一种基于Cache机制的嵌入式Flash控制器设计
2016-09-08李凌浩黄雅东吴中海
曹 健 李凌浩 黄雅东 吴中海 张 兴,2
1(北京大学软件与微电子学院 北京 100871)2(北京大学信息科学技术学院 北京 100871)
一种基于Cache机制的嵌入式Flash控制器设计
曹健1,2*李凌浩1黄雅东1吴中海1张兴1,2
1(北京大学软件与微电子学院北京 100871)2(北京大学信息科学技术学院北京 100871)
嵌入式Flash(eFlash)在SoC中的运用日益广泛,而Flash较慢的读取速度与处理器高频取指之间的矛盾愈发突出。针对该问题,在Flash控制器中引入Cache机制,并运用组相联映射、优化的“最近最少使用”LRU(Least Recently Used)替换算法、流水预填充结构对Cache进行多方面优化。与未加入Cache机制的Flash控制器相比,加入Cache机制的Flash控制器可使处理器取指时间节省38%。
嵌入式FlashCache组相联映射LRU流水预填充
0 引 言
嵌入式Flash(eFlash)是一种和传统CMOS工艺相兼容,内嵌于芯片内部的非易失性存储器。eFlash以低成本、高安全性等特点,在SoC领域应用广泛,常作为系统的程序存储器。然而,eFlash较慢的读取速度,易成为系统瓶颈。特别是随着工艺特征尺寸的缩小,eFlash与处理器频率差距逐渐增大。本文针对这一问题,在Flash控制器中引入Cache机制,缩小了两者的速度差距。同时Cache复用了控制器内部逻辑,节约资源的同时便于工具综合优化。
Cache由Wilkes于1965年提出[1],其原理是根据程序局部性原则,通过小容量速度快的存储器缓存部分指令或数据,以减少处理器对慢速大容量存储器的访问次数。Smith于1982年提出了Cache设计的三个基本参数——容量、关联度、行长,分析了容量与程序循环体,关联度、行长与Cache命中率之间的关系,以及它们对整体性能的影响[2],为以后的Cache设计提供了基本思路。Puzak从Cache替换算法的角度进行分析,提出了经典的LRU替换算法[3]。Chan等从预填充的角度,提出了辅助缓存结构[5],解决了“Cache 污染”的问题,提供了另一种提升Cache性能的思路。2008年,Baker等提出了4至6路组相联动态分配的映射方法[10],可有效降低1%的Cache块冲突。Ricardo等对Cache可重构技术进行研究[11],通过改变Cache容量、关联度、替换算法等结构参数,实现Cache对不同应用场景下的动态或静态重构。Shan等于2011年提出了EBA-LRU-SEQ算法[12],该算法在LRU算法基础上加入分支预取表,可降低54%的Cache功耗。
本文将Cache引入Flash控制器,通过映射结构、替换算法和预填充三方面的优化,对Cache性能进行提升。在映射结构上,以“容量”、“关联度”、“行长”为研究起点,通过实验对比,选择性能、面积最优的4组4路组相联映射。在替换算法上,本文对LRU算法进行改进,新的算法以更小的硬件消耗取得与LRU相似的性能。在预填充方面,将文献[5]的辅助缓存与流水线相结合,实现了处理器的顺序无间断取指。实验数据表明,与未加入Cache机制的Flash控制器对比,Cache机制的引用可节省38%的取指时间。
1 Flash控制器架构
Flash控制器的整体架构如图1所示,采用哈佛结构的处理器通过指令总线从Cache取指,通过外设总线配置专用寄存器(sbus_sfr)传递Flash操作命令。主状态机(main_fsm)根据SFR配置,对“编程擦除控制器”(pe_ctrl)及Cache进行调度。“编程擦除控制器”(pe_ctrl)在取得Flash总线控制权后,进行相应的Flash操作。由于主状态机的统一调度及Flash读逻辑的复用(fl_rd),相较于Cache和Flash控制器分离的设计,内嵌Cache节约了资源,减少了模块间的信号交互,利于综合工具的优化。
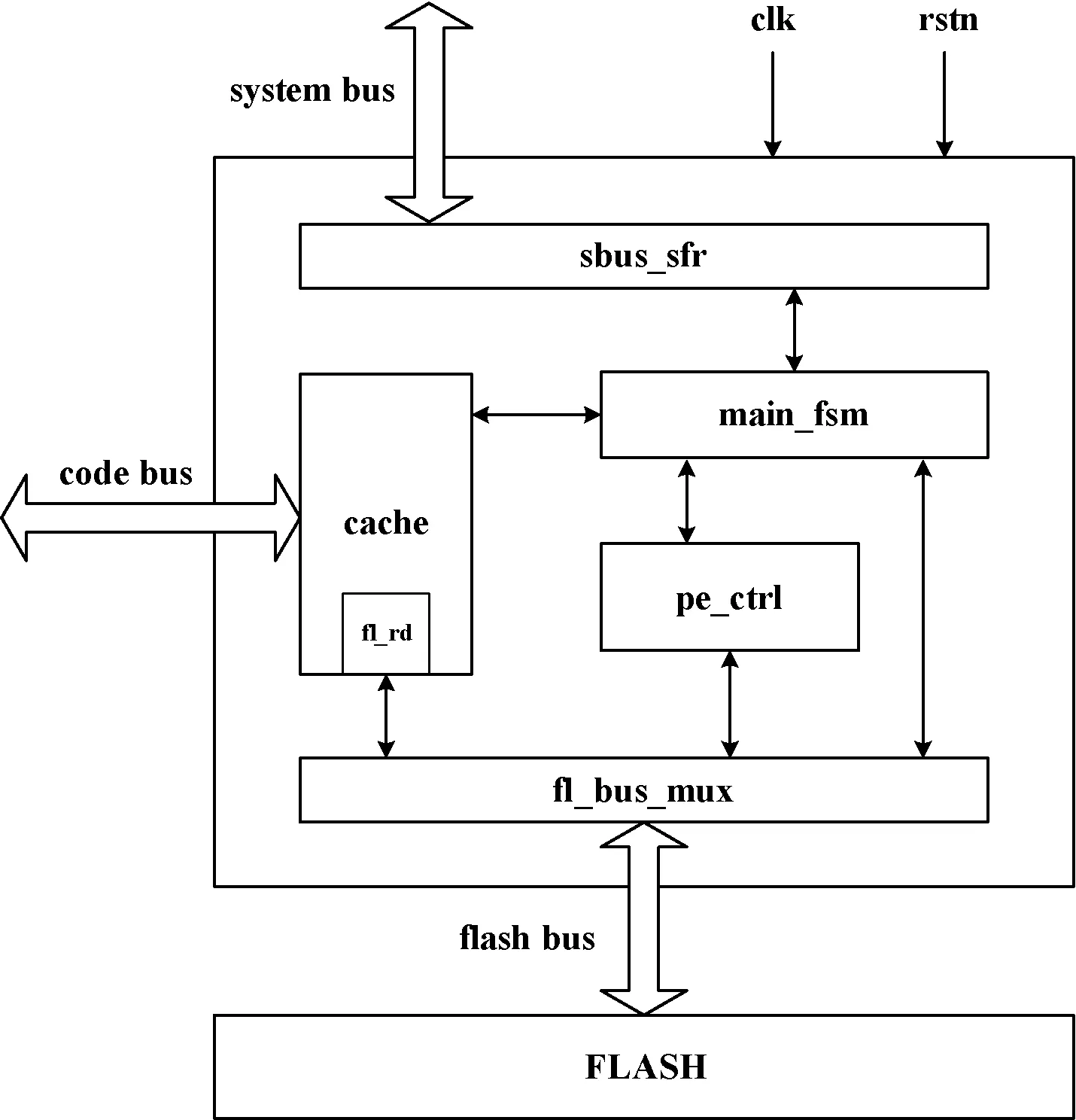
图1 Flash控制器架构
2 内嵌Cache设计
内嵌Cache结构如图2所示,其主缓存容量为256 Byte,映射结构为4组(Set)4路(Way)组相联,每路大小为128 bit。其替换算法采用基于LRU的改进算法。另外,其内置128 bit的辅助流水缓存(Victim Way),用于实现顺序无间断取指。
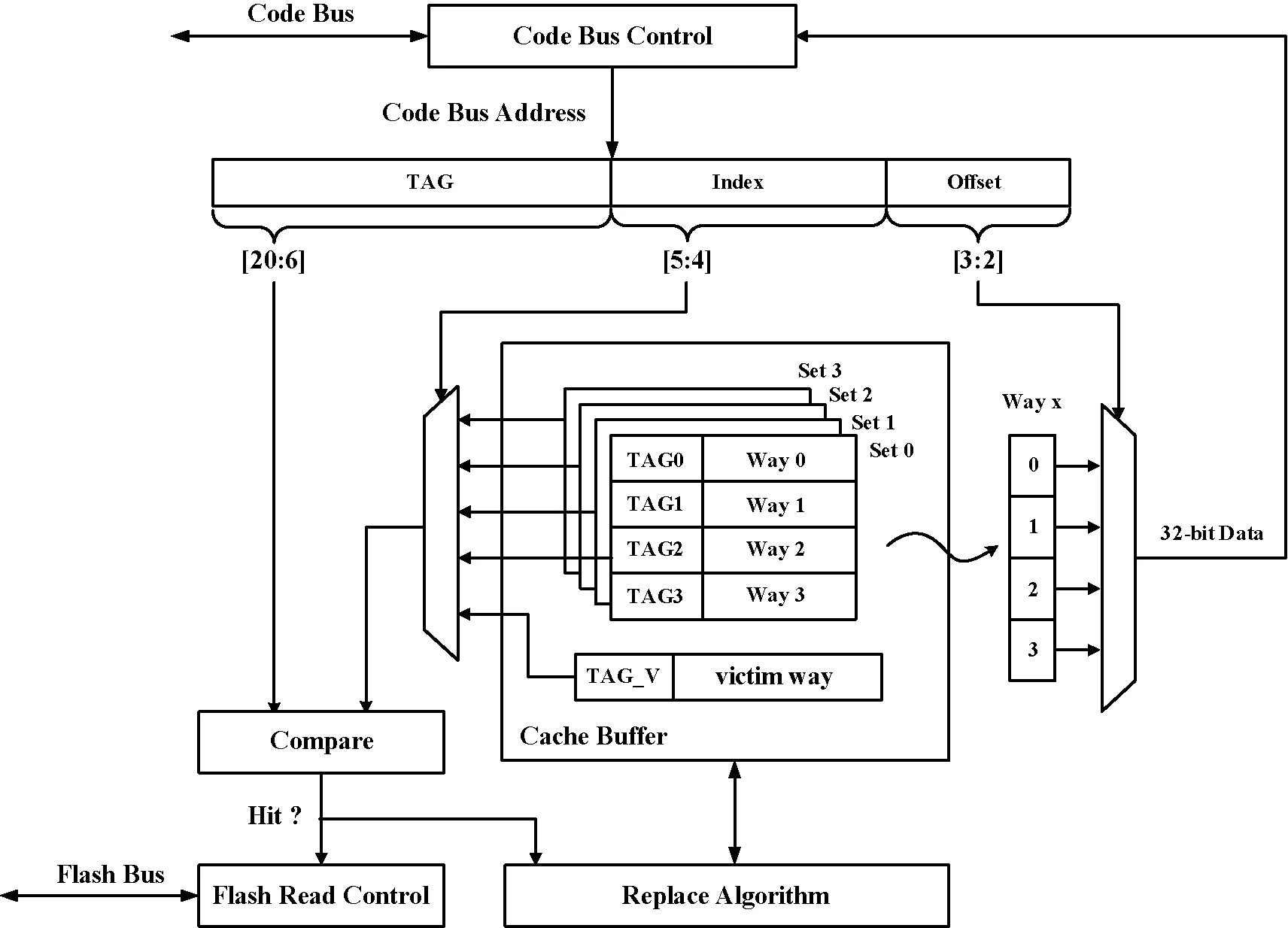
图2 内嵌Cache结构
Cache工作流程为Code Bus发起读操作,根据Code Bus地址Index段选中四组中的某一组,然后将该组所有路的TAG与Code Bus的TAG段进行匹配,确定Cache命中或缺失。当命中某路,用地址Offset段选通128 bit数据中的某个32 bit数据输出。如果4路均未命中,而命中辅助缓存,则缓存数据输出,并按替换算法将该数据写入某组某路,同时开始新的预取指。如果均未命中,则挂起总线,进行Flash读操作,读取的数据按替换算法写入某组某路输出,并判断是否进行预取指操作。
2.1地址映射方式
文献[2]提出Cache的映射方式需由容量、关联度、行(路)长度三个参数来确定。根据程序局部性原则,当其他参数不变,Cache容量可装载程序最大循环体时,其性能最优[1]。通过对项目嵌入式应用程序的统计,其循环体大多介于20 byte至192 byte之间,考虑到存储的冗余量,确定Cache容量为256 byte。从文献[6]的实验对比可知:当缓存容量小于16K byte时,组相联映射配合替换算法的性能远优于直接映射,故缓存组织形式确定为组相联映射。另外,由于所选Flash最慢读取速率为30 M,而处理器工作频率为120 M,且每次取指32 bit,为实现辅助缓存的流水结构,确定每一“路”(Way)的宽度128 bit。上述变量确定后,关联度则是通过各组合代码实现后的实验对比来确定。
实验的测试向量由循环嵌套程序组成,Cache缺失率是通过 Synopsys公司的VCS对电路cache_miss信号的高脉冲个数统计获得(该信号高脉冲表明Cache缺失)。如表1所示,“2组8路组相联”性能最优,但由于实现“2组8路组相联”需复杂的TAG比较器,导致资源开销大,且时序不能满足实际需求,故折中选择“4组4路”组相联方式,其结构如图2所示。在该结构中,将指令地址划分为三段,Index用于选择“组”号;TAG为“路标”,用于确定某路命中或Cache缺失;当某路被命中后,用Offset选通128 bit数据中的某个32 bit数据。
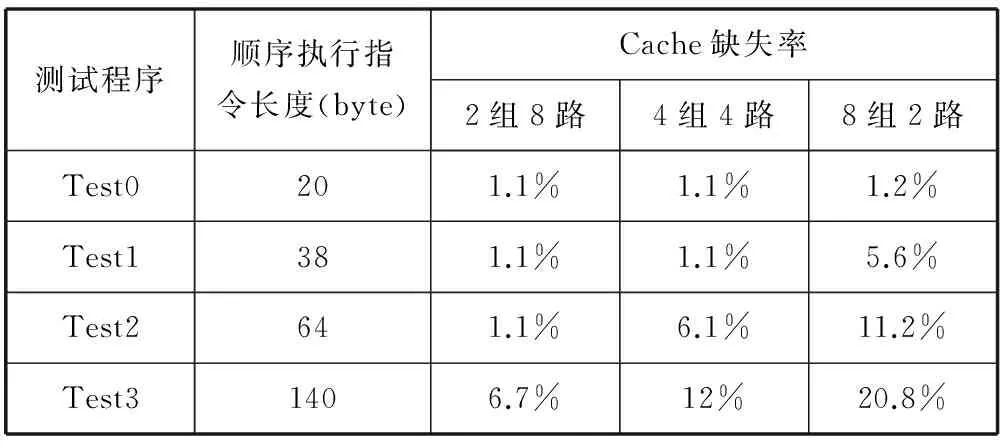
表1 组相联性能对比
2.2替换算法
文献[3]对Cache的各种替换算法进行对比,并提出了LRU替换算法,即根据最近最少使用原则进行替换。其原理是N路组相联需在每一路之前添加一个N位计数器记录每一路的使用情况,采用循环计数,增量为1。当需要替换时,将计数值最小的路替换。相较伪随机或FIFO算法,LRU体现了程序局部性的特点,故性能更优,但其复杂度相对较高,硬件资源消耗大且关键路径长。
本设计对传统的LRU算法进行优化,如表2、表3所示。优化后的算法面积及关键路径比LRU减少10%,而性能与LRU相似。该算法与LRU的主要区别是记录每行最近最多使用的情况,从而使计数器的位宽减半。算法整体思路是在每“路”之前增加“log2N”(N为“路”的数量)位的计数器,用于记录各“路”的使用频率。当某“路”被命中时,其计数器变为最大值,即使用频率最高,其他各路按一定原则计数值递减;当Cache缺失时,将计数值为0的“路”进行替换。使用频率的计数原则如图3所示,首先将所有计数器的值由大到小进行初始化;之后如果命中计数值最大的一路,则所有计数器的值保持不变;如果命中非最大值的任意一路,比该路计数值大的其它各路均减1,同时该路的计数值更新为最大值;如果所有路均为命中,则将计数为0的路更新为最大值,其他各路均减1。

表2 各算法面积对比
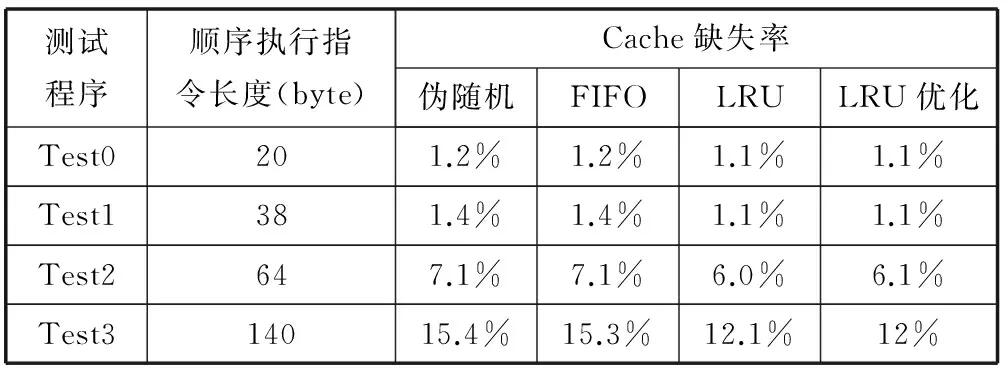
表3 各算法性能对比

图3 优化的LRU替换算法
以4路组相联为例,如图4的“Step 0”所示,每路之前有2 bit计数器,各计数器初始值从2’b11至2’b00依次递减,2’b11表示该路使用频率最多,2’b00表示该路使用频率最低;在“Step1”中,当命中“Way2”后,其计数值变为2’b11,其他各路计数器进行递减;当Cache缺失发生,如“Step 2”所示,“Way 3”将被替换,其计数值变为2’b11,其他各路计数器进行递减。
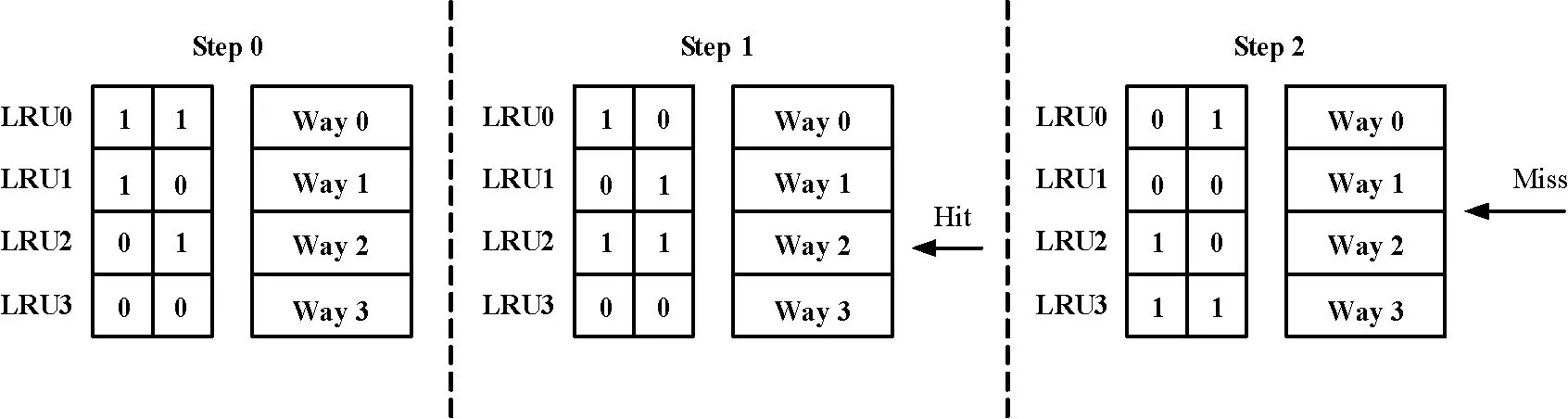
图4 优化的LRU算法图例
表2中的各项数据是通过对不同算法进行代码实现,并使用TSMC 90 nm标准单元库进行物理综合得到,其综合工具为Synopsys的Design Complier。表3中各算法Cache缺失率的获得与表1所对应的实验相同。
2.3预填充策略
预填充是一种提前从慢速存储器中读取数据写入Cache,以降低Cache缺失率的操作。其主要分为顺序预填充和非顺序预填充。顺序预填充仅按地址顺序进行预取,不需对处理器取指进行预测,硬件实现简单,适合嵌入式系统[9]。预填充可提高取指效率,但也会引入“Cache污染”的问题,即预取数据未被处理器所用,而被替换的数据却是真正所需的指令。为解决该问题,出现了辅助缓存[5]及牺牲缓存[4]等辅助结构。辅助缓存的思路是将预取数据先写入辅助缓存,当Cache命中该数据后,再按替换算法写入主缓存区。牺牲缓存则是将预取的数据写入主缓存区,将被替换的数据写入牺牲缓存。两种方法均可有效地解决“Cache污染”的问题。
本文将“顺序预取”、“辅助缓存”与“流水控制”相结合,实现了处理器顺序读取下的不间断取指。其原理是根据Flash与处理器工作频率相差4倍的关系,选定Flash读数据宽度、辅助缓存宽度为指令长度的4倍即128 bit,使一次消耗4个系统时钟的Flash读取可输出4条指令。当处理器取走第一条指令时,控制逻辑将辅助缓存的数据转移至主缓存,并开始新一轮的辅助缓存填充,从而实现流水预取指操作。具体时序如图5所示。

图5 流水预填充时序
T0时刻,Code Bus(AHB总线)读使能(p2c_rd)有效,对A0地址进行读操作。假定此次操作为Cahce缺失,Cache拉低c2p_ready信号挂起处理器。同时,对Flash发起读操作(c2m_rd拉高),进行第一次填充。
T1时刻,c2m_rd拉高后4个系统时钟(clk),Flash输出128 bit数据,将A0对应数据输出(c2p_rdata)。
T2时刻,因A0数据已输出,可视为一次Cache命中,故128 bit Flash数据直接写入主缓存的某一路(way_x)。因此时处理器还在顺序取指,故Cache继续进行Flash流水预取(c2m_flash一直有效),T3时刻将Flash数据输出。
T4时刻,假定处理器进行跳转取指(p2c_addr返回A0),Cache从主缓存输出A0数据的。下一时钟,预取的Flash数据被写入辅助缓存(way_v)。
T5时刻,处理器返回原有顺序取指(p2c_addr返回A8),辅助缓存数据被输出。下一时钟,辅助缓存数据被写入主缓存。当Cache发生缺失或处理器进行非边界跳转读取(跳转地址非Flash输出128 bit数据的首地址),Cache会挂起处理器,进行新的流水线填充。
上述流水控制有效地结合了辅助缓存和顺序取指,以4个时钟填充流水线的极低代价,使处理器能够顺序无间断取指,提升了程序的运行效率。
3 Flash控制器性能测试
Cache设计需满足程序局部性原则,而程序局部性主要表现形式为“循环体”,故Cache的测试程序由循环体相互嵌套组成,通过改变循环中顺序执行的指令长度来测试被测对象的性能。
测试的参照对象为“Flash控制器第一版”和飞思卡尔的K21芯片。第一版Flash控制器未加入Cache机制,其只有简单的256 bit缓存结构。当处理器顺序读取时,该控制器可实现流水取指,如出现跳转取指,则需要挂起处理器重新填充缓存。飞思卡尔的K21芯片是一款目前应用于支付终端的主流MCU,其包含同样大小的Cache,且处理内核与本设计相同,可作为参照对象。
测试方法是在测试程序的开始和末尾加入GPIO翻转指令,通过使用精密示波器采集两次GPIO翻转的时间间隔,来确定程序执行时长。
从表4的实验数据可知,相对于未加入Cache机制的控制器,引入Cache机制的控制器可使处理器取指时间节省38%,与主流Flash控制器飞思卡尔的K21芯片性能相当。

表4 Flash控制器性能对比
4 结 语
本文实现了一种基于Cache机制的Flash控制器,与Cache和控制器分离的设计相比,本设计结构更加紧凑,利于综合工具优化。内嵌Cache的设计从映射结构、替换算法、预填充三个方面进行。在映射方式上,通过需求分析及实验对比,确定内嵌Cache采用4组4路组相联映射。对比8组2路映射,该映射方式最大可降低8.8%的Cache缺失率。在替换算法上,本文提出“优化的LRU算法”,并对FIFO、伪随机、LRU及“优化的LRU算法”进行RTL实现及性能测试。通过测试对比,新算法的面积及关键路径比LRU减少10%,而性能与LRU相似,且优于其他替换算法。在预填充上,本文将“顺序预取”“辅助缓存”与“流水控制”相结合,实现了处理器顺序读取下的不间断取指,进一步提升Cache性能。最后,通过实验对比,对内嵌Cache的整体性能进行测试。相较于未加入Cache机制的控制器,本设计可使处理器取指时间节省38%,与当前主流Flash控制器飞思卡尔的K21芯片性能相当。
[1] Wilkes.Slave memories and dynamic storage allocation[J].Electronic Computers,IEEE Transaetionson,1965(2):281-293.
[2] Smith A J.Cache memories[J].ACM Computing Surveys,1982,14(3):473-530.
[3] Puzak T R.Analysis of cache replacement-algorithms[D].PhD thesis.University of Massachusetts Amherst,1985.
[4] Jouppi N P.Improving direct-mapped cache performance by the addition of a small fully-associative cache and pre-fetch buffers[C]// ISCA’90:Proceedings of the 17thannual international symposium on Computer Architecture. New York. NY, USA ACM. 1990:364-373.
[5] Chan K K,Hay C C,Keller J R,et al.Design of the HP PA 7200 CPU[J].Hewlett-Packard Journal:technical information from the laboratiories of Hewlett-Packard Company,1996,47(1):25-33.
[6] Hennessy J L,Patterson D A.计算机体系结构:量化研究方法[M].3版.北京:机械工业出版社,2002.
[7] 何勇,肖斌,陈章,等.一种低功耗的动态可重构Cache设计[J].计算机应用与软件,2009,26(8):247-250.
[8] 张轮凯,宋风龙,王达.一种针对片上众核结构共享末级缓存的改进的LFU替换算法[J].计算机应用与软件,2013,30(1):1-6,10.
[9] 薛燕.Cache预测技术的研究[D].西安:西北工业大学,2005.
[10] Baker Mohammand,Ken Lin,Paul Bassett,et al.A 65nm Level-1 Cache For Mobile Applications[C]//International Conference on Microelectronics,2008:5-10.
[11] Ricardo Quislant,Ezequil Herruzo.Teaching the Cache Memory System Using A Reconfigurable Approach[J].IEEE Transactions on Education,2008,51(3):336-341.
[12] Shan Yueer,Yu Zongguang.EBA-LRU-SEQ Data Cache Policy in DSP to Optimize the Power Consumption[J].Tsinghua Science and Technology,2011,16(2):164-169.
DESIGN OF AN EMBEDDED FLASH CONTROLLER BASED ON CACHE MECHANISM
Cao Jian1,2*Li Linghao1Huang Yadong1Wu Zhonghai1Zhang Xing1,2
1(SchoolofSoftwareandMicroelectronics,PekingUniversity,Beijing100871,China)2(SchoolofElectronicsEngineeringandComputerScience,PekingUniversity,Beijing100871,China)
Embedded Flash (eFlash) is widely used in SoC, but the contradiction became more prominent between the flash slow reading speed and the processor high-frequency fetch. To solve the problem, we introduce the cache mechanism in the flash controller, and use set-associative mapping, optimized LRU (Least Recently Used) replacement algorithm and pre-fetching structure to optimize the cache. Compared with the flash controller without cache, the flash controller with cache can enable the processor to take the time to save 38%.
Embedded flashCacheSet-associative mappingLRUPre-fetching
2015-10-28。曹健,讲师,主研领域:嵌入式系统设计,软硬件协同设计,抗静电保护电路设计。李凌浩,硕士生。黄雅东,教授。吴中海,教授。张兴,教授。
TP3
A
10.3969/j.issn.1000-386x.2016.08.053
