两种基于K近邻特征选择算法的对比分析
2016-09-08薛又岷严玉萍古嘉玲包晓蓉
薛又岷,严玉萍,古嘉玲,包晓蓉
(江苏科技大学 计算机科学与工程学院,江苏 镇江 212003)
两种基于K近邻特征选择算法的对比分析
薛又岷,严玉萍,古嘉玲,包晓蓉
(江苏科技大学 计算机科学与工程学院,江苏 镇江212003)
在特征选择过程中,针对近邻错误分类率较低的问题,分别采用正向贪心和逆向贪心思想设计了两种启发式特征选择算法,其目的是在降低数据集中特征数量的同时,能够进一步降低近邻错误分类率。通过8组UCI数据集上的交叉验证结果表明,相比于正向贪心算法,逆向贪心算法能够删除较多的冗余特征,从而得出逆向贪心算法能够更有效地提高近邻算法的分类精度的结论。
特征选择;启发式算法;贪心算法;近邻错误分类率
特征选择,是机器学习与人工智能领域[1-4]内的一项重要研究内容。众所周知,在数据集中,每个特征的重要程度是不同的,而特征选择就是考虑在一些评价指标的前提条件下,选择出数据集中重要的特征并删除其中不相关或冗余的特征,以达到简化知识表示与数据分析的目的。近年的研究成果表明,现有的很多特征选择算法大致可归为两类:Filter算法与Wrapper算法[5]。一般来说,Filter算法在特征子集的评价过程中 (特征选择)不考虑数据的分类或学习过程,而Wrapper算法往往利用某种分类性能作为评价指标,并采用一定的搜索策略[6]加以实现。在现实世界中,由于数据规模的高速增长,目前已经出现了多种类型的优化搜索策略,其中启发式算法作为一大类搜索方法,采用贪心的基本思想,以较快的速度逼近问题的精确解或近似解,因而受到了众多研究学者的广泛关注。
在Wrapper算法[7]中,分类性能是一项重要的评价指标。作为十大经典分类算法之一,KNN(K近邻)方法由于其分类思想简单且易于实现,因而在许多领域得到了广泛的应用。但在实际应用中,当训练样本的特征较多时,KNN算法通常会面临时间效率低下,精度下降等一系列的不足。为解决这一问题,本文将采用两种不同的贪心搜索策略并设计基于K近邻分类器的特征选择算法,其主要目的是选择出对于分类影响较大的特征并剔除冗余特征,因而利用该思想有望提高KNN的分类性能。
1 基本知识
KNN算法[8]的主要分为3步:首先,计算待分类样本与已知类别的训练样本之间的距离或相似度,找到与待分类样本最近的k个样本,称之为待分类样本的k个近邻;其次,根据这些样本所属的类别来判断待分类样本的类别,如果待分类样本的k个近邻都属于同一个类别,那么待分类样本也属于该类别;否则的话,对每一个候选类别进行评分,按照一定的规则来确定待分类样本的类别。
K近邻算法中的分类决策规则往往遵循多数表决[9],多数表决是指由待分类样本的k个近邻(训练样本)所得到的多数类别来决定输入样本的类别。尽管K近邻算法可以在一定程度上有效地判断出待分类样本的类别,但其结果往往也伴随着误差,这样的误差文中称为近邻错误分类率。
定义1给定一个分类任务,分类函数为

其中ci为类别标记,x为待分类样本。
定义2对给定的待分类样本x,可构建判别函数
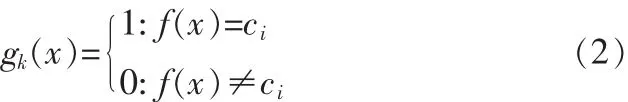
其中ci为x的真实类别标记,k表示采用KNN分类器。
定义3对于一组给定的样本集合X,特征集合为C,则该组样本的近邻正确分类率为

其中|X|表示集合X的基数。
定义4对于一组给定的样本X,特征集合为C,对于a埸C,特征a相对于特征集合C的重要度为
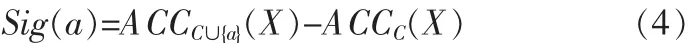
2 基于贪心策略的K近邻特征选择算法
所谓特征选择,是指从原始特征中选择出一些最有效的特征以降低数据维数的过程[10],是提高学习算法性能的一个重要手段,也是数据挖掘、机器学习与模式识别中关键的数据预处理步骤。
其实,在样本分类的过程中,有些特征对于分类的贡献度很小,甚至毫无贡献。显然,在这种含有冗余特征的样本中利用KNN分类器进行分类[11],会在一定的程度上影响分类的正确率。如果将那些对于分类重要的特征选取出来,以此组合成为一个新的测试样本,然后在这个新的测试样本上分类,就可以提高传统的K近邻算法的分类精度从而降低近邻错误分类率。根据这一思想,本文设计了两种基于贪心策略的K近邻特征选择算法。
2.1正向贪心特征选择算法
给定的一组待分类样本集合X,正向贪心特征选择算法可以分为2步:首先,利用正向贪心选择出重要度较大的特征,并将该特征加入到候选特征集合Red中,从而构建新的测试样本集;其次,不断重复上述步骤直到分类精度ACCRed(X)不再上升。
根据定义3所示的特征重要度,正向贪心特征选择算法如算法1所示:
算法1正向贪心特征选择算法(FGA)
输入:待分类样本集合X,特征集合C。
输出:所选择出的特征集合Red。
步骤1:计算ACCC(X);
步骤 4:选择特征 b∈C且满足 Sig(b)=max{Sig(ai):ai∈C},若Sig(b)>0,令Red=Red∪{b},C=C-Red;转至步骤3,否则转至步骤5;
步骤5:输出Red和ACCRed(X)。
2.2逆向贪心特征选择算法
给定的一组待分类样本集合X,逆向贪心特征选择算法可以分为2步:首先,利用逆向贪心选择出重要度较大的特征,并将该特征加入到候选特征集合Red中,从而构建新的测试样本集;其次,不断重复上述步骤直到分类精度ACCRed (X)不再上升。
算法2逆向贪心特征选择算法(RGA)
输入:待分类样本集合X,特征集合C。
输出:所选择出的特征集合Red。
步骤1:计算ACCC(X);
步骤2:Red←C,ACCRed(X)=ACCC(X);
步骤3:坌ai∈Red,计算属性ai的重要度Sig(ai)=ACCRed(X)-ACCRed-{ai}(X);
步骤4:选择特征b∈C且满足Sig(b)=min{Sig(aj):坌aj∈C},若Sig(b)>0,转至步骤6,否则转至步骤5;
步骤5:令Red=Red-{b},转至步骤3;
步骤6:输出Red和ACCRed(X)。
通过计算,可以得到传统的K近邻特征选择算法的时间、空间复杂度分别为O(n2)和O(n)。而基于贪心策略的K近邻特征选择算法的时间、空间复杂度均为O(n),其中n表示数据中特征的个数。因此,正向贪心特征选择算法与逆向贪心特征选择算法可以一定程度提高算法效率。
3 实验结果
为了验证算法的有效性,本文选取了8组UCI数据集,并进行了3组实验。这8组数据集的基本信息如表1所示。实验1是将本文提出的正向贪心算法与传统的KNN算法进行对比分析;实验2是将本文提出的逆向贪心算法与传统的KNN算法进行对比分析;实验3是将本文提出的正向贪心算法与逆向贪心算法进行对比分析。这3组实验中我们都采用10倍交叉验证的方法。实验环境为PC机,双核2.1 GHz CPU,2 GB内存,Windows 8操作系统,MatlabR 2014a实验平台。

表1 数据集的基本信息Tab.1 The information of used databases
实验1正向贪心特征选择算法
在实验1中,我们将正向贪心特征选择算法(FGA)与传统的K近邻算法(KNN)进行了对比分析,结果如表2所示。从表2可以看出,所提出的正向贪心特征选择算法可以在部分数据集上有效地减少特征个数:如Abalone数据集原始数据有9个特征,利用正向贪心特征选择算法(K=5)选择出了2个特征,同时分类精度提高了近3个百分点。由此可以看出在部分数据集中通过正向贪心策略进行特征选择,可以去除原始数据中的冗余特征(降低了数据的存储空间),从而可以提高了KNN分类器的时间效率。因此正向贪心特征选择算法在特征选择和分类时间方面具有一定优势。但同时值得注意的是,特征数目的减少有可能带来分类精度的降低,如Wine Quality数据集原始数据有12个特征,利用正向贪心特征选择算法(K=1)选择出了2个特征,分类精度相比于原始分类精度下降了近25个百分点,这是由于正向贪心策略的终止条件是分类精度不再上升,此时得到的分类精度有可能会小于利用所有特征所得到的分类精度。

表2 正向贪心算法与KNN算法的比较Tab.2 The comparison between forward greedy algorithm and KNN algorithm
实验2逆向贪心特征选择算法
在实验2中,我们将逆向贪心特征选择算法(RGA)与传统的K近邻算法(KNN)进行了对比分析,结果如表3所示。从表3可以看出,利用所提出的逆向贪心特征选择算法可以大幅度减少特征数,如在Breast Cancer Wisconsin数据集上,原始数据拥有31个特征,而逆向贪心特征选择算法(K=1)仅选取了6个特征。由此可以看出通过逆向贪心策略进行特征选择,可以去除原始数据中的冗余特征(降低了数据的存储空间)。此外,值得注意的是利用逆向贪心特征选择算法得到的特征子空间可以有效地提高分类精度。原始数据通过逆向贪心特征选择,去除了数据集中的冗余特征,且保留原数据集的特征信息,从而在保持分类精度上升或与原始分类精度差别不大的前提下,降低了时间和空间复杂度。因此,相比于传统的K近邻算法,逆向贪心特征选择算法更加有效。

表3 逆向贪心算法和KNN算法的比较Tab.3 The comparison between reverse greedy algorithm and KNN algorithm
实验3正向贪心特征选择算法与逆向贪心特征选择算法的比较
在实验3中,我们将正向贪心特征选择算法(FGA)与逆向贪心特征选择算法(RGA)进行对比分析,如表4所示。从表4可以看出,利用逆向贪心特征选择算法所选取的特征数在大多数数据集上要少于利用正向贪心特征选择算法所选取的特征数,且利用逆向贪心特征选择出的特征子集进行分类,其分类精度要普遍高于利用正向贪心特征选择出的特征子集进行分类所求出的分类精度。
4 结 论
为了进一步降低K近邻算法的近邻错误分类率,本文结合正向/逆向贪心搜索策略所设计了两种启发式特征选择算法。由实验结果可知,正向贪心特征选择算法仅能降低数据集中特征数量,但往往不能降低近邻错误分类率。而相比于正向贪心算法,逆向贪心算法不仅能够删除较多的冗余特征,而且能够更有效地提高近邻算法的分类精度。因此所提出的算法是有一定现实意义的。

表4 正向贪心算法和逆向贪心算法的比较Tab.4 The comparison between forward and reverse greedy algorithms
在本文工作的基础上,笔者下一步会尝试将正向/逆向贪心搜索策略与其他类型的分类器(如支持向量机SVM,决策树等)相结合,并将其应用到蛋白质二级结构类预测的问题上。
[1]Qian Y H,Liang J Y,Pedrycz W,et al.Positive Approximation:An Accelerator for Attribute Reduction in Rough Set Theory[J].Artificial Intelligence,2010,174(9-10):597-618.
[2]Yang X B,Yu D J,Yang J Y,et al.Dominance-based Rough Set Approach to Incomplete Interval-valued Information System[J].Data&Knowledge Engineering,2009,68(11): 1331-1347.
[3]Yang X B,Yang Y,Wu C,et al.Dominance-based Rough Set Approach and Knowledge Reductions in Incomplete Ordered Information System[J].Information Sciences,2008,178(4):1219-1234.
[4]Qian Y H,Liang J Y,Pedrycz W,et al.An Efficient Accelerator for Attribute Reduction From Incomplete Data in Rough Set Framework[J].Pattern Recognition,2011,44(8):1658-1670.
[5]Zeng Z L,Zhang H J,Zhang R,et al.A Novel Feature Selection Method Considering Feature Interaction[J].Pattern Recognition,2015,48:2656-2666.
[6]Ding J Y,Song S J,Gupta J,et al.An Improved Iterated Greedy Algorithm With a Tabu-based Reconstruction Strategy for the No-wait Flowshop Scheduling Problem[J].Applied Soft Computing,2015,30(5):604-613.
[7]Kohavi R,John G H.Wrappers for Feature Subset Selection [J].Artificial Intelligence,1997,97(1-2):273-324.
[8]Hu Q H,Pedrycz W,Yu D R,Lang J.Selecting Discrete and Continuous Features Based on Neighborhood Decision Error Minimization[J].IEEE Transactions on Systems,Man,and Cybernetics-Part B:Cybernetics,2010,40(1):137-150.
[9]梁立东,叶邦彦.一种最近邻像素值的极大概率滤波算法[J].电子设计工程,2014(7):181-183,187.
[10]刘轩,王卫红,唐晓斌,等.遗传算法在SAR图像目标鉴别特征选择上的应用[J].电子科技,2014(5):140-144.
[11]景永霞,苟和平,冯百明,等.不均衡数据集中KNN分类器样本裁剪算法[J].科学技术与工程,2013(16):4720-4723.
A comparison between two KNN based feature selection algorithms
XUE You-min,YAN Yu-ping,GU Jia-ling,BAO Xiao-rong
(School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang 212003,China)
To reduce the nearest neighbor error classification rate in feature selection,two heuristic algorithms are proposed by using the forward and reverse greedy ideas,respectively.The purpose of our paper is not only to reduce the features in data sets,but also to further reduce the nearest neighbor error classification rate.By the cross validation on eight UCI data sets,the experimental results show that the reverse greedy algorithm can not only remove more redundant features,but also can effectively improve the classification accuracy of the nearest neighbor algorithm.
feature selection;heuristic algorithm;greedy algorithm;nearest neighborhood error classification rate
TN18
A
1674-6236(2016)01-0019-04
2015-06-11稿件编号:201506121
国家自然科学基金(61305058);中国博士后科学基金(2014M550293)
薛又岷(1995—),男,江苏南京人。研究方向:粗糙集、粒计算与数据挖掘。
