ID3算法在程序设计类课程成绩分析中的应用研究
2016-09-14刘敏娜
刘敏娜
(1.咸阳师范学院 信息工程学院,陕西 咸阳 712000;2.咸阳师范学院 图形图像处理研究所,陕西 咸阳 712000)
ID3算法在程序设计类课程成绩分析中的应用研究
刘敏娜1,2
(1.咸阳师范学院 信息工程学院,陕西 咸阳712000;2.咸阳师范学院 图形图像处理研究所,陕西 咸阳712000)
基于分析学生成绩主要影响因素的目的,采用了ID3算法完成决策树的生成。算法包括数据采集、数据处理、绘制决策树、决策树剪枝、去噪和模型准确性评估等阶段。模型选取软件工程专业2012级1班的学生的《JAVA程序设计》课程期末考试成绩和学生的基本情况信息等数据作为训练数据。经过反复训练,模型能够根据输入学生的基本信息分析出学生的学习成绩优,良,差的概率。该决策树准确率为90%,能够满足用户需求,决策树模型符合要求。
ID3算法;MATLAB;决策树;数据挖掘
随着无纸化办公的推进,教务部门积累了大量的学生的电子信息,如学生的学籍信息,学习成绩等数据,但是这些数据主要还是以各种形式的表格保存在存储介质中,没有被充分挖掘背后隐藏的规律。比如,在对学生学习成绩的分析处理仅仅停留在统计成绩优秀、良好、及格、不及格各个等级的人数,而对于学生取得这样成绩的原因没有进行过深究。本次研究中采用数据挖掘中的决策树技术分析影响学生程序设计课程成绩的主要因素,对教学环节进行相应的改进,及时纠正学生在学习中的不良行为,减轻教师工作量,从而提高学生的学习效率,提升学校的教育教学质量[1]。
1 数据处理流程
数据预处理过程通常包含数据集成,数据清理,转换和规约4个步骤[2]。
1.1数据集成
数掘集成是将多个表中数据整理后存放在一个统一的数据表中。本文中,将数据分别放入“学生调查统计表”和“老师调查统计表”中。“学生调查统计表”的包含:学号、性别、年龄、班级、课外练习时间、对本课程的兴趣等属性。
1.2数据清理
在数据中存在一些不符合现实情况的数据,为了提高数据的准确性,需要把不符合实际的数据人为的去除。比如学生的数据某些信息存在空缺,对于这种情况,可以将存在空串的记录删除。
1.3数据转换
将数据转换成离散的值。如1表示上课考勤 “差”,用2表示“一般”,用3表示“好”;用1表示上机练习时间“少”,用2表示“一般”,用3表示“多”;用1表示课程 “不感兴趣”,用2表示“一般”,用3表示“感兴趣”;试卷难度用1表示“低”,用2表示“中”,用3表示“高”;1表示成绩 “差”,用2表示“良好”,用3表示“优秀”。
1.4数据归约
数据归约是在不影响最终结果的情况下对数据集中的数据进行划分,缩小数据规模的过程。根据得到的数据集,经过观察后使用数值压缩方法,得到对学习成绩影响最大的属性。
2 决策树算法
2.1ID3算法
1986年J.R.Quinlan在 Machine Learning Journal发表了题为《Inductionof Decision Trees》的论文,首次提出ID3算法[3]。ID3算法是通过计算每个属性的信息增益,选取具有最高增益的属性作为给定数据集合的测试属性。对被选取的测试属性创建一个结点,并以该属性标记,对该属性的每个取值创建一个分支,并据此划分样本[3-4]。
算法描述
ID3算法具体的伪代码描述(T,C)如下。其中,假设T代表当前样本集,候选属性集用C表示,侯选属性集中的所有属性都为离散型,连续型必需事先经过预处理转化为离散型[3]。
1)创建根节点N:
2)IFT都属于同一个类Cthen返回N作为叶节点,以类C标记;
3)IFC为空
则返回N作为叶节点,标记为T中出现最多的类;
4)ForeachC中的属性,计算信息增益gain;
5)N的测试属性Test_C=C中具有最高信息增益的属性;
6)ForeachTest_C的取值
{
由节点N长出一个新叶节点:
IF新叶节点对应的样本子集T'为空
则不再分裂此叶节点,将其标记为T中出现最多的类;
ELSE
在该叶节点上执行ID3算法(T',T'_C),对它继续分裂;
}
ID3算法优点
ID3算法是通过计算每个属性的信息增益,算法理论清晰简单;每一个结点对应一个分类规则,易于理解;使用ID3算法构建的决策树深度小,分类速度快。
ID3算法缺点
1)该算法的注意力集中在特征的选择上,且计算方法偏向于属性取值数目较多的特征,而这一属性不一定是最优的。
2)ID3只能处理具有离散值的属性,对连续值属性无能为力。如对连续值的属性,必须先对其离散化、取样,而为了这种处理大数据集的算法,不仅增加了分类算法的额外开销,还降低了分类的准确性。
3)ID3算法没有考虑训练集中的缺值问题。
4)ID3在建树时,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
2.2C4.5算法
J.R.Quinlan通过对ID3算法的研究发现ID3算法存在很多不足,在1993年提出了C4.5算法,它是ID3算法的改进算法[5]。由于ID3算法利用信息增益作为分类规则来选取影响最大属性,这将导致该算法容易倾向于选择取值较多的属性。针对这种缺陷,C4.5算法修改了分类规则,用计算信息增益率来取代信息增益作为分类规则[6]。
3 系统设计与实现
系统采用MATLAB平台开发,MATLAB是三大数学软件之一,它在算法开发、数据分析方面有很高的实用性。文中在MATLAB中实现ID3算法,由于ID3算法是单变量决策树,更容易反映出每个属性对成绩的影响,因此确定ID3算法作为建立决策树的算法。
决策树的建立过程主要由两个阶段组成:第一阶段根据数据集绘制决策树阶段。对数据集中的每个属性分别计算的信息增益,然后依次确定每层树中最主要的影响因素,最后采用自顶向下的递归方式来绘制出决策树。第二阶段是根据绘制好的决策树,去掉无效数据,对决策树进行剪枝、去噪声阶段[7]。
3.1数据采集
以软件工程专业2012级1班的学生的 《JAVA程序设计》课程期末考试成绩为基础,挖掘出如学生上课考勤,每周上机练习时间,对本课程的兴趣,试卷难度等因素对学生成绩的影响。
数据采集的内容包括:1)学生的基本情况信息(主要包括学号,性别,年龄,班级);2)学生对课程是否感兴趣、每周上机练习时间等;3)上课考勤记录、期末考试试卷难度、期末考试成绩。
3.2数据处理
通过数据集成,数据清理,转换和规约4个步骤之后学生信息表如表1。

表1 学生信息统计表
3.3决策树模型构建
1)计算分类属性的信息熵。
对成绩进行分类,在23个样本中成绩为1的有4个样本,为2的有5个样本,为3的有14个样本。计算给定样本成绩分类所需的期望信息:
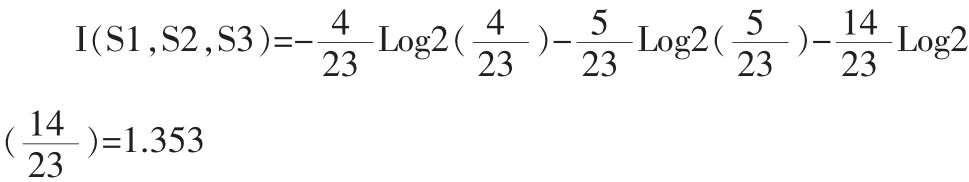
2)计算属性的信息熵。
计算上课考勤属性,它的属性值分别是3、2、1。
上课考勤划分的信息增益:
Gain(上课考勤)=I-E(上课考勤)=1.353-0.667= 0.686。
上机作业时间:
因此,如果样本按照每周上机练习时间划分,对一个给定的样本分类对应的熵为:
每周上机练习时间划分的信息增益:Gain(每周上机练习时间)=I-E(每周上机练习时间)=1.353-0.969=0.384。
以对本课程的兴趣划分的信息增益是:
Gain(对本课程的兴趣)=I-E(对本课程的兴趣)=1.353-1.151=0.202。
计算得到相应的信息增益值分别是:
Gain(上课考勤)=I-E(上课考勤)=1.353-0.667=0.686。
Gain(每周上机练习时间)=I-E(每周上机练习时间)= 1.353-0.969=0.384。
Gain(对本课程的兴趣)=I-E(对本课程的兴趣)=1.353-1.151=0.202。
对本课程的兴趣为“感兴趣”,“一般”,“不感兴趣”进行信息增益计算,得到学生成绩分析决策树,如图1所示。

图1 学生成绩分析决策树
3.4决策树修剪
对已经绘制好的决策树进行剪枝,用剪枝来解决数据匹配问题。剪枝有两种基本策略,一种是预先剪枝,另一种是后剪枝。预先剪枝在生成树的过程中对数据进行判断,以决定下一步是继续划分还是停止;后剪枝是生成一个与数据集相同的一棵树,然后从叶子结点开始一个一个慢慢向树根剪枝[8]。如果剪去某个叶子节点对数据准确度没有影响就剪去该叶子节点,如果有影响就马上停止。图2为使用后剪枝所绘制出来的决策树。可以明显看到只保留对学习成绩影响最大的属性值。

图2 修正后的决策树
3.5模型准确性评估
通过已经构建完成的学习成绩决策树,选择了软件工程专业2012级2班的学生的成绩作为测试数据,通过决策树,分析出学生期末考试成绩等级,然后与实际情况相比较来判断该决策树是否有效。经过调研及分析,确定准确率最小值是84%。经过实际测试,该决策树准确率为90%,超过了预定的准确率,能够满足用户需求,该决策树模型符合要求。
4 结束语
对决策树技术在高校学生成绩分析中的应用研究中,使用了ID3算法建立模型。在算法实现中经历了数据的采集与处理,决策树模型的建立等过程。建立模型时,通过分析上课考勤,每周上机练习时间,对本课程的兴趣以及试卷难度四个因素,选择具有最大信息熵的属性作为根节点,每确定一个根节点就必须再次计算最大信息熵,从而再次确定新的根节点,经过多次计算和递归调用,生成学生成绩分析决策树。通过测试数据的验证,该模型能根据学生的学习兴趣,考勤情况,上机练习时间和试卷难度预测出学生学习成绩。
[1]赵红艳.决策树技术在学生成绩分析中的应用研究[D].济南:山东师范大学,2007.
[2]邵峰晶,于忠清.数据挖掘原理与算法[M].北京:中国水利水电出版社,2003.
[3]Quinlan J R.Induction of decision trees[J].Machine Learn-
[4]林向阳.数据挖掘中的决策树算法比较研究[J].中国科技信息,2010(2):94-95.
[5]毛国君.数据挖掘原理与算法[M].北京:清华大学出版社,2007:122-128.
[6]Quinlan J R.C4.5:Programs for Machine Learning[J].Machine Learning,1993(16):235-240.
[7]白雪.决策树分类算法的研究及其在教学评估中的应用[J].电脑开发与应用,2007,20(2):24-26.
[8]胡江洪.基于决策树的分类算法研究[D].武汉:武汉理工大学,2006.
Application of the decision tree analysis technique in scores of programming course
LIU Min-na1,2
(1.Xianyang Normal University,College of Information Engineering,Xianyang 712000,China;2.Xianyang Normal University Institute of Graphics and Image Processing,Xianyang 712000,China)
Based on the analysis of the main influence factors of students'performance,the ID3 algorithm is used to accomplish the decision tree.Algorithm consists of data acquisition,data processing,drawing decision tree,decision tree pruning,to noise and the accuracy of the model evaluation.Model selection of software engineering 1 class 2012 students of the"JAVA program design"course final exam results and students'basic information and other data as training data.After repeated training,the model can be based on the basic information of the students to analyze the students'learning performance,good,poor probability.The accuracy rate of the decision tree is 90%,which can satisfy the needs of users,and the decision tree model meets the requirements.
ID3 algorithm;MATLAB;decision tree;data mining
TN-9
A
1674-6236(2016)09-0042-03
2015-10-20稿件编号:201510131
陕西省教育厅专项基金资助项目(15JK1803);陕西省科学技术研究发展计划项目(2013JM8037);咸阳师范学院专项科研基金项目(14XSYK036)
刘敏娜(1981—),女,陕西榆林人,硕士,讲师。研究方向:CUDA并行计算,机器学习。
