强噪声环境下基于改进粒子滤波的麦克风阵列定位
2016-09-07唐勇奇
吴 迪,唐勇奇
(湖南工程学院 电气信息学院,湘潭 411101)
强噪声环境下基于改进粒子滤波的麦克风阵列定位
吴迪,唐勇奇
(湖南工程学院 电气信息学院,湘潭 411101)
针对噪声和混响环境下说话人定位不准确的问题,提出了一种基于迭代无味粒子滤波的麦克风阵列声源定位方法.利用迭代无味卡尔曼滤波产生的建议分布函数对粒子滤波算法进行改进形成迭代无味粒子滤波,在该算法的框架下通过计算麦克风阵列波束形成器的输出能量构造似然函数.实验结果表明,该方法提高了说话人的定位精度,增强了说话人跟踪系统的抗噪声和抗混响能力.
说话人定位;迭代无味粒子滤波;麦克风阵列;建议分布函数;似然函数
基于麦克风阵列的说话人定位与跟踪是人机交互研究中的一个重要课题,它在多媒体系统、视频会议系统、移动机器人等领域有着广泛的应用[1].传统的麦克风阵列声源定位方法主要是通过计算麦克风阵列接收语音信号当前时刻的时间延迟估计说话人的位置,在自由声场情况下,该方法取得了很好的定位跟踪效果,但是当房间背景噪声强度较大或混响时间较长的情况下,会导致大量虚假声源的产生,从而影响了定位的精确性.
近年来,随着非线性滤波技术的发展,研究人员采用状态空间方法对说话人运动轨迹进行建模处理,通过适当的动态方程模拟说话人的运动状态,将当前时刻的信息和过去的历史信息综合处理,有效克服了复杂噪声环境下虚拟声源的影响,较好地提高了说话人跟踪系统的精确性和鲁棒性.Vermaak 等人[2]通过建立合理的说话人运动模型来抑制虚假声源的影响,根据时延估计构造似然函数,通过粒子滤波实现声源的有效定位.Ward等人[3]在此基础上做了改进,对声源跟踪方法进行总结,并利用波束形成的输出能量构造似然函数,通过粒子滤波实现说话人声源的准确跟踪.殷福亮等人[4,5]在对粒子滤波算法改进的基础上分别根据时延估计和SRP-PHAT波束形成器的输出能量构造似然函数,对说话人进行跟踪定位.金乃高等人[6]采用量子进化方法对粒子滤波进行改进,并将改进的粒子滤波算法应用到说话人跟踪中,取得了较好的效果.以上方法在混响时间短、信噪比大的环境中可对说话人进行准确定位,但在强噪声环境中依然不能有效跟踪说话人.
本文针对混响时间长,信噪比小时说话人定位不准确的问题,综合考察量测信息和说话人运动模型在抑制房间混响时的作用,提出一种基于迭代无味粒子滤波的声源定位方法.该方法采用麦克风阵列采集的语音信号作为观测信息,通过计算麦克风阵列可控波束形成的输出能量构造似然函数.其次,将迭代无味粒子滤波引入到音频定位中,通过与其它滤波算法进行对比分析验证了该滤波算法在音频定位中的有效性.
1 算法原理
1.1无味粒子滤波
在说话人跟踪系统中,运动模型的变化信息是很难完全掌握的,而标准粒子滤波算法为了求解方便,一般选取先验概率密度作为建议分布函数,但是,这种方法丢失了当前时刻的量测值,使得当前时刻的状态严重依赖于模型,当模型不准确,或者量测噪声突然增大时,这种选取方法将不能有效的表示真实的建议分布函数.而利用无味卡尔曼滤波(Unscented Kalman Filter,UKF)来产生建议分布函数,可以很好的融入最新的量测信息,从而提高粒子滤波的跟踪性能.无味粒子滤波(Unscented Particle Filter,UPF)算法的具体过程如下:
(1)
(2)
(2)重要性采样.
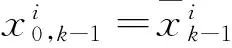
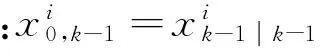
(3)

j=1,2,…,nx
(4)
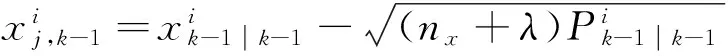
j=nx+1,nx+2,…,2nx
(5)
(6)
(7)
(8)
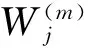
时间更新:
(9)
(10)
(11)
(12)
(13)

量测更新:
(14)
(15)
(16)
(17)
(18)
采样粒子
(19)
其中,N(·)表示高斯函数.
计算权值
(20)
其中,i=1,2,…,Ns,归一化权值
(21)
(22)
1.2迭代卡尔曼滤波算法
迭代卡尔曼滤波(Iterated Kalman Filter, IKF)算法思想是在上次滤波得到状态估计值的基础上进行线性化,得到的一种迭代卡尔曼滤波结构,是一种最大后验逼近,迭代卡尔曼算法的修正步骤如下:
序列{xi}和{Pi}定义为:
Pi+1=(I-KiHi)P
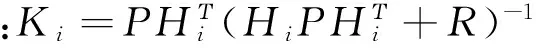
Hi=h′(xi),R为量测噪声的协方差矩阵,I为单位矩阵.
2 改进的粒子滤波算法
本文通过对UPF算法进行改进,加入IKF算法来修正UKF算法更新的状态均值和方差,优化建议分布函数,改进后的算法称为IUPF算法.IUPF算法实现步骤如下:
(1)利用(1)-(22)产生量测更新的状态均值和方差.
(2)迭代更新
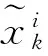
采样粒子
(23)
其中,N(·)表示高斯函数.
计算权值
(24)
其中,i=1,2,…,Ns,归一化权值
(25)
(3)重采样过程.
(4)状态估计.
(26)
3 基于IUPF的说话人定位
3.1说话人的运动模型
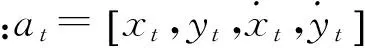
(27)
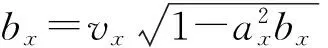
3.2说话人的定位函数
SRP-PHAT声源定位算法[11]将波束形成方法的鲁棒性、短时分析特性与相位变换方法对环境的不敏感性相结合,使声源定位系统对噪声和混响的灵敏度降低,提高了系统的鲁棒性和定位的精确性.
设声源信号s(t)经多径传播后到达麦克风阵列,第i个麦克风接收到的信号mi(t)可以表示为:
mi(t)=s(t)*hi(t)+vi(t)
(28)
其中vi(t)为噪声,hi(t)是声源与第i个麦克风之间的冲激响应,它是麦克风位置和声源位置的函数,“*”为卷积运算符.SRP-PHAT声源定位算法是通过计算麦克风阵列的波束输出能量来定位,定位函数如下:
(29)
3.3似然函数构建
似然函数的作用是评价粒子权值,定位函数是空间位置的连续函数,因而可用作似然函数,称之为伪似然函数(PseudoLikelihood).构建的伪似然函数为:
(30)
其中,ξ=0,其作用是确保似然函数的非负性.γ为正实数,用来使似然函数更尖锐,使得似然函数更适合于说话人定位,一般取值为γ=3.
3.4基于IUPF的说话人定位算法实现
基于迭代无味粒子滤波算法的说话人定位具体实现步骤如下:
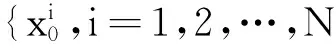
(2)采样粒子.k=1,2,…,利用IUPF算法和说话人运动模型以及定位函数,得出k时刻的采样粒子
(31)
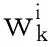
(4)重采样过程.
(32)
(6)判断语音信号是否结束.如果结束则停止运行,否则转到步骤2.
4 实验结果与分析
4.1实验参数设置
仿真实验模拟普通会议室的声学环境,其中房间设置为5m×7m×3m,在X,Y两个方向上,分别放置两组包含两个麦克风的线性阵列,麦克风之间的距离为1m,说话人在房间内沿X轴斜45°方向匀速运动,说话人运动的起点为(1,1),如图1所示,并保持持续发声状态.房间混响的冲激响应函数由IMAGE模型产生,采用的噪声类型为高斯白噪声,麦克风阵列获取的语音信号以fs=16kHz的采样率进行16比特采样,说话人的高度为固定值.
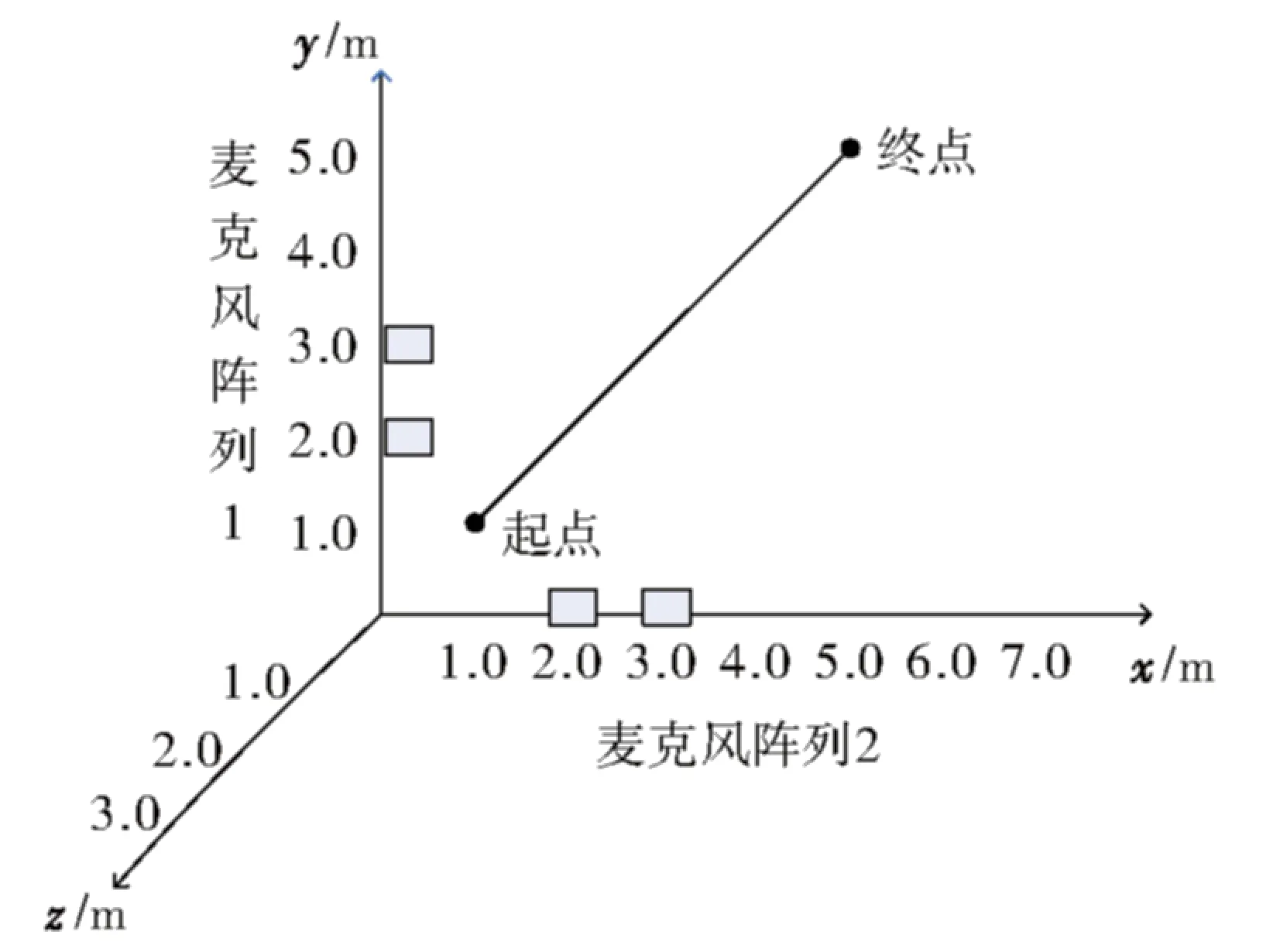
图1 麦克风阵列的摆放位置
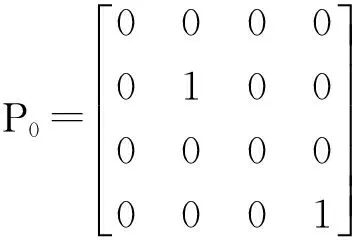
为了验证IUPF算法在说话人定位中的性能,本文将其与PF、UPF两种算法进行了比较,文中引入了均方误差(RMSE)作为衡量精度的标准.
4.2实验结果与分析
在不同信噪比和混响时间(T60)的情况下,比较了PF、UPF和本文所用的方法对说话人的定位效果.图2是SNR=15dB,T60=100ms时,X方向三种算法的定位效果.图3是SNR=15dB,T60=100ms时,Y方向三种算法的定位效果.图4是SNR=5dB,T60=200ms时,X方向三种算法的定位效果.图5是SNR=5dB,T60=200ms时,Y方向三种算法的定位效果.其中横轴表示时间,竖轴表示各方向的位置.实验中分别在两种不同信噪比和混响时间(T60)情况下,各做了50次仿真,得出来RMSE的平均值如表1和表2所示.
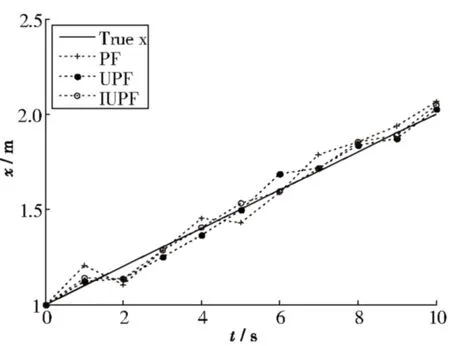
图2 SNR=15 dB,T60=100 ms X方向三种算法的跟踪结果比较
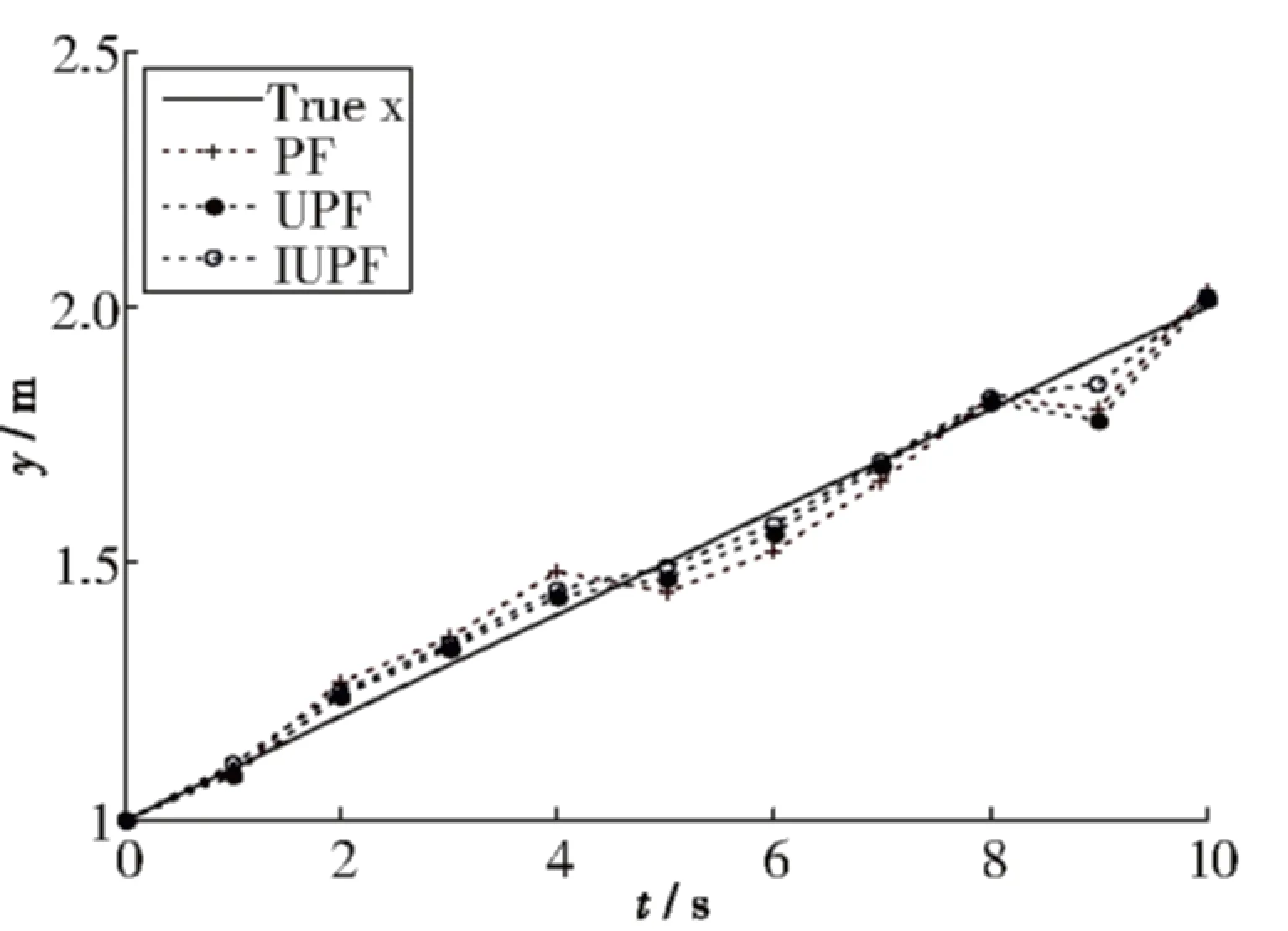
图3 SNR=15 dB,T60=100 ms Y方向三种算法的跟踪结果比较
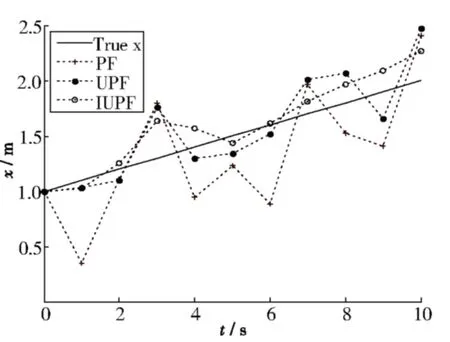
图4 SNR=5 dB,T60=200 ms X方向三种算法的跟踪结果比较

滤波算法RMSEXYPF0.06270.0578UPF0.04150.0451IUPF0.03330.0318
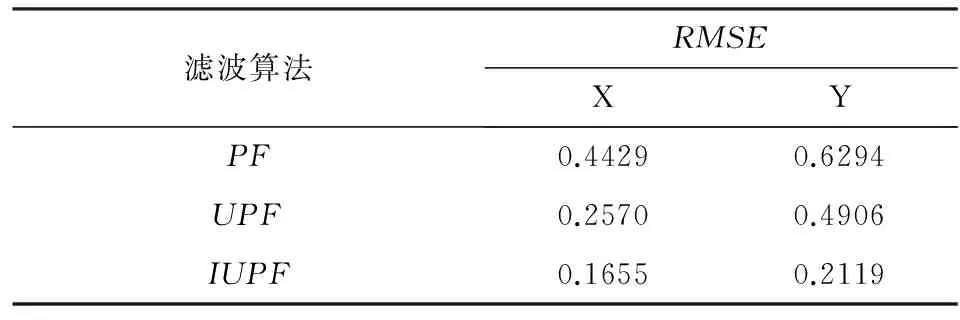
表2 SNR=5 dB,T60=200 msRMSE值对比
由图2和图3可以看出,在信噪比较大、混响时间较短的情况下,PF和UPF定位结果粗糙,定位不精确.相比PF和UPF算法的定位效果,本文算法可以实现说话人的精确定位.该实验说明本文所提方法在定位的准确性方面优于PF和UPF算法.
由图4和图5可以看出,随着信噪比减小,混响时间增加.三种算法的定位精度都出现不同程度的降低,其中,PF和UPF算法出现很明显的估计误差,而本文算法仍然能够保持较好的定位精度.该实验说明在定位的稳定性方面本文算法优于PF和UPF算法.通过对比表1和表2的均方误差可以明显看出,IUPF算法的均方误差最小,其定位精度相比标准粒子滤波提高了50%~60%,相比无味粒子滤波提高了10%~30%.说明本文的算法具有更好的定位精度.综上,在房间混响较强、信噪比较低的情况下,PF和UPF算法会出现较大的定位误差,IUPF利用UKF和IKF相结合产生建议分布函数,通过融入最新量测信息提高了抽样粒子对真实状态后验分布的逼近程度,很好的提高了说话人定位的精度.
5 结 论
为了提高跟踪精度,本文对粒子滤波进行了改进,并提出了一种基于迭代无味粒子滤波算法(IUPF)的说话人定位方法,该算法通过UKF和IKF算法相结合产生建议分布函数对粒子滤波进行改进,并在改进的算法框架下,采用SRP-PHAT构建似然函数实现对说话人的跟踪定位.仿真实验表明,本文算法的定位精度相比PF算法和UPF有明显的提高.
[1]金乃高,殷福亮,陈喆.基于加权子空间拟合的声源定位于跟踪方法[J].电子与信息学报,2008,30(9):2134-2137.
[2]JVermaak,ABlake.NonlinearFilteringforSpeakerTrackinginNoisyandReverbe-rantEnvironments[C].inProc.IEEEInt.Conf.Acoust.Speech,SignalProcessing(ICASSP-01),SaltLakeCity,UT,2001.
[3]DBWard,RCWilliamson.ParticleF-ilterBeamformingforAcousticSourceLo-calizationinaReverberantEnvironment[C].inProc.IEEEInt.Conf.Acoust,Spe-ach,SignalProcessing(ICASSP-02),Or-lando,FL,2003.
[4]侯代文,殷福亮. 基于粒子滤波的交互式多模型说话人跟踪方法[J].电子学报. 2010,38(4):835-841.
[5]金乃高,殷福亮,陈喆.基于分层采样粒子滤波的麦克风阵列说话人跟踪方法[J].电子学报,2008,36(1):194-198.
[6]金乃高,殷福亮.量子进化粒子滤波算法及其在说话人跟踪中的应用[J].信号处理,2008,24(6):982-987.
[7]GordonN,SalmondD,SmithA.NovelApproachtoNonlinear/non-GaussianBay-esianStateEstimation[C].ProceedingofInstituteElectricEngineering, 1993, 140(2):107-113.
[8]潘泉,杨峰,叶亮,梁彦,程咏梅. 一类非线性滤波器-综述[J]. 控制与决策,2005,20(5):481-489.
[9]ShmaliyYS.AnIterativeKalman-LikeAlgorithmIgnoringNoiseandInitialConditions[J].IEEETransactionsonSignalProcessing,2011,59(6):2465-2473.
[10]侯代文,殷福亮,陈喆.基于拟蒙特卡洛滤波的说话人跟踪方法研究[J].自动化学报,2009,35(7):1016-1021.
[11]DanteA.Blauth,VicenteP.Minotto,ClaudioR.Jung,BowonLee,TonKalker.VoiceActivityDetectionandSpeakerLocalizationUsingAudiovisualCues[J].PatternRecognitionLetters,2012,33(4):373-380.
AcousticSourceLocalizationBasedonIterativeUnscentedParticleFilter
WUDi,TANGYong-qi
(CollegeofElect.andInformationEngineering,HunanInstituteofEngineering,Xiangtan411101,China)
Inordertosolvetheproblemofinaccuratelocalizationinnoiseandreverberationenvironment,anewmicrophonearraysoundsourcelocalizationmethodbasedonIterativeUnscentedParticleFilterisproposedinthispaper.First,theIterativeUnscentedParticleFilterisintroducedtotheacousticsourcelocalization.Then,thelikelihoodfunctionisconstructedbycalculatingthemicrophonearray’soutputenergyintheframeworkoftheimprovedparticlefilteringalgorithm.Finally,theexperimentresultsshowthattheproposedlocationmethodcannotonlyimprovethepositioningaccuracy,butalsoenhancetheabilityofacousticsourcetracingsystemtoresistnoiseandreverberation.
speakerlocalization;IterativeUnscentedParticleFilter(IUPF);microphonearray;proposaldistribution;likelihoodfunction
2015-09-10
国家科技支撑计划资助项目(1214ZGA008),国家自科基金资助项目(61263031),湖南省重点学科建设资助项目(081101),重庆市教委自然科学基金资助项目(KJ1400628),湖南工程学院博士科研启动基金(15045).
吴迪(1985-),男,博士,研究方向:多源信息融合及智能信息处理.
TP391.41
A
1671-119X(2016)01-0001-05
