数据挖掘在轮胎均匀性试验数据上的应用
2016-09-06张健斌朱兰娟上海交通大学自动化系上海200240
张健斌, 朱兰娟(上海交通大学自动化系, 上海 200240)
数据挖掘在轮胎均匀性试验数据上的应用
张健斌, 朱兰娟
(上海交通大学自动化系, 上海 200240)
摘 要:制造执行系统(MES)可以提升轮胎制造企业的运营水平,同时也集成了海量的制造环节数据,能够应用数据挖掘技术进行充分利用和挖掘,使信息更有价值。基于MES数据仓库中提取的轮胎质检工段的均匀性检测数据,采用特征选择的方法分析影响各规格轮胎均匀性的质量因素及权重,比较了基于信息论、统计、相似度的几种算法的应用效果。对于均匀性数据的冗余属性问题,利用LFS+CFS进行分析,发现降维后的属性在预测均匀性等级、归档压缩和质量管理方面展现出了价值。
关键词:轮胎均匀性;制造执行系统(MES);特征选择;数据挖掘;Python程序设计
0 前 言
数据挖掘技术在商业、银行、零售、基因工程等领域已经应用得十分广泛[1]。在工业领域,随着智能传感器以及集成以太网的控制器、驱动器、HMI、DCS、仪表的广泛应用,工业以太网技术将原本在车间里各自独立的各种机器、生产线、厂房设施、工艺流程、人员、产品等对象产生的信息,由底层的IoT兼容的控制器采集上来,MES/MOM等制造层信息系统对数据进行实时的采集和应用[2]。罗克韦尔公司的互联企业策略则提出,制造企业通过物联网技术实现互联互通,通过大数据技术和机器学习,转化和利用数据,可以改善制造企业的运营[3]。事实上,数据挖掘技术在工业领域,比如生产过程优化、质量管理、故障诊断、汽车制造、油田规划、矿藏产量等各个行业和生产环节都有所应用[4-7]。
中国的轮胎制造近些年得到飞速发展,产能达到全世界的30%,是世界轮胎生产大国,但品牌效应差、质量低下、同质化严重等问题较为突出。轮胎生产制造过程伴有大量数据,例如密炼、挤出、硫化的过程数据,以及设备状态、操作信息、质量信息等工艺数据,它们都反映了每个生产环节的状态。实时生产数据不仅能为生产管理的正确决策提供科学依据,若能进一步利用数据挖掘技术对这些数据进行分析,如能耗预测、质量问题分析、设备预维护、产品研发等等,就为轮胎制造厂家带来更大的回报[8]。
数据挖掘技术充分利用海量的数据,在大型数据库中探索和发现有用的信息,发现先前未知的模式或者预测未来的观测结果,并提供决策支持。常见的数据挖掘方法包括分类预测、回归预测、关联分析、聚类分析等[9]。数据挖掘技术包括很多方面,从流程上说大致有数据输入、数据预处理、数据挖掘、后处理、信息描述几个阶段,其中数据预处理在探索一个新的问题时会对整个分析过程起至关重要的作用。预处理是将原始数据转换成适合用于分析的数据,主要是数据清洗及处理缺失项、噪声、重复项。其实预处理阶段还有一些更具有价值的功能,即,当面对高维数据集时应用的特征选择、维规约、规范化、数据子集选择这些技术。本文从数据挖掘的视角,通过数据预处理的特征选择,对来自轮胎MES系统的均匀性实验数据进行了分析。
1 轮胎质检MES与轮胎均匀性检测数据
轮胎的生产制造工艺主要有密炼、成型、硫化、检测等工序,前工段属于流程制造,后工段属于离散制造,小批量多品种,生产过程复杂。为提升企业运营效率,越来越多的国内轮胎企业开始实施整厂级别的制造执行系统,简称MES[10]。
MES系统根据ISA-95标准[11]中的企业信息架构角度看,是属于Level 3,其下层是车间自动化层和SCADA层,MES负责对底层数据进行有机集成。车间采用工业以太网实现数据通信,如EtherNet/IP或者ProfiNet。在MES的上层一般是企业信息层,常见的有ERP等各种系统,MES需要通过ERP-GATEWAY中间件或者Web-Service等方法来进行ERP与MES的数据交互。因此,MES在运行中会处理和记录从车间层到企业管理层的制造运营相关数据,以MES中存储的数据作为数据挖掘对象,是很有潜在价值的。一些先进的MES软件平台同时提供了ODS(操作数据存储)的功能,帮助建立制造过程数据仓库,方便后续的数据挖掘。
轮胎工厂MES涵盖各个工艺段,轮胎检测工段是轮胎制造的最后一个工段,这个工段的MES系统将每个轮胎在各种检测设备上的检测分析数据和检测结果进行存储,以便今后的质量追溯。检测设备包括动平衡、均匀性、X光机、里程试验等。本文以均匀性试验数据作为对象进行数据挖掘应用。
均匀性试验机是检测轮胎不圆度性能的设备,通过轮胎在高速旋转时,设备上的传感器反馈回来的各种数据进行均匀性等级的判断,检测的指标主要有纵向力波动RFV、横向力波动LFV、侧向力积分LFD、自身锥向力CON、旋转锥向力PLY、半径变化RRO、宽度变化LRO、上胎侧尺寸变化LROT、下胎侧尺寸变化LROB、上胎侧鼓包BULGT、下胎侧鼓包BULGB、上胎侧凹陷DENT、下胎侧凹陷DENB等,其中RFV 和LFV会有额外的正反转测试和一次谐波分量分析。这些指标各自反应不同方面的质量特征,也是轮胎均匀性质量等级的判定依据。每个具体的指标包含传感器测量值和一个等级,例如RFVCW指标包含{数值,角度,等级},对应的某条数据记录为{5.34,321,A},数值和角度属性为连续变量,后文标记为f,基于数值角度得出的属性等级为离散变量,后文标记为fiG。以上各个指标总共的测量值共有40个,将所有的指标判定结果汇总,得到一个轮胎总的均匀性判定。判定规则由均匀性试验机设定,流程为:比较检测值fi与标准值,根据偏差大小和规则得出fiG,再根据所有fiG综合得到整体的均匀性等级G。规则信息保存在机器上,由专业人员人为制定,可以理解为If…Then…规则。规则不开放给MES系统和数据分析人员。在MES系统中集成的数据还包括轮胎条码、操作员、机台号、重力、压力、时间等相关数据,每条轮胎的均匀性数据有53个属性。
传统的轮胎质量管理人员对于均匀性会使用均值和方差的统计方法来进行质量控制,配合X-R控制图和SPC方法,但属性多、数据量大,分析工作会因过于繁杂而无法有针对性的重点解决质量问题。
2 特征选择与应用
轮胎的质量因素非常多,仅均匀性属性可达53个。回溯一条轮胎的整个生产环节,包括炼胶、硫化等过程参数,裁断成型等状态数据,快检数据……与轮胎质量相关的属性估计会多达上千个。
而如此庞大的、高维的数据,往往存在数据缺失、冗余、噪声的各种问题,最重要的是,高维数据会对数据分析造成维数灾难的问题。因此无论是从质量管理人员进行数据统计分析方面考虑,还是后期对数据挖掘算法的应用,都需要对这样的数据进行清洗和降维处理[12]。
降维后数据的优势一般有:提升分类和回归问题的预测性能;降低运算复杂度和训练时间并提高运算效率;增强对于一个复杂问题的洞察和理解能力,即以对业务的专业理解为基础,把需要改善的指标作为应变量,找出对其有影响的自变量。对于制造生产运营人员来说,可以透过复杂的、庞大的、难以理解的数据,快速了解生产过程中的关键指标,从而对影响和调整生产起到帮助作用。
特征选择(Feature Selection)和特征提取(Feature Extraction)是目前应用最多的两种降维方法,能够去除数据噪声和非相关属性、冗余属性。特征提取将原有的高维特征空间投影到一个新的低维特征空间,并且通常是由原来的特征空间的线性或者非线性组合而成。常见的算法有主成分分析PCA,即寻找表示数据分布的最优子空间;线性判别分析LDA,即寻找可分性判据最大的子空间;典型对应分析CCA,即通过找到两组基,使得两组数据在这两组基上的投影相关性最大。类似的还有SVD、ISOMAP、LLE、ICA、HSIC判别等算法等。特征提取的方法是将原有的特征空间映射到一个新的特征空间,在新的特征空间中,属性不再具备原空间的物理意义。因此,当讨论或者分析必须基于有实际物理含义的属性时,就需要使用特征选择的方法[3]。
相比特征提取,特征选择保持了原有属性的物理意义,在原有的特征空间中选择一个高相关度的子集,使得新的模型具有高可读性和可解释性。针对轮胎均匀性这一数据集,可以利用特征提取的方法,从53个属性集中提取出影响均匀性指标的几个重要特征属性,这几个重要的特征属性同时也是影响均匀性质量的关键质量因素。
根据数据集中有无类标记信息Label,即目标变量Target Variable,可分为有监督、无监督和半监督三种特征选择。其中有监督的特征选择,指的是每个实例包含了类标记信息,根据其离散或者连续值的不同,应用分类或者回归的方法进行处理。均匀性数据集有一列是轮胎的均匀性总等级指标,即为这个数据集的Label类标记信息,等级的集合为{OE1:优质,OE2:次优,OK:合格,DA:瑕疵品,DX:废品}。均匀性等级是根据数据集其余52(列)属性综合判断得出,因此轮胎均匀性数据集是一个有监督的分类问题。参考Jiliang Tang和Huan Liu的分类问题基本框架和姚旭、王晓丹等的特征选择基本框架[14],轮胎均匀性数据集等级分类的参考框架如图1所示。
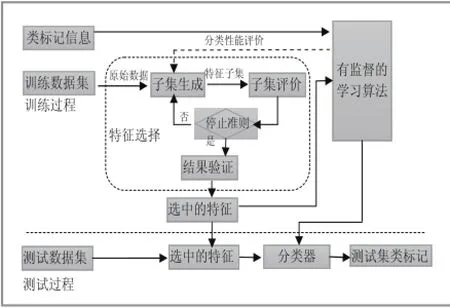
图1 有监督分类过程的一般框架
根据上图的框架可以看出,特征选择是分类问题的非常重要的一个环节。其一般由以下四个环节组成,首先基于某一特定搜索策略的生成备选特征子集,这通常是一个在特征空间中寻找特征子集的优化方法,总的来说有启发式、随机搜索和全局寻优三类,常用的方法有遍历法、贪婪算法、基因算法、特征排名Ranker、序列向前选择SFS、序列向后选择SBS等,各种方法各有优缺点,其中特征排名策略将每个属性的得分进行排名并选择得分较高的几个作为特征子集,得分对于属性的可解释性很有价值;第二步则是子集评价,通常分为Filter过滤式(采用了与后续分类器无关的评价准则,例如基尼指数、信息增益等)、Wrapper封装式(使用分类器的分类性能指标对特征子集优劣性进行评价,因此不会存在类似Filter造成的偏倚问题,缺点是计算量大,实际应用相对较少)、Embedded嵌入式(比如决策树、SVM等分类器使用了自身算法的特征子集)三类;第三步是停止准则,根据事先设定的条件决定这次的特征选择是否满足要求;第四步则是评估和验证获得特征子集。
如何选择正确的特征选择算法也需要考虑数据本身的特性,Li将众多的特征选择算法以数据视角进行了整理并编制了特征选择算法框架[15],根据数据的特性属于Static静态数据还是Streaming流数据、特征流还是数据流、多媒体还是文本、结构化还是扁平化(Flat Feature)等特性,全面地提出了对应的特征选择方案。对本文从MES中提取的均匀性数据对象,可以认为是静态的、扁平的文本数据,数据的属性间满足独立同分布 (IID) 特性且没有内在的结构化关联,适用扁平特征选择的方法进行分析。扁平特征选择也称为经典特征选择,一般有如下几种类型:
(1)基于相似度的特征选择,这一类的算法主要考虑数据间的相似度,监督学习中考虑属性与类标记的相似,比如皮尔逊相关系数;无监督学习中通常考虑数据间的距离,典型的算法有ReliefF、Fisher Score、Laplacian Score等。
(2)基于信息论的特征选择,通过信息增益Information Gain或者互信息Mutual Information来度量特征的重要程度,典型的算法有MIM、MRMR、FCBF等。
(3)基于稀疏学习的特征选择,特点是在添加稀疏正则化项的同时最小化拟合误差,而正则化获得稀疏解,使某些属性的系数很小或为零,将对应的属性移除,剩余的是被选中的属性,典型的算法有RFS、Least square loss (l2,1)、Logistic loss (l2,1)等。
(4)基于统计学的特征选择,这类算法有别于机器学习,主要是以统计方法为主,单独评价属性的重要性,通常不考虑属性间的冗余,典型的算法有T-score、Chi-square、GiniIndex等。
本次分析的目标是,对于同种规格和批次的轮胎,找出影响该特定轮胎均匀性等级判定的属性,并按照重要性排序。因此搜索策略采用特征排序(Ranker),属性评估采用能提供特征评分的算法。由于特征排序并不考虑属性冗余,再采用LFS(Linear Forward Selection)子集搜索[16]+CFS[17]属性评估算法进行冗余问题的辅助分析。
3 实验分析
本次试验平台使用Python(x,y)和Weka。 Python(x,y)集成了丰富的科学计算包Numpy和机器学习包Scikit-learn等,特征选择算法实现的库函数非常丰富,很多学者会将自己的算法在Python环境下做算法的实现,扩展性好;Weka作为一个集成的数据挖掘工具,内置了常见数据挖掘功能,可以快速对数据集进行处理和分析,但一般新算法的实现较慢。因此前期使用Weka进行数据集的清洗和基本算法测试,后期使用Python测试新的算法和系统实现。
从数据库仓库中提取数据进行分析,轮胎规格为310P2105。对均匀性检测机UF01上连续两天的均匀性质检数据,剔除噪声记录后,共有有效样本实例3456个,其中OE1级优质样本数有2898条,占比为83%;OE2级次优样本330条,占比为9.5%;OK级合格样本121条,占比为3.5%;DA级瑕疵品样本88条,占比为2.5%;DX级废品样本19条,占比为0.5%。其中优质等级占比较大,因此非优质品的属性会是重要的分类特征。对应的样本各属性均在正常范围内,每一种检测属性均近似正态分布,对这个数据集进行特征选择,通过Ranker特征排序提供的得分观察每个属性对于最后质量等级结果的影响。算法上选择信息增益InfoGain、基尼增益GiniGain、增益比率 GainRatio、对称不确定性SU、ReliefF算法,涵盖了以信息、统计、相似性为背景的各算法。
从表1所示各算法得出的特征属性得分来看,对于规格为310P2105的轮胎,质量问题影响最大的是自身锥向力CON,其次是侧向力积分LFD和半径变化RRO。后续的几个特征在各算法下的得分排名有所差异,但总体均在前10大属性中出现,特征的得分从第10个开始基本只有第1名的1/10。根据工程上习惯的大小数原理,在主要质量问题的分析上,忽略排名11开始后续的属性。并且事实上,26个属性中,大部分的属性在离散化后表现出了稀疏的特性。
为验证各算法选择的特征的有效性,对包含不同数量的特征子集,通过对应的分类预测准确度进行评价。评价时使用SVM[18]和C4.5[19]两种算法,测试采用十折交叉验证。两种算法下获得的结果如图2所示。
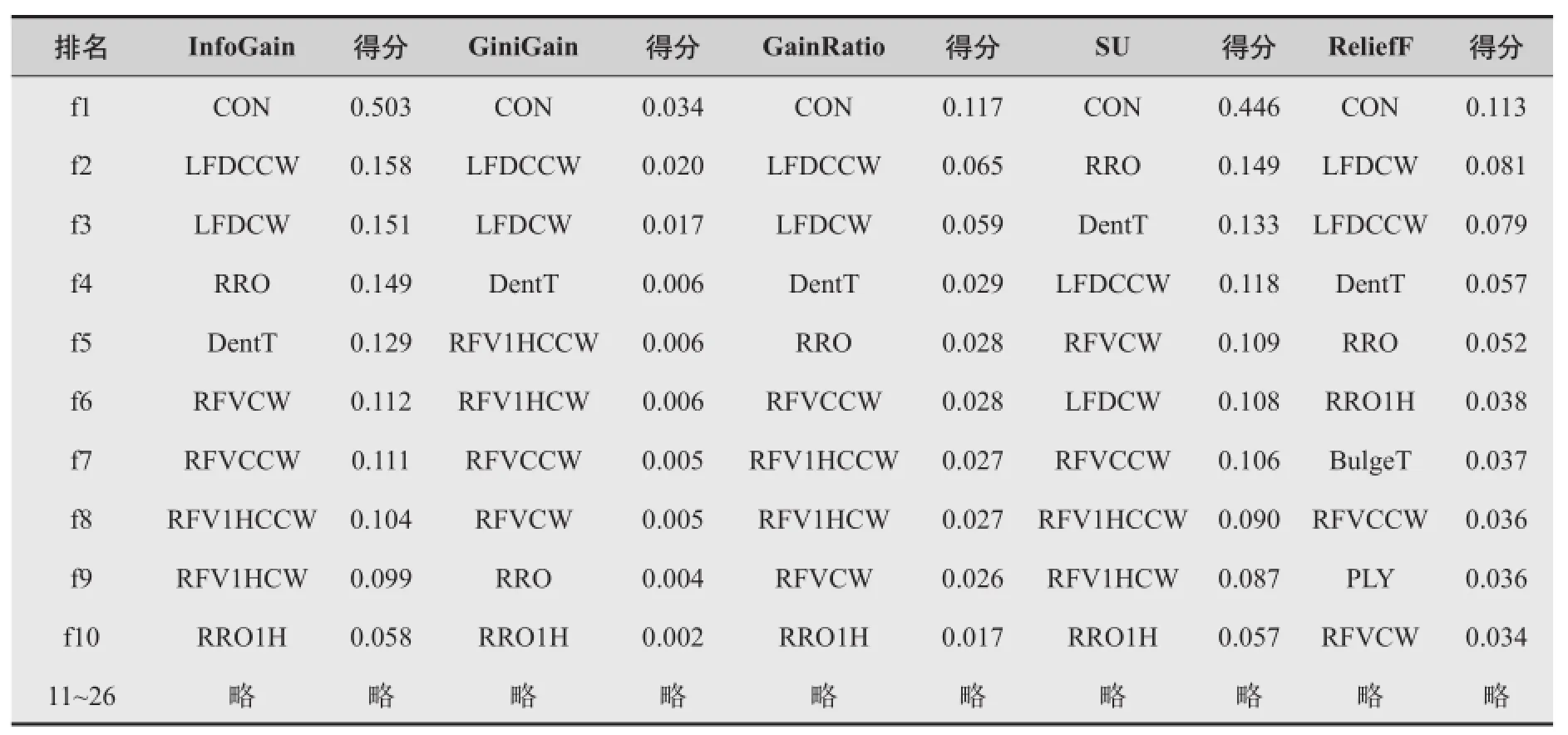
表1 各特征选择算法下属性得分表
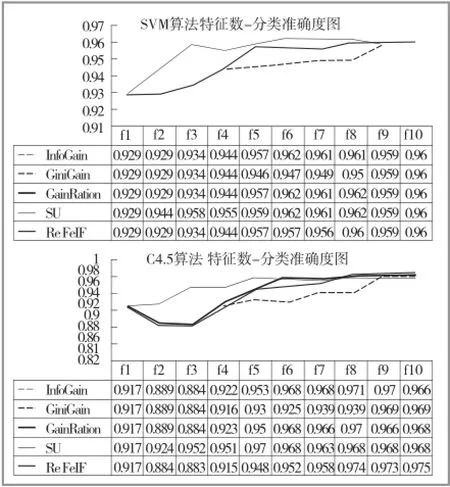
图2 SVM和C4.5下特征子集分类准确度图
从图2中可以看到,在两种验证算法下,第一特征CON即可使算法CA达到90%以上,即侧面反映这个因素是非常关键的质量因素。当特征子集达到5个时,SU算法下获得的特征子集的CA已经达到96%以上,所有算法在特征数达到9时基本趋于稳定,并且再增加属性也不提升CA,因此这些特征选择算法是有效的。
将每个属性在不同特征选择算法下的得分进行归一化处理(f'=f/∑f),作权重的分布对比分析。通过对比我们可以发现,GainRatio、InfoGain、GiniGain、SU、ReliefF算法下的属性得分或属性排名比较接近,除了GiniGain对RRO评分较低,ReliefF对PLY属性评分稍高,SU认为LFD的评分应该更低些。整体来看,属性从DentB开始得分趋近于0,表明后续属性对均匀性等级分类作用很小,甚至完全没有作用。

图3 各特征选择算法下特征权重比较
为评价算法得出的排名和权重(得分)的实际物理意义,查阅保存在现场的机器上的均匀性等级判定规则以及各属性单独的等级fiG,统计对均匀性等级G的决策影响的因素,即根据实际在设备上的等级判定过程和结果,统计关键决策所对应的fG的次数。例如在一个样本上,RRO使该样本的等级G被判定为DX,则被记一次,即RRO是造成这条胎DX问题的关键质量因素。汇总得到表2,并和InfoGain算法下的排名作一个比较。
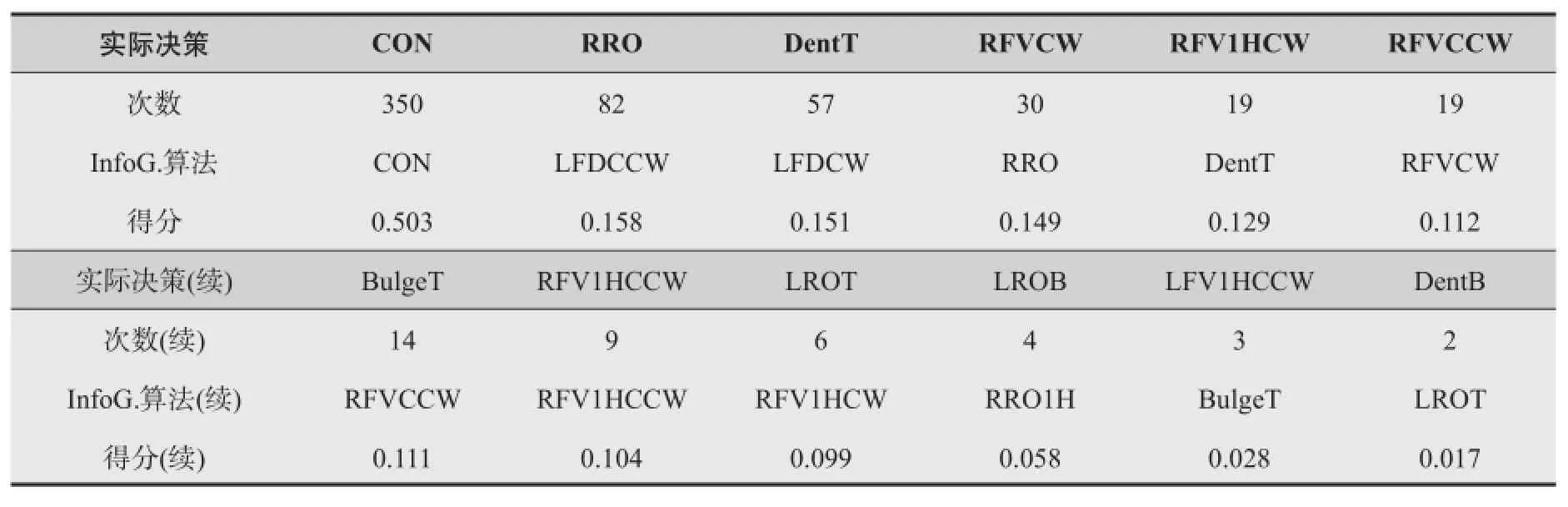
表2 实际决策属性统计与算法得分的比较
可以看到,实际的均匀性质量属性频次统计与信息增益算法的排名和权重非常接近,其中存在的差异是LFD正反转侧向力积分及RRO1H真圆度一次谐波没有参与等级判定决策,所以没有在机器的决策记录里面出现,但信息增益算法表明这三项质量属性是与最终的均匀性等级强相关的。事实上,在每种规格的轮胎均匀性判定规则中,质量管理人员都会按照经验或其他因素忽略掉26个检测值中的某几个指标,不放在等级判定规则中,这种实践中忽略某些属性的做法,在利用去除冗余的特征选择算法后得到了验证。去冗余验证方法采用LFS+CFS,获得最小特征子集为 {CON,RFVCW,RRO,LROT,LROB,Bulge T, DentT },这个最小子集在SVM(c=10, g=0.04,ε=0.01)和C4.5算法下,十折交叉验证的分类预测准确率CA分别为0.953和0.977,因此,在实践中,LFD和RRO1H等属性作为冗余属性,在规则判定中被省略是合理的,可以提高整个均匀性检验的效率。
4 结 语
轮胎MES系统提供了理想的均匀性检测数据集。对均匀性检测数据进行特征选择,可以快速筛选出与质量相关的属性,通过权重系数提示某一质量属性所造成的质量问题的严重程度,在数据归档的时候可以剔除稀疏属性,帮助压缩数据库,利用特征属性快速预测轮胎均匀性等级。用到的算法中,基于信息论的如InfoGain、SU和基于相似度的如ReliefF等算法表现较好,可以在实践中继续使用。而基于统计的方法在个别属性的权重得分表现不够理想。基于稀疏的方法则可以在后期予以进一步研究。另外,LFS+CFS可以有效找到轮胎均匀性问题的最小特征子集,可以实现对于质量属性的冗余分析,为简化现场质量分析工作提供了一种依据。
进一步的研究可以考虑完善MES的数据仓库,集成前工段的生产过程信息,进行均匀性质量属性与前工段生产过程与状态的关联分析,从源头上发现造成均匀性质量问题的因素,从管理上和技术上干预质量关键因素,从而改善均匀性质量乃至轮胎制造的整体质量水平。随着制造数据的进一步完备,数据挖掘技术在轮胎制造的MES数据环境下有着广阔的前景。
参考文献:
[1] Bharati M. Data Mining Techniques and Applications [J]. Indian Journal of Computer Science and Engineering,2010, 1(4): 301-305
[2] Choudhary A K, Harding J A, Tiwari M K. Data Mining in Manufacturing: A Review Based on the Kind of Knowledge[J]. J. Intell. Manuf., 2009(20):501-521.
[3] Rockwell Automation. The Connected Industrial Enterprise White Paper[R/OL].http://literature.rockwellautomation. com/idc/groups/literature/documents/wp/cie-wp001_-en-p.pdf
[4] Joaquin B, Ordieres M. Data Mining in Industrial Process[J]. Engineering Data Mining and Numerical Simulation,2005: 57-66.
[5] Rokach1 L, Maimon O. Data Mining for Improving the Quality of Manufacturing a Feature Set Deomposition Approach[J]. Journal of Intelligent Manufacturing, 2006, 17(3): 285-299.
[6] 孙卫祥. 基于数据挖掘与信息融合的故障诊断方法研究[D]. 上海: 上海交通大学, 2006.
[7] Rudolf K,Matthias S, Christian M. Data Mining Applications in the Automotive Industry[C].Singapore:4th International Workshop on Reliable Engineering Computing, 2010.
[8] Gunturkun F. A Comprehensive Review of Data Mining Application in Quality Improvement and a Case Study [D]. Ankara: The Graduate School of Natural and Applied Sciences of Middle East Technical University,2007.
[9] Witten L H, Frank E F, Hall M A.数据挖掘: 使用机器学习工具与技术[M]. 北京: 机械工业出版社,2014: 4.
[10] 张海燕. 轮胎企业制造执行系统(MES)的研究与应用[D]. 青岛:青岛科技大学,2006.
[11] ANSI ISA 95.01-2000. Enterprise - Control System Integration[S].
[12] Isabelle G, Andre E. An Introduction to Variable and Feature Selection[J]. Journal of Machine Learning Research 2003(3):1157-1182
[13] Mahdokht M, Glenn F, Jennifer G. From Transformation-Based Dimensionality Reduction to Feature Selection[C]. Haifa: The 27th International Conference on Machine Learning, 2010.
[14] 姚旭, 王晓丹, 张玉玺, 权文. 特征选择方法综述[J]. 控制与决策, 2012,27(2): 161-166.
[15] Li J, Cheng K, Wang S, et al. Feature Selection: A Data Perspective[R/OL]. http://arxiv.org/abs/1601.07996. Bibliographic Code: 2016arXiv160107996L. Arizona State University, 2016.
[16] Martin Guetlein, Eibe Frank, Mark Hall, Andreas Karwath. Large Scale Attribute Selection Using Wrappers[C]. Proc IEEE Symposium on Computational Intelligence and Data Mining, 2009: 332-339.
[17] Mark A H. Correlation-Based Feature Selection for Machine Learning[D]. Hamilton:The University of Waikato, 1999.
[18] Chih-Chung Chang, Chih-Jen Lin. LIBSVM: A Library for Support Vector Machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011(2):1-27.
[19] Quinlan J R. C4.5: Programs for Machine Learning[M]. Burlington: Morgan Kaufmann Publishers, 1993.
[责任编辑:朱 胤]
中图分类号:TP 274.+2
文献标志码:A
文章编号:1671-8232(2016)07-0045-07
收稿日期:2016-03-04
作者简介:张健斌(1981— ),男,硕士研究生,研究方向为工业工程与信息化。
Application of Data Mining in Tire Uniformity
Zhang Jianbin, Zhu Lanjuan
(Department of Automation, Shanghai Jiaotong University, Shanghai 200240, China)
Abstract:MES system could help the tire manufacturer improve their operations, integrate the manufacturing domain data, and could be benefited by data mining technology. Based on the tire uniformity test data extracted from the MES data warehouse, the infuence factors on the tire uniformity attribute were analyzed by feature selection method. The application effects of several kinds of algorithmaccording to information theory, statistics, similarity were compared. The solution of LFS + CFS was applied to eliminate the uniformity attribute redundancy feature. The attributes value went up by dimensionality reduction in the felds of uniformity forcast, archive compression and quality control.
Keywords:Tire Uniformity; MES; Feature Selection; Data Mining; Python Language
