基于Hadoop的校园一卡通数据分析
2016-09-25付影平
付影平,马 晶,杜 程
(西安邮电大学 信息中心,陕西 西安 710061)
基于Hadoop的校园一卡通数据分析
付影平,马晶*,杜程
(西安邮电大学 信息中心,陕西西安710061)
文章通过对校园一卡通消费数据特征进行分析,发现学生消费行为背后隐藏的规律。文章采用数据挖掘统计分析的方法对前期获取的原始数据进行筛选,从不同年级、不同就餐地点两个方面考虑,研究不同群体的消费习惯。数据处理是在Hadoop(分布式系统基础架构)框架下采用MapReduce(一种编程模型,映射和化简)方法,通过对关键字过滤之后得到统计结果并将其可视化。
校园一卡通;消费数据;Hadoop;MapReduce
当下,众多高校都在积极建设数字化校园。校园一卡通系统作为数字化校园的重要组成部分,是校园信息化建设的基础工程之一,主要具有综合消费、身份识别、金融服务、公共信息服务等功能。校园一卡通卡片取代了以前各种证件(包括学生证、工作证、借书证、出入证等)的全部或部分功能,最终实现“一卡在手,走遍校园”。以校园卡为纽带促进数字校园的建设,扩展校园卡和业务系统的结合应用,会产生大量学生消费和日常活动数据。通过对这些数据进行分析,可发现其潜在价值,促进学校管理效率和水平的提升。
1 相关技术介绍
1.1Hadoop介绍
Hadoop是由Apache Lucene的创始人Doug Cutting创建的,起源于开源网络搜索引擎Apache Nutch,它本身也是Lucene项目的一部分。Hadoop框架中最核心的设计是分布式文件系统( Hadoop Distributed File System,HDFS)和MapReduce。HDFS提供了海量数据的存储,MapReduce提供了对海量数据的计算[1]。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理[2]。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务[3]。
1.2MapReduce介绍
MapReduce是一种可用于数据处理的编程模型。Hadoop可以运行各种语言版本的MapReduce程序。MapReduce本质上是并行运行的,因此可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心。MapReduce的优势在于处理大规模数据集。MapReduce实现了存储的均衡,但未实现计算的均衡。MapReduce模型主要有Mapper和Reducer两个抽象类。Mapper端主要负责对数据的分析处理,最终转化为Hadoop的数据结构;Reducer 端主要是获取Mapper出来的结果,对结果进行统计[4]。
为了充分利用Hadoop架构下MapReduce的并行处理优势,需要将查询表示成MapReduce作业。MapReduce任务过程分为两个处理阶段:Map阶段和Reduce阶段。每个阶段都以键值对作为输入和输出,其类型由程序自己选择。只需要程序员自己写入Map函数和Reduce函数。本文使用MapReduce的逻辑数据流,如图1所示。

图1 逻辑数据流
2 消费数据分析方法设计
2.1消费数据结构
一卡通数据单日产生量大、来源广泛、产生人群类型复杂。消费日志数据包括证件号码、卡号、第二证件号码、流水号、商户名称、交易金额、交易时间等18项信息。而此次需要获取的关键数据主要是证件号码、第二证件号码(身份证)、商户名称、交易金额和交易时间等。
2.2消费数据分析设计
2.2.1基于年级的消费数据分析方法设计
在近两万名学生中,不同年级因为教学计划安排差异以及高年级学生考研、找工作等因素影响,会在消费地点、消费时间等方面有差别。从这些方面分析学生消费行为,可以更好地帮助学校引导学生进行实际需求的消费。
按照上述思路,通过从原始数据“学生证件号”“消费商铺”以及“消费金额”等字段进行数据提取,将年级和消费地点等条件相结合,计算不同年级在不同地点的平均消费额,以此来发现不同年级选择消费地点的倾向性;通过从原始数据“学生证件号”和“消费商铺”以及“消费时间”等字段进行数据提取,以年级、消费地点及时间段为关键字,计算出不同消费地点在各个时间段内发生的消费次数,用于判断相同时间段内,哪些地点是消费发生的热点地区。
2.2.2基于位置的消费数据分析方法设计
学校有两个食堂,但在两个食堂建成之后,并没有数据表明其设置是否合理、师生是否满意,是否因环境问题而选择不同的就餐地点。通过对数据的分析,可以提示学校对消费人次较少的地方加强建设,增强服务提供能力,提升学生消费体验。
按照上述思路,将原始数据中的消费时间和消费地点提取出来,将月份和两个食堂作为关键字,依据不同时间对消费人次和每月单次平均消费额进行计算。
3 消费数据分析方法实现及分析
采用Hadoop框架,实现是在Ubuntu和Windows操作系统中完成的,数据采集时间为2015年3月1日至2016年3月20日,主要采用MapReduce和HDFS技术完成数据分析工作。
3.1数据分析平台搭建
本次环境的搭建如图2所示,主要分为两个部分。一端是Hadoop集群,在集群中分为Master和Slave两个角色,其中Master是Hadoop的主节点,主要是管理文件系统的命名空间和客户端对文件系统的访问,Slave 则作为管理和存储数据。MapReduce框架是由一个单独运行在Master节点上的JobTracker和运行在每个集群Slave节点的TaskTracker共同组成的[5]。Master节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;Slave节点仅负责由Master节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给Slave节点,同时调度任务并监控TaskTracker的执行。

图2 环境搭建示意
另一部分是在Windows7上安装Eclipse开发软件,配置Hadoop开发环境,通过以太网连接Hadoop集群Master,利用Eclipse的开发环境来控制HDFS和调用MapReduce。
Hadoop操作环境为Ubuntu14.4系统,Hadoop软件版本为2.6.4,集群架构为伪分布式。Eclipse安装在Windows7操作系统中,软件版本为4.5.0,HadoopEclipse插件版本为hadoop-eclipse-plugin-2.6.4。Hadoop是一个强大的并行框架,它允许任务在其分布式集群上并行处理[6]。
3.2消费数据预处理
本文获取的原始数据是以Excle格式存储的,需要先将其以UTF-8编码形式转换为txt格式,以便MapReduce识别、处理。在对原始数据分析过程中发现有些数据是不完整的,或者有很多数据如果不进行剔除,会影响最后结果的准确性。那么在Mapper函数进行处理之前,要对这些数据进行一次清洗,将无效数据进行剔除,避免不必要的误差。
3.3基于年级的消费行为分析
根据上述数据分析方法,基于年级的消费数据设计,是利用Hadoop的MapReduce方法进行一个关键字段的过滤以及一个群体共同特征的统计,得出这个特征群体的平均值并进行对比。代码流程如图3所示。

图3 基于年级消费数据分析流程
在前期各个年级的消费数据代码运行之后,各个年级在不同消费地点段平均消费金额对比如图4所示。
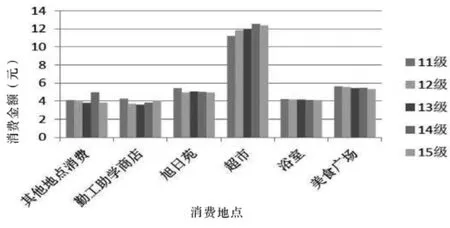
图4 各个年级在相同地点消费对比
其中2011级学生的数据截止到2015年6月前,2015级学生数据从9月开始,从图4中可以看出,2011级学生在旭日苑消费比其他低年级要高。大四毕业生因为课业量少,如果没有参加实验室或其他社团,那么每天主要的消费活动范围就在宿舍楼附近,而旭日苑是离宿舍最近的食堂;从勤工助学商店消费平均额可以看出,大一、大二学生略高一些。
3.4基于位置的消费行为分析
基于上述关于食堂的消费数据分析方法的设计,因此在关于食堂的流程图设计上,主要依据季节以及各个月份每个食堂的单次平均消费额来对比,代码流程如图5所示。

图5 基于位置的消费数据流分析
基于位置的数据可视化,如图6所示,可以更加直观地对比不同季节对于食堂的选择差异。

图6 消费次数对比
由图6可以看出,学生更倾向于旭日苑而不是美食广场,季节对于学生选择食堂并没有太大的影响,基本在所有季节,旭日苑的消费次数都是美食广场的2倍左右。
4 结语
本次工作因为需要进行大量数据的处理,在平台搭建上选择了Hadoop框架。针对新校区的本科生,从不同年级、不同就餐地点两个方面进行消费行为的统计。发现,低年级和高年级在消费时间段和消费地点都会有一定差异,低年级的消费地点更分散,消费时间段高峰期在下课后;高年级恰恰相反,消费点多数集中在宿舍楼附近,消费时间段刚好会避开低年级消费高峰期;对两个食堂消费进行统计发现,旭日苑消费次数一直都是美食广场的两倍。
[1](美)怀特.Hadoop权威指南[M].曾大聃,周傲英,译.北京:清华大学出版社,2010.
[2]黄懋.基于集群的HDFS高可用性研究和实现[D].上海:复旦大学,2012.
[3]蔡睿诚.基于HDFS的小文件处理与相关MapReduce计算模型性能的优化与改进[D].吉林:吉林大学,2012.
[4](美)拉姆.Hadoop实战[M].韩冀中,译.北京:人民邮电出版社,2011 .
[5]张永坤.基于进程剩余运行时间的集群负载平衡系统[D].武汉:华中科技大学,2004.
[6]贾玉生.基于Hadoop的分布式文本分类研究[D].北京:北京工业大学,2013.
Analysis on data of the Campus IC Card based on Hadoop
Fu Yingping, Ma Jing, Du Cheng
(Xi'an University of Posts and Telecommunications, Xi'an 710061, China)
This article found the hidden rules of students' consumption behavior through the analysis on characteristics of the Campus IC Card consumption data. In this paper, the methods of data mining and statistical analysis are used to screen the raw data,in terms of two sides including different grades and different restaurants to considerate and study the consumption habits of different groups. Data processing means to adopt the MapReduce method under the Hadoop framework to get statistical results and visualize them after fltering the keywords.
Campus IC Card; consumption data; Hadoop; MapReduce
付影平(1973— ),男,陕西西安,助理工程师;研究方向:计算机网络安全。*
马晶(1991— ),女,陕西渭南,硕士研究生;研究方向:云计算理论与应用。
