SparkCRF:一种基于Spark的并行CRFs算法实现
2016-08-31朱继召贾岩涛乔建忠王元卓程学旗
朱继召 贾岩涛 徐 君 乔建忠 王元卓 程学旗
1(东北大学计算机科学与工程学院 沈阳 110819)2 (中国科学院计算技术研究所网络数据科学与技术重点实验室 北京 100190)
SparkCRF:一种基于Spark的并行CRFs算法实现
朱继召1,2贾岩涛2徐君2乔建忠1王元卓2程学旗2
1(东北大学计算机科学与工程学院沈阳110819)2(中国科学院计算技术研究所网络数据科学与技术重点实验室北京100190)
(zhujzh.paper@gmail.com)
条件随机场(conditionrandomfields,CRFs)可用于解决各种文本分析问题,如自然语言处理(naturallanguageprocessing,NLP)中的序列标记、中文分词、命名实体识别、实体间关系抽取等.传统的运行在单节点上的条件随机场在处理大规模文本时,面临一系列挑战.一方面,个人计算机遇到处理的瓶颈从而难以胜任;另一方面,服务器执行效率较低.而通过升级服务器的硬件配置来提高其计算能力的方法,在处理大规模的文本分析任务时,终究不能从根本上解决问题.为此,采用“分而治之”的思想,基于ApacheSpark的大数据处理框架设计并实现了运行在集群环境下的分布式CRFs——SparkCRF.实验表明,SparkCRF在文本分析任务中,具有高效的计算能力和较好的扩展性,并且具有与传统的单节点CRF++相同水平的准确率.
大数据;机器学习;分布式计算;Spark;条件随机场
条件随机场(conditionrandomfields,CRFs)[1]是在已知输入随机变量条件下,输出随机变量的条件概率分布模型.可以用于文本分析、计算机视觉、生物信息学等众多领域中的预测问题,如自然语言处理中的序列标记、中文分词、命名实体识别,实体间关系抽取等.随着互联网、物联网、云计算等技术的迅猛发展,网络空间中各类应用层出不穷,引发了数据规模的爆炸式增长[2],预计到2020 年,全球的数据总量将达到35ZB.传统的运行在单节点上的CRFs工具在处理大规模计算任务时(任务的计算规模与训练集大小、模板和输出标记数量有关),面临一系列挑战.一方面,个人计算机遇到处理的瓶颈从而难以胜任;另一方面,服务器执行效率较低.在面对大数据[3-4]时代下的大规模计算任务时,通过升级服务器的硬件配置来提高其计算能力的方法,终究不能从根本上解决问题.因而,将大规模计算任务转移到分布式集群平台上处理,成为了解决以上问题的有效途径.代表性的批处理系统有MapReduce[5],Storm[6],Spark[7],Scribe,Samza,Flume,Nutch,Dremel[8],Pregel[9]和Trinity[10]等,其中Spark近年来受到了更多用户的青睐并成为了最活跃、最高效的大数据通用计算平台.这些优秀分布式处理框架,使得开发分布式应用、充分利用集群中的资源变得十分容易,从而大大减小了大规模数据分析任务的难度.
为了解决CRFs在处理较大数据集时的低效问题,文献[11]基于多核实现了CRFs训练过程的并行化;文献[12]通过将学习过程分解为若干更小、更简单子问题的方式来处理复杂的计算任务;文献[13]基于MapReduce计算框架实现了CRFs的训练过程并行化,在保证训练结果正确性的同时,大大减少了训练时间,性能上也得到了一定的提升.然而,由于MapReduce自身的实现机制,每次Mapper需要将计算结果写入磁盘.对于训练过程需要大量迭代操作的机器学习算法,这在效率上存在瓶颈,尤其针对大规模训练数据集的计算任务.
针对单机CRFs在处理大规模训练数据集时存在的问题.我们采用“分而治之”的思想,基于ApacheSpark大数据处理框架设计并实现了运行在集群环境下的分布式CRFs——SparkCRF.SparkCRF充分利用了Spark提供的弹性分布式数据集(residentdistributeddatasets,RDD),将所有的数据转化成RDD存储在集群节点的内存中,实现了基于内存的分布式计算方式.最后,通过设计的3组实验,分别从执行效率、可扩展性和正确性方面对SparkCRF进行评估.实验表明,SparkCRF具有高效执行计算任务的能力和较好的可扩展性,并且具有与CRF++相同水平的预测准确率.
1 背景知识
1.1条件随机场
CRFs作为一种统计序列模型首先于2001年被Lafferty提出[1],至今,已被广泛应用到自然语言处理、计算机视觉、生物信息学等众多领域中.模型思想的主要来源是最大熵模型,是在给定待标记的观察序列条件下的整个标记序列的联合概率分布,模型中的概率计算、学习和预测3个问题的解决和隐马尔可夫模型(hiddenMarkovmodel,HMMs)模型类似,使用到的算法如前向-后向和维特比.
CRFs是一种用来标记和切分序列化数据的概率统计模型.通常被用于在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率.标记序列的分布条件属性,可以让CRFs很好地拟和现实数据,而在这些数据中,标记序列的条件概率信赖于观察序列中非独立的、相互作用的特征,并通过赋予特征以不同权值来表示特征的重要程度.
条件随机场的定义:设X与Y是随机变量,P(Y|X)是在给定X的条件下Y的条件概率分布.若随机变量Y构成一个由无向图G=(V,E)表示的马尔可夫随机场(Markovrandomfield,MRF),即P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v)对任意节点v成立,则称条件概率分布P(Y|X)为条件随机场,其中w~v表示在同G=(V,E)中与节点v有边链接的所有节点w,w≠v表示节点v以外的所有节点,Yv,Yu,Yw为节点v,u,w对应的随机变量.
①https:sourceforge.netprojectscrfpp
条件随机场能够充分地利用上下文信息从而达到良好的标注效果,目前实际应用中最常用的是一阶链式结构的CRF模型,即线性链结构(linear-chainCRFs),其结构如图1所示:
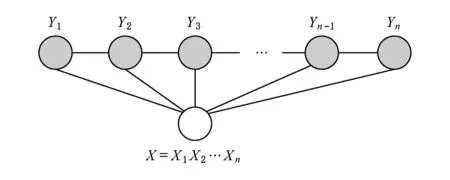
Fig. 1 The structure of linear Chain CRFs.图1 线性链条件随机场
条件随机场的参数化形式定义:设P(Y|X)为线性链条件随机场,则在随机变量X 取值为x的条件下,随机变量Y 取值为y 的条件概率

其中,
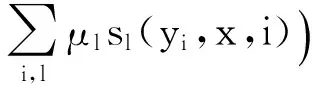
式子中,tk和sl是特征函数,λk和λl是对应的权值,Z(x)是规范化因子,求和是在所有可能的输出序列上进行的.tk是定义在边上的特征函数,称为转移特征,依赖于当前和前一个位置,sl是定义在节点上的特征函数,称为状态特征,依赖于当前位置.tk和sl都依赖于位置,是局部特征函数.通常,特征函数tk和sl取值为1或0;当满足特征条件时取值为1,否则为0.条件随机场完全由特征函数tk,sl和对应的权值λk、λl确定.
1.2Spark计算框架
Spark[7]是一种基于内存计算的分布式集群计算框架.与MapReduce相比具有多方面的改进,即较低的网络传输和磁盘IO使得效率得到提高,Spark使用内存进行数据计算以便快速处理查询、实时返回分析结果,Spark提供比Hadoop更高层的API,同样的算法在Spark中的运行速度比Hadoop快10~100倍[7].
Spark是为集群计算中的特定类型的工作负载而设计,即在并行操作之间重用工作数据集(比如机器学习任务)的工作负载.Spark的计算架构具有3个特点:
1)Spark拥有轻量级的集群计算框架.它将Scala应用于其程序架构,而Scala这种多范式的编程语言具有并发性、可扩展性以及支持编程范式的特征,与Spark紧密结合,能够轻松地操作分布式数据集,并且可以轻易地添加新的语言结构.
2)Spark包含了大数据领域的数据流计算和交互式计算.Spark可以与HDFS[14]交互取得里面的数据文件,同时Spark的迭代、内存计算以及交互式计算为数据挖掘和机器学习提供了很好的框架.
3)Spark有很好的容错机制.Spark使用了RDD,RDD被表示为Scala对象分布在一组节点中的被序列化的、只读的、具有容错机制的并且可被并行执行的对象集合.Spark高效处理分布数据集的特征使其成为了最活跃、最高效的大数据通用计算平台.图2描述了Spark的运行模式.
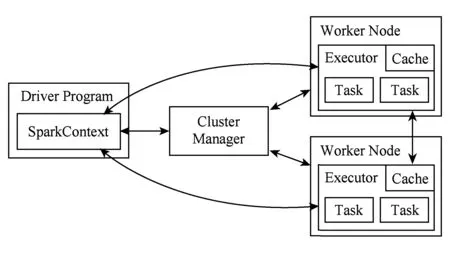
Fig. 2 Operation schema of Spark.图2 Spark运行模式
2 问题提出
在众多的CRFs算法工具中,最具代表性的是CRF++①.CRF++提供了Linux和Windows2个版本,是一款开源的用于分词、序列标记等任务的工具.它的设计和实现基于通用性的目的,并已被应用于多种自然语言处理任务.CRF++是单机程序,它能够处理的计算规模与机器的硬件配置关系密切,其中计算规模与训练集大小、模板和输出标记数量有关.这些单机实现工具在处理计算规模较大的任务时,面临一系列挑战.1)由于个人计算机的处理能力有限,在面对较大规模的计算任务时往往难以胜任;2)服务器处理能力较为强大,但在处理大规模计算任务时执行效率却不够高.单纯的通过升级服务器的硬件配置来获得更强的处理能力的方法,面对大数据时代下更大规模的处理任务,其终究不能从根本上解决问题.
①http://nlp.fudan.edu.cn//nlpcc2015//
我们以CRF++为例,通过实验来说明以上问题.实验设计如下:1)实验环境:运行环境分别为个人计算机和服务器,配置信息见表1;2)实验数据:使用NLPCC2015①公开数据集,选用中文分词数据集train-POS-EN.txt,该数据集大小共3MB,包含10 000个句子,输出标记共122个;3)模板配置:分别使用窗口大小为3和5的配置模板用于训练过程中特征抽取.

Table 1 The Configuration of Experiment Platforms表1 实验平台配置信息
对于个人计算机,我们对训练集以句子为单位进行切分,切分后的训练集包含的句子总数分别为:100,200,300,400,500,….在每个训练集上按照实验的设计对每个训练过程分别重复进行5次,取5次的平均执行时间作为最终结果,并统计对应的特征数,实验结果如图3所示:
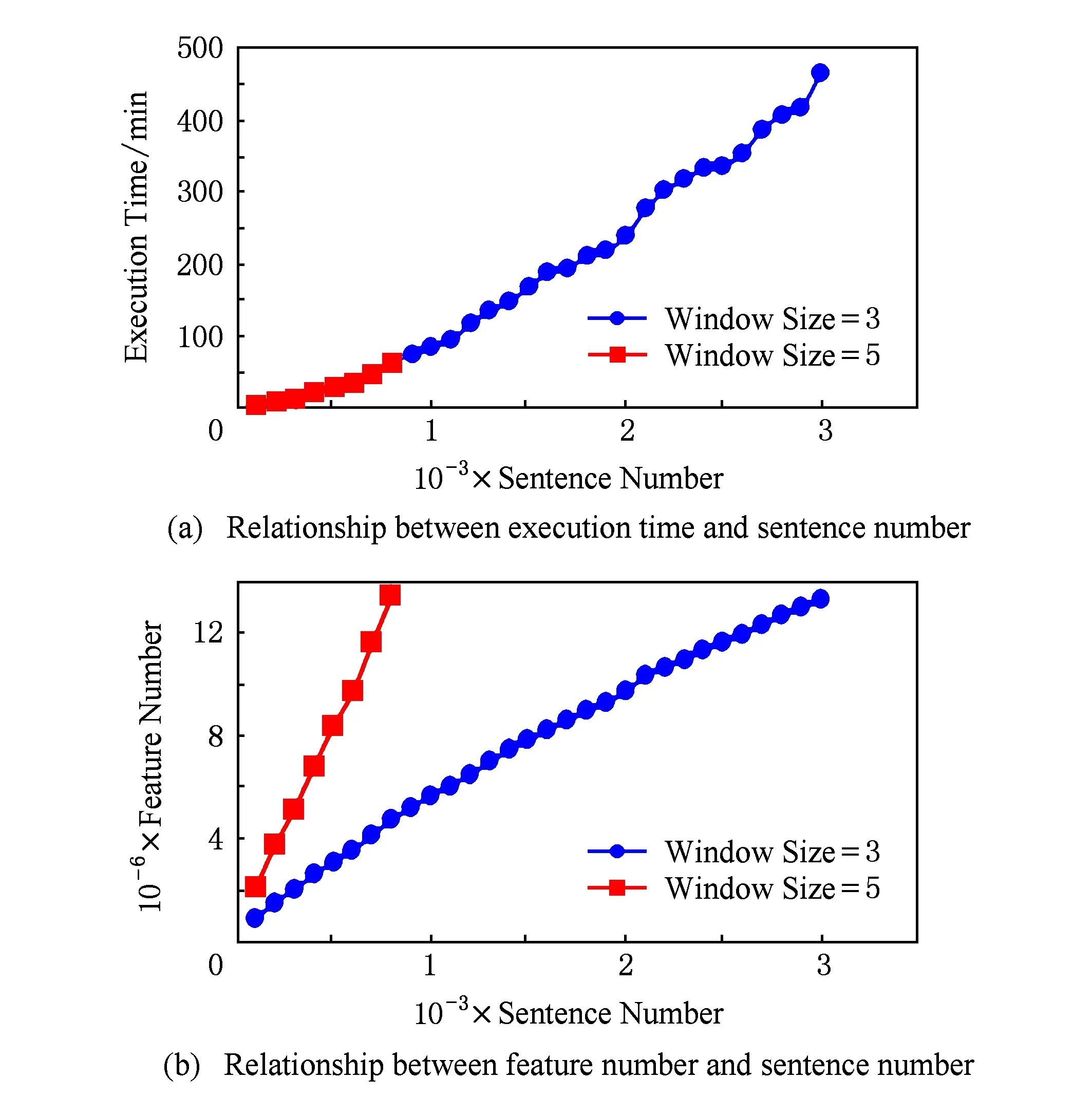
Fig. 3 Experiment results on personal computer.图3 个人计算机上实验结果
从图3(a)可以看出:窗口大小为3时,能够处理的训练集最多为3 000条句子;窗口为5时,能够处理的训练集最多为800条句子.当训练集大小达到上限后,若继续增加训练句子数量,将会导致系统异常而终止程序运行.出现这种现象的原因从图3(b)中可知:随着训练集句子规模的增大,对应特征数量也在增长.但对于相同规模的训练集,特征数量却不同,这与所使用模板窗口大小有关.对于不同的窗口设置,当到达机器所能处理的上限时,所对应训练集的特征数基本相同(约1 400万).
对于服务器,我们同样按句子对训练集进行切分,切分后的训练集句子总数分别为:1 000,2 000,3 000,4 000,5 000,…,10 000.在每个训练集上按照实验的设计对每个训练过程分别重复进行5次,取5次的平均执行时间作为最终结果,并统计对应的特征数,实验结果如图4所示:
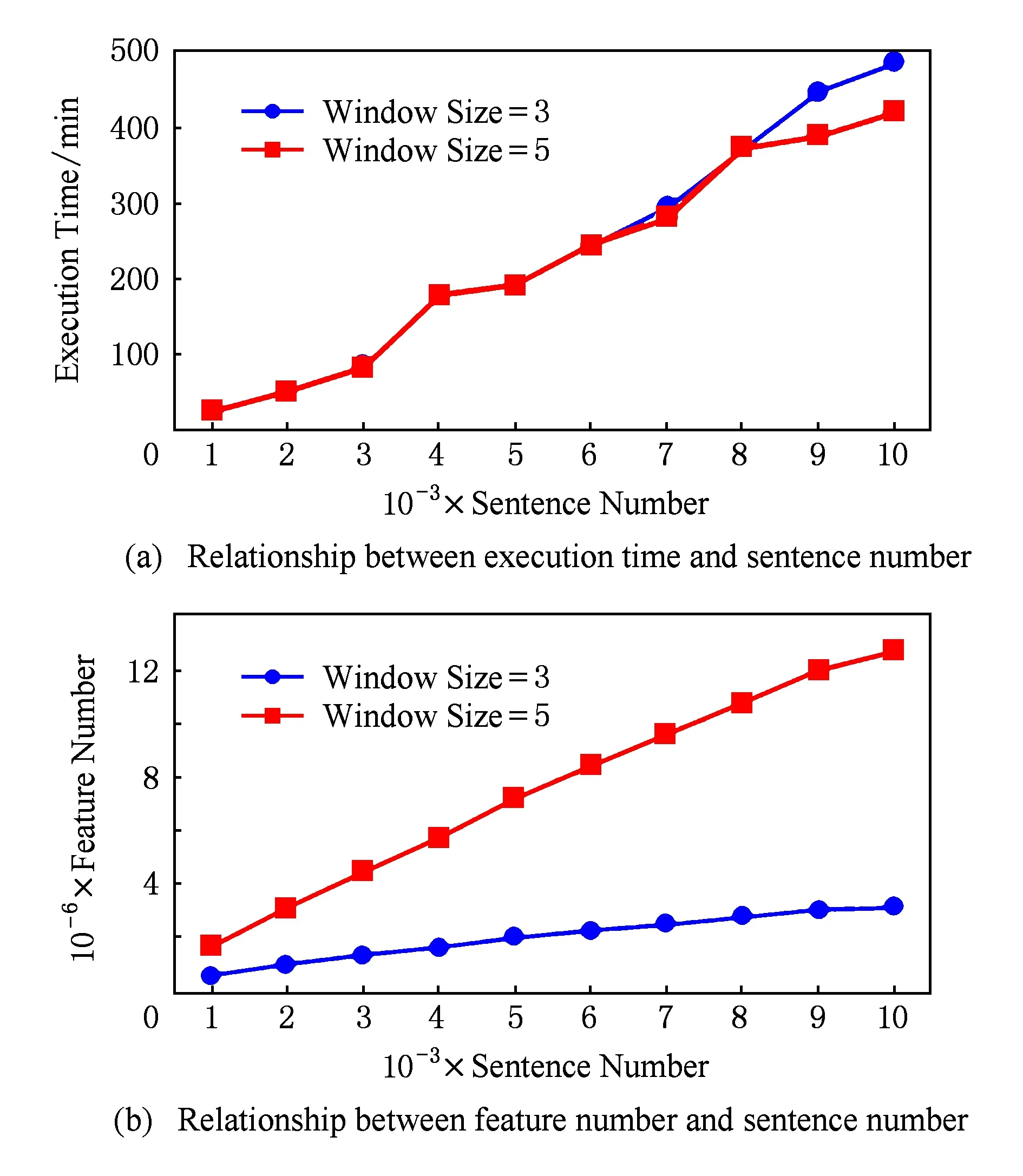
Fig. 4 Experiment results on server.图4 服务器上实验结果
从图4(a)可知,训练时间随训练集的增大不断增长;当训练集大小从1 000增加到8 000时,2种窗口情况下的耗时基本相同.从4(b)可以看出,随着训练集的增加,特征个数成线性增长;窗口为5时的增长速度远快于窗口为3时.当训练集增加到10 000个句子时,整个训练过程需要7h以上,而此时的训练集却仅仅3MB.
实验告诉我们:对于个人计算机,其能够处理的计算规模十分有限;而服务器执行效率较低.通过升级服务器的硬件配置来提高其计算能力的方法,在处理大规模的文本分析任务时,终究不能从根本上解决问题.
根据以上实验分析设想:如果将大的训练集合分割成若干个小的训练集,在多台机器间分布式并行执行,即采用“分而治之”的思想协同工作,那么可处理的训练集大小将会成线性增长.本文以此为动机,将传统的CRFs单机运行模式实现为分布式集群运行模式,采用目前分布式计算框架Spark,以HDFS[14]作为数据存储平台.
3 相关工作
从2001年CRFs被Lafferty提出,已被广泛应用到自然语言处理、计算机视觉、生物信息学等众多领域中.到目前为止,很多工作致力于CRFs算法工具的实现,最具代表性的是CRF++.此外,还有CRF-ADF,GRMM,DGM,CRFall,CRFSuite等.以上实现存在单机运行模式的共同特点,因此,使用这些工具处理大规模计算任务时必然会面临一系列挑战:1)个人计算机遇到处理的瓶颈从而难以胜任;2)服务器执行效率较低.
文献[11]为了解决CRFs的训练过程在规模较大数据集耗时、低效问题,基于多核实现了CRFs训练过程的并行化.使得CRFs能够处理的训练集规模可达到百上千条序列和百万级别特征;文献[12]通过将学习过程分解为若干更小、更简单子问题的方式,来处理复杂的计算任务;文献[13]通过在CRFs模型中引入惩罚项控制非零系数的个数,同时又可避免能够导致大维度参数设置的数字问题.在忽略执行时间因素下,实现了CRF用于处理几百个输出标志和多达几十亿特征的训练任务;文献[15]对CRF采用平均场近似推理及高斯对势函数,提出一种新的神经网络CRF-RNN,用作CNN的一部分来得到一种具有CNN和CRF的属性的深度网络应用于图像识别.
文献[16]基于MapReduce计算框架实现了CRFs的训练过程并行化.该方法确保训练结果正确性的同时,大大减少了训练时间,性能也得到了一定的提升.由于MapReduce自身的机制,每次Map完成需要将操作结果存入磁盘,这显然对于训练过程需要大量迭代操作的机器学习类算法在实现效率上存在瓶颈.因此,这种基于MapReduce的实现虽然能够处理较大规模的训练集和特征集,但运行效率并不高.
文献[17]基于Spark提出一种并行蚁群优化算法,相比于基于MapReduce平台下的实现,在速度上提升10倍以上;文献[18]基于Spark实现了并行化频繁项集挖掘算法,并在多项基准实验上与基于MapReduce的实现算法进行对比,实验证明基于Spark的频繁项集挖掘算法比基于MapReduce的实现在运行速度上平均提升了18倍.语义数据在大数据时代下快速增加,传统的单机语义推理实现工具的处理能力面临了严峻的挑战;文献[19]在Spark框架上实现了一种高效的大规模RDFSOWL推理工具Cichlid,并具有良好的可扩展性和容错能力.
4 SparkCRF的实现
本节描述SparkCRF的实现过程,在工作流程上它包含2个阶段:训练和预测.SparkCRF在集群中通过创建DriverExecutor进程实现分布式运行,对输入数据格式的要求与CRF++一致.
4.1训练阶段
训练阶段包含数据加载、特征抽取和循环迭代调整特征权重的训练过程,最终生成训练模型.
该阶段所用到特征模板、训练集数据预先存储在HDFS中,将数据转换成SparkRDD形式存储到集群的内存,图5描述了通用的加载过程.
特征模板和训练集数据以Block形式存储在HDFS系统中,由SparkContext对象通过textFile方法将数据转化为以Partition形式存储的RDD并加载到内存中.对于特征模板RDD调用filter并传入规则,将无效数据过滤,然后分别获取U和B模板.训练集RDD通过一系列转换(transformations)操作进行处理,将原始数据以句子为单位根据自定义的类型转化为句子封装类,每个Partition中包含若干个封装类单元存储在集群节点的内存中.
算法1. 训练过程伪代码.
输入:训练集RDD、SparkContext对象、迭代最大次数和收敛条件;
输出:特征集合、权值向量、模型元数据.
Loop:
Executor:
对每个包装实例:
重置图中所有node和edge对象的cost值;
ForwardBackward();
Viterbi();
Driver:
更新期望;
调用L-BFGS算法模块更新权值向量;
EndLoop
算法1描述了训练过程的总体流程.训练集RDD,SparkContext对象、训练过迭代最大次数及收敛值作为过程的输入;这里以NLP中序列标记为例进行描述,训练过程开始先将特征模板RDD广播到各个工作节点.在各工作节点上,对训练集以句子为单位进行特征抽取并转化成一个句子包装类别实例,这样训练集RDD被转化为新的RDD存储在内存中.新的RDD中的每个实例对象包含有m×n大小的图,其中m和n分布代表句子中含有的字个数和可能的输出标记个数.Driver进程根据抽取的特征集大小初始化对应的权重数组.训练迭代过程开始,每个句子包装对象中:1)重置图中节点对象和边对象的cost值;2)调用ForwardBackward函数(见算法2)计算图中每个节点的α和β值.前向算法是给定到特定观测及该观测之前的所有连续观测序列,计算该观测下特定状态出现的概率,后向算法是给定到特定观测及该观测之后的连续观测序列,计算该观测下特定状态出现的概率.3)计算每个特征的期望改变量,以〈index,incremental_value〉对的形式临时存储下来,待解码过程完返回给Driver进程;4)解码过程调用函数Viterbi(见算法3)实现.Driver进程首先更新期望数组的值,然后使用L-BFGS算法对权值数组进行更新.每次迭代过程结束,判断是否满足终止训练的条件.训练过程结束后,输出特征的权值向量、特征集合和模型的元数据信息.
算法2.ForwardBackward实现过程伪代码.
Fornum_r=1to句子长度total_lengthdo
Fornum_c=1to输出标记数tags_numberdo
计算图中第num_r行,第num_c列节点的前向概率α;
计算图中第total_length-num_r行,第num_c列节点的后向概率β;
计算当前节点所以输出边edge的cost值;
EndFor
计算规范化因子Z;
EndFor
算法3. 训练Viterbi实现过程伪代码.
Fornum_w=1to句子长度senten_lengthdo
Fornum_t=1to输出标记数tags_numberdo
初始化变量best_cost, best_node;
获取第num_w -th行、第num_t -th 列的节点,用node_w_t表示;
遍历节点node_w_t的所有输出边edge;
对节点的所有输入边:
计算边的总代价cost,当前节点node_w_t的cost及前向连接节点中最小的cost的节点;
IFcost>best_cost
更新best_cost;
更新best_node;
ENDIF
更新节点node_w_t的前驱指针prev;
更新节点node_w_t的best_cost;
EndFor
EndFor
Return最优的路径,即输出标记序列.
每轮迭代过程,Driver进程与Executor进程通信2次:1)广播特征权值向量;2)接受各个Executor返回的期望增量集合和局部的梯度改变量.数据的传递和接受基于Spark内在操作机制完成.
4.2预测阶段
Driver进程首先从HDFS上读取训练好的模型数据和测试集并转化为RDD存储在内存中,将模型RDD广播到各个工作节点的Executor进程.Executor进程执行特征抽取操作,重置图中节点对象和边对象的cost值,通过ForwardBackward算法完成路径代价的计算,最后使用维特比算法解码找出最优的输出标记序列.
①http://www.sighan.org//bakeoff2005//
算法4. 预测过程伪代码.
Driver:
从HDFS加载训练模型和测试集,转化为RDD;
将模型广播到工作节点;
Executor:
对测试集RDD进行map操作;
对每个包装对象:
生成特征;
重置图中所有node和edge对象的cost值;
ForwardBackward();
Viterbi();
输出预测序列.
5 实验结果与分析
实验在我们的集群服务器上进行,共有8台配置相同的服务器节点组成(配置信息见表1),其中主节点1台、从节点7台. 集群服务器操作系统为CentOS6.6,安装有JDK1.8.0,SparkCRF的设计和实现基于Spark-1.5.2.其中,HDFS与Spark集群安装在同一集群服务器.实验使用到的数据均已存储到HDFS中,并且数据格式与CRF++的输入数据要求一致.
我们设计了3组实验,分别从执行效率、可扩展性和正确性方面对SparkCRF性能进行评估.由于预测阶段是一个使用训练过程生成的模型对测试数据进行解码的过程,各个工作节点在获得Driver进程广播的数据后,整个过程均在各工作节点的Executor进程中执行,Executor间不存在数据的传输.因此,预测阶段执行时间与参与工作的节点个数成正线性关系.因此,高效性和可扩展性的验证,我们只对训练阶段进行.
5.1高效性
为了验证SparkCRF比单机CRF算法工具更加高效,我们继续选用NLPCC2015公开数据集中的train-POS-EN.txt数据,将其切分为句子条数为1 000,2 000,3 000,…,10 000的10份数据分别用于训练,单机程序继续使用CRF++.考虑到单机下的训练过程十分耗时,我们复用第2节的实验数据.我们将训练数据集分别在集群环境下使用SparkCRF运行,实验在Spark集群可获取的最大服务器资源下进行.当模板窗口大小为3时,实验结果如图6(a)所示,窗口大小为5时,结果如图6(b)所示.
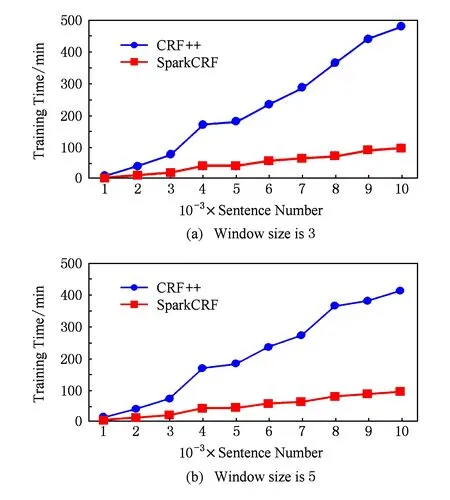
Fig. 6 CRF++ vs SparkCRF.图6 CRF++与SparkCRF对比结果
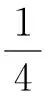
5.2可扩展性
我们的实验在第2届国际中文分词公开数据集①上对SparkCRF进行可扩展性测试.公开的数据集包含4套用于训练和测试的数据,它们分别由微软亚洲研究院(MicrosoftResearchAsia,MSR)、香港城市大学(CityUniversityofHongkong,CityU)、台湾中央研究院(AcademiaSinica,AS)和北京大学(PekingUniversity,PKU)提供.根据我们的了解,这份数据集是目前可免费获取到的最大的中文分词数据集,由于其在数据格式与SparkCRF对输入数据的格式要求不一致,因此我们开发一个数据格式转换程序对其进行预处理.训练数据的详细统计信息见表2所示,其中WT代表WordTypes,SN代表SentencesNumber,PFS代表ProcessedFileSize.
实验在仅处理器核数为可变因素、其他所有因素均不变的条件下进行.我们将SparkCRF的工作核数分别设定为50,70,90,110,130和150来验证其可扩展性能.对每个训练数据,分别在指定的每种处理器核数下,对同一实验重复进行5次,记录下运行时间,最后对这5次结果取平均值作为执行时间.实验结果如图7所示.
Table2StatisticalInformationoftheSecondInternationalChineseWordSegmentationBakeoff
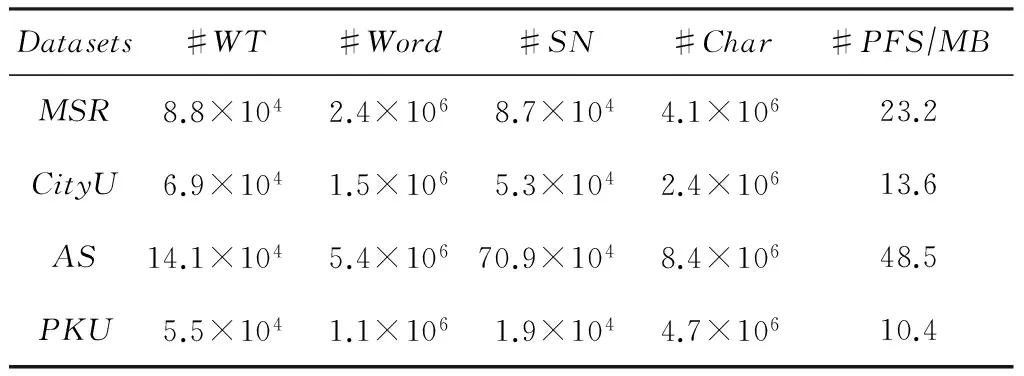
表2 第2届国际中文分词数据集统计信息
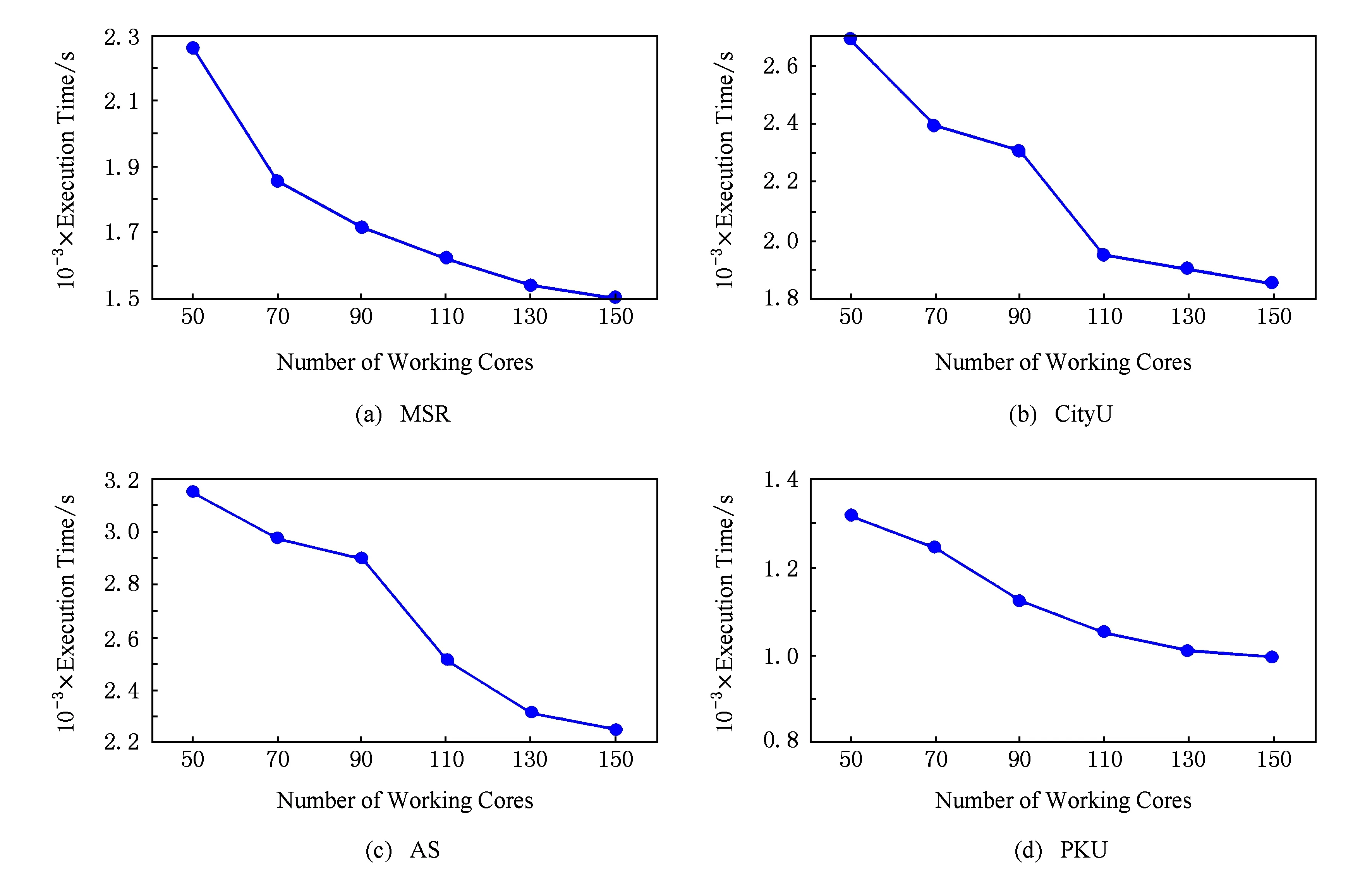
Fig. 7 Relationship between core number and execution time on different datasets.图7 不同数据集上核数与执行时间的关系
图7(a)(b)(c)(d)分别描述了在训练数据集MSR,CityU,AS和PKU上的实验结果.我们从图7中发现:1)随着工作核数的增加,不同数据集上的训练时间均在减少;2)不同数据集间的表现虽有一定的差别,但总体上工作核数与执行时间均呈现出了线性的关系.
5.3正确性
为了检验SparkCRF的正确性,我们选择与CRF++进行实验对比.实验训练数据集使用NLPCC2015公开数据集中的train-SEG.txt,预测数据集为对应的test-Gold-SEG.txt.通过2组实验进行验证,特征模板窗口大小分别设置为3和5,训练集包含的句子数分别为1 000,2 000,3 000,…,10 000.
按照实验的设计,1)分别使用CRF++和SparkCRF在训练集集合上进行训练,分别生成的模型;2)使用生成的模型分别用于对标准测试集进行预测;3)统计预测的准确率.图8(a)展示了窗口大小为3时的结果,图8(b)为窗口大小为5时的结果.
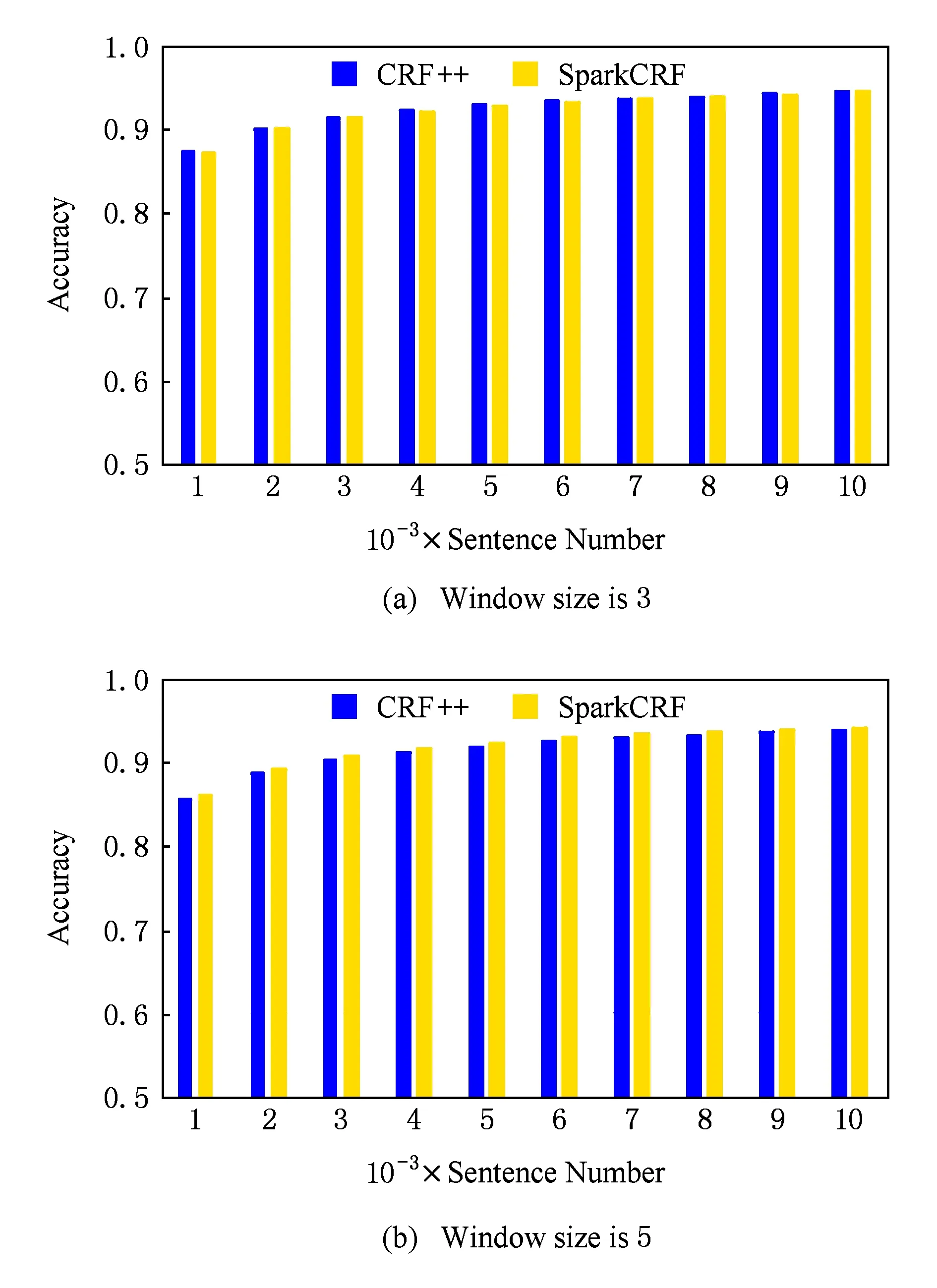
Fig. 8 Relationship between sentence number of corpus and accuracy.图8 训练集句子个数与预测正确率的关系
实验结果表明:1)2种窗口大小下,CRF++和SparkCRF预测的准确率均随着训练规模的增大而提高;2)不同窗口下,二者在相同训练集上的准确率稍有差别.窗口为3时,SparkCRF略低于CRF++的准确率,窗口为5时,SparkCRF预测的准确率稍高于CRF++,但总体上二者的预测准确率基本相同;3)窗口为3时,当训练集句子增加到8 000后,此时CRF++和SparkCRF的准确率分别为94.12%和94.14%,增加训练集包含的句子数对该测试集预测准确率的提高不明显;窗口为5时,当训练集增加到9 000条句子时,CRF++SparkCRF对应的准确率为93.73%94.04%,10 000条句子时对应的准确率为94.07%94.33%.通过分析可知,模型中包含的该测试集所需特征的比重是影响预测准确率的根本因素.
6 总 结
针对传统的运行在单节点上的条件随机场在处理大规模文本时,面临一系列挑战.本文采用“分而治之”的思想,基于ApacheSpark的大数据处理框架设计并实现了运行在集群环境下的分布式CRFs.通过对文本分析任务进行的实验,证明了SparkCRF具有高效的计算能力和较好的扩展性,并且具有与传统的单节点CRF++相同水平的准确率.
在理论上,SparkCRF能够处理大规模的数据集.由于可获得标准训练集有限,我们仅对几十兆级大小的数据集进行了测试.因此,还有待进一步在大规模数据集上对SparkCRF验证;在应用方面,利用SparkCRF工具提升文本处理的效果也是一个有待尝试的工作.例如,与知识表示[20]工作相结合,提升领域知识的抽取效果.以上两个方面也是我们未来的工作重点.
[1]LaffertyJ,McCallumA,PereiraFCN.Conditionalrandomfields:Probabilisticmodelsforsegmentingandlabelingsequencedata[C] //ProcoftheIntConfonMachineLearning.Francisco,CA:MorganKaufmann, 2001: 282-289
[2]WangYuanzhuo,JiaYantao,LiuDawei,etal.OpenWebknowledgeaidedinformationsearchanddatamining[J].JournalofComputerResearchandDevelopment, 2015, 52(2): 456-474 (inChinese)
(王元卓, 贾岩涛, 刘大伟, 等. 基于开放网络知识的信息检索与数据挖掘[J]. 计算机研究与发展, 2015, 52(2): 456-474
[3]WangYuanzhuo,JinXiaolong,ChengXueqi.Networkbigdata:Presentandfuture[J].ChineseJournalofComputers, 2013, 36(6): 1125-1138 (inChinese)
(王元卓, 靳小龙, 程学旗. 网络大数据:现状与挑战[J].计算机学报, 2013, 36(6): 1125-1138)
[4]ChengXueqi,JinXiaolong,WangYuanzhuo,etal.Surveyonbigdatasystemandanalytictechnology[J].JournalofSoftware, 2014, 25 (9): 1240-1252 (inChinese)
(程学旗, 靳小龙, 王元卓, 等. 大数据系统和分析技术综述[J]. 软件学报, 2014, 25(9): 1889-1908.)
[5]DeanJ,GhemawatS.MapReduce:Simplifieddataprocessingonlargeclusters[J].CommunicationsoftheACM, 2008, 51(1): 107-113
[6]ToshniwalA,TanejaS,ShuklaA,etal.Storm@Twitter[C] //Procofthe2014ACMSIGMODIntConfonManagementofData.NewYork:ACM, 2014: 147-156
[7]ZahariaM,ChowdhuryM,FranklinMJ,etal.Spark:Clustercomputingwithworkingsets[C] //Procofthe2ndUSENIXWorkshoponHotTopicsinCloudComputing.Berkeley,CA:USENIXAssociation, 2010: 10-10
[8]MelnikS,GubarevA,LongJJ,etal.Dremel:Interactiveanalysisofweb-scaledatasets[J].ProceedingsoftheVLDBEndowment, 2010, 3(1//2): 330-339
[9]MalewiczG,AusternMH,BikAJC,etal.Pregel:Asystemforlarge-scalegraphprocessing[C] //Procofthe2010ACMSIGMODIntConfonManagementofData.NewYork:ACM, 2010: 135-146
[10]ShaoBin,WangHaixun,LiYatao.Trinity:Adistributedgraphengineonamemorycloud[C] //Procofthe2013ACMSIGMODIntConfonManagementofData.NewYork:ACM, 2013: 505-516
[11]PhanHX,NguyenML,HoriguchiS,etal.ParalleltrainingofCRFs:Apracticalapproachtobuildlarge-scalepredictionmodelsforsequencedata[C] //ProcofIntWorkshoponParallelDataMining.Berlin:Springer, 51-63
[12]BradleyJK.Learninglarge-scaleconditionalrandomfields[D].Pittsburgh:CarnegieMellonUniversity, 2013
[13]LavergneT,CappéO,YvonF.PracticalverylargescaleCRFs[C] //Procofthe48thAnnualMeetingoftheAssociationforComputationalLinguistics.Stroudsburg,PA:ACL, 2010: 504-513
[14]ShvachkoK,KuangH,RadiaS,etal.Thehadoopdistributedfilesystem[C] //Procofthe2010IEEE26thSymponMassStorageSystemsandTechnologies.Piscataway,NJ:IEEE, 2010: 1-10
[15]ZhengShuai,JayasumanaS,Romera-ParedesB,etal.Conditionalrandomfieldsasrecurrentneuralnetworks[C] //ProcoftheIEEEIntConfonComputerVision.Piscataway,NJ:IEEE, 2015: 1529-1537
[16]LiuTao,LeiLin,ChenLuo,etal.AparalleltrainingresearchofChinesewordspart-of-speechtaggingCRFmodelbasedonMapReduce[J].ActaScientiarumNaturaliumUniversitatisPekinensis, 2013 (1): 147-152 (inChinese)
(刘滔, 雷霖, 陈荦, 等. 基于MapReduce的中文词性标注CRF模型并行化训练研究[J]. 北京大学学报: 自然科学版, 2013 (1): 147-152)
[17]WangZhaoyuan,WangHongjie,XingHuanlai,etal.AntcolonyoptimizationalgorithmbasedonSpark[J].JournalofComputerApplication, 2015, 35(10): 2777-2780, 2797(王诏远, 王宏杰, 邢焕来, 等. 基于Spark的蚁群优化算法[J]. 计算机应用, 2015, 35(10): 2777-2780, 2797)
[18]QiuHongjian,GuRong,YuanChunfeng,etal.YAFIM:AparallelfrequentitemsetminingalgorithmwithSpark[C] //Procofthe2014IEEEIntConfonParallel&DistributedProcessingSympWorkshops.Piscataway,NJ:IEEE, 2014: 1664-1671
[19]GuRong,WangShanyang,WangFangfang,etal.Cichlid:EfficientlargescaleRDFS//OWLreasoningwithSpark[C] //Procofthe2015IEEEIntConfonParallelandDistributedProcessingSymposium.Piscataway,NJ:IEEE, 2015: 700-709
[20]JiaYantao,WangYuanzhuo,LinHailun,etal.Locallyadaptivetranslationforknowledgegraphembedding[C]
//Procofthe30thAAAI’6.PaloAlto,CA:AAAI, 2016: 992-998

ZhuJizhao,bornin1986.PhDcandidate.Hismainresearchinterestsincludeopenknowledgenetwork,representationlearningandparallelcomputing.

JiaYantao,bornin1983.PhD,assistantprofessor.Hismainresearchinterestsincludeopenknowledgenetwork,socialcomputingandcombinatorialalgorithm.

XuJun,bornin1979.Professor,PhDsupervisor.Hismainresearchinterestsincludeinformationretrieval,machinelearningandbigdataanalysis.

QiaoJianzhong,bornin1964.Professor,PhDsupervisor.Hismainresearchinterestsincludeoperationsystem,parallelanddistributedcomputing.

WangYuanzhuo,bornin1978.PhD,associateprofessor.IEEEmemberandseniormemberofChinaComputerFederation.Hismainresearchinterestsincludesocialcomputing,openknowledgenetwork,networksecurityanalysis,stochasticgamemodel,etc.

ChengXueqi,bornin1971.Professor,PhDsupervisor.Hismainresearchinterestsincludenetworkscience,Websearch&datamining.
SparkCRF:AParallelImplementationofCRFsAlgorithmwithSpark
ZhuJizhao1,2,JiaYantao2,XuJun2,QiaoJianzhong1,WangYuanzhuo2,andChengXueqi2
1(College of Computer Science and Engineering, Northeastern University, Shenyang 110819)2(Key Laboratory of Network Data Science and Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190)
Conditionrandomfieldshasbeensuccessfullyappliedtovariousapplicationsintextanalysis,suchassequencelabeling,Chinesewordssegmentation,namedentityrecognition,andrelationextractioninnaturelanguageprocessing.ThetraditionalCRFstoolsinsingle-nodecomputermeetmanychallengeswhendealingwithlarge-scaletexts.Foronething,thepersonalcomputerexperiencestheperformancebottleneck;Foranother,theserverfailstotackletheanalysisefficiently.Andupgradinghardwareoftheservertopromotethecapabilityofcomputingisnotalwaysfeasibleduetothecostconstrains.Totackletheseproblems,inlightoftheideaof“divideandconquer”,wedesignandimplementSparkCRF,whichisakindofdistributedCRFsrunningonclusterenvironmentbasedonApacheSpark.WeperformthreeexperimentsusingNLPCC2015andthe2ndInternationalChineseWordSegmentationBakeoffdatasets,toevaluateSparkCRFfromtheaspectsofperformance,scalabilityandaccuracy.Resultsshowthat: 1)comparedwithCRF++,SparkCRFrunsalmost4timesfasteronourclusterinsequencelabelingtask; 2)ithasgoodscalabilitybyadjustingthenumberofworkingcores; 3)furthermore,SparkCRFhascomparableaccuracytothestate-of-the-artCRFtools,suchasCRF++inthetaskoftextanalysis.
bigdata;machinelearning;distributedcomputing;Spark;conditionrandomfields(CRFs)
乔建忠(qiaojianzhong@mail.neu.edu.cn)
2016-03-21;
2016-06-08
国家“九七三”重点基础研究发展计划基金项目(2014CB340405,2013CB329602);国家重点研发计划基金项目(2016YFB1000902);国家自然科学基金项目(61173008,61232010,61272177,61303244,61402442);北京市自然科学基金项目(4154086)
TP181
ThisworkwassupportedbytheNationalBasicResearchProgramofChina(973Program) (2014CB340405, 2013CB329602),NationlalKeyResearchandDevelopmentProgramofChina(2016YFB1000902),theNationalNaturalScienceFoundationofChina(61173008, 61232010, 61272177, 61303244, 61402442),andtheNaturalScienceFoundationofBeijing(4154086).
