星载IP交换机中变长调度Clos交换结构的设计
2016-09-03乔庐峰陈庆华邵世雷张俊俊
郑 振,乔庐峰,陈庆华,邵世雷,张俊俊
(中国人民解放军理工大学 通信工程学院,江苏 南京 210007)
星载IP交换机中变长调度Clos交换结构的设计
郑振,乔庐峰,陈庆华,邵世雷,张俊俊
(中国人民解放军理工大学 通信工程学院,江苏 南京 210007)
针对星载设备对体积、硬件资源消耗等严格限制的情况,为提高IP交换机的吞吐性能,同时尽可能地降低硬件开销与时延等,设计了一种用于星载IP交换机中的三级Clos交换结构。该结构可支持多个优先级,并采用变长分组调度机制,能够直接处理IP分组。该结构还对原有的三级Clos结构进行改进,将中间级部分整合为一个模块完成,便于在中间级实行集中调度,从而避免了在输出级模块中形成阻塞,同时简化了交换结构的实现过程,降低了硬件资源耗费。使用Xilinx xc5vlx330t FPGA实现了完整的16×16的八优先级变长调度交换结构,其峰值吞吐率可达16 Gb/s。综合结果显示,整个交换结构占用slice register 80352个、block RAM 252块,满足星载交换机的设计需求。
星载交换机;交换结构;Clos结构;变长调度;FPGA
0 引 言
信息技术的快速发展在大大方便人们工作、生产和生活的同时,也在不断产生海量的通信数据,这给当前的卫星网络带来了严峻的挑战。而网络的核心是路由器和交换机等节点设备,它们的性能直接影响网络的时延、吞吐量等重要参数。因此,研制高性能的星载交换机对于卫星网络来说显得尤为重要。
当前大多数交换设备所使用的是单级crossbar交换结构。这种结构因其简单、灵活等优点而得到广泛的研究和优化[1],然而由于受单个芯片端口数量和速率等的限制,该结构的性能已经逐渐到达极限[2]。同时,星载设备对体积、功耗等有着苛刻的限制,加上太空电磁环境恶劣,关键电路还需要使用备份来克服单粒子效应等带来的不良影响,这对星上交换电路的硬件资源消耗提出了更严格的要求。
此外,目前在星载交换设备中已经得到广泛应用的是ATM交换技术,而IP交换机在地面网的普及使得可以实现直接传输IP包的星载IP交换机成为研究热点[3-4]。
本文针对星载IP交换机设计并实现了一种改进的变长调度三级Clos交换结构,该结构可支持优先级服务,并具有可直接处理IP分组、结构模块化且占用逻辑电路资源少等优点。
1 交换结构的构成
Clos结构最早由Chales Clos于1953年提出[5],目前最常用的是三级Clos结构,其一般由k个输入级模块(Input Module, IM)、m个中间级模块(Central Module, CM)、k个输出级模块(Output Module, OM)排列而成,每一个交换模块和相邻级任一交换模块通过唯一路径相连。
在三级Clos交换结构中,人们使用最多的是存储器-空分-存储器(Memory-Space-Memory, MSM)结构,它曾被成功地用在ATLANTA交换机中[6],后来又不断得到应用和改进[7-8]。该结构在输入级和输出级模块中设置缓存,而在中间级模块中采用无缓存的交叉开关(crossbar)结构。相比于全空分结构,这种结构在调度上更简单,而相比于全缓存结构,它又有更低的时延和更少的资源消耗。
考虑到MSM型交换结构一般采用分布式调度算法,各个中间级模块之间的调度过程相互独立,且其调度算法较为简单,保持原有调度机制而集成到一个芯片上并不会增加算法复杂度,同时,无缓存的中间级模块结构简单,在端口数量不太多的情况下完全可以由一个模块代替,因此,本文提出了一种针对星载交换机改进的三级Clos交换结构,如图1所示。在满足电路性能要求的基础上,这种设计便于在中间级模块采取集中调度、有利于简化输出级电路,从而降低了交换结构的实现复杂度,同时还尽可能地降低了交换电路的体积、硬件资源耗费等。

图1 改进的三级Clos交换结构
1.1输入级模块
IM的结构如图2所示,每个IM都有n个输入端口、m条连接到中间级模块的输出链路、k个队列控制器(Queue Controller, QC)和一个输入级调度器等。
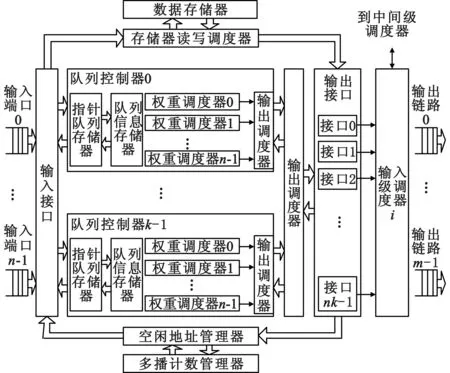
图2 输入级模块的结构
其中,k个QC分别用来管理去往不同输出级模块的虚拟输出队列(Virtual Output Queue, VOQ),每个QC中容纳pn个虚拟输出队列(p为优先级数,n为每个输出级模块的输出端口数)。一个QC内含有两个RAM、n个权重调度器和一个输出调度器,其中两个RAM分别作为指针队列存储器和队列信息存储器,n个权重调度器分别为各自相应的输出端口提供优先级服务,输出调度器则可以在不同输出端口的虚拟输出队列之间平衡获得接入的机会。
输入级调度器的作用是与中间级调度器协作,在公平的前提下,最大化地将已到达的输入请求分配到m条输出链路。
此外,为了节约存储资源,在每个IM中还设有一个SRAM作为数据存储器集中存放到达的数据、一个空闲地址管理器用以维护SRAM内的空闲指针信息。当有IP包到达,首先会从空闲地址管理器中读取空闲指针,根据指针位置将包存入SRAM中,然后根据数据包的目的端口和优先级将该指针以链表的形式在对应的QC中进行排队,队列存放在指针队列存储器中,每个链表队列的头指针、长度等信息存于队列信息存储器中。如果有一个包要去往多个目的端口,就将该包所存放的地址指针复制到各目的端口对应的队列中去,同时在多播计数管理器中计数。这种指针复制的多播实现方式也能有效地减少资源消耗。
1.2中间级模块
交换结构的中间级模块结构如图3所示,有mk条输入链路和输出链路、一个中间级调度器和一个mk×mk的crossbar。其中,中间级调度器的工作是协助k个输入级调度器完成链路的有效分配并避免发生冲突。mk×mk的Crossbar用来提供从输入级模块到输出级模块的无阻塞连接,可以直接将到达的数据转发出去。

图3 中间级模块的结构
1.3输出级模块
输出级模块的结构较为简单,有m条来自中间级模块的输入链路、n个输出端口和(m+n)个先入先出缓存(First Input First Output, FIFO)。其中每个FIFO各对应一个输入或输出端口,用来作为该端口的缓存,从而保证数据在输出端得到完整有序的输出。
2 交换结构的队列模型
在ATM网络中,数据都是被封装进固定大小的单元中,被称为信元。但是在IP网络中却不同,长度可变的IP分组最大可以支持65 535字节。为了能够在ATM交换技术的基础上传输IP分组,当前广泛使用的是通过分段重组来实现变长调度的信元交换模型。如图4所示,这种模型在每个输入端口都需要一个输入分段模块(Input Segmentation Module, ISM)把每个变长IP分组分割成多个长度固定的内部信元,然后在交换结构中以每个内部信元为单位进行调度传输。另外在每个输出端口采用一个输出重组模块(Output Reassembly Module, ORM),把来自不同输入端口的不同数据包进行重组复原,同时还要为每个数据流设置一个FIFO进行缓存[9]。

图4 基于分段重组的信元交换模型
这种模型虽然较为方便地实现了IP分组的传输,但是存在一些缺点。首先,当端口数量较多或者设有多个优先级时,信元的分段重组部分会消耗很多的硬件资源;其次,分段和重组的过程引入了一定的交换时延;此外,对于三级Clos等多级交换结构,信元间还会产生乱序,这样为信元重排要付出更大的代价。
针对资源消耗的问题,以nk×nk的三级Clos交换结构来计算,由于要在每个输出端口为来自不同输入端口的数据流各设一个缓存队列,所以需要(nk)2个队列,考虑到还要支持p个优先级服务,则共需p(nk)2个队列。而在相同的条件下,如果直接变长调度传输IP分组而不需要在输出端重组,那么将只需为每个输出端口设置一个缓存队列,即共nk个队列。显然,变长调度的方式可以有效降低输出级模块的电路资源消耗及设计复杂度。
然而,如果直接以IP分组为单位进行调度传输,由于IP分组长度的不确定性,在大规模交换结构中,这种纯分组交换的调度器将会复杂得难以实现[10]。因此,本设计采用了另一种以逻辑切分的方式实现变长调度的分组交换模型,如图5所示。这种方法并不是对IP分组采取真正的物理切割,而是在逻辑上将分组分成长度为64字节的定长信元,但属于同一个分组的信元在调度传输上仍然是按序连续的。当交换结构为一个信元建立输入输出连接后,该连接会一直保持直到来自该分组的最后一个信元传输完毕,这样在输出端就可以直接得到完整的分组。

图5 分组交换模型
3 交换结构内的调度器
3.1输入级调度器与中间级调度器
对于MSM型的三级Clos交换结构,为了避免内部阻塞和输出端口竞争等,人们先后提出了随机分配(Random Dispatching, RD)[6]、并发轮询分配(Concurrent Round-Robin-Based Dispatching, CRRD)[11]、并发主从轮询分配(Concurrent Master-Slave Round-Robin Dispatching, CMSD)[11]等调度算法。这些算法大多采用协议匹配的方式,一般为两次匹配过程,一次先是在输入级内部,由VOQ与输入级模块输出链路之间的匹配,第二次是输入级与中间级之间的匹配。这样的两次匹配需要输入级与中间级模块共同完成,因此在每个输入级模块中都需要一个输入级调度器,中间级模块还需一个中间级调度器。
在一般的三级Clos交换结构中,RD算法并不能很好地解决内部阻塞问题,而CRRD算法在非均匀流量下可能会引起一定的内部冲突。因此有人提出了一些改进的算法,如:分布式正交路由算法[7]、主动授权并发轮询调度算法[12]等。这些算法较好地提高了交换结构在多种业务流下的吞吐性能,然而实现起来相对复杂,且难以满足提供多优先级服务、支持变长调度等需求。而本文中改进的三级Clos交换结构由于其只使用一个中间级模块,其内部采用16×16的crossbar结构,且调度过程中在中间级可以由一个模块集中仲裁,已经尽可能地减少了一般三级Clos交换结构的内部冲突问题,因此完全可以参考CRRD算法完成调度器设计。
输入级调度器的作用是将该输入级模块中的至多nk个非空VOQ与m个输出链路之间通过“请求-允许-接受”的握手方式相互匹配建立连接,并且多次迭代以确保输出链路能得到充分使用。匹配的建立过程由nk个VOQ仲裁器和m个输出链路仲裁器共同完成。每个仲裁器都维护着一个轮询指针,根据指针的位置来选择建立连接的对象。
一个非空VOQ与输出链路匹配完成后,输入级调度器还需要向中间级调度器发送一个匹配请求,匹配的目标是与该VOQ的目的输出级模块相连的中间级输出链路。中间级调度器就根据各个输出链路所收到的请求,各选择其中一个确认匹配,选择的过程同样遵循各自的轮询指针。
两次匹配完成之后,从VOQ到输出级模块的通路便建立成功,该VOQ开始发送队首的信元。为了实现变长调度对同一分组的信元连续调度的需求,当一条通路建立完成后,输入级调度器和中间级调度器便要保持该通路的两个匹配状态,直到同一个分组的所有信元都按照顺序地传输完成才能断开连接再重新匹配。
基于CRRD算法的输入级调度器和中间级调度器结构简单,匹配的工作全部由采用轮询机制,实现较为容易。此外,通过保持匹配状态来完成单次传输整个分组,效率高并且有效降低了资源消耗。
3.2输入级模块内的其他调度器
考虑到在一个输入级模块内单次只能有一个输出接口访问片外存储器,即一次只能有一个队列获得输出机会,另外,在进行变长调度时,不同的队列中分组的长度可能会有较大差异,且不同端口所经过的流量特征也会有不同,为了在满足一定吞吐性能的同时尽可能保证公平性,还需要设置多个调度器。
首先是在每个QC内,为了在调度中实现对不同优先级队列的区分服务,设置了n个权重调度器,分别对应n个输出端口。在每次输出时,每个权重调度器要从p个优先级不同的队列中选择一个进行输出。本设计采用权重轮询(Weighted Round Robin, WRR)算法[13]实现,通过更改不同优先级在轮询列表中出现的频率来控制带宽分配,优先级越高则轮询的频率越高,该优先级对应的队列也就更容易得到输出机会。
其次是在QC与输入级模块输出接口之间,以及每个QC的输出端都有一个输出调度器,用来保证在去往不同端口的队列之间调度的公平性。在每次输出时,首先由QC与输出接口之间的输出调度器从k个QC中选择一个,然后在选中的QC内,再由输出调度器从n个权重调度器中选择一个进行输出。本设计采用轮询(Round Robin, RR)算法实现,每个输出调度器都通过简单轮询的方式选择输出对象,从而达到对每个输出端口的公平调度。
以上采用的WRR调度器和RR调度器结构简单、易于实现,能够尽可能地减少硬件资源消耗,同时,也能够在实现优先级调度的情况下保证各端口的公平。
4 仿真结果与分析
本文基于上述设计实现了一个16×16的八优先级变长调度三级Clos交换结构(n=k=4,p=8)。交换结构的具体电路设计使用Verilog HDL语言完成,并在Xilinx的xc5vlx330t FPGA上进行了实现。设计过程采用ISE Design Suite 14.3开发环境,并且用Modelsim SE 10.0a对整个电路完成了仿真。以下是一些关键电路的仿真结果。
4.1输入级调度器与中间级调度器工作仿真
图6所示的仿真波形是在一个输入级调度器内进行的匹配过程。图中①处表示在该输入级模块中,有四个输出请求,分别来自VOQ0、VOQ4、VOQ8和VOQ12,其中VOQ12要输出的是一个单信元分组,该分组长度不足64字节而只需用一个内部信元传输,VOQ8要输出的是一个分组内的首个信元,该分组由不止一个内部信元组成,而VOQ0和VOQ4要输出的则是各自分组的最后一个信元,并且该分组之前已经输出了一部分。可以看到在图中②处,输出链路0和输出链路1维持了之前已经分别跟VOQ0和VOQ4达成的匹配关系,而输出链路2和3则与VOQ8和12开始了新的匹配。经过两次迭代,该输入级模块内匹配全部完成,4个输出链路向中间级发送输出请求,如图中③处所示。

图6 输入级调度器工作仿真波形
图7是中间级调度器参与调度过程的仿真波形。以图中竖线游标处为例,中间级调度器收到了8个来自输入级的请求,其中4个IM的输出链路0都请求与CM输出链路4建立匹配、4个IM的输出链路1都请求与CM输出链路0建立匹配。可以看到CM输出链路4选择IM0的输出链路0回应了允许,CM输出链路0选择了IM0的输出链路1回应了允许。这样,两条连接就建立完成。另外,从整个仿真结果来看,中间级调度器中收到的各个请求都得到了较为公平的匹配机会。

图7 中间级调度器工作仿真波形
4.2输入级队列的调度过程仿真
本文实现的交换结构中有4个IM,每个IM中有4个QC,而每个QC中包含去往4个不同输出端口的共计32个队列。输入级内的各个调度器就是要保证所有队列都能得到公平的输出。
图8是针对优先级为0的条件下,各个IM中要去往输出端口0、4、8和12的4个队列的深度变化情况仿真结果。图中的数值表示各自队列中当前正在排队的分组数。由图可见,在优先级相同的情况下,各个队列都能得到均衡的调度机会,较好地保证了公平性。

图8 部分队列的深度变化仿真时序
4.3综合结果分析
使用Xilinx XST综合工具,对整个电路在xc5vlx330t FPGA上进行的综合,得到的综合结果报告如表1所示。该16×16的八优先级变长调度三级Clos交换结构设计共占用80 352个Slice Register、100 629个Slice LUTs和252块Block RAM,资源占用比率相对较少。因此该设计完全可以在一个芯片内实现,方便了三级交换结构在实现过程中的接口调试等工作,此外,使用两片FPGA即可实现整个电路的备份,满足星载交换设备的设计要求。

表1 器件资源使用情况报告
考虑到该交换结构的吞吐率主要与输入级模块内部数据存储器的访问带宽有关,而设计使用的SRAM数据位宽为128位、时钟频率为125 MHz,且一次读或写操作占用两个时钟周期,则SRAM读写带宽为8 Gb/s。因此在对SRAM读写操作均衡的条件下,每个输入级模块的吞吐率最高可达4 Gb/s,则该16×16交换结构的峰值吞吐率可达16 Gb/s。
5 结 语
本文针对星载IP交换机,设计并实现了一种支持多优先级的变长调度三级Clos交换结构。相比于文献[9]中实现的基于共享缓存的单级交换结构,本结构不仅可以扩展交换端口的规模,还大大提升了交换结构的吞吐性能。而相较于文献[7]中提出的中间级交换模块数目可变的Clos网络结构,本文实现的结构将多个中间级交换单元整合为单个中间级模块,简化了交换结构,不需要动态调整中间级模块的数目,降低了调度算法的复杂度,且占用更少的硬件资源,满足了高性能星载交换机的设计需求。下一步将要研究交换结构的进一步优化方法,以及对应的更加高效的调度算法。
[1]戴艺, 苏金树, 孙志刚. 高性能新型交换结构综述[J]. 电子学报, 2010, 38(10): 2389-2399.DAI Yi, SU Jin-shu and SUN Zhi-gang. A Survey on High Performance Switch Architecture[J]. Acta Electronica Sinica,2010,38(10):2389-2399.(in Chinese)
[2]夏羽. 高性能大容量多级交换结构与调度算法研究[D]. 成都: 西南交通大学, 2012: 3-5.
XIA Yu. Research on Multi-Satge Switch Fabric and Scheduling Algorithms for High-Performance and High-Capacity Switches[D]. Chengdu: Southwest Jiaotong University, 2012: 3-5. (in Chinese)
[3]王晶, 乔庐峰, 陈庆华等. 一种星载 IP 交换机队列管理器的设计[J]. 通信技术, 2015, 48(10):1196-1201.
WANG Jing, QIAO Lu-feng, CHEN Qing-hua, et al. Design of Queue Manager in Satellite-Borne IP Switch[J]. Communications Technology, 2015, 48(10): 1196-1201.(in Chinese)
[4]Buster D. Towards IP for Space-based Communications Systems: A Cisco Systems Assessment of a Single Board Router[C]//MILCOM. 2005, 5: 2851.
[5]Clos C. A Study of Non-Blocking Switching Networks[J]. Bell System Technical Journal,1953,32(2):406-424.
[6]Chiussi F M, Kneuer J G, Kumar V P. Low-Cost Scalable Switching Solutions for Broadband Networking: the ATLANTA Architecture and Chipset[J]. Communications Magazine, IEEE, 1997, 35(12): 44-53.
[7]陶淑婷. 三级Clos交换网络结构及其调度算法研究[D]. 西安: 西安电子科技大学, 2010: 25-44.TAO Shu-ting. Research on Switching Structure and Scheduling Algorithm for Three-Stage Clos Networks[D]. Xi’an: Xidian University,2010:25-44.(in Chinese)
[8]高雅, 邱智亮, 张茂森等. 一种支持单组播混合交换的Clos网络及调度算法[J]. 西安电子科技大学学报, 2013, 40(01):48-52.
GAO Ya, QIU Zhi-liang, ZHANG Mao-sen, et al. Integrating Unicast and Multicast Traffic Scheduling in Clos-Network Switches[J]. Journal of Xidian University, 2013, 40(01): 48-52. (in Chinese)
[9]沈泽民,乔庐峰,陈庆华等. 一种多优先级变长调度星载IP交换机交换结构的设计[J]. 电子学报,2014, 42(10):2045-2049.
SHEN Ze-min, QIAO Lu-feng, CHEN Qing-hua,et al. Design of Switch Fabric in Satellite Onboard IP Switch based on a Multi-Priority Variable-Length Packets Scheduling[J]. Acta Electronica Sinica, 2014, 42(10): 2045-2049.(in Chinese)
[10]GAN Ja-li, Keshavarzian A and Shah D. Input Queued Switches: Cell Switching vs. Packet Switching[C] //IEEE INFOCOM 2003. San Francisco: IEEE Press, 2003: 1651-1658.
[11]Oki E, Jing Z, Rojas-Cessa R, et al. Concurrent Round-Robin-based Dispatching Schemes for Clos-Network Switches[J]. IEEE/ACM Transactions on Networking, 2002, 10(6): 830-844.
[12]刘晓锋, 赵有健, 陈果. 一种面向MSM型Clos交换结构的启发式并发调度算法[J]. 软件学报, 2015, 26(10): 2644-2655.
LIU Xiao-feng, ZHAO You-jian and CHEN Guo. Heuristic Concurrent Dispatching Algorithm for MSM Clos-Network Switches[J]. Journal of Software, 2015,26(10):2644-2655. (in Chinese)
[13]ZHANG Y, Harrison P G. Performance of a Priority-Weighted Round Robin Mechanism for Differentiated Service Networks[C]//IEEE Computer Communications and Networks 2007. Honolulu:IEEE Press,2007:1198-1203.

郑振(1992—),男,硕士研究生,主要研究方向为高性能交换机和路由器相关技术;
乔庐峰(1971—),男,博士,教授,主要研究方向为通信和计算机网络中关键芯片和电路技术;
陈庆华(1976—) ,男,讲师,主要研究方向为交换技术和计算机网络;
邵世雷(1966—),男,博士,教授,主要研究方向为智能网络、通信网软件与系统开发;
张俊俊(1991—),男,硕士研究生,主要研究方向为高性能交换机和路由器相关技术。
Design of Clos-Network Switch Fabric with Variable-Length Packets Scheduling for Satellite Onboard IP Switches
ZHENG Zhen,QIAO Lu-feng,CHEN Qing-hua,SHAO Shi-lei,ZHANG Jun-jun
(Institute of Communication Engineering, PLA University of Science and Technology,Nanjing Jiangsu 210007,China)
Aiming at the strict restraints of volume and hardware resource consumption, and in order to improve the throughput of satellite onboard IP switches while reducing as possible the hardware overhead and time delay, a three-stage Clos-network switch fabric is designed and implemented, which could support multiple priorities and with variable-length packets scheduling, directly transmit IP packets. Benefiting from the modification of three-stage Clos network, this newly-designed fabric with one central module could easily implement centralized scheduling in middle stage and avert the blocking in last stage. Meanwhile, the switch fabric is simplified in implementation and decreased in resource consumption. Finally, a 16×16 three-stage Clos-network switch with 8 priorities is implemented in a Xilinx xc5vlx330t FPGA, and the throughput is up to 16Gbps. Overall results indicate that the whole fabric occupies 80352 slice registers and 252 block RAMs, and could satisfy the requirements of satellite onboard switches.
satellite onboard switch; switch fabric; Clos network; variable-length packets scheduling; FPGA
10.3969/j.issn.1002-0802.2016.03.021
2015-10-10;
2016-01-22Received date:2015-10-10;Revised date:2016-01-22
TP393; TN915.05
A
1002-0802(2016)03-0361-07
