军事指挥信息系统中的机器智能:现状与趋势
2016-09-10胡晓峰
胡晓峰
【摘要】我军指挥信息系统建设取得突出成就,但也面临极大挑战,其中最大的挑战来自于智能化。如何理解智能化在未来战争中的地位和作用,推进智能化关键技术研究突破,是我国指挥信息系统建设必须面对的问题。本文以美军“深绿”计划发展过程为例,分析当前指挥信息系统发展存在的智能化难题,并结合以AlphaGo为代表的智能技术突破,探讨指挥信息系统建设及其智能化发展的方向。
【关键词】指挥信息系统 人工智能 深度学习 态势理解
【中图分类号】 E919 【文献标识码】 A
【DOI】10.16619/j.cnki.rmltxsqy.2016.15.002
近年来我军指挥信息系统建设成果十分显著。首先,以指挥自动化建设为基础,新型指挥信息系统已经涵盖了作战指挥C4ISR的各个环节,成为作战指挥的基础平台;其次,多年的建模仿真及数据工程建设实践为指挥信息系统建设积累了大量的基础性模型、规则和数据;第三,分析评估和任务规划系统快速发展,已经成为指挥信息系统的重要组成部分。但是,这些系统都遇到了智能化问题,即对智能程度要求稍高的态势理解、决策辅助或对抗推演等问题始终难以突破。未来战争需要快速决策、自动决策和自主决策,这些都有赖于智能瓶颈的突破,否则无法适应未来战争的需要。这也是其他国家军队指挥信息系统建设同样面临的问题。
指挥信息系统的智能化既是系统能力实现阶跃式提升的核心环节,也是形成与对手不对称优势的关键。本文将以美军的“深绿”计划发展过程为例,简要分析机器智能辅助存在的问题,并结合AlphaGo在智能方法研究上的突破,探讨未来指挥信息系统研发需要关注的问题及趋势。
“深绿”计划的组成及特点
“深绿”计划是2007年由美国国防部高级研究计划局(DARPA,Defense Advanced Research Projects Agency)启动的关于指挥控制系统的研发计划,原计划3年完成,然后将这个系统嵌入到美国陆军旅级C4ISR战时指挥信息系统中去①。
简单的说,“深绿”就是想将智能技术引入到作战指挥过程中。受当时IBM的“深蓝”战胜了国际象棋棋王卡斯帕罗夫的影响,该计划取名“深绿”。美军认为既然计算机可以战胜棋王,那么也能帮助指挥员快速决策,在作战指挥中取得致胜的先机。但事实证明原先的估计过于乐观和简单了,计划至今都没有完成。
“深绿”的任务是预测战场上的瞬息变化,帮助指挥员提前进行思考,判断是否需要调整计划,并协助指挥员生成新的替代方案。最初的设想是能够将制定和分析作战方案的时间缩短为现在的四分之一。通过提前演示出不同作战方案以及可能产生的分支结果实现快速决策,从而使敌方始终不能将完整的决策行动闭环(观察—判断—决策—行动),永远无法完成决策并行动。“深绿”的主要目标是将指挥员的注意力集中在决策选择上,而非方案细节制定上,方案细节的制定交由计算机完成。
“深绿”由四大部分组成。第一部分叫指挥官助手,实质是人机接口;第二部分叫“闪电战”,实质是模拟仿真;第三部分叫“水晶球”,相当于系统总控,完成战场态势融合和分析评估;第四部分是“深绿”与指挥系统的接口。它们主要有三个特点:
基于草图指挥。通过指挥官助手这个模块实现决策指挥“从图中来,到图中去”,以最大限度地符合指挥员的决策分析与操作习惯。也就是通过最自然的手写图交互的方式,与计算机实现交互。从战场态势感知、目标价值分析、作战方案制定、指挥员决策,一直到作战行动执行、作战效果评估,全部实现“基于草图进行决策”,即由“草图到计划”(STP, Sketch to Plan)和“草图到决策”(STD, Sketch to Decision)两个模块完成。该功能实现的关键是智能化的人机接口。
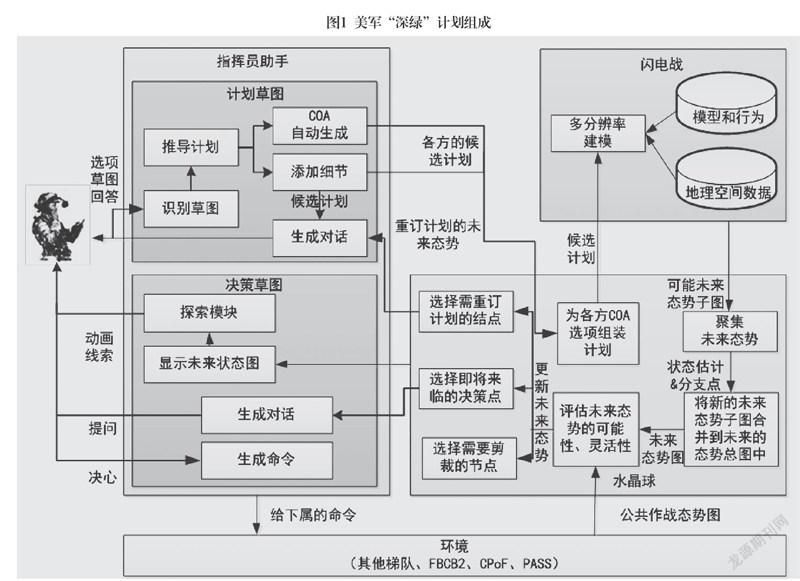
自动决策优化。决策通过模型求解与态势预测的方式进行优化,系统从自动化接口的“指挥官助手”进去,然后通过“闪电战”模块进行快速并行仿真,再通过“水晶球”模块实现对战场态势的实时更新、比较、估计,最后将各种决策方案提供指挥员,由指挥员决策选择。
该功能的实现需要两个工具支持:即“闪电战”和“水晶球”。前者是自动决策优化工具,实际就是分析引擎,能够迅速地对指挥官提出的各种决策计划进行并行模拟仿真,从而生成一系列未来可能的结果。同时它可以识别出各个决策的分支点,预测可能的结果、范围和可能性,即通过多分辨仿真实现对未来的预测。后者实际就是决策总控,通过收集各种计划方案,更新战场当前态势,控制快速模拟,向指挥员提供可能的选择,提醒指挥员决策点的出现。
指挥系统的集成。即将决策辅助功能集成到“未来指挥所”(CPoF, Command Post of Future)系统中。“未来指挥所”是美军针对未来作战需要研发的一个指挥信息系统。“深绿”的项目负责人苏杜尔曾说,“深绿”将来就是未来指挥所系统屏幕上的一个图标或工具。通过简单的点击操作就可以辅助指挥员进行决策。未来指挥所系统虽然很复杂,包括了各种传感器、可视化、空间推理、仿真决策、数据库等要素,但美军觉得最需要的是智能辅助决策的支持。
“深绿”的无奈——指挥信息系统面临的智能化难题
“深绿”的理想效果是只要提供己方、友方和敌方的兵力数据和可预期的计划,系统就可以快速推演出结果,辅助指挥员快速做出正确决策。如将该系统嵌入到指挥系统中,就可以大大提高指挥效率。但该项目发展并不顺利,“深绿”最后只留下了“草图到计划”STP,其它都不见了②。“深绿”是美军十年前设想的项目,但为什么没有做到并达成预定目标呢?这就要回答指挥信息系统面临哪些智能化难题。实际上我国这几十年也在做类似工作,但结果也是一样,很多都觉得应该能够做到,但到最后都卡在智能化问题环节。
战场态势理解。战场态势理解与各种棋类比赛的态势理解的特点完全不同。下棋是固定规则、完全信息,行动全开放,什么都能看见,什么都知道,看的是你的决策。但战场态势理解是不完全信息条件下的态势判断,也就是态势信息有真有假,有多有少,指挥员看到的和实际的情况根本不一样。战场态势理解是指挥决策不可缺少的前提,决策内容包括作战力量、战场布势、行动过程、环境目标等多种要素,而且层次越高,对态势的认知就越具主观性,从战斗、战术层,再到战役、战略层,态势可量化的程度就越低。从这个角度来说,低层次的战斗战术态势理解相对容易一些,现在能够做到的几乎都在这个层面,比如飞行员看到的双机对抗态势,连排长看到的分队战术态势。但就整体而言,计算机对态势的理解能力还远远达不到人的水平。即使非常复杂的战略战役态势,有经验的指挥员一看马上就知道战场情况如何,百万雄兵自在胸中,但计算机还做不到。
态势理解的表达。“深绿”将决策的“想法”用笔绘制图形输入很容易,画个草图就行了,这对于目前的技术来说几乎没有问题。但要把对态势判断的理解表达出来就不容易了,比如作战决心,采用哪种图表和符号呢?是画个箭头,还是画个圈圈来表示?表达粗细如何选择?如何补充其中的细节?而且,如果要素更多一些,各种情况更复杂一些,这种决策的表达就会更加复杂。对人来说,这种表达没有任何问题,但让计算机去做就比较困难,因为人机接口还做不到对图形图像和自然语言的理解。决策想法的输入是分析评估的前提,要解决这个问题,智能化人机接口就必不可少。
作战计划的描述。这是一个最大难题。因为作战行动及结果有不确定性,会导致行动偏离计划预想。而且决策选择还会出现组合爆炸现象,前面计划的任何变化都会导致后面计划的无穷变化。所以识别情况变化并能正确应对就成为难题。态势改变了如何识别和理解?如何知道改变的意思是什么?如何调整后面的计划?敌方的决策如何确定?这其实就是“人机对抗问题”的翻版,和AlphaGo人机大战一样。不管红方、蓝方,你事先都可以做一个很“圆满的”作战计划,但因为不确定性,只要对抗开始,一切就全都变了,使得你根本无法再按原计划进行。所以以往进行作战计划评估,一般只做单方的,像地地导弹发射,不管别人怎么办。在一些低对抗条件、低层次或低复杂度的行动组合,也可以勉强做到一部分。但对高对抗条件、较高层次的作战计划,如果不能实现态势认知理解和智能应变,就根本无法做到对计划的真正评估。
对“未来”的仿真。“深绿”的“闪电战”模块功能是对未来多种可能情况进行仿真,推演出可能的结果,供指挥员决策时参考。该模块的实现需要回答两个问题:一是“未来”有多远?对于长程的推演,会由于复杂性传递导致状态偏离越来越大,和你原来设想的不一样,你将如何处理这种变化?而且越复杂的行动推演,涉及要素和变化越多,又怎么办?二是推演中谁来负责敌方的决策?因为推演即有对抗,指挥信息系统都是我方的,谁来负责推演中敌方的行动决策?是由指挥员去假定,还是由指挥信息系统自动得出?而且对抗的敌方是不会合作的,如何进行取舍?是不是需要配套合适的仿真系统并与指挥系统互联?这些问题的本质其实都是智能问题,不解决这些问题就无法对“未来”进行仿真。
数据的决定性作用。人们总是认为,系统之所以做不出正确决策,是因为所提供的数据不够或不准。这是典型的“决定论”观点,即初始条件足够,就可以预测一切。实际上这种理解是片面的,也是不正确的。战争是典型的复杂系统,敌人也不是合作者,永远也不会有“足够的”数据给你,不完全信息条件下决策是作战指挥的本质特点。决策需要根据情况不断变化,数据的要求也会不断发生改变。复杂性会导致“决策”本身不唯一,也就无法确定哪个“正确”,哪个更好?层次越低,决策越接近简单系统,数据可能才越具有决定性作用。比如单机单舰,在战术级还勉强可以,但到了高层次就可能不行了,数据的多少并不能减少作战的复杂性。但无论如何,能否采集到足够的数据是能否正确决策的前提,“深绿”之所以要集成到指挥所系统中,就是要通过指挥系统给它提供采集和感知到的各种数据。所以说,“数据是否具有决定性”,在不同情况下会有不同的回答。
计算机的决策是不是优于人。计算机做出的作战决策是不是可以优于“人”?米勒定律③认为,大多数人在分析问题的时候,同时只能考虑7至9个因素。但如果计算机能够同时考虑10个以上因素的话,那么它的分析能力肯定可以超过人。美军曾做过一个RAID仿真实验来验证这个结论。设想了一个步兵连与一群叛乱分子的对抗,步兵连分为30~35个小组,由斯特瑞克装甲车和武装直升机加强火力。叛乱分子则由30个规模不一的小组组成。用OneSAF仿真系统仿真实验36次,最后得出结论是RAID表现像人类的有16次,也就是你分不出来是人决策还是计算机决策,大约占到44%,也就是一半左右。战斗取胜的18组中有16组是计算机,就是说有88%超过了人,这说明在这种情况下计算机能力还是很强的。
但这是在战斗或战术层面等比较低的层次。到了高层,比如说旅级指挥所这一层,这个结论就很难说了。很多研究证明,层次越高艺术成分越高,越难用计算机辅助,就是因为计算机还不能像人那样“艺术地”思考问题,其实这也是智能问题。这种情况下想要计算机去取代人肯定是不现实的,也不明智。决策问题最终要解决的问题,本质上就是人与计算机应该如何分工的问题。
陆军平台问题。“深绿”计划虽然主要是针对陆军部队的,但事实上解决陆军的自动化指挥决策问题比海空军更困难,因为陆军作战行动中个人更自由,一般的步兵散兵很难定位和规范,也就是很难数字化。所以要想使用“深绿”系统,就必须先将部队的行动规范化,但是这在实际作战中又做不到。
那么“深绿”更适合用在什么系统里呢?对陆军来说,更适合的是车载战术级作战指挥辅助系统,就是使用车、使用坦克、使用装甲车的部队。对海军、空军及导弹部队来说,比较适合的是战术级辅助决策以及作战规划等系统。对网络作战来说,可能更适合于“事先规划”的方式,就是战前依托系统辅助制定决策,战时依托数据自动决策的方式来完成。这种智能决策辅助应该如何使用,应该由它的对象来决定。
以上这七个问题都是在“深绿”研发中必须要解决的问题,否则就很难被广泛使用。但就目前的情况来看,“深绿”能做到的和人们期望只值之间,还存在很大的差距。而且还有一个矛盾或悖论:有的事情你能够做到,但作战并不太需要;有的事情作战特别需要,却很难做到。比如,在战斗层或分队层指挥信息系统可以做到智能辅助决策,因为这个层次的智能问题比较易于解决,但在实战中偏偏在这种情况下指挥员一般一眼就可以看清,并不需要推演计算;但在战役以上层次,战场态势特别复杂,一般人往往看不懂或看不清,特别需要智能辅助,但它却无能为力。
层次越高,作战决策越复杂,越难以描述和处理,这不仅仅是因为部队多了、数据多了、运算量大了等问题,而且还有复杂性带来的不确定性、指数爆炸,以及对“对手”意图的把握等对抗博弈的问题。所以说到底,核心问题还是决策智能辅助问题,也就是智能瓶颈能否突破?如果不能突破智能瓶颈,刚才说的问题就永远都是问题。

AlphaGo带来的机遇——指挥信息系统智能技术的探索
人类智能和机器智能面临着不同的智能难题。有些事情对计算机非常容易,但对人却很难,比如说计算、排序、记忆等;也有些事情对人来说很容易,但对计算机却很难,比如说理解图像,人一眼就能看出图片中的各种物体,但是让计算机去看恐怕就很困难。这就是所谓的“莫拉维克悖论”,说的就是人和机器在智能方面往往非常不同。
一般来说,机器智能主要分为三大类:第一类是计算智能。机器可以在科学计算、逻辑处理等方面完胜人类。比如超级巨型机“天河”,科学运算速度可以达到几千万亿次。但也还有很多事情能做但还做不好,比如说复杂推理时可能还需要直觉的帮助。IBM的“深蓝”和“更深的蓝”连续战胜国际象棋棋王卡斯帕罗夫,但有很多科学家却认为,它的方法本质上还只是数学方法,并不属“智能”的范畴。第二类是感知智能,就是智能化的感知接口,这种智能对人很容易但对机器却很难。这几年大数据和深度学习的出现,使得机器在这方面有了很大的进步。比如语音识别,即将听到的语音识别成文字,讯飞、阿里的语音识别就可以完胜速记员④,苹果Siri、微软小冰和百度的小度等也都做得非常出色,谷歌的图片识别标注、ImageNet竞赛等,都已经达到令人惊叹的水平。在行为感知智能方面,比如“大狗”机器人、行走士兵等。虽然现在进步很大,但还只是初级水平,尚有很多复杂的事情计算机还做不了。第三类是认知智能。这是最复杂的智能,以“能理解”“会决策”为基本特征。IBM的问答智能程序“沃森”可以在问答比赛中完胜人类,标志着计算机在知识组织上更有效;谷歌无人车需要多种感知和决策方面智能的结合,标志着无人平台开始融入社会生活;现在还有包括我国在内的多个国家都在做一件事情,就是要让人工智能程序参加高考,甚至要争取考入一本大学,最好能进清华、北大。这些事情在智能方面未来都有可能做到,但即便如此它们离真正的认知智能还有很远的距离。要真正做到“能理解”“会决策”还很困难,因为“可识别”不等于“能理解”,你能认出这个东西是什么不等于理解了它,更不等于它“有意识”。AlphaGo和李世石的比赛一结束,就有媒体制造一些耸人听闻的标题,讨论“计算机何时开始统治人类”等问题,而目前计算机能不能具有“自我意识”都还不知道,消灭人类估计是很久以后的事情了。
从三类机器智能来看,指挥信息系统在认知智能方面的差距最大,是明显的瓶颈。但可以设想如果一旦突破,带来的影响也将是极为重大的,这样战场态势的认知速度就将成为决定作战胜负的关键因素。因为从工具的角度来看,机器肯定要比人要做得好,所以只要一旦做出来了,它的算法、数据及计算能力都是可以重复的,因而也就可以无限放大它的作用。
表1列出了指挥信息系统在三类智能方面的差距。认知智能、计算智能、感知智能分别对应着指挥信息系统的人机接口、基本指挥业务和辅助决策等功能。在感知智能方面,人机接口技术现在已经越来越好了,因为近几年深度学习方法取得很大突破,今后应该会有很大的突破。但是在辅助决策的认知智能方面,目前还有较大差距,还非常初级,就像“深绿”所做的那样,雷声大雨点小,至少目前还没有很大的进展。
AlphaGo近期掀起了一个很大的高潮,被认为是机器智能在方法进步上的里程碑。有人说这是谷歌会做广告,但笔者认为不是这样。为什么别的下棋程序也非常多,也战胜过一些“名人”,却知者寥寥?因为它们从智能技术和方法进步上来看价值不是太大。但AlphaGo却给了我们很多惊喜,有了很多新的发现,而且还有很多甚至连设计者事先可能都没想到的地方,这才是它被大家认可的真正原因。
AlphaGo在这次人机大战中至少表现出以下几个方面的突破,或者是表现出了很好的苗头:一是它是通过深度学习自己掌握了围棋对弈知识,而不是像“深蓝”那样将相关知识编在程序里;二是它展现出了一种捕捉“棋感直觉”的方法,将人类平衡全局胜负和局部优化的能力捕捉下来并用于对抗,这是一个很大创新;三是在对弈中它甚至发现了人类没有的围棋着法,这是从围棋高手的评论中得知的,说它比人更接近“围棋之神”。据说它已经达到了职业十三段,也有说可以让四子下赢柯洁。这个进展还隐含着另一个结论,就是机器智能并不是简单模拟和逼近人的智能,而是可以超过人的智能的。四是这种方法具有一定的“通用性”,可以应用在其他地方,而不只是下棋,因而极具参考价值。
从以上这四条可以看出,虽然AlphaGo在认知智能方面还非常简单也非常初级,但它揭示出了非常重要的趋势,即在未来几年以深度学习为代表的机器智能技术将有可能会有很大的突破,有可能产生出爆炸性的影响,我们不能不关注。
深度学习方法的进展
围棋棋手的棋感和其他很多经验知识是一样的,决定了他的水平,但只可意会,不可言传。那么,怎样让AlphaGo学会围棋高手的着法,并且获得所谓的“棋感直觉”呢?这是通过深度学习方法做到的。
深度学习是通过建立神经元网络达成“理解概念、捕捉感觉”的目的的,即“通过对大量样本的学习,形成对事物特征的提取和分类”。这种学习可以分为有监督训练,也就是有人指导,用标签进行分类;无监督的训练,没有人指导,自己实现对特征的聚类。但这需要非常大的计算能力,比如AlphaGo就用了1202个CPU、176个GPU,计算能力约为深蓝2.5万倍,才完成了训练。
AlphaGo的神经元网络是通过学习逐步建立起来的,学习的过程就是逐步整合神经网连接的过程,而逐渐整合就意味着逐步理解。但这个神经网络本身对外部的人来说仍然是黑箱网络,我们并不知道十几亿节点之间怎么连接的,而且这些连接还会发生什么变化。但这些神经网络确实表示出了人对围棋规律的理解,它是建立在大量训练数据和大量计算基础上的。可以说,深度学习就是“大数据+高性能计算+神经网络算法”的一个综合体。
而且,深度学习的学习方法是一种非常接近人类认知的形式。一般来说,人类学习的知识有两类,一类是通过抽象化方式学习得到的,比如说在小学中学学习四则运算、牛顿定律和运动方程,这些是用抽象的形式化方法表达的。语文则是用文字方式来表达的,也是形式化的。另一类则是通过反复训练、积累经验,以直觉的方式学习。以人接抛过来的球的过程为例,当你伸手去接球时,你的大脑中并没有任何有关抛物线方程等形式化的公式,而是根据多年的经验就能把球接到。当我们把飞盘抛给狗的时候,这个狗也可以被慢慢地训练得知道如何去接,形成条件反射。深度学习就是这种学习方法,而且具有“学习需要过程、经验难以言传、结果有对有错”等特点。这也是一种比较符合复杂系统特点的认知方式,虽然可能暂时找不到对应的因果关系或形式化表达,那就只能依据“感觉”和“经验”来做。而AlphaGo的深度增强学习方法,就为人们提供了捕捉这种经验和感觉的具体方法。其实,高手和低手的差别,其实就在“经验”“感觉”方面。谁都知道围棋怎么下,但是高手和低手之间的差别就在于经验和棋感的差距。抓住经验的过程实质上就是认知的过程。
将这些方法用于作战指挥信息系统,既大有好处也非常自然。现在许多深度学习方面的研究进展,都可以用于指挥信息系统设计中。
智能人机接口方面的进展。在图像语音的识别和理解方面,谷歌、微软等很多公司做得非常好,进展很大。比如对象的识别、图像的标注等,目前都可以做到。如果将这些方法用于卫星图像处理、目标识别、作战文书识别等方面,效果肯定要比过去的那些方法要好很多,比如模式识别,这就可以为指挥信息系统提供更好的智能人机接口手段。

智能认知方面的进展。以AlphaGo为例,它主要使用了四种方法实现围棋的对弈决策:一是通过策略网络(Policy Network)预测下一步走棋,这个网络是通过前人棋谱和新老版本的自我博弈训练出来的;二是通过估值网络(Value Network)实现对整个棋局胜负的判定和预测,这个网络是用随机自我博弈的方式得到的;三是快速走子(Fast rollout),这是一种加快走棋速度的方法,是一种只管局部的着法,类似深蓝,虽胜率要低些,但速度可以快1000倍左右;四是通过蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)来探索胜率高的着法,将前三者结合起来,就像总控一样来判断哪种方式更好,并且结合起来使用。
AlphaGo的这些方法很巧妙地解决了对围棋这一类复杂问题的思考、判断和决策问题。这方面的技术问题已经有很多文章解释过,本文仅简单说明。如图2所示,精确思考可以看作是以深度为主的推演估算,而若要得到对棋局全局的理解,就要在广度上具有胜负直觉。这两种方式正好与人类思考过程一致,推演估算是慢思考的方式,是一个精确计算逐步推理的过程,这是用策略网络和快速走子完成的。而胜负直觉的思考过程,可以与快思考过程相对应,是由估值网络实现的。现在科学已经证明,快思考的准确率可能比慢思考的准确率反而要高。也就是说,有时候我们一眼看过去得到的直觉答案往往是对的,而仔细推敲得到的答案反而可能是错的。AlphaGo因为采用了类似的思考方式,所以胜率得以提高。
AlphaGo团队在论文里提供了一些数据,这三种走子方式都可以单独使用,但等级分并不高,也就是个业余水平;但如果将他们两两结合甚至三个结合起来,就完全可以超过人类顶尖棋手。这就是智能应该有的宏观微观整体考虑的感觉,所以结果就会很不一样。至于用多少CPU,用分布式还是集中式,其实不是关键,差别也不大,核心问题仍然是算法。
为了实现以上算法,就必须训练得到两个神经网络。为做到这一点,他们收集了16万人类高手的棋谱,拆分为3000万手盘面,相当于3000万个训练数据,最后得到13层神经网络。但是对估值网来说,由于只估算终局胜负,16万棋谱数据就远远不够了。为得到更多数据,他们再用随机法生成了自我博弈的3000万盘面,并且快速下完,得到胜负结果。有人认为这种方式其实也是一个重大创新,因为找到了产生更多样本数据的途径。
这些方法也可以用于战场态势认知,通过多层神经网络学习来理解作战态势,并利用历次作战、演习的数据进行逐层训练,逐步得到态势理解的神经网络。在理解战场态势的基础上准确判断并合理处置,就可以实现辅助决策或自主决策。这就为解决最复杂的态势认知问题提供了新的途径。但是下棋和作战指挥打仗还是很不一样的,战场上不可能有那么多得样本数据,而且决策方式、对抗过程也不可能让你反复试验,这就需要研究出更多的方法出来,并结合使用。
学习方法的进展。AlphaGo使用的增强深度学习方法,是最可能用于战场态势理解的方法。一般的有监督学习方法,比如AlphaGo最初得到的策略网络,基本是模仿人类走法的套路,属于经验招式。它学来学去最后也超不过人类高手,为什么?因为它学习的都是前人的东西,徒弟不创新怎么能战胜师傅呢?
但用增强学习得到的最终策略网络就不一样了,因为它还要通过自我博弈、调整参数等更多的学习过程加以完善。这就像师傅带徒弟打篮球,徒弟老是去加班训练投篮,而且还净找些新方法,训练的时间长了就有可能超过师傅了。所以,只有“训练超出”“样本超出”,才有可能做到“能力超出”。要下赢人,光靠模仿人不行,还要找到超过人的方法,自己加强创新训练才行。AlphaGo团队利用增强学习方法训练计算机玩视频游戏,已经基本全部超过人类玩家,而且也是通过看电视进行像素级反复训练做到的。
增强学习方法是一种自我强化的训练方式,但需要更多的样本。而样本并不容易找,因此就要有一种用少量样本产生更多样本方法,以解决样本稀缺问题。对作战态势理解来说更是如此。AlphaGo产生训练估值网络的3000万盘面用的是随机下子然后正推的方式,在图像识别领域用的则是将图像旋转等方法。对作战态势理解所需的训练样本,也可以使用空间划分、时段分解、随机复推等方式。利用兵棋推演得到仿真数据,也可以看成是一种样本生成方式。样本生成是一种“以少代多、无中生有”的方法。
迁移学习是一种可以只用少量样本就可以完成训练的学习方法,可以看成是“触类旁通、举一反三”的过程。在一些比较相似的领域,可以利用已经训练好的模型,这样只需要一小部分数据就可以完成训练,而不需要那么多的数据。比如,已经认识了“坦克”,再去认识“自行火炮”就容易得多了,就不需要几千万样本再去训练它。
小样本学习可能是一种更有用的方式,可以看成是一种“照猫画虎”的方式。人类为什么可以只看一眼就可以识别某个对象的特征?比如看这个菠萝只用一眼就可以找出特征,下次再看到就知道这是菠萝。通过“例子”抓住特征,一旦抓住我们就能把它和别的东西区分开。2016年初《科学》杂志报道了麻省理工学院的一种小样本学习方法⑤,叫“概率程序计算结构”,其实就是基于案例的贝叶斯程序方法(BPL)。用这个方法生成相似的字符,还通过了图灵测试,也就是分不出人类与计算机的差别。这就给了我们新的启示,用小样本也可以来做作战态势理解,过去在分析过程中就常用贝叶斯方法。
具体对抗类应用方面的进展。现在深度学习方法已经被DeepMind公司用到了很多地方,比如说用于打德州扑克,这是一种“不完全动态信息”博弈问题。对抗各方的牌面不完全公开,这就要求对抗各方要在“战争迷雾”中进行决策和对抗,让计算机去理解它就更为复杂。他们怎么做的呢?也是用“增强学习方法+虚拟自我博弈”的方式,通过自己跟自己打来学习,打久了也就知道怎么打了。目前它打德州扑克已经达到了人类专家的水平,也就是和高手去比胜多负少。
DeepMind下一步还准备攻克“星际争霸II”。这是一种2010年出品的即时战略游戏,可以多人对战,在特定的地图上采集资源,生产兵力,并摧毁对手的所有建筑而取得胜利。可以认为它就是一种真实战场的简化:不确定条件、不完全信息、多兵种行动、策略间对抗。如果成功,它就将进一步接近对战争对抗的认知,而且还很容易迁移到真实的作战态势认知方面,所以我们绝对不能忽视!
指挥信息系统的智能化趋势
如何把这些方法用于改进指挥信息系统呢?DARPA原以为“深蓝”可以自然变为“深绿”,但实际上,“深蓝”方法并不是真正的智能,与作战指挥的本质规律也不太符合,“暴力搜索”方法也不适应决策的非线性空间求解,即使是在智能接口实现方面也不太理想。
但AlphaGo的深度学习方法更有参考价值,因为它已经有了通用化特点,具备了产生突破的可能性,技术途径更符合人类智能行为,而且易与指挥活动对接起来。如果把AlphaGo的方法用于“深绿”,可以有很好的对应关系:对于指挥官助手,可以采用深度学习方法解决语音理解、草图输入等问题;闪电战部分有点类似AlphaGo的走子网络SL+RL+Rollout的结合;和水晶球部分类似的则是AlphaGo的蒙特卡洛树搜索MCTS。把它们结合起来,就可以比过去“深蓝”的方法要好得多。所以说,如果“深绿”引入AlphaGo的技术,将会很快取得更大进展,这一点我们可以拭目以待。
最近又爆出一个消息,辛辛那提大学开发的“阿尔法AI”机器飞行员,在2016年6月,战胜了著名的空军战术教官基纳·李上校,而且无一败绩。据说这个上校虽然已经退役,但在空战方面是专家。与机器飞行员的“人机”对抗是通过空战模拟器进行的,单机对单机,过程比较简单,属于“动作及简单战术行为”的智能。它采用的是称为“遗传模糊逻辑”的智能技术,空中格斗快速协调战术计划的速度比人快250倍。而且所用硬件仅价值500美元,比AlphaGo便宜太多了。据说在未来这个机器飞行员可充当智能对手进行作战训练,也可以成为智能僚机,帮助人去打仗,或者是用于自主化的无人机。它的出现使人们可以肯定一点,即人工智能将会很快走入实战领域。这是一件比较可怕的事情,设想计算机打败了一个著名资深战术教官上校,那它来跟人打仗,至少在速度上已经占据了优势,如果还捕捉了专家的经验,斗争的结果将不言而喻。
目前机器智能研究已成热点。孙正义认为,机器智能就是未来的“智能核弹”。他说,普通人的IQ为100,爱因斯坦为190,达芬奇是人类史上IQ最高的人为200,如果机器达到了10000,那将会是一种什么效果?那时,是不是机器看人类都像是傻子?世界上许多大型IT公司对“深度学习”研究也都做了大量的布局,谷歌在2012年只有不到100这个方面的项目,而到了2015年,就超过了2700个。如果其中有十分之一甚至百分之一获得成功,他也将会大获成功。AlphaGo已经证明了这一点,脸谱、百度、腾讯、阿里巴巴等公司也是一样。
美国DARPA现在非常重视人工智能的研究,它的第三次抵消战略实际上就是围绕人工智能和无人机这个重点来做的。他们认为,智能技术是改变战争规则的东西,但重点在人、机智能的结合方面,所以它叫“半人马”⑥。所以说,即使从这一点看,解决指挥信息系统中的智能瓶颈问题也是刻不容缓的。
目前指挥信息系统智能化方面的趋势主要有以下一些:
拟人化人机交流。未来在指挥信息系统中拟人化的人机交流方式会越来越普遍,指挥员与系统将通过草图、口语或手势进行交流,成为指挥信息系统人机接口的标配,而且会普及到所有装备和人员。
数据化快速决策。从数据到决策将使决策走向智能化、自动化。“深绿”只能为指挥员“辅助决策”,起作战伴侣作用,但利用大数据及智能辅助可实现“从数据到决策”,也就是它可以直接决策,不需要人介入,因而作战速度会大大加快。不仅行动要快,态势理解要快,做出决定更要快!这就意味着认知速度将成为未来作战胜负的决定性因素,也就是谁理解得快谁就可以打赢,谁理解得慢谁就挨打。
无人平台的指控。未来需要特别关注自主化无人智能作战平台的指挥控制问题,这在过去根本没有过,所以如何指挥控制成为问题。无人机与有人机的协同,尤其是自主无人机协同,将成为重点。兰德公司去年出了一个报告,专门研究了无人机和有人机协同作战问题,演化出的新战法完全不同于现在。如果我们还是沿用传统思维,哪怕是信息化了的传统思维,恐怕连敌机的面都没有见到,就与世界拜拜了。这种方式在未来可能成为主要的作战方式。所以,美国人说了一句话:“散开来的智能武器更令人恐惧”⑦。明明知道它没有人,但散开来之后极其吓人,因为你根本不知道它会如何对付你。现在已经出现恐怖分子向美国无人机投降的情形,很值得玩味。
作战云开始出现。这个概念是前美国空军第一副参谋长戴维·A·德普图拉中将提出来的⑧,他也是美国军事变革的代表性人物。他的意思就是要采用信息时代技术的情报、监视与侦察、打击、机动和维持的复合体,以使高度互联的分布式作战行动可行。这类似于云计算和云服务的概念,通过所有可能得到的数据,整合各个作战力量,从而达到增强作战效能且获得规模效益。它特别适于智能化无人平台、特战部队等新型作战力量的运用。
所有这些都特别需要智能技术的进步。指挥信息系统未来发展的关键在于:第一,要充分利用智能技术进步成果,如深度学习等,促进指挥控制技术和信息系统的升级换代;第二,对不同类型应用应结合不同智能技术和方法,比如人机接口、辅助决策、模拟推演等,都会有不同的侧重点;第三,发挥人机结合的优势,未来是“人机智能”的时代,而不是机器取代人。人、机在智能上如何分工如何合作,这才是关键之所在。
“深绿”的发展及AlphaGo的突破给了我们很多启示。我们不能急功近利,但也不能坐以待毙,特别注意搞好基础性研究。有人说,我们过去是“机械化没赶上,信息化拼命追,智能化不能再落后”。笔者认为,机械化通过装备更新比较容易赶上,信息化需要时间积淀和规模效应,但也可以逐步追上,但智能化就不太一样,它们之间是有本质区别的,一旦赶不上可能就会永远赶不上,因为战争可能不会给你追赶的时间了,战争智能技术会快速地扩大强者和追赶者之间的鸿沟,放大两者之间的能力差距,从而导致狂妄的战争冒险,让你追无可追。
注释
Kerr,Bob, "DARPA demos Deep Green," Fort Leavenworth Lamp, 7 April 2011. Surdu, John R.,"Deep Green," Defense Advanced Research Projects Agency (8 May 2008). Banks, Stephen, J., "Lifting Off of the Digital Plateau With Military Decision Support Systems, " United States Army Command and General Staff College, 2013.
Surdu, John R., "The Deep Green Concept," Huntsville Simulation Conference 2007. Huntsville, 2007. Surdu, John R.,"The Deep Green Concept," Spring Simulation Multiconference 2008 (SpringSim'08), Military Modelling and Simulation Symposium (MMS). Ottawa, 2008.
Geoge A Miller, "The magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information," The Psychological Review, 1956, 63: 81-97.
Yann LeCun, Yoshua Benjio, Geoffrey Hinton, "Deep Learning," Nature, 2015, 521:436-444.
Brenden M. Lake, Ruslan Salakhutdinov, Joshua B.Tenenbaum, Human-level Concept Learning Through Probabilistic Program Induction, Science. 2015, 350:1332-1338.
http://www.cetin.net.cn/gcw/index.php?m=content&c=index&a=show&catid=9&id=17945.
王涛:《美军打造无人机系统训练战略》,《现代军事》,2015年第7期,第99页。
Lt Gen David A.Deptula, "A New Era for Command and Control of Aerospace Operations" Air & Space Power Journal, July–August 2014.
责 编/凌肖汉
Abstract: The military command information system has made outstanding achievements, but it also faces great challenges, the biggest one comes from intelligent technology. How to understand the role and function of intelligent technology in the future war and help to make a breakthrough in the research on the key intelligent technology are the problems that must be faced in the construction of the Chinese command information system. Taking the development process of the American "Deep Green" project as an example, this article analyses the intelligence-related problems existing in the development of the current command information system, and by referring to intelligent technology breakthroughs like AlphaGo, explores the development direction of the command information system as well as the way to make it intelligent.
Keywords: command information system, artificial intelligence, depth learning, situation understanding
