基于MP3格式的语音隐写算法
2016-09-14敖珺,李睿,张涛
敖 珺,李 睿,张 涛
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
基于MP3格式的语音隐写算法
敖珺,李睿,张涛
(桂林电子科技大学 信息与通信学院,广西 桂林541004)
为了解决基于Huffman编码的MP3隐写算法隐藏容量较小的问题,提出了一种基于MP3格式的语音隐写算法。该算法在MP3隐写算法的基础上增加了10对Huffman码字,将信息隐藏在MP3编码中的大值区内。引入大容量MP3比特流音频隐写算法,该算法可以与MP3隐写算法在互不影响的前提下完美结合。实验结果表明,该算法增加了隐藏容量,而算法的透明性和码字的统计特性并无太大的差异。
Huffman编码;MP3编码;大值区;信息隐藏
随多媒体技术和互联网的快速发展,信息安全得到越来越多的重视。信息安全包含信息加密和信息隐藏两大分支。加密信息在传递的过程中很容易被攻击者发现,即使在无法正确解密的情况下,也可以破坏信息的传递,因此安全性较低。而信息隐藏技术可以达到传输秘密信息不易被发现的目的,所以安全性高,受到人们越来越多的关注。目前基于图片的信息隐藏技术已很成熟,使得人们将隐藏信息的载体转向音频。MP3是MPEG1 Layer-3音频文件,压缩率为10∶1甚至12∶1,是目前最为流行的一种音频格式。由于MP3的压缩率和保真性都非常高,研究MP3如何应用于音频隐藏信息[1]中具有非常重要的意义。现如今,基于MP3的信息隐写算法比较少,主要因为MP3的编解码特性使得嵌入信息非常复杂,而且冗余少,很容易在嵌入信息后对音质造成较大影响,从而未能达到隐蔽通信的目的。目前,一些有效的隐写算法陆续被提出。例如,宋华等[2]深入研究了MP3Stego算法,该算法通过改变part_2_3_length[3]的奇偶性来隐藏信息,但是信息嵌入量非常小,而且现在针对该算法的检测方法也很成熟;高海英等[4]提出了基于Huffman编码的MP3隐写算法,即通过改变部分Huffman码字达到信息隐藏的目的,该算法透明性高,嵌入量比较大,并且在不清楚具体码对的情况下能达到绝对的安全;刘秀娟等[5]提出了一种大容量MP3比特流音频隐写算法,即查找可以嵌入的小值区码字,按照相应的嵌入规则修改对应码字以嵌入信息,该算法嵌入量远大于MP3Stego算法,同时透明性也较高,且能够抵抗对MP3Stego的隐写分析算法;董亚坤等[6]提出了基于MP3哈夫曼码字linbits的隐写算法和基于MP3哈夫曼码字符号位的隐写算法,这2种算法只需对MP3进行部分解码,计算简单,复杂度低,并且具有嵌入容量大,实时性高以及良好的透明性和安全性等优点。
为此,在文献[4]算法基础上,增加了10对符合要求的霍夫曼(Huffman)码字,又将文献[5]中的算法成功融合进去,使得改进算法的隐藏容量远大于原算法,而算法的透明性和码字的统计特性并无太大的差异。目前,MP3隐写算法和改进后的算法均已用软件(Windows XP和Windows 7,Microsoft Visual Studio 2012平台)成功实现。
1 预备知识
1.1MP3编码原理
基于Huffman编码的MP3隐写算法均建立在MP3编码原理[7]基础上,MP3编码过程如图1所示。

图1 MP3编码Fig.1 MP3 coding
MP3(单声道为例)编码过程:原始PCM数据以每1152个采样值为一帧来处理,一帧分为2个粒度组,每个粒度组576个值。PCM数据分为2路,一路通过子带滤波和MDCT[8]变换后,得到576个相同间距的频域系数,然后将频域系数根据模式进行声道的模式处理。另一路经过心理声学模型[9]得到整个频域上的信掩比,并以此对频域样值的量化进行指导,使得量化噪声尽可能分布在人耳不易察觉的频带中。2路PCM数据处理结束后,对频域系数进行量化和编码。经过量化后的频域系数分为3个区域:高频段的一串零值的区成为“0区”,不编码;中频段由量化后的值0,1或-1组成“小值区”,以4个为一组进行编码,小值区对应2个霍夫曼码表;剩余低频段的量化值组成“大值区”,该区数值比较大,以2个为一组编码,大值区对应32个霍夫曼码表。MP3编码的最后一步是将帧数据流格式化,即根据MP3标准规定的码流格式,将帧头、帧边信息和主数据等有关信息组成适合于MP3解码的帧。
主数据由比例因子(scalefactor)和霍夫曼码字(Huffman code)组成。具体的主数据内部结构如图2所示。

图2 主数据内部结构Fig.2 Internal structure of main data
从图2可看出,大值区和小值区分别位于不同的频段,而基于Huffman编码的MP3隐写算法将信息隐藏在大值区,大容量MP3比特流音频隐写算法将信息隐藏在小值区,这为算法改进提供了理论依据。
1.2基于Huffman编码的MP3隐写算法
该算法通过改变部分Huffman码字实现信息隐藏,而且在听觉效果上与载体MP3并无差异。
1.2.1信息的嵌入
搜索每帧中符合嵌入要求的Huffman码字h,如码字长度为8的一对码字0x1a和0x1f,嵌入信息后的码字为H,码字长度为L,嵌入信息为W,具体嵌入方法为:

(1)
嵌入秘密信息后,原来的码字h被H代替,接着进行编码生成携密MP3。
1.2.2信息的提取
在携密MP3中搜索码字长度为8的码字0x1a和0x1f,具体的提取方法为:
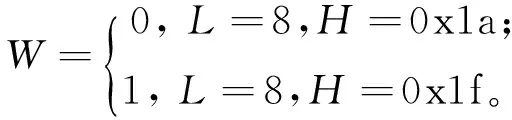
(2)
1.3大容量MP3比特流音频隐写算法
在小值区,Huffman码流格式如图3所示,其中小值区系数编码后的码字为H,4个小值区系数中不为零的符号为A、B、C、D(每个符号位占1 bit)。

图3 Huffman码流格式Fig.3 Huffman stream format
由小值区码流格式和Huffman码表可知,汉明距离L(L=1,2或3)相等的4个小值区系数,编码后的Huffman码字及符号位的总长度也相等,即在MP3比特流中所占的位数相等,其中,码表Ha中的{0,1,0,1}和{1,0,1,0}除外。这也是该算法能成功的重要前提。
1.3.1信息的嵌入
以码表Ha为例,符合要求的Huffman码字有12个,将其分为2个集合:v={0101,0100;00101,00011;000100,000010}和V={0110,0111;00100,00111;000000,000011},将v和V中的码字分别表示信息比特0和1。信息嵌入时,先找到属于v和V的码字,再依据具体嵌入的信息决定保持或修改码字。若修改,则一定是对应另一个集合中的等长码字。正是因为这种修改规则,所以该算法的信息嵌入方式也称为“码字映射替换规则”。
码表Hb的情况类似,符合要求的码字有14个,具体的码字映射替换规则如图4所示。

图4 码表Hb的码字映射替换规则Fig.4 Code mapping substitution rule of code table Hb
1.3.2信息提取
信息提取的具体方法为:
1)打开携密MP3,并进行解码。
2)帧同步,读取帧头信息、帧边信息及解码比例因子系数。
3)根据解码出的帧边信息选出大值区的Huffman码表,查找大值区,直至大值区结束。
4)选出小值区的Huffman码表,并搜索小值区中属于v或者V中的码字。若搜索到的码字属于v,则嵌入信息W=0;若属于V,则W=1。
5)重复执行2)~4),直到提取的隐蔽信息大小与嵌入时的相等。
2 基于MP3格式的语音隐写算法
基于MP3格式的语音隐写算法是在基于Huffman编码的MP3隐写算法基础上,分两步进行了改进。第一步是在原算法基础上新增符合嵌入要求的Huffman码对,第二步再将大容量MP3比特流音频隐写算法融入。
2.1Huffman码对的增加
文献[4]详细介绍了基于Huffman编码的MP3隐写算法,且通过实验获取了13对符合嵌入要求的码字,但是也强调了满足要求的码字还有很多。所以为了增加信息的嵌入量,又通过大量的计算和实验,找到了10对新的符合要求的码字,并且成功在软件上实现。
新的Huffman码对如表1所示,以下是符合嵌入要求的Huffman码对的选取方法。

表1 新的Huffman码对
符合嵌入要求的码对必须等长。若载体码字为4 bit,则嵌入信息后的码字也必须为4 bit。
MP3标准中包括34个码表,其中前32个码表适用于大值区[10]。符合嵌入要求的码字的选取必须成对,且每对码字要在相同的码表中。
符合嵌入要求的码字对应的x或y中不能出现0,若载体码字对应的x为0,嵌入信息后的码字对应的x为1,则在译码过程中就会多读取一个符号位,这就导致比特流错位,译码出现错误。
符合嵌入要求的码字对应的x、y要相近。如长度为8的码字0x3d、0x33、0x2a,其中码字0x3d对应的x=1,y=6;码字0x33对应的x=1,y=7;码字0x2a对应的x=2,y=8。在此情形下,要将0x3d和0x33选为码对,不能将0x2a和0x3d选为码对,在较大程度上减少数据的差异。
2.2大容量MP3比特流音频隐写算法融合
文献[5]的算法嵌入容量大,透明度较高,目前还无有效方法检测出隐藏的信息,关键是它在小值区进行信息隐藏。由于大值区和小值区为2个不同频段的区,因此,该算法与MP3隐写算法互不影响,可以完美融合,既可以增加嵌入量,又对透明性和码字统计量不产生明显影响。
改进算法的实现流程如图5所示,嵌入信息的具体步骤(单声道为例)为:
1)选定载体MP3文件,设i=0,n为密文比特数,N=n+16(其中16表示存放密文的大小)。
2)解码MP3文件,搜索大值区符合嵌入要求的Huffman码字,嵌入1 bit信息使得i+1。若i=N,则返回“嵌入完毕”,结束信息嵌入过程,否则,再判断载体文件是否结束,若结束,则返回“载体文件太短”,结束信息嵌入过程,否则,判断大值区是否结束。
3)若大值区未结束,则重复执行步骤2),否则,继续执行步骤4)。
4)搜索小值区符合嵌入要求的码字,嵌入1 bit信息使得i+1。若i=N,则返回“嵌入完毕”,结束信息嵌入过程,否则,再判断载体文件是否结束,若结束,则返回“载体文件太短”,结束信息嵌入过程,否则,判断小值区是否结束。
5)若小值区未结束,则重复执行步骤4),否则,循环到下一粒度组,重复执行步骤2)。

图5 改进算法的流程图Fig.5 Flow chart of the improved algorithm
3 改进算法的性能分析
3.1隐藏容量对比分析
改进算法隐藏容量的大小由两部分决定,即大值区特定的码字和小值区特定的码字。而对于不同大小的载体MP3文件,特定码字的个数也不尽相同,所以在隐藏信息之前需对载体MP3文件的隐藏容量进行判断。若隐藏信息的比特数超过了最大的隐藏容量,则需要另行处理。
表2为试验载体MP3文件在原算法和改进算法下的隐藏容量对比。

表2 隐藏容量
从表2可看出,改进算法的隐藏容量相比原算法的隐藏容量增加了3.5~7倍,使隐藏容量得到了较大的提升。
3.2透明性对比分析
文献[4]通过分段平均信噪比[11]判断透明性的好坏,人耳可察觉信噪比的阈值为66 dB。通过实验求出隐藏信息后音频的平均信噪比为67.48 dB,所以人耳无法觉察音频失真。
改进后的算法利用文献[11]的方法对算法透明性进行分析,具体过程为:

(3)
其中:
(4)
(5)
(6)
根据式(3),通过实验求得105帧的隐藏信息后音频的平均信噪比为66.52 dB,比MP3隐写算法的透明性稍差,但在人耳可察觉阈值之上(即大于66 dB),所以人耳也无法觉察音频失真。
3.3新增加码字统计量分析
改进的隐写算法做了2步改进,第一步是在原算法基础上增加了新码对,第二步再将大容量MP3比特流音频隐写算法融入。又因为第二步是作用在小值区,所以对大值区中的Huffman码字统计量并无影响。
根据原算法的嵌入原理可知,隐藏信息后必定会对Huffman码字有所修改,导致修改前后的码字统计分布发生变化。文献[4]分析了隐藏信息前后的码字统计量的变化,所以只需分析隐藏信息前后的新增加码字统计量的变化。嵌入隐蔽信息前后使用的新增加码字统计量的变化如图6、7所示。
从图6、7可看出,嵌入隐蔽信息前后使用的新增加码字统计量的变化并不大,因此,虽然增加了10对新的码字,但在码字统计量的变化上与原隐写算法基本无异。

图6 载体码字的分布Fig.6 Distribution of vector code

图7 携密文件码字的分布Fig.7 Code distribution with confidential documents
4 结束语
提出了一种基于MP3格式的语音隐写算法,该算法在Huffman编码的MP3隐写算法的基础上,通过增加新Huffman码对和将大容量MP3比特流音频隐写算法融入,实现了算法的改进。实验结果表明,与原算法相比,改进的算法在隐藏容量上得到了较大提升,而在听觉效果和码字统计量上基本无异,所以,改进的算法具有更大的实用价值。并且以上各类算法都已用软件全部实现,后续研究将进一步探讨码字统计的补偿方法和改进算法的应用领域。
[1]PETITCOLAS F A P,ANDERSON R J,KUHN M G.Information hiding a survey[J].Proceedings of the IEEE,1999,87(7):1062-1078.
[2]宋华,幸丘林,李伟奇,等.MP3Stego信息隐藏与检测方法研究[J].中山大学学报(自然科学版),2004,43(增刊2):221-224.
[3]江洪.MP3解码程序开发[J].电脑编程技巧与维护,2014(1):20-24.
[4]高海英.基于Huffman编码的MP3隐写算法[J].中山大学学报(自然科学版),2007,46(4):32-35.
[5]刘秀娟,郭立.大容量MP3比特流音频隐写算法[J].计算机仿真,2007,24(5):110-113.
[6]董亚坤.基于MP3的信息隐藏技术研究[D].北京:北京邮电大学,2015:8-9.
[7]蒋学鑫.MP3实时编解码系统的研究与开发[D].成都:电子科技大学,2007:9.
[8]李晓飞.Huffman编解码及其快速算法研究[J].现代电子技术,2009(21):102-104.
[9]张力光,王让定.心理声学模型及其在MP3编码中的应用[J].宁波大学学报(理工版),2010,23(3):27-31.
[10]SHLIEN S.Guide to MPEG-1 audio standard[J].IEEE Transactions on Broadcasting,1995,40(4):206-218.
[11]赵春晖,李福昌.数字音频水印技术:回溯与展望[J].哈尔滨工程大学学报,2002,23(6):57-61.
编辑:梁王欢
Voice hiding algorithm based on MP3 format
AO Jun, LI Rui, ZHANG Tao
(School of Information and Communication Engineering, Guilin University of Electronic Technology, Guilin 541004, China)
To improve hidden data capacity of MP3 hiding algorithm based on Huffman coding, a voice hiding algorithm based on MP3 format is presented. The algorithm adds ten pairs of new Huffman codes based on the original algorithm, the information is hidden in big value region in MP3 coding. High capacity audio steganography in MP3 bit streams is introduced. The algorithm can be combined with the above algorithm. Experimental result shows that the hidden data capacity of the algorithm is increased. The imperceptibility and statistical characteristic of the codes are almost same.
Huffman coding; MP3 coding; big value region; information hiding
2016-02-21
国家自然科学基金(61167006);广西认知无线电与信息处理重点实验室主任基金(CRKL150106)
敖珺(1978-),女,广西桂林人,教授,博士,研究方向为通信信号处理、光通信。E-mail:junjunao1@263.net
TP393
A
1673-808X(2016)04-0315-06
引文格式:敖珺,李睿,张涛.基于MP3格式的语音隐写算法[J].桂林电子科技大学学报,2016,36(4):315-320.
