C].Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on. IEEE, 2015: 5251-5255.
[16] NIST. The NIST 2006 speaker recognition evaluation [EB/OL].(2006-xx-xx)[2016-01-04]http://www.itl.nist.gov/iad/mig/test/sre/2006/index.html,2006.
Utilizing duration information to improve the robustness of speaker verification system
Hu Qunwei,Wu Minghui,Li Hui
(Department of Electronic Science and Technology, University of Science and Technology of China, Hefei 230027, China)
The approaches based on total variability space have become popular in text-independent speaker verification, and the probabilistic linear discriminant analysis (PLDA) has attracted much attention because of its promising performance. However the traditional PLDA model don’t consider duration information between enrollment utterance and test utterance under the duration mismatch, thus it can’t solve the problem of system performance degradation incurred by duration mismatch. In this paper, a method is proposed to estimate duration variance information, where the duration variance information is integrated into the PLDA model, resulting in improving robustness to duration variability. Experiments on NIST database show that the proposed method is more effective to improve the performance of speaker verification system compared to the PLDA method.
speaker verification; I-Vector system; Probabilistic Linear Discriminant Analysis(PLDA); duration mismatch; duration variance information
TP391
A
10.19358/j.issn.1674- 7720.2016.11.017
2016-01-14)
胡群威(1989-),通信作者,男,硕士研究生,主要研究方向:说话人识别。E-mail:hqw2607@mail.ustc.edu.cn。
吴明辉(1990-),男,硕士研究生,主要研究方向:说话人识别。
李辉(1959-),男,博士,副教授,主要研究方向:语音信号处理,电子系统设计。
