基于多层图划分的云环境软件部署管理算法
2016-09-12戴伟刘华
戴伟,刘华
(1. 华中科技大学 管理学院,湖北 武汉,430074;2. 湖北理工学院 经济与管理学院,湖北 黄石,435003)
基于多层图划分的云环境软件部署管理算法
戴伟1,2,刘华1
(1. 华中科技大学 管理学院,湖北 武汉,430074;2. 湖北理工学院 经济与管理学院,湖北 黄石,435003)
针对在云服务器上软件构件分配时需要最大限度地减少所需带宽的问题,提出一种基于多层图划分算法的混合算法,来解决云计算环境中的软件部署问题。该算法对重边匹配(HEM)算法进行改进,同时添加1个新的约束条件来进行粗化,且使用类似KL的算法进行细分,最后结合退火算法从而实现对图划分算法的重新设计和评估。与传统的图划分相比,本文提出的算法考虑到基础设施的异构性,因此不局限于平衡划分。实验仿真结果表明:相比传统的KL图划分算法,提出的混合算法在执行时间和求解质量之间取得很好的平衡,综合性能优于传统算法。
云计算;图划分算法;退火算法;软件部署
当今,云计算的出现促进了效用计算[1]新模式的产生,即根据需求提供计算能力。用户能够通过互联网来使用应用程序并进行存储及处理。与维护自己的私人电脑系统相比,新的终端模式的优势是成本更低、扩展性更高及性能更高,因此,其适用于计算负载较高的情况。使用云计算对基于Web的应用程序是有利的,而且也可以用于其他由很多服务组件组成的应用程序,这些服务组件遵循服务型的编程范式。对于中央处理器(CPU)功率或内存消耗而言,一些服务组件的需求量很大,因此,应该在云中的专用服务器上运行这些服务组件,而不是在普通台式电脑或移动终端运行,例如目标识别中的识别组件或语音文字转换应用程序。云计算的广泛应用就会带来软件部署这一问题。在云计算环境里可以将软件构件从移动设备上传到云服务器,即将软件应用程序部署到云基础设施上,但是这种应用会显著增加网络流量。在均匀适度规模的数据中心内,就可用的硬件节点而言,有很多选项需要进行考虑。为了降低成本,云客户和云供应商都十分需要通过部署优化把所有组件都要部署在具有强大工作性能的服务器上,同时最小化不同机器间的通讯开销,但是这一过程会导致额外的延时和网络负载。针对这一问题可以构建1个图划分模型,把软件组件的加权图划分成若干份,用这些分区表示可用的机器[2]。此外,优化部署会随着时间改变,因此,迫切需要找到一种快速算法来实现优化部署。本文作者提出一种能够有效降低组件之间的通信成本,并同时实现划分软件应用程序的算法。这种软件应用由若干组件组成,位于云中若干相互连接、具有不同容量的机器上。对算法的性能和执行时间,与不同的算法进行评估和比较,并讨论不同参数的影响。本研究把重点放在本次评估中含有100~1 000个组件的图上。
1 原理介绍
1.1 图划分原理
在计算机科学的很多领域,图划分是一个基本的问题,例如超大规模集成电路(VISI)设计、并行处理与负载平衡[3]。图划分问题能够解决在 k等集中的图分割问题,同时最小化等集间的边权。当k=2时,称作是最小分割对分问题。
第1种算法就是所谓的移动型算法,这种算法尝试通过在划分区之间移动顶点或交换顶点迭代改进划分[4]。通过加入顶点移动选择降低图切割的成本,这种算法会收敛到局部最优。FIDUCCIA等[5]为KL算法引进了若干个最优解并产生了图划分的线性时间算法。移动型算法能够与随机算法结合,如模拟退火算法,粒子群优化算法或为脱离局部最优解的蚁群优化算法。迭代改进方法的最大劣势是其性能会随着图的变大而恶化。
人们已经广泛使用多层次划分方法来划分大图。主导思想是:根据匹配通过合并顶点迭代的方法使原始图粗化,直到最后留下一个具有相似结构的小图。然后可以用拟谱方法或贪婪型图增长方法对这个小图标进行划分。接下来对粗化的图再次迭代细化。在每个层次中都使用了局部改进启发法如 KL算法[6]。图划分的近期工作是以扩散或最大流量为作为研究重点。已知技术间的组合也能够产生新的启发法。CHARDAIRE等[7]结合贪婪算法、遗传算法和KL优化算法,并使用了基于群数加强优化(PROBE)的启发法。ZAMPROGNO等[8]提出了贪婪图增长启发法,这种启发式结合了局部优化算法。MARTIN[9]使用了由拟谱方法和KL优化算法改进的遗传法。
这些方法都可以把图划分成预先设定好的块数且每块大小相同。但是在云计算背景下,并非所有的机器都有同等的能力,使用的机器数量也不是预先设定好的,因此,这些算法也不能随时使用。本文提出的算法把若干可用的具有不同能力的机器作为输入的唯一约束条件,任何机器都不能超过这种约束条件的最大能力并且每台机器上恰好部署1个组件。同时,仍旧可以使用原始图划分问题的思想,对1个优化部署进行计算。
1.2 网格上的任务分配
在网格计算背景下,可以使用图划分问题对异构基础设施上的并行任务进行划分。很多已提出的算法如MiniMax,VHEM,QM,PaGrid和MinEX结合优化算法使用多层次划分算法,而其他的算法如PART[10]使用了模拟退火法。
所有的算法都是把重点放在以网络模型为基础的并行应用程序上,如流体动力学,把1个大任务分解成较小的平行小任务,网格中的每个处理器执行1个小任务,目的是为了以后尽可能快地执行这些任务,因此,要将速度最慢的节点的执行时间最小化。在本文提出的问题中,执行时间的指标没有什么意义,因为把重点放在了云应用程序上,只要终端用户开始使用程序,这些程序的组件就会产生负荷。网格中任务图的结构也是以输入网为基础的,而就本文提出的方法而言,云应用程序的图是以软件组件和它们之间的相互作用为基础的。
设定G=(V,E)为无向图,V={v1, v2, …, vN}为N个顶点的集合,E为与顶点连接的所有边的集合。顶点代表在分布式软件系统中部署的组件,边代表这些组件之间的通信费用。每个顶点 vi设定 1个成本值 wj代表此顶点组件所需的资源量(如 CPU处理能力)。C=cij为G的邻接矩阵,例如,如果vi和vj之间存在边,那么cij等于这条边的权值,否则cij=0。边权值代表不同软件组件之间的通信费用(例如带宽)成本。
设定S=(K, L)为基础设施的无向图,K为可用的机器集合,L为不同机器间的链接。每个机器都有最大的能力Xm,每个链接都设定1个成本值便于使用此链接。从这个图中可以推导出矩阵B=(bmn),bmn代表机器m和机器n之间交换数据的成本。
此时的目的是把每个顶点 vi分配给其中 1台机器,这样机器间的交换的总数据加权通过B将最小化。更正式的方法是,决策变量 Tim代表图切割。如果组件i部署在机器m上,那么Tim等于1,否则Tim为0。为让部署在不同机器间的节点之间的边权值总和最小化,需要引进变量hij,当组件i和j部署在不同的机器上,hij等于1,否则为0。这样目标函数最小化就变成了图切割(GC)的权值:
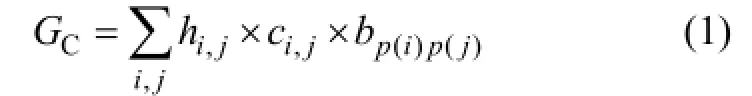
函数P(j)返回到顶点j所部属的机器上,变量hij可以用Tim表示为
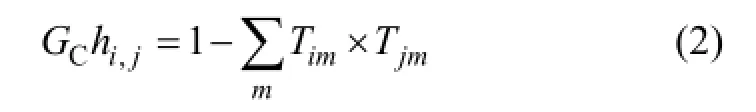
还需要2个约束条件,对本文提出的问题进行描述。
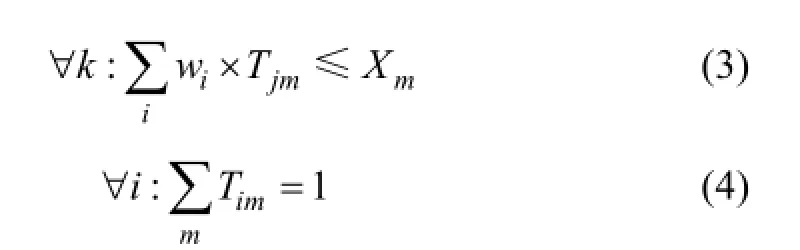
式(3)表示的是在1台机器上节点所使用的资源总量,但资源总量不能超过这台机器的最大能力。式(4)确保了在每台机器上部署1个节点。
2 提出的混合算法
由于模拟退火法(SA)的随机因素,因此它通常探索的解空间比以KL为基础的优化算法要大得多,这样就会以耗费更多的计算时间才能得到最优解。因此,本文结合了这2种方法,混合算法与多层次算法非常相似:仅在最粗化阶段,第1次把划分和SA的一些操作优化。在最粗化阶段,使用SA可以找到最优解,而额外的计算代价仍然相对较低。在进一步细化迭代中,再次使用KL优化算法,这样细化过程比较快。此外,由于粗化和细化的特征,预计在邻近最粗化图时会出现全局最优解,因此,KL算法最终得到的局部最优解更可能也是全局最优解,而且在最粗化阶段,多次使用SA优化是为了得到更好解。
2.1 多层图形划分算法(MLKL)
前面所述问题可看作是整数线性规划(ILP)问题,因此,可以用ILP求解器(IBM ILOGCPLEX)找到这个问题的最优解。解决此问题所需要的时间和资源的数量会随着图的大小呈几何方式增长,因此,需要用启发法更快地寻求一个好的解决方法。本文仍可以使用针对较小图设计的ILP解决方法来对本文提出的算法进行基准测试,但这可能需要承担最优性的费用。
本文使用了由HENDRICKSON等[11]提出的多层次优化方法。即合并相连的顶点对图进行粗化,最后得到1个小图。然后再次划分并细化小图,同时在每个细化阶段都要进行最优化划分。划分包括3个阶段。
1) 粗化阶段:粗化图G生成一系列较小的图G1,G2,…,Gm,得到的顶点|V1|>|V2|>…>|Vm|。
2) 初始划分阶段:在最粗化的图基础上计算划分P。
3) 细化阶段:通过所有中间一系列图,把图 G中的划分P映射回原图。为得到更好地划分,每一个细化阶段都要使用优化算法。
2.1.1 粗化阶段
在粗化阶段,从图Gi开始,通过折叠边及合并与其他边连接的顶点得到图Gi+1,此时图Gi+1的顶点较少。当折叠1条边的时候,与这条边相连接的两个顶点会变成1个顶点,此时这个顶点的权值是折叠前2顶点的权值之和。当2个顶点之间有1条连接到第3个节点的边,这2条边会折叠成1条边且此时这条边的权值是这两条边的边权值之和。每次粗化迭代时,匹配都会产生无公共顶点边的集合,然后合并匹配的顶点,为了得到最小切割边,需要折叠很多带权值的边,因为这些切割边可能不是最好的切割边。
粗化算法使用了重边匹配(HEM)算法。该算法是由KARYPIS等[12]提出并得到广泛使用的粗化方法。即采用随机顺序访问图的顶点,每个顶点u会与1个未被匹配的邻接点v相匹配,最后得到的这条边(u,v)就具有最大权值,这一权值超过其他与顶点u相关连的边权值[13-15]。当顶点权值和小于最小分区的尺寸,为了能够映射出不同机器上的最大图的顶点,又添加了1个新的约束条件与这2个顶点相匹配。
2.1.2 初始划分阶段
经过粗化,现在的问题是对基础设施上的软件组件进行可行性的部署选择。假设已有足够的机器和资源满足条件。此时,问题即可简化为1个简单的装箱问题并且可以用首次适应算法来解决。
通过降序排列顶点权值对顶点进行排序,降序排列机器的最大能力对机器进行排序。对于每个顶点来说,机器列表都是迭代过的,然后把顶点分配到第 1台剩有足够能力的机器上,此后这台机器的能力就会随着这个顶点的权值减弱。
算法1计算初始化分的伪代码如下:

2.1.3 细化阶段
在最后阶段,再次逐渐将图细化,并使用KL优化算法改进在先前阶段中得到的初始划分。该算法是建立在HENDRICKSON等[11]提出的优化算法基础之上的。即移动1个顶点到1个不同的组件相关联的增益概念。这种增益可以反射出切割尺寸的净变化,这种变化是由于把顶点从一台机器移动到另一台机器造成的。也就是说,增益是在顶点vi从机器m移动到机器n的过程中加入的。相关增益kmn表达如下:

当函数p(j)再次返回到当前顶点j的位置,使用改进的KL基础优化算法进行处理,这种算法由2遍循环组成。每遍外循环都会试图移动周围的顶点以此找到更好的切割方式。在一遍到目前为止对最好划分没有任何改进的循环之后,新一遍循环也会结束,这暗示着此算法达到了局部最优。为避免此算法陷入无限循环,在单次外部循环过程中1个顶点只能移动1次。内循环会迭代选择1个顶点让其移动,例如具有最大增益却受某些条件管制的顶点,但注意这也可能是 1个负增益的移动。在一定程度上负增益的移动会让此算法有脱离陷入局部最优的可能性。当1个顶点移动的时候,这个顶点的所有邻接点的增益也会更新。当找不到更合适的移动时,此过程就会结束。
算法2 KL优化算法伪代码如下:

选择不在移动列表中的且具有最高增益kmn的顶点,并让其移动;
If (θ(p)<0 && θ(n)-wi>θ(m))
正确→找到更合适的移动
If (∃p: θ(p)<0) /* θ(p)表示P划分区自由空间的数量 */
else
正确→找到更合适的移动
}
If (找到更合适的移动)
进行移动并把此移动添加到移动列表中;
更新已移动的顶点的邻接点的增益;
If (当前划分<最好划分)
当前划分→最好划分;
If (如果没有合理的正增益移动)
break;}}
Return 最佳划分
当找到1个最好的划分方式,内循环只接受正增益的移动,然后进行下一遍循环。基本原理是:将这种算法找到1个最好的划分方式,以此得到局部优化,然后开始新的迭代,在先前迭代移动列表中出现的顶点移动可以再次被选择作为新迭代的顶点移动。
图1所示为符合选择条件的局部优化。需确保没有机器超负荷,而不是建立平衡划分。在这方面,1个不正确的做法是阻止顶点移动,这样会违反目标的能力条件。然而,这个规则会导致移动对局部优化造成无法避免的影响(见图1)。
因此,允许顶点移动到1个超过最大分区权值的分区,条件是再也没有其他的权值过大的分区。如果分区s具有很多权值,那么选择具有最高增益的顶点,然后把它从机器m中移走并降低负荷量。符合选择条件的局部优化如图1所示,此方法也会收敛到1个最优解(m0={n0, n2},m1={n1, n3, n4})。

图1 符合选择条件的局部优化Fig.1 Suitable selection conditions of local optimization
当两个合理的移动具有相等的增益时,选择没有超过目标分区边界的移动。若不能区分出合理的移动,则选择对分区来说非空白的移动。若仍旧不能区分出这2个移动,则局面随机就会被打破。
不再继续进行移动,直到对所有的顶点进行移动,便可以尽快终止这种算法以节约时间。通过截止阈值的合理选择能够降低执行时间,同时也不会耗费太多求解质量。如果选择截止阈值 0,这种算法就不会接受任何带有负增益的移动,而且会表现得像最陡下降算法一样,在最接近的局部最小值处终止。
2.2 模拟退火法(SA)
用于解决K划分问题的第2种方法是建立在模拟退化法(SA)基础之上的,组合优化技术由KIRKPATRICK等[16-17]提出。为了在K划分问题的背景下使用SA技术,受JOHNSON等[18]的启发,本文把SA技术作为拼装后的优化技术。JOHNSON等[18]验证了SA对于图对分问题的有效性。
SA算法通过把顶点从一个分区移动到另一个分区的方式把自己从一个解决方法移动到邻近的解决方法。带有概率经验值(g/T)的移动会被接受,在(g/T)中,如在其中的描述,g为移动增益,T为温度,它会随着时间渐渐降低。为了找到上节描述条件下的最优解,需要把带有正增益的顶点 i移动到具有概率经验值exp(θ(p)-wi/T)但没有足够能力的分区上,θ(p)为在分区p上的自由空间的数量。这一移动也需要依赖温度。这就确保了在算法快要结束时,无需过度占用分区就可以收敛到1个有效解。
SA的性能主要依赖不同退火参数的设置,退火参数包括初始温度T1、冷却进度表、时长长度L和终止条件。PARK等[19]提出了一个更好的退火参数集,在其基础之上本文作者进行如下改进。
2.2.1 初始温度T1
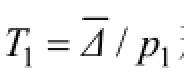
2.2.2 温度冷却
冷却功能会渐渐把温度降低,直到这种算法达到其终止条件。本文采用一个简单的几何冷却功能,在几何冷却功能中,由Tk=α×Tk-1给出在k时期的温度,α(0<α<1)为冷却比。JOHNSON等[18]验证了其他不会影响性能的冷却函数,如线性函数或对数函数。
时长长度L指的是尝试在每个温度层次上移动的次数。本文把每个顶点移动到其他的机器上,因此,时长长度L=s×N×(M-1) (其中,N为顶点的个数,M为使用的机器的数量)。试验证明:对于s来说,选取50较合适。
算法3模拟退火法伪代码如下:
While (满足终止条件)
{
While (计时器≥L(时长))
{
计数器++;
计算把顶点i移动到分区p的增益g;
If (g≥0)
{
If (θ(p)≥wi)
执行移动;
else
}
else
If (θ(p)≥wi)
进行移动;
If (当前划分<最好划分)
当前划分→最好划分;}}
Return 最佳划分
2.2.3 终止算法
终止条件决定算法何时达到冻结状态以及何时终止进一步研究解决方法。当时间计数达到了预先设定的最大值或当温度下降到预选的最终温度以下时,一些终止条件会终止这种算法。本文作者使用了JOHNSON的终止规则[18],即在时长结束时增加1个计数器。当计数器达到预定的终止极限I时,模拟退火法就会终止,计数器会重置为0。
表1显示的是使用的SA细化算法中采用的模拟退火法参数,这些参数参照文献[18-19]中的实验设置。其中,p1为衰减参数,s为分区数量,α为冷却比,I为计数器预定的极限值。
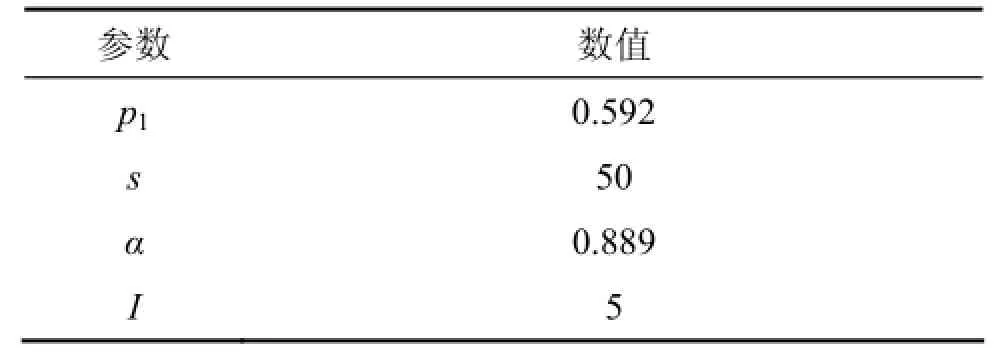
表1 SA细化算法参数值设置Table 1 Parameters settings of SA refinement algorithm
3 算法结果评估
用产生的含有不同大小节点的测试图对本文提出的算法进行评估。图由EPPSTEIN等[20]提出的幂率生成器生成,并且根据参数λ分别是0.1和0.005的指数分布指定节点和边的权值。虽然实际应用程序的图结构依赖于软件设计,但是依照大多数的设计原则选取这些图配置,目的是为了减少不同软件组件之间的依赖性,因此,产生具有节点少、邻接点多的图。产生的节点权值的限制范围为1到100,这可以直观地代表该组件在单处理器内核上的CPU时间。
实验环境为1台CPU为英特尔芯片Xeon L5520(2.2 GHz)四核的惠普机架式服务器,内存8 GB,使用JAVA软件语言进行最佳部署,随机生成100,200,…,800个节点部署在机器上。针对每个尺寸的图,生成了100个图和机器权值,根据得到的图切割尺寸和处理时间进行评估。
首先,为了显示本文提出的方法的有效性,将本算法与理论上作为小尺寸图的ILP最优解进行比较。对于较大尺寸的图,就求解质量和执行时间对3种算法进行比较,研究了截止阈值对KL优化算法的影响以及SA的执行次数。
图2(a)和(b)显示的是由MLKL,SA和混合算法得到的与ILP最优解相关的图切割尺寸的平均值和执行时间。
为了评估软件组件部署效率,假设在数据中心不同服务器间的通信链路区中权值相同,因此,∀m,n:bmn=1。由于图代表的是交互的软件组件,还假设重要尺寸的图有几百个节点。对于小图,可以将该解与最优ILP解进行对比(图2)。
SA和混合算法使用了模拟退火法的4项并行执行的最好解决方法。混合算法所得结果比MLKL结果好。然而,混合算法和SA的执行时间分别比MLKL多3~8倍。
对于较大的图,ILP处理器需要很长的时间才能找到1个解,因此,对与MLKL相关的算法进行比较,也对不同参数的影响进行了讨论,这些参数包括 KL优化算法的截止阈值和SA优化算法的并行执行次数。

图2 不同算法的图切割尺寸和执行时间Fig.2 Graph partitioning size and execution time of different algorithms
图3(a)所示为MLKL算法的截止阈值为0,200和500时的求解结果。当前划分的图切割偏差超过当时找到的最佳解的某一截止阈值,KL优化算法就会终止。0截止阈值意味着不允许有负增益的移动,从而这种优化就表现为最陡下降算法。阈值越高,就越接近无阈值的初始解。随着图尺寸的变大,允许带有负增益的移动得到的提升就越少。图3(b)所示为不同截止阈值算法的执行时间,以求解质量为代价,利用截止阈值可以减少执行时间。
图4(a)和图4(b)所示为 SA算法的求解质量与MLKL算法的对比以及SA算法不同数量的执行运行的执行时间。相对较小的图而言,与MLKL找到的解相比,SA找到的解较好;但随着图尺寸的变大,MLKL找到的解比SA的好。由于搜索空间的增加,SA将不太可能找到可以得到最优解的随机移动。SA执行时间要高于MLKL的执行时间。
随着图尺寸的增大,允许负增益移动的求解质量的提高会越少。图5(a)显示的是相对于MLKL算法的混合算法的求解质量,图5(b)显示的是执行时间。与MLKL相比,混合算法得到了稍好的分区,但是随着图变大,这种改进开始减少。就执行时间而言,混合算法比SA的少但仍比MLKL的执行时间长。
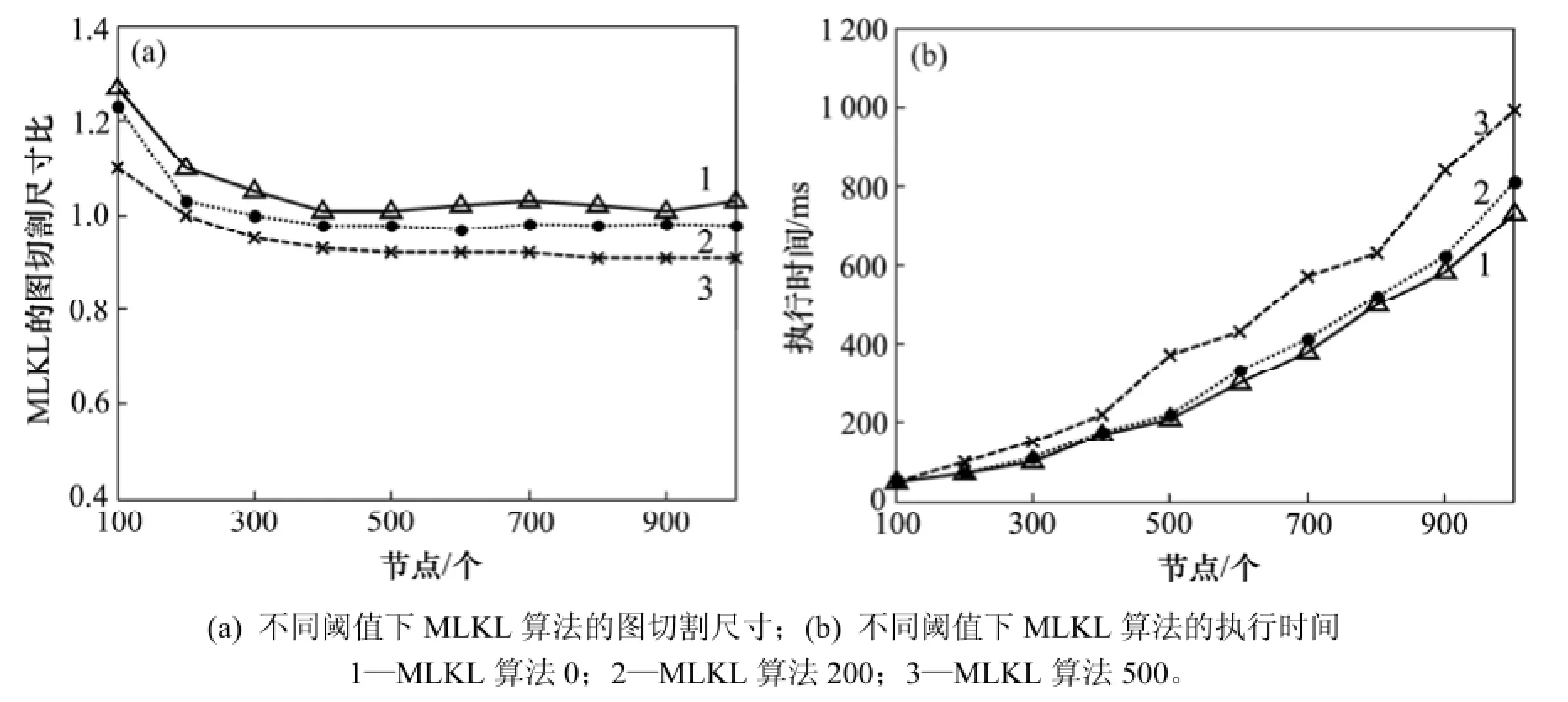
图3 不同阈值下MLKL算法的图切割尺寸和执行时间Fig.3 Graph partitioning size and execution time of MLKL under different thresholds
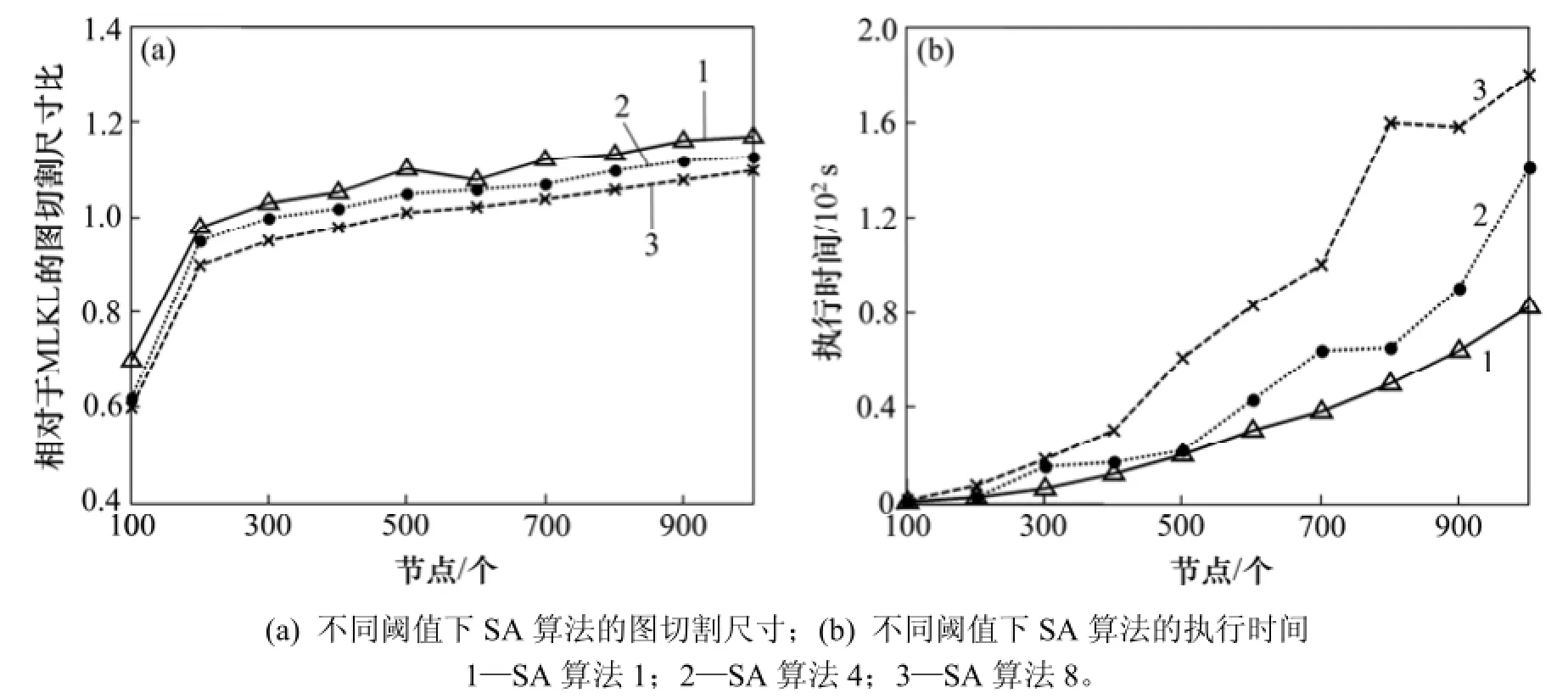
图4 不同阈值下SA算法的图切割尺寸和执行时间Fig.4 Graph partitioning size and execution time of SA under different thresholds
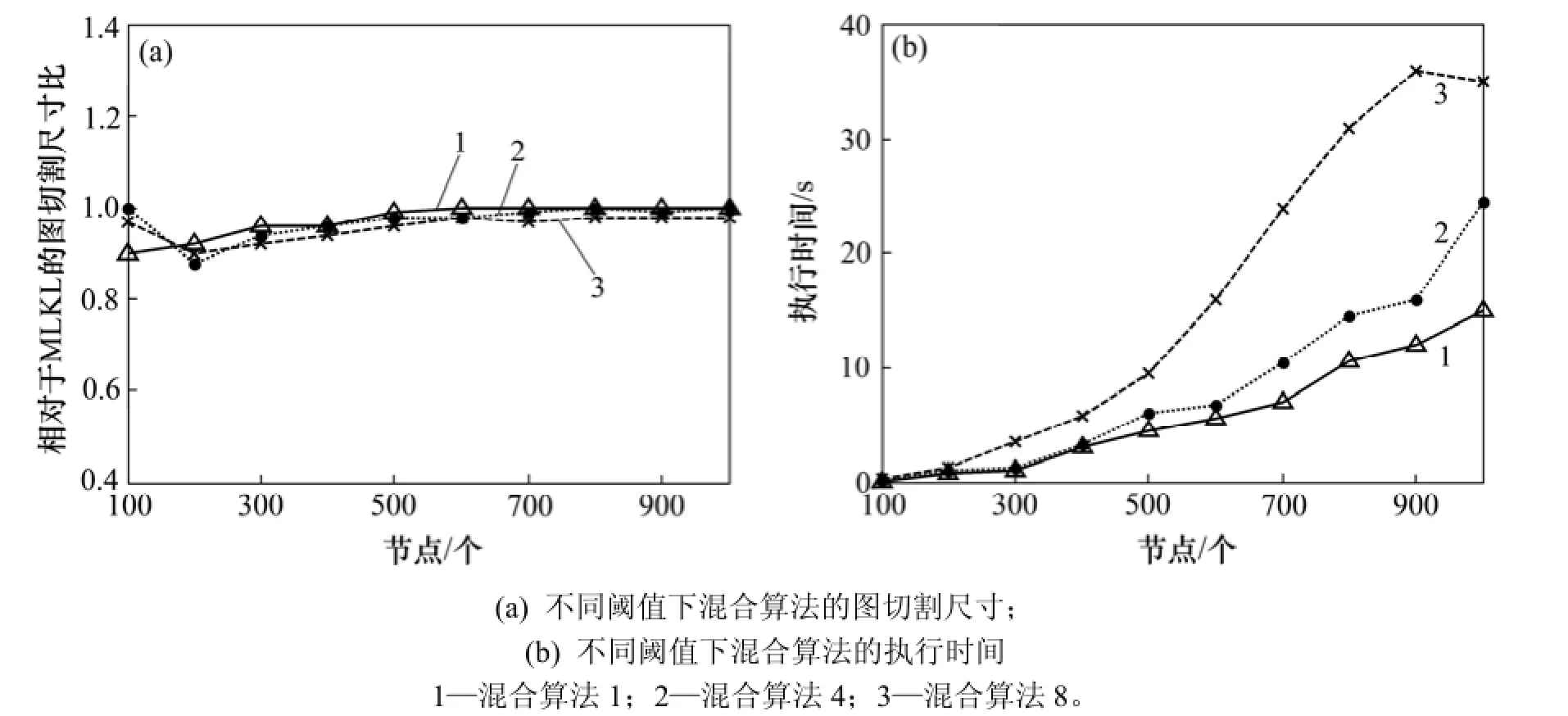
图5 不同阈值下混合算法的图切割尺寸和执行时间Fig.5 Graph partitioning size and execution time of hybrid algorithm under different thresholds
假定所有的应用程序组件都部署在云上,所有的服务器通过相同的链接互联,因此,∀m,n:bm,n=1。然而,在移动云计算背景下,用云可以把应用程序上的组件从移动设备上卸载到云上,其中用来将设备连接到互联网的无线链路是一个重要的限制因素。依赖于技术和介于移动设备和云之间可使用的带宽信号强度,最佳部署会改变。为计算这种情况下的最佳部署,可以通过无线链路尝试限制交换数据的数量。
为计算在卸载场景中的最佳部署,在随机生成的机器表中额外添加了1台容量为25 G的机器D并锁定这台机器上的1个节点。机器之间的连接权重设置为1,对于每个服务器与D之间的连接要设置成α≥1。当α增加时,算法会计算出1个新的部署并尝试降低无线链路的带宽。
4 结论
1) 提出一种划分软件图的混合算法,以实现在云中的部署。考虑到基础设施的异质性,对最优划分进行了计算。与计算网格部署最优化相反,未对一组网格结构任务的执行时间最小化,而是将软件组件之间的带宽最小化。
2) 提出多层次以KL为基础的算法,这是一种快速分割器,可以实现实时部署计算。
3) 下一步可将这些方法融入到一个实际的软件部署框架中,这样可以对云基础设施上的软件组件进行自动分配。
[1] 靳志成. 云计算环境下的软件动态部署[D]. 上海: 上海交通大学电子信息与电气工程学院, 2011: 1-8. JIN Zhicheng. Research on dynamic software deployment in cloud environment[D]. Shanghai: Shanghai Jiao Tong University. School of Electronics and Electric Engineering, 2011: 1-8.
[2] 钱育蓉, 于炯, 王卫源, 等. 云计算环境下软硬件节能和负载均衡策略[J]. 计算机应用, 2013, 33(12): 3326-3330. QIAN Yurong, YU Jiong, WANG Weiyuan, et al. Energy saving and load balance strategy in cloud computing[J]. Journal of Computer Applications, 2013, 33(12): 3326-3330.
[3] MEYERHENKE H, MONIEN B, SCHAMBERGER S. Graph partitioning and disturbed diffusion[J]. Parallel Computing, 2009,35(10): 544-569.
[4] 黄树成, 李甜, 沙爱晖. 一种基于图划分的混合属性数据聚类算法[J]. 计算机应用与软件, 2013, 30(7): 11-13. HUANG Shucheng, LI Tian, SHA Aihui. A graph partition-based clustering algorithm for mixed attribute data[J]. Computer Applications and Software, 2013, 30(7): 11-13.
[5] FIDUCCIA C M, MATTHEYSES R M. A linear-time heuristic for improving network partitions[C]// Proceedings of the 19th Design Automation Conference. IEEE Press, 1982: 175-181.
[6] VAHID F, LE T D. Extending the Kernighan/Lin heuristic for hardware and software functional partitioning[J]. Design Automation for Embedded Systems, 1997, 2(2): 237-261.
[7] CHARDAIRE P, BARAKE M, MCKEOWN G P. A probe-based heuristic for graph partitioning[J]. IEEE Transactions on Computers, 2007, 56(12): 1707-1720.
[8] ZAMPROGNO R, AMARAL A R S. An efficient approach for large scale graph partitioning[J]. Journal of Combinatorial Optimization, 2007, 13(4): 289-320.
[9] MARTIN J G. Spectral techniques for graph bisection in genetic algorithms[C]// Proceedings of the 8th Annual Conference on Genetic and Evolutionary Computation. Washington, USA:ACM, 2006: 1249-1256.
[10] CHEN J, TAYLOR V E. Mesh partitioning for efficient use of distributed systems[J]. IEEE Transactions on Parallel and Distributed Systems, 2002, 13(1): 67-79.
[11] HENDRICKSON B, LELAND R. A multilevel algorithm for partitioning graphs[C]// Proceedings of the 1995 ACM/IEEE conference on Supercomputing. California, USA: ACM, 1995:28-41.
[12] KARYPIS G, KUMAR V. A parallel algorithm for multilevel graph partitioning and sparse matrix ordering[J]. Journal of Parallel and Distributed Computing, 1998, 48(1): 71-95.
[13] MIMAROGLU S, ERDIL E. Combining multiple clusterings using similarity graph[J]. Pattern Recognition, 2011, 44(3):694-703.
[14] 李冰鹏, 娄国哲. 一种软件部署冲突检测及其自动调整算法[J]. 计算机应用与软件, 2011, 28(4): 63-66. LI Bingpeng, LOU Guozhe. A software deployment algorithm of conflict detection and automatic adjustment[J]. Computer Applications and Software, 2011, 28(4): 63-66.
[15] 陈伟, 魏峻, 黄涛. W4H:一个面向软件部署的技术分析框架[J]. 软件学报, 2012, 23(7): 1669-1687. CHEN Wei, WEI Jun, HUANG Tao. W4H: An analytical framework for software deployment technologies[J]. Journal of Software, 2012, 23(7): 1669-1687.
[16] KIRKPATRICK S, VECCHI M P. Optimization by simmulated annealing[J]. Science, 1983, 220(4598): 671-680.
[17] CERNY V. Thermodynamical approach to the traveling salesman problem: an efficient simulation algorithm[J]. Journal of Optimization Theory and Applications, 1985, 45(1): 41-51.
[18] JOHNSON D S, ARAGON C R, MCGEOCH L A, et al. Optimization by simulated annealing: an experimental evaluation;part I, graph partitioning[J]. Operations Research, 1989, 37(6):865-892.
[19] PARK M W, KIM Y D. A systematic procedure for setting parameters in simulated annealing algorithms[J]. Computers & Operations Research, 1998, 25(3): 207-217.
[20] EPPSTEIN D, WANG J. A steady state model for graph power laws[C]// Proceedings of the 2nd International Workshop on Web Dynamics. Hawaii, USA: ACM, 2002: 1-8.
(编辑 陈爱华)
Hybrid software deployment management algorithm based on multilevel graph partitioning in cloud environment
DAI Wei1,2, LIU Hua1
(1. School of Management, Huazhong University of Science and Technology, Wuhan 430074, China;2. School of Economics and Management, Hubei Polytechnic University, Huangshi 435003, China)
To allocate the software components to the appropriate cloud servers at the same time of minimizing the required bandwidth, a hybrid algorithm based on multi-layer graph partitioning algorithm was proposed for solving the software deployment issues in cloud computing environment. This algorithm improves the heavy-edge matching (HEM)algorithm, adds a new constraint for coarsening, conducts segmentation using the algorithm similar to KL, and finally achieves the re-design and assessment for graph partitioning algorithm in combination with annealing algorithm. Compared with traditional graph partitioning, the proposed algorithm takes into account the heterogeneity of the infrastructure, and so it is not limited to the balance partitioning. The simulation results of test show that compared with the traditional KL graph partitioning algorithm, the proposed hybrid algorithm can achieve a good balance between execution time and solution quality, and so its overall performance is better than that of the traditional algorithms.
cloud computing; graph partitioning algorithm; SA algorithm; software deployment
TP393.02
A
1672-7207(2016)05-1565-08
10.11817/j.issn.1672-7207.2016.05.016
2015-07-15;
2015-09-227
教育部人文社会科学研究青年基金资助项目(13YJCZH028) (Project(13YJCZH028) supported by Humanities and Social Sciences Youth Fund Project of Ministry of China)
戴伟,博士,副教授,从事云计算、数据挖掘和企业管理研究;电话:13971762521;E-mail: dweisky@163.com
