基于关键词网络的热点关键词及热点项目挖掘
2016-09-08陈泽亚
郭 静 陈泽亚 王 庆
(中国科学技术大学计算机科学与技术学院 安徽 合肥 230027) (中国科学技术大学苏州研究院 江苏 苏州 215123)
基于关键词网络的热点关键词及热点项目挖掘
郭静陈泽亚王庆
(中国科学技术大学计算机科学与技术学院安徽 合肥 230027) (中国科学技术大学苏州研究院江苏 苏州 215123)
针对传统使用频数挖掘热点关键词不能保证有效完整地挖掘出数据库中的热点关键词,提出基于项目、专家对应的关键词数据,分析不同项目关键词之间的相关度,从而建立“项目与专家”网络关系。其创新点在于用双层结构来连接专家、网络、关键词,计算关键词的热度值,挖掘出热点关键词及热点项目。实验结果表明,该方法更能准确地挖掘出项目中的热点关键词,避免了单纯频数计算热点关键词带来的片面化问题。
热点关键词项目—专家网络相关度热点项目权重
0 引 言
在科技成果培育的全过程管理中,重大的科技成果往往呈现一定的规律和特征。这些可以看作是科研活动的发展演化在时空历史信息中表现出来的一致性和连续性,并可随着时间或空间进行发展变化。研究表明大多数网络都是一个具有幂律分布的小世界网络[1],科技论文的关键词网络也具有这样的特性。
国外对科技成果评价方法的研究时间已久,既有定性研究也有定量研究,因而评价结果具有严肃性,可信赖度较高。国内虽然在该领域起步较晚,但也逐渐在政策法规制定、指标体系建立和方法研究上取得了一定的进展。另外,当前国内科技项目评价主要还是以同行专家评议为主,尚未见到涵盖成果培育全过程、成体系的、目标明确的评价方法,也没有一套完整的评价机制实现对科技成果从遴选、诊断到产出阶段的全过程综合评价。
专家项目的匹配一直是科研领域的重要问题。现阶段选择专家一般都是采用计算机简单查询辅助人工选择的方式,计算机辅助程度比较低,只是针对数据库查询,没有提供比较好的智能辅助。目前的匹配方法大多是基于关键字的方法,从数据库中查询相关的关键字进行项目与专家的匹配,但这种方法匹配的准确程度不高。文献[14]提出将项目信息文档和专家信息文档转换为两棵本体概念树,通过计算两棵树之间的相似度来判断项目和专家是否匹配。文献[15]在文献[14]的基础上,计算树型概念结构中两个概念节点以及两个树型概念结构之间的语义相似度,进行项目和专家的匹配。文献[16]利用分词工具ICTCLAS[17]和TF-IDF算法[18]对项目申请书和表示专家的文本信息进行文本挖掘和分析,从而选出与项目研究内容最相符的评审专家,解决项目与评审专家的匹配。项目专家的匹配关键在于其关系网络的建立。
项目特征是用关键词来表示的,那么项目中关键词的挖掘就成为重中之重。最早期IBM用词频来提取关键词[2],该方法存在很多弊端,后来又相继出现各种改进的方法。文献[3]用n-grams、NP-chunks、关键词模式三种方法和文档内频率等特征来进行关键词的提取;文献[4]则是基于k-means聚类算法挖掘热点关键词;文献[5]增加了信息的实效性,采用实时跟踪系统,挖掘项目或信息中的热点关键词。这些方法大多数是考虑了词频、词性、词长度等属性。科研项目中的关键词也是采用这些方式,挖掘出关键词后就可以依据其在项目中的共现关系建立关键词网络。同样专家负责的项目的关键词也可作为专家的标签,这样就可以建立项目、关键词、专家的网络关系。
项目—关键词—专家网络建立之后,利用该网络就可挖掘出热点的关键词或者热点项目,从而预测未来的科研趋势或走向。热点关键词挖掘问题在社交网络中用到很多,也有较为成熟的理论和方法。文献[10,11]根据朋友关系建立社交网络,分析评论转发关系挖掘热点关键词;文献[12]引入权重网络的聚类系数从而计算关键词权重挖掘热点关键词;文献[13]提出一种自动话题监测方法,该方法结合了聚类算法迭代特征向量,以跟踪监测挖掘热点关键词;文献[19]通过文本聚类归纳话题,对话题影响力进行计算和分析,从而挖掘出热点话题。文献[20]利用single-pass动态聚类算法对文本进行处理,然后对大的类别做挖掘,因为只有大类别才能反映一些热点事件。微博的跟帖转发蕴含着话题的关联性假设,文献[21]分别采用single-pass、K-means以及K-medoids聚类算法进行话题识别,在话题识别的基础上,综合话题的线索数、精华线索数、回复数、单位时间浏览数等信息来识别热点话题。然而在科研项目中,热点关键词及热点项目挖掘的研究少之又少。
目前电力领域网络建立以及热点关键词挖掘大多只考虑关键词词频,没有形成一个成熟完整的体系。本文针对这种现状,对电网领域科研项目数据库研究,提出一种双层结构的专家—项目网络。利用该结构挖掘出热点关键词及热点项目的方法,并将该方法部署到实际的电力数据中,验证了该方法对于挖掘热点关键词及热点项目的正确性。对比与社交网络中建立关联网络,并采用分类聚类等方法来挖掘热点关键词,本文综合考虑关键词出现的频数、负责项目的专家的专业影响力来计算关键词的热点程度,从而挖掘热点关键词。最大的不同在于文中提出的双层网络结构模型是从上下两层网络关系来计算热点关键词。
本文的主要贡献如下:
1) 改进了原有的只考虑词频的方法,综合词频及专家专业影响力计算关键词的热度值。
2) 建立专家—项目—关键词双层结构网络,挖掘热点关键词。
3) 根据与热点关键词存在共现关系,建立关键词拓扑图,查找拓扑图中的强连通分量,从而挖掘热点项目。
1 相关工作
1.1TF-IDF函数
TF-IDF算法[6]是由McGill和Gerald Saltom针对向量空间信息检索样例提出的一种用来表示文本特征的方法。在该算法中出现在文档中的词语被称为术语,每个术语有自己相应的特征权重,这个权重代表了在文档识别时该术语所具有的重要程度。术语的权重与其在文档中出现的频率成正比,而与其在所有文档中出现的频率成反比。其中TF(Term Frequency)被称为词频,代表术语在文本中出现的次数,IDF (Inverse Document Frequency)被称为逆向文件频率,反映某个术语在一个文档集中按文本统计出现的频繁程度指标。传统TF-IDF函数可以用如下公式描述:
(1)
式中,wj代表某篇文本中第j个术语的特征权重,TFj代表术语词j在本篇文本中出现的次数,TFmax代表在一批文档集合中某个术语j在单篇文本中出现的最大次数,IDF代表倒文档频率,用式(2)表示:
(2)
其中N代表某批集合中包含的文本总数,DFj则代表了在这批文本集合中出现过术语j的文本总数。
传统的TF-IDF函数所要传达的思想是:如果某个特征词出现在测试文档集合的某篇文档中的频率TF越高,而该特征词在背景语料文档集合中出现的次数越少,则越认为这个特征词能够代表此类文本的特征。
1.2关键词网络
关键词的提取[6]是根据关键词在项目中的共现次数以及相关度来提取的。首先确定基类关键词。基类关键词包括领域的专业术语、常用词语或者是文章、项目中的关键词。然后对项目中的摘要、主要内容做分词划分,对于划分好的关键词跟基类关键词计算其相关度。如果相关度在一定阈值内,那么将其加入关键词库中;如果超出阈值范围内,就丢弃它。这样迭代的提取就可以不断完善关键词库。本文假定关键词库已有。
2 关键词—项目—专家双层结构网络
2.1关键词向量
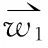
(3)
(4)
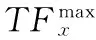
2.2关键词—项目网络
根据关键词的共现关系(两个关键词在同一个项目中出现)就可以将关键词关联起来,形成一个关键词共现关系网络。由于关键词有多重属性,一个关键词可能属于不同的项目,一个项目包含多个关键词,每个项目都有相应的领域。为分析关键词和其他属性关系,可以将该属性与共现关系结合形成一个多维异质网络。该网络不仅保留了关键词的共现关系,而且加入了新的节点属性,即关键词所属的项目领域。图1是一个部分项目—关键词网络。矩形圈住的节点表示项目领域,其他节点表示关键词。关键词之间的连线表示其出现在同一个项目中,关键词与领域之间的连线表示关键词所在项目属于该领域,领域节点之间没有边相连。对于每一个关键词,用式(3)计算权重。图1是一个权重网络图,关键词的权重大小表示其在网络中的重要程度。
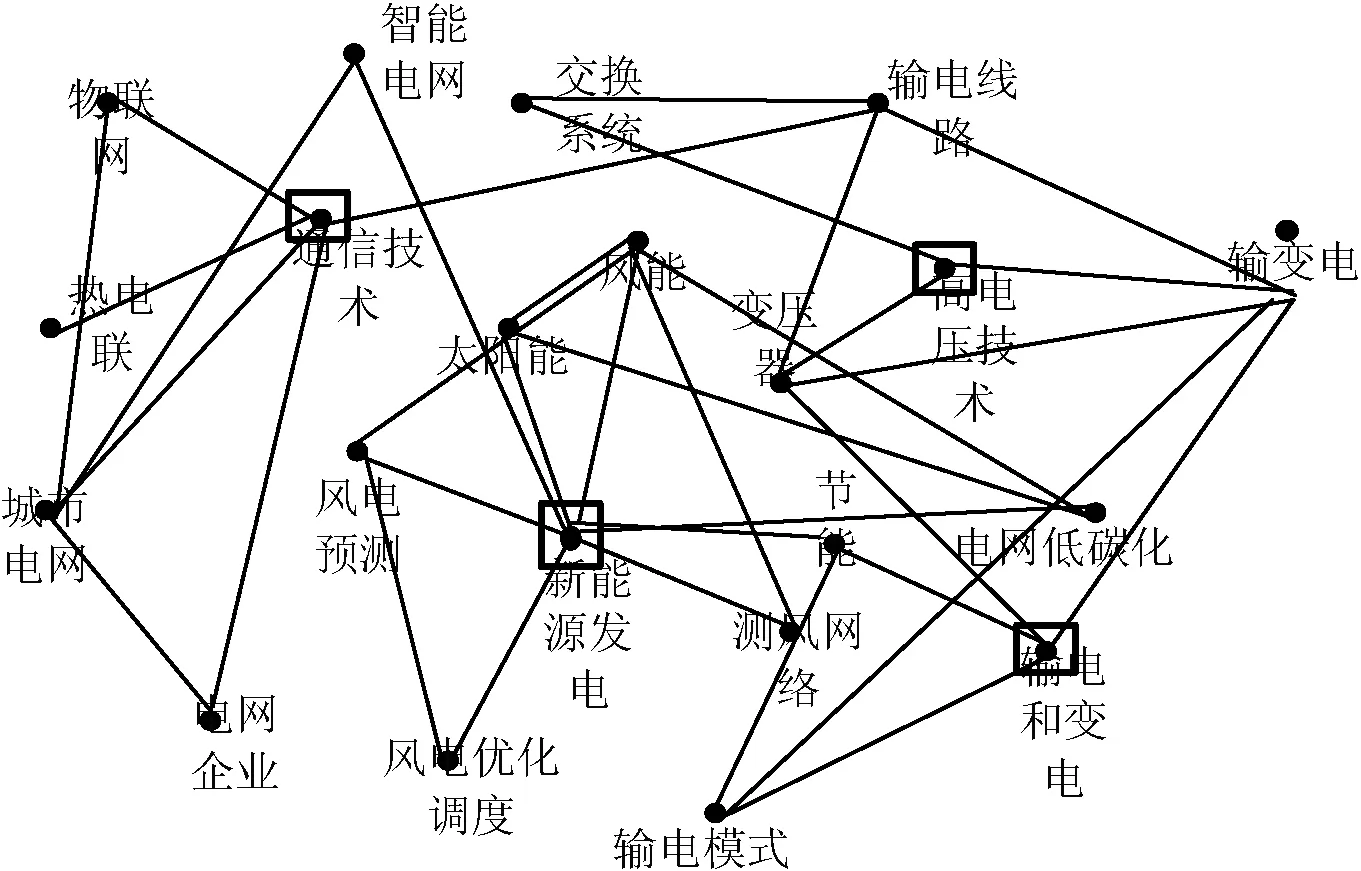
图1 关键词—项目网络结构图
2.3专家社交网络
专家往往通过论文参考、科研合作、项目评审等多种方式建立合作网络。分析这种社交网络,发现紧密合作的专家圈子,进行项目和专家匹配分析(例如专家回避)的基础。
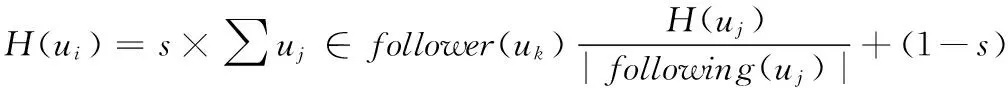
(5)
其中s∈(0,1),s是一个倾销因素,s值在这里代表图G中一个点到另一个点的随机游走概率。函数following(uj)返回的是专家uj引用的文章或者项目的作者集合,follower(uk)函数是指专家ui的引用者集合。H-Factor值的计算可以通过迭代算法来完成,初始化设置为:
(6)其中,|U|是所有专家集合。接下来的每一步中,按照式(5)重复计算H-Factor值,当满足收敛条件时,该过程停止。专家社交网络的建立是为关键词最终的热度值做准备,因为影响力大的专家负责的项目成为热点项目的可能性就大,因而热点项目中包含的关键词成为热点关键词的可能性就大。图2为部分专家网络图。
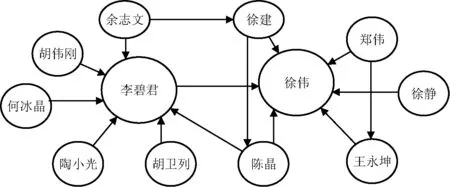
图2 专家社交网络结构图
专家社交图如图2所示,图中圈的大小表示用户H-Factor值的大小。从图中可以看出,文章或项目被引用次数多的专家的H-Factor值相对比较大;同样,他的引用者H-Factor值大的专家的H-Factor值也相应的会比较大。因为一个专家的H-Factor值受两个因素的影响,即引用者个数和引用者的H-Factor值的大小。
2.4关键词—项目—专家双层网络
项目和关键词、专家和专家之间的关系网络已经建好,那么关键词—项目—专家之间的关系可以用一个双层立体结构图表示。该结构图分两个平面,上层平面表示关键词—项目领域关系图,下层平面表示专家社交关系图。上层领域节点与下层专家节点之间的连线表示专家负责的项目属于该领域,上层关键词节点与专家的连线表示专家负责的项目包含该关键词。所以专家跟领域、关键词之间都存在关系。
图3是部分关键词—专家网络双层结构图。由于关系网络比较复杂,因而图3中上层结构和下层结构之间的线条没有完全画出。上层结构是2.2节中描述的项目—专家网络,下层结构是2.3节中的专家社交网络,两层结构通过项目、关键词、领域之间的关系连接。因而关键词的权重不仅表现在它出现的次数,同样表现在项目是由哪个专家负责,这个专家的专业影响力有多大,即H-Factor值的大小。
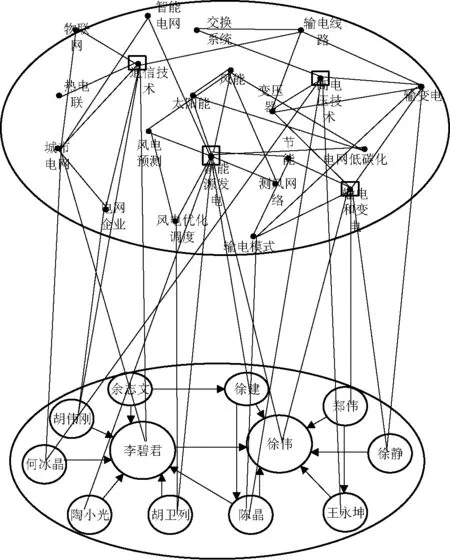
图3 关键词—专家网络图结构图
3 热点关键词挖掘
3.1热点关键词挖掘
上面提到关键词的热点程度不仅跟它在项目集中出现的次数相关,还跟其所在项目的负责人相关,换言之关键词根据其权重和项目负责人的H-Factor值来决定其是否是热点。这里引入一个热度值的概念。定义关键词的热度为:
nutrk=∑twj∈TWkwj,k×H(user(twj))
(7)
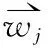
选择热点关键词的方法依赖于用户自定义的一个参数,用该参数计算一个临界阈值:
(8)
其中,δ≥1,这里考虑了平均nutr值来设置临界阈值,因此定义热点关键词集合为:
∀k∈Kk∈HK⟺nutrk>ε
(9)
由此可以选择出热点关键词集合HK,关键词集合个数大小跟δ的值成反比关系。
3.2关键词拓扑网络
项目是由若干关键词表示的,热点关键词可能只是一个独立的个体。那么从热点关键词延伸到热点项目,我们需要分析那些和热点关键词共同出现的语义相关的关键词对,从而挖掘出热点项目或者在未来一段时间会成为热点的项目。

(10)
(11)其中,rk,z是项目领域同时包含关键词k和z的个数,nz是包含关键词z的个数,nk包含关键词k的项目个数,N是整个项目集总个数。
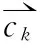
(12)
有向图TG(K,E,ρ)通过一个局部自适应边集细化算法来处理。采用自适应折中法这个过程确保了只有强连通的边集才会被保留,也就是只有高度相关的关键词才会出现在同一个项目领域的可能性会大。图4为部分关键词拓扑图,圈代表关键词,各个圈之间的箭头表示关键词之间的关系。

图4 关键词拓扑图
3.3热点项目挖掘
所谓的热点项目是指包含热点关键词的项目。本文中的项目热度值是根据其包含的关键词的热点值来计算的。3.1节中挖掘出的热点关键词集合EK,要找与热点关键词相关的项目,就要寻找根在3.2节中TG中的强连通分量。因此给定一个关键词代表图中一个节点,找到节点集合S(从k通过一条路径到达的),找这些节点可以用深度优先遍历算法(DFS)。然后在相同的拓扑图中用反向边重复该过程找节点集合T(从这些节点出发,通过一条路径可以到达k)。强连通分量就是EK_k,它由T和S之间的点集构成。该过程是线性的。 热点关键词z属于Ek,定义热点项目为子图ET(Kz,Ez,ρz),代表与关键词z语义相关的关键词集合。考虑整个热点关键词集合EK,我们计算相应的强连通分量,热点项目ET={ET1,ET2,…,Etn,}(n≤|EK|),热点项目个数少于关键词个数,因为可能两个关键词同属于一个项目。最后关键词集合K-z是否属于项目集合ET-z通过计算关键词z为TG起点,并且包含与z语义相关的。用该方法不仅能检测直接出现的热点关键词,而且能检测与热点关键词间接相关的关键词。建立一个序列告诉用户哪个话题更有热点。例如从图4中可看出{智能变电站、智能电网、电动汽车}构成了一个强连通分量,因而他们可以表示一个热点项目集。用以上方法可以挖掘出热点项目,我们需要给挖掘出的热点项目建立一个热点值顺序,以供用户来判断哪个项目更具热度,因而引入一个顺序值的概念,如式(13)所示:
(13)
其中nutrk是式(7)中计算的关键词k的热度值,|ET|表示热点项目中关键词个数。
4 实验仿真分析
本文对热点关键词的挖掘考虑到项目中关键词出现的次数以及关键词对应的项目负责人的专业影响力,从不同的方面考虑关键词的重要程度。为了进一步说明该方法的有效性,我们用C++语言实现了该过程。我们选取的数据集是电力行业的项目数据库来做实验验证。在基于该数据源的基础上,建立关键词—项目—专家的双层网络,从而进行热点关键词挖掘以及热点项目挖掘。对于热点关键词的挖掘,用3.1节中提到方法在原有关键词频数的基础上,考虑专家的影响力,从而挖掘出热点关键词。根据式(7)计算关键词的值,当其值大于某个临界阈值(阈值计算用式(8))时,认为它是热点关键词。由于该临界阈值是用户自己设定的,那么不同的临界阈值,挖掘出的热点关键词也会相应的不同。由式(7)-式(9)可知,阈值设置的不同会影响挖掘出的热点关键词的个数.图5是针对不同δ值挖掘出的热点关键词的个数,由图中曲线可知,δ值越大,热点关键词的个数相应越小,他们二者之间成反向变化趋势。

图5 不同δ值对应的不同热点关键词个数
然而要想找到一个确切的δ值来更正确地挖掘出热点关键词需要不同的实验来实现。衡量不同阈值的准确性,我们先采用人工标注方法识别出热点关键词,然后用本文提到的方法挖掘出热点关键词,计算该方法挖掘热点关键词的正确率,从而确定一个合适的δ阈值。图6是按照3.1节中提到的方法挖掘出的正确热点关键词的正确率,这里正确率的计算按照式(12)。从图中可以看出,当δ值为3时,得到热点关键词的正确率是最高的,因此确定该δ为3。
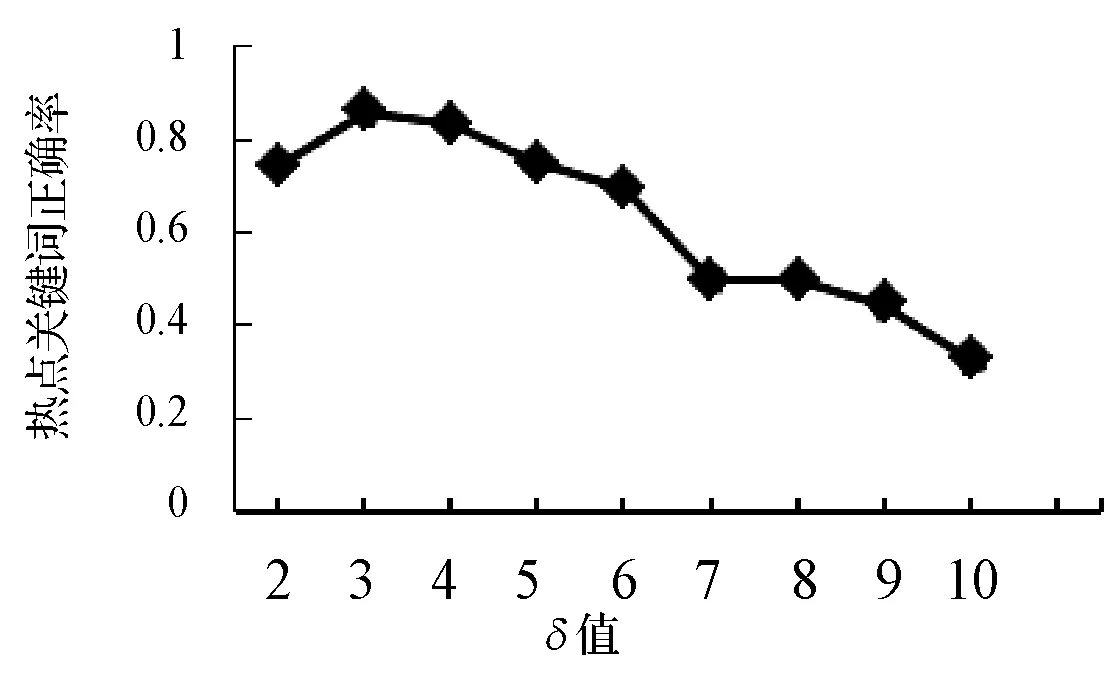
图6 热点关键词正确率
式(14)中N是人工标记的热点关键词的个数,n1是挖掘出的正确热点关键词个数,n2是挖掘出的错误热点关键词。之所以给一个系数0.2,是因为错误热点关键词比正确热点关键词的重要程度低。
(14)
词频方法挖掘热点关键词通常是通过关键词在整个数据库中出现的次数来衡量。网络方法挖掘热点关键词是根据关键词之间的关联共现关系,采用聚类方法,找出网络中的中心关键词,将其作为热点关键词;而本文中提出的方法改进了传统词频的方法,充分考虑了关键词出现的次数以及该关键词所属项目领域专家的影响力各方面的因素,建立双层网络模型从而挖掘热点关键词。表1中所列的是部分领域(由于数据量比较大,就挑选了几个代表性的领域数据来分析)的项目个数、人工标注的热点词个数,并按照3.2节中提到的方法挖掘出的热点关键词个数的正确率和词频方法以及网络方法挖掘出的热点关键词的正确率数据比对。从表中数据可以看出,本文方法挖掘出热点关键词的正确率明显高于词频方法和网络方法,因此热点关键词由词频和关键词所在项目的负责人的影响因子来共同决定更有说服力。
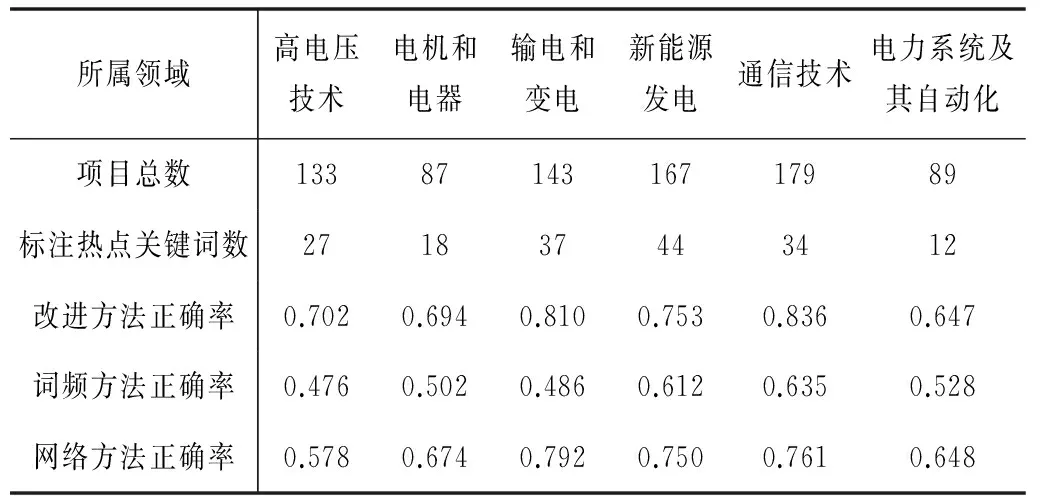
表1 各领域热点关键词个数及各个方法挖掘热点关键词的正确率
挖掘出热点关键词后,根据3.2节方法建立关键词拓扑网络,用DFS找出拓扑图的强连通分量,那么强连通分量组合就代表热点项目,或者在未来一段时间内可能会多次出现在项目中的。这里用rank值表示强连通分量的相对顺序值。根据该值的计算方式,我们知道rank值越大表示该组合热点程度越高,因而越能代表科研的热点趋势。表2为rank值排序靠前的热点关键词拓扑中的强连通分量集合。这些关键词的组合可能成为热点项目或潜在热点项目用到的关键词组合。

表2 热点关键词拓扑图强连通分量
5 结 语
项目—专家网络的建立需要考虑很多因素,本文从最基本的关键词的词频和其所在项目的负责人的影响因子出发来衡量关键词的权重,比单一词频算法更有说服力。同属于一个领域且在项目中共现的频数大的关键词,可能在未来一段时间成为热点项目的关键词,从而这些热点关键词的组合有可能成为潜在热点项目。
[1] Fan Y, Li M, Chen J, et al. Network of econophysicists: a weighted network to investigate the development of econophysics[J]. International Journal of Modern Physics B, 2004, 18(17n19):2505-2511.
[2] Luhn H P. The automatic creation of literature abstracts[J].IBM Journal of research and development, 1958, 2(2):159-165.
[3] Hulth A. Improved automatic keyword extraction given more linguistic knowledge[C]//Proceedings of the 2003 conference on Empirical methods in natural language processing. Association for Computational Linguistics, 2003:216-223.
[4] Liu H, Li X. Internet public opinion hotspot detection research based on k-means algorithm[M]//Advances in Swarm Intelligence. Springer Berlin Heidelberg, 2010:594-602.
[5] Zheng K, Shu X M, Yuan H Y. Hot Spot Information Auto-detection Method of Network Public Opinion[J]. Computer Engineering, 2010, 36(3):4-6.
[6] Bun K K, Ishizuka M. Topic extraction from news archive using TF* PDF algorithm[C]//Web Information Systems Engineering, International Conference on. IEEE Computer Society,2002:73-73.
[7] Chen J, Geyer W, Dugan C, et al. Make new friends, but keep the old: recommending people on social networking sites[C]//Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. ACM, 2009:201-210.
[8] Griffiths T L, Steyvers M. Finding scientific topics[J].Proceedings of the National academy of Sciences of the United States of America, 2004, 101(S1):5228-5235.
[9] Li M, Fan Y, Chen J, et al. Weighted networks of scientific communication: the measurement and topological role of weight[J]. Physica A: Statistical Mechanics and its Applications, 2005, 350(2):643-656.
[10] Wu K J, Chen M C, Sun Y. Automatic topics discovery from hyperlinked documents[J]. Information processing & management, 2004, 40(2): 239-255.
[11] 吴江宁, 杨光飞. 基于本体的项目和领域专家匹配原型系统[J]. 计算机应用研究, 2009, 26(10):3787-3790.
[12] 陈庄, 荆于勤. 基于相似度计算的信息化项目与专家匹配方法[J]. 重庆理工大学学报: 自然科学版, 2013,27(4):81-84.
[13] 杨生举, 蒙杰, 赵昕辉,等.基于文本挖掘的科研项目网上评审系统研究与实现[J].甘肃科技,2012,24(15):12-14.
[14] 刘克强. 2009 共享版 ICTCLAS 的分析与使用[J]. 科教文汇, 2009(22):271-271.
[15] 施聪莺, 徐朝军, 杨晓江. TFIDF 算法研究综述[J]. 计算机应用, 2009,29(B06):167-170.
[16] 何跃, 帅马恋, 冯韵. 中文微博热点话题挖掘研究[J]. 统计与信息论坛, 2014,29(6):86-90.
[17] 刘金岭, 王新功, 周泓. 基于短信文本信息流的多热点事件挖掘[J]. 山东大学学报:工学版,2013,43(3):7-12.
[18] 姚晓娜. BBS 热点话题挖掘与观点分析[D].大连:大连海事大学, 2008.
MINING HOT KEYWORDS AND HOT PROJECTS BASED ON KEYWORD NETWORK
Guo JingChen ZeyaWang Qing
(SchoolofComputerScienceandTechnology,UniversityofScienceandTechnologyofChina,Hefei230027,Anhui,China) (SuzhouInstituteforAdvancedStudy,UniversityofScienceandTechnologyofChina,Suzhou215123,Jiangsu,China)
Traditional method using frequency to mine hot keywords cannot guarantee the effectiveness and integrity of hot keywords mining from database, for this issue, we propose a method which is based on the keywords data corresponding to projects and experts and analyses the correlation between different project keywords so as to establish project-expert network relationship. Its innovation lies in using double-layer structure to connect the experts, the network and the keywords, calculating the hot degree of keywords, so that mines out the hot keywords and hot projects. Experimental results show that the method can more accurately mine the hot keywords in projects, and avoids the one-sided problem brought forth by only using frequency to calculate hot keywords.
Hot keywordProject-expert networkRelevanceHot projectWeight
2015-03-04。郭静,硕士生,主研领域:无线传感器网络,软件工程与理论。陈泽亚,硕士生。王庆,硕士生。
TP311
A
10.3969/j.issn.1000-386x.2016.08.016
