改进的基于代码污染识别安全警告的算法
2016-09-08牛霜霞莫坚松
牛霜霞 吕 卓 张 威,2 莫坚松,2
1(国网河南省电力公司电力科学研究院 河南 郑州 450000)2(河南恩湃高科集团有限公司 河南 郑州 450000)
改进的基于代码污染识别安全警告的算法
牛霜霞1吕卓1张威1,2莫坚松1,2
1(国网河南省电力公司电力科学研究院河南 郑州 450000)2(河南恩湃高科集团有限公司河南 郑州 450000)
由于静态代码审计工具具有自动化、不容易出错的特点,开发人员经常使用它来检测代码漏洞,但是检测出的代码漏洞的结果会产生大量的警告信息,开发人员必须手动进行检查和纠正。此工具的缺点是浪费开发人员大量的时间。通过对用户的输入以及敏感数据流的追踪来确定警告的缺陷是否真的被利用,从而减少静态检测工具产生的大量警告数量。同时提供给开发者更多真正能对软件产生威胁的警告信息。针对静态代码审计工具的缺点,研究三种不同的方法来提高静态代码审计工具的性能。第一,对于商业性的静态代码分析工具Coverity,重新分析它的结果,并且从安全的角度创建一组具体的相关警告。第二,对开放的源代码分析工具Findbugs进行修改,并只对被用户输入所污染的代码进行分析。第三,研发灰盒代码审计工具,此工具侧重于Java代码中的跨站脚本攻击XSS(Cross Site Scripting),使用数据流分析的方法来确定漏洞的切入点。实验结果证明工程B使警告数量降低了20%,工程E只产生了2%的警告,降低了工具产生警告的数量,为开发人员提供更多的信息来区分此警告是否是真正的安全威胁。
CoverityFindbugsXSS漏洞
0 引 言
在众多的研究[1-3]中,自动化的静态代码分析工具作为在开发早期检测漏洞的工具被提出,发挥了极大的作用,减少了程序员人工检查代码的时间。微软安全开发生命周期[4]也将静态代码审计工具作为软件开发中的一个重要组成部分。然而,行业研究显示静态代码分析工具在使用的过程中存在一些问题。在研究和观察中得知开发人员往往没能意识到这些安全警告,同时也没有对其进行纠正[5]。静态代码分析工具产生的报告中含有大量的警告信息使得这一问题变得更加严重[6]。本文同样发现当开发人员试图纠正一些错误的警告时,又产生了新的安全漏洞。研究表明,一些主流的静态分析工具产生的报告中只有约5%的警告是安全威胁。
少量真正有意义和大量晦涩难懂的警告信息杂糅在一起造成了开发者忽视静态检测工具产生的结果这一模糊情形。从某种角度,开发者认为这些警告不能带来麻烦或者产生真正的危害,从而认为警告信息没什么意义。本文将展示如何通过已有的静态代码检测工具进行一些限定,使得产生的结果报告更高效简洁。本文通过限定检测的对象为任何受到外部源影响的源代码,来降低产生的警告数量并且准确的定位由用户数据产生的源代码漏洞。
1 背 景
虽然目前有很多关于静态代码分析技术和一些关于静态检测效果的文献,但是很少有文献研究静态分析工具是如何用于企业和会给企业带来什么样的问题。文献[6]罗列出了大量的警告,但是这些警告很难进行归类[5],因此,开发人员很难分辨出与安全相关的警告。有必要确定一个外部攻击的警告的子集,这样可以使得开发人员更容易确定哪些警告对于安全性来说是重要的。
在开发过程中,代码审计工作者很早就用各种自动化静态代码审计工具对代码进行漏洞分析,因此,不需要花费很多的精力去研究这些漏洞。但是,代码审计工作者也希望静态代码分析工具可以检测出代码中真正的安全漏洞[6],这就需要对从静态分析工具中得到的警告进行严格的审查并记录成报告。代码审计工作者可以观察到哪些警告被开发人员纠正,哪些没有被纠正,同时也清晰地发现哪些漏洞容易被忽略,哪些漏洞永远不会对其进行修正。被忽略的漏洞通常是大量相似的不会形成安全威胁的警告,因为没有用户数据利用警告进行攻击。开发人员只会将这些警告看作是锦上添花的更正信息,因为开发人员不可能进入警告信息所需要的状态。因此这类漏洞容易被忽视并且永远不会被纠正。这种忽略警告的行为最早是在一个关于审查开发人员能否正确地从静态分析工具中识别安全警告的能力的研究[5]中发现的。
从对这类文献的研究来看,在产业化开发中,对静态代码工具的使用策略以及检测报告的正确评估是很有必要的。
2 研究方法
因为开发人员经常会忽略或误解安全警告,本文需要想办法来区分那些非常可能被开发人员误认为是安全相关的标识的警告,需要将源代码分割成很多部分。这些分割后的代码可以直接或者间接地被用户数据所影响,同时代码并不能被外部非用户数据来源所影响。本文通过研究流程敏感分析、过程间分析和上下文相关的数据流分析方法解决上述问题。由于这种方法非常详细和精确,在某些情况下可以使用更简单、快速的分析方法,但是为了简单起见在本文所有的分析中都是用相同的分析方法。数据流分析通常用于编译器的优化[7]中,在这个领域中,有无数的课题和研究利用了此种方法。因为本文关注已经被分析但还没有统一化的C++和Java代码,所以本文采用了几种已知的流分析方式和程序模块化方式,而并不是用自己定义的方法去解决。
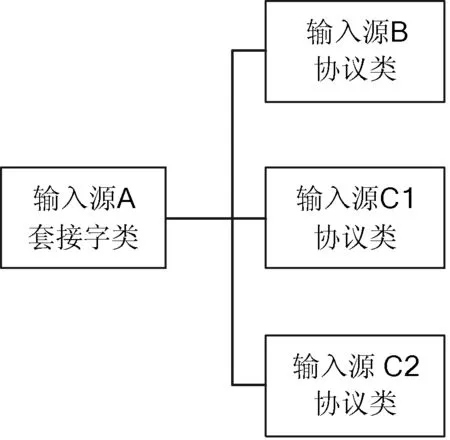
图1 污点输入源层次结构图
为了更好地筛选安全警告,首先,本文必须确定源代码中的数据入口点。入口点可以是任何类型的用户数据、甚至套接字、文件操作或其他的用户输入的操作。这是通过在不同的特定输入源中进行简单的词法分析来实现的。然而,仍有一些局限需要被解决。第一,对所有可能的输入源做数据流分析往往会导致大部分代码都被标记为污染代码,因此,有必要将输入源限定为特定的输入类型或者追踪那些被不同的输入源污染所影响的代码。本文通过结合这两种方法并且允许审核者决定如何处理输入源才能得到最好的结果。第二,由于面向对象的程序设计往往只有一个程序类,并且该程序类执行了由词法分析所确定的套接字操作,因此有必要继续进行分析并确定哪些代码或类使用了基础套接字类。这个操作可以创建输入源的层次结构[8],并且可以更加充分将结构展示给开发人员,以便开发人员能够确定威胁的根源。图1展示了这种层次结构。在这个例子中,输入源B和C是开发人员所关心的,而输入源A只是一个基类。
在确定了一个输入源之后,数据流分析将表明用户数据是如何通过源代码进行传播的。因为本文关心那些可以被服务软件用户所利用的漏洞,所以只需要在网络中检查输入源。一些检查器将用户数据所影响到的每一行都将被标记成被污染的代码,并对被污染的源代码进行专门的标记。比如,一个循环执行N次取决于用户输入变量的大小,然而,用户输入本身从来没有在循环内使用过。因此循环并不会直接被污染,与此同时缓冲区溢出检查器也会检查被污染的代码。
由于在面向对象的设计中,数据路径分析往往会中断和创建新的片段,分析将会从代码中原始类或对象所使用的位置开始重新启动。通过这种方式,本文可以将程序片段从开始到结束进行传递,如果数据流分析的过程中发现了已经被污染的代码有相同的上下文内容,它将会终止分析跟踪,以节省分析所消耗的时间。
最终的结果将是一个包含被污染的和未被污染的源代码树,以及带有可能污染路径的层次结构输入源。
由于Coverity[9]工具是一个商业化的非开源的源码工具,不能对其代码进行修改来分析被污染的代码。不过本文可以对Coverity工具分析的结果和污染源代码进行比较,如果一个警告存在于被污染的代码部分,可以根据它们的输入源进行组合,忽略未被污染的源代码中产生的警告。
本文可以改变Findbugs[10]工具的源代码,用此工具对被污染的源代码进行数据流分析。为了确保所有的被需要的代码都包括其中,还必须要加入变量初始化和其他的一些代码以保证分析不会失败。本文只对被污染的代码进行一个标准的Findbugs工具分析,来减少Findbugs工具分析时所必须检查的行数。
3 研究结果
3.1Coverity工具的分析
Coverity 工具审计了两个工程和一个类库。本文的关注点是在远程安全漏洞上,因此忽略了本地输入污染的影响。事实上,输入污点分析的使用要求检查器是特定的输入或者大部分将被标记为污染的源代码。在表1和表2中,警告的数量和被输入数据所污染的代码百分比被分布到不同的输入源中。通过比较代码的行和警告的数目,推测出该代码的差异。在大多数情况下,存在一个第一次创建的套接字类,然后其他的类使用这个基础的套接字类来处理不同的协议。在这些情况下创建的初始的套接字类并未考虑到入口点,而是考虑使用基础套接字类的协议。这样做的目的是增强用户的可读性,而是采用了何种协议或命令来启动污点来作为重要的入口点而不是套接字类。在工程A中,头两个输入源对它们的数据进行的遍历非常相似,得到的大多数的代码和所有的警告都是相同的。然而,从工具中得到的报告警告的数量降到了只有总警告数的18%,明显减少了来自开发人员的负担。第三个输入源是一个新的协议,与其他的输入源之间存在着很小的交互作用。尽管如此,结合用户输入的所有三个来源,得到报告中的警告在1600个警告总数中占24%这个结果。从这个改进的报表中可以得出21%的漏洞是先前的研究中就被发现的,而剩余的则是通过非安全检查器发现的漏洞。
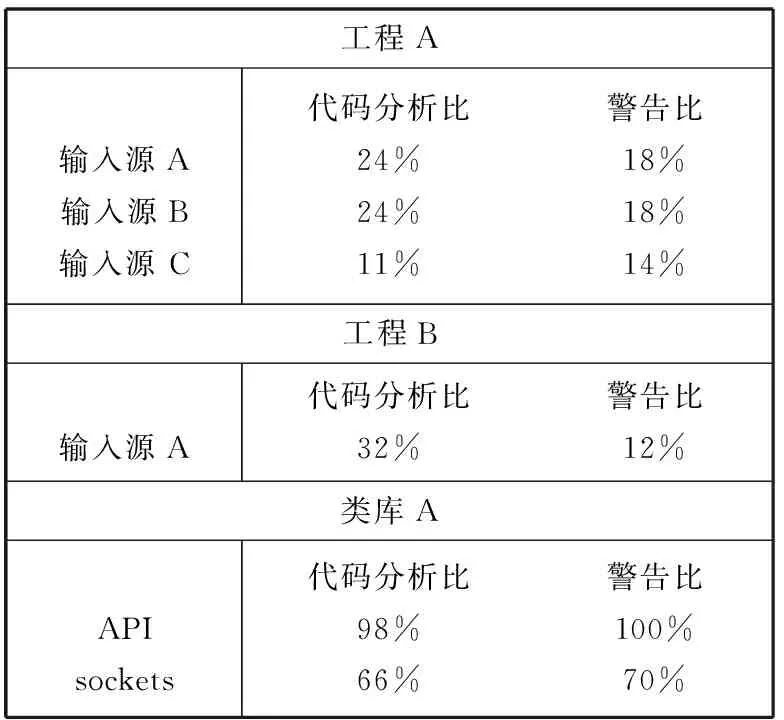
表1 Coverity工具分析结果
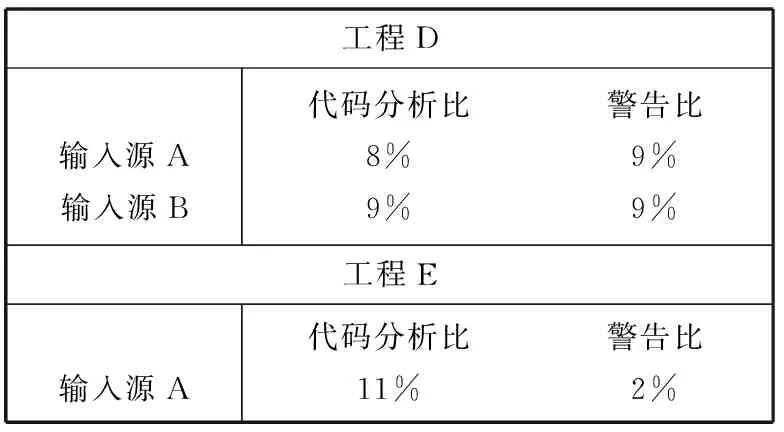
表2 改进的Findbugs工具结果
工程B明显降低了警告的数目,使得开发者有意愿对每个警告进行检查,而这些警告有可能危及产品的安全性或稳定性。但是与工程A进行对比,工程B的每行代码同样有较低数量的警告产生。由于污点分析,本文确保那些被忽略的警告并不是可利用的安全警告,因此,提高了静态代码分析工具的准确性。
3.2改进的Findbugs工具
对一个类库进行分析,是比分析一个工程更加困难的工作。如果整个API类库被认定为一个输入源[11],3.1节中方法将不再可用。通过限制其只对网络类进行污点分析仍然会检测大量代码并报出大量警告来,这就表明了对非服务器源代码使用输入污点分析是有限制性的。除了考虑到对API库进行处理时有限制性外,在进行文件操作和数据库的处理时,同样有相当大的问题。这主要取决于当这两个操作被执行时会丢失信息。数据流分析将会在数据库进行写操作时结束,不会再继续进行分析[12]。但是,用户数据却可以被阅读并且在代码的不同部分中使用。如果在数据库的读操作进行一轮新的污点分析,那么将会有大部分的代码会包括在其中,不会达到预期的效果。因此本文需要对数据库的使用执行更加智能化的分析。Java静态代码分析工具Findbugs并不像Coverity工具一样有大量的安全检查器。因此,当本文使用FindBugs工具对代码进行检查分析的时候出现的安全相关警告的数量会比Coverity低。这主要是因为Java语言更加安全和FindBugs静态代码分析工具更加成熟。
与C/C++产品相比,Java产品只有少量的警告产生[13]。因为Java产品并未对用户数据执行任何繁重的计算,这种设计也意味着会有较少的代码受到用户输入的直接影响。这样产生的少量的警告,使得审计者可以更加容易的对其进行核查。对于工程D来说,两个输入源尽管有着不同的代码路径,却有着基本完全相同的警告。经过其数据流分析之后,工程E就只产生了先前2%的警告。
3.3灰盒静态代码审计工具
最后,本文设计了一个新的静态代码审计工具,这个工具主要针对跨站点脚本攻击(XSS)漏洞的识别。通过确定用户输入源和反馈给用户的数据之间是否有数据流,就可以查找XSS漏洞。表2中只有工程D可能遭受到XSS漏洞的攻击,Findbugs工具并不会对单一的XSS漏洞作出报告,而此静态代码审计工具检测到了7个可能的XSS攻击威胁,所有被发现的漏洞在代码中都被利用进行攻击。由于在审查代码时,首先进行了输入验证,因此在最终产品中并不存在被攻击的情况。此代码审计工具同样对反射型XSS攻击的检测做了限制,反射型XSS通常会在一个错误的页面产生。而存储型XSS首先将数据保存到一个储存设施中,在将其发送给用户之前先对数据进行重新检索。由于本文将从数据库的检索中得到的用户输入信息的污点设置为安全,因此代码审计工具不会对数据库的读操作做任何的污点分析。在结果中,存储型XSS漏洞不会被报告出来,这样的分析是建立在准确度和少量警告以及误报之间的博弈。
限制静态代码审计工具来报告所有代码中可能的错误看上去好像很奇怪,然而,如果一个开发团队处在一个轻量级的开发上,大量的警告并不会在每一个版本发布出来前被尽数更正。事实上,这样一来静态代码审计产生的结果很难在项目开发中占有一个较高优先级的位置。对于静态代码审计工具来说,能将那些可以被认定为是安全威胁的警告与那些不可以被认定为是安全威胁的警告区分开来是非常重要的事情。不管是执行静态分析前还是进行分析后,都可以通过执行污点分析的方法将安全漏洞从其他的漏洞中区分出来。当使用Coverity工具时,工程A出现的警告数超过了1600个。如果假设每检查一个警告平均耗时3分钟,那么,对所有的这些警告进行审查将要需要80个小时。在轻量级产品开发中,这是一个非常耗时并且不实用的开发。当使用3种不同的网络协议对其进行处理后,确实将警告的总数量降到了24%。
面对一个少量一个大量的两份报告,开发人员一般都会忽略掉数量大的报告,而选择数量少的报告。相反地,根据不同的污染输入源对这些警告进行分组处理。通过流分析方式,开发人员可以将注意力主要放在那些存在较高概率报告出漏洞的警
告上面。通过了解错误是如何进入源代码中的这一问题,对警告进行审查的工作也变得比较简单。
本文集中对数据流分析的耗时进行了研究,包括流程敏感分析、过程间分析和上下文相关的数据流分析。但是,对源代码进行的处理也应该可以使用较少耗时的算法,事后,再用较多的时间对输入源标记的特殊的警告进行验证研究。由于Coverity 分析过程往往会消耗多个小时,因此消耗额外的几分钟对数据流进行分析并不影响分析的结果。相对于Findbugs工具的分析,Java源代码量比较小,整个分析过程会在几秒钟完成,并且数据流分析也主要集中在对网络输入进行处理的少量代码上。而为了对数据库进行处理,需要传输更多的信息,因此污点分析变得更加的复杂。为了降低复杂性,可以主要研究软件的设计。如果本文没办法对数据库的输入进行区分,那么整个数据库读取流程将被认定为是污染点。在这种情况下,污点分析可能将会对源代码中的大量的代码考虑使用别的分析方式,但是,如果能很好地区分,那么污点分析可以继续执行并且可以获得比较好的结果。
4 结 语
本文展示了静态代码分析过程中只对可能被外部用户数据所影响的警告进行过滤分析的益处。通过执行数据流分析和只报告或者分析这些特定的源代码,开发人员可以了解威胁的来源以获取更多漏洞的信息。并且对那些有较高概率被标记为漏洞警告的优先级的确定和审查也比较容易识别,这主要是因为将那些不受来源影响的警告和受到安全来源影响的警告进行了区分。分析可得,如果只对被污染的源代码进行分析,如降低四分之一被分析的代码(未受污染的代码)数量,就可以减少分析所消耗的时间,得出的警告的数量减少到了总数量的五分之一,漏洞的数量从5%增加到了将近25%。这样减少了开发人员所必须审查的无用的警告的数量,从而提高了静态代码审核工具的准确性,为开发人员节省了审计漏洞的时间。
从开发人员对产生威胁的数据源和小型报告感兴趣的情况来看,本文对警告进行优先级划分的方法将使得开发者在快速开发周期中获益,而在这样的周期中开发者恰恰难以保证所有的警告都得到更正。
[1] Brian Chess,Gary McGraw.Static Analysis for Security[J].IEEE Security and Privacy,2004,2(2):76-79.
[2] David Evans,David Larochelle.Improving Security Using Extensible Lightweight Static Analysis[J].IEEE Software,2002,19(1):42-51.
[3] John Viega,Gary McGraw,Tom Mutdosch,et al.Statically Scanning Java Code: Finding Security Vulnerabilities[J].IEEE Software,2000,17(5):68-77.
[4] Steve Lipner.The Trustworthy Computing Security Development Lifecycle[C]//Computer Security Applications Conference,2004:45-48.
[5] Baca Dejan,Petersen Kai,Carlsson Bengt,et al.Static Code Analysis to Detect Software Security Vulnerabilities—Does Experience Matter?[C]//Availability,Reliability and Security,2009:804-810.
[6] Baca D,Carlsson B,Lundberg L.Evaluating the cost reduction of static code analysis for software security[C]//Proceedings of the Third ACM SIGPLAN Workshop on Programming Languages and Analysis For Security (Tucson, AZ, USA, June 07-13, 2008). PLAS ’08. ACM, New York, NY, 2008:79-88.
[7] Attila Szegedi,Tamas Gergely,Arpad Beszedes,et al.Verifying the Concept of Union Slices on Java Programs[C]//Software Maintenance and Reengineering, European Conference on,11th European Conference on Software Maintenance and Reengineering (CSMR’07),2007:233-242.
[8] Cathal Boogerd,Leon Moonen.On the Use of Data Flow Analysis in Static Profiling, Source Code Analysis and Manipulation[C]//IEEE International Workshop on,2008 Eighth IEEE International Working Conference on Source Code Analysis and Manipulation,2008:79-88.
[9] http://www.coverity.com/services/.
[10] http://baike.so.com/doc/2150444.html.
[11] Hallem S,Chelf B,Xie Y,et al.A system and language for building system-specific, static analyses[C]//Proceedings of the ACM SIGPLAN 2002 Conference on Programming Language Design and Implementation,2002:69-82.
[12] Tok T B,Guyer S Z,Lin C.Efficient flow-sensitive interprocedural data-flow analysis in the presence of pointers[C]//15th International Conference on Compiler Construction (CC),2006:17-31.
[13] Gary McGraw.Software Security:Building Security In[J].IEEE Security & Privacy,2006,2(3):6.
IMPROVED SECURITY WARNING ALGORITHM BASED ON CODE POLLUTION IDENTIFICATION
Niu Shuangxia1Lü Zhuo1Zhang Wei1,2Mo Jiansong1,2
1(ElectricPowerResearchInstitute,StateGridHenanElectricPowerCompany,Zhengzhou450000,Henan,China)2(HenanEpriGaokeGroupCo.,Ltd,Zhengzhou450000,Henan,China)
Since static code auditing tools have the features of automation and less error-prone, developers often use them to detect code vulnerabilities. However the results of the vulnerabilities detected will generate a lot of warning messages, and have to be manually examined and corrected by developers. The disadvantage of such tools will waste a lot of time of them. In this paper, we determine whether the defects warned really be used or not by tracking user inputs and sensitive data flow, thereby reduce the number of numerous warnings generated in static detection tools. Meanwhile we provide developers with more real warning messages which actually threaten the software. For the shortcomings of the static code auditing tools, we study three different ways to improve the performance of them. First, for commercial static code analysis tool coverity, we re-analyse the results, and create a set of specific warnings from the security point of view. Secondly, we modify the open source code analysis tool Findbugs, and only analyse those codes to be tainted by user inputs. Thirdly, we develop an auditing tool for grey box, which focuses on XSS (cross-site scripting) vulnerabilities in Java code, and use data flow analysis to determine the entry point of vulnerabilities. Experimental results show that the project B reduces the warning numbers by 20% and the project E produces 2% of warnings only, the number of warnings produced by a tool is lowered, and this provides the developers with more information to discriminate whether the warning is a real security threat.
CoverityFindbugsXSSVulnerability
2015-01-12。江苏省未来网络创新研究院“未来网络前瞻性研究项目”(BY2013095-4-05)。牛霜霞,高工,主研领域:信息安全。吕卓,工程师。张威,工程师。莫坚松,高工。
TP3
A
10.3969/j.issn.1000-386x.2016.08.008
