多处理器系统实时任务限制抢占调度算法
2016-08-11王华忠聂永高
王华忠, 聂永高
(华东理工大学化工过程先进控制与优化教育部重点实验室,上海 200237)
多处理器系统实时任务限制抢占调度算法
王华忠,聂永高
(华东理工大学化工过程先进控制与优化教育部重点实验室,上海 200237)
针对多处理器平台完全可抢占调度(Fully Preemptive Scheduling,F-PS)可能造成低优先级任务的响应时间超出截止期限的问题,提出了两种基于固定抢占点模型的限制抢占调度算法:一种是常规延迟(Regular Deferrable Scheduling,RDS),即高优先级任务抢占正在运行的执行到最近抢占点的低优先级任务,被抢占的任务可能不具有最低优先级;另一种是自适应延迟(Adaptive Deferrable Scheduling,ADS),即高优先级任务等待正在运行的最低优先级任务执行到最近的可抢占点位置,并抢占。搭建了一个仿真实验平台,并在该平台上进行一系列的仿真实验来探究两种算法的性能表现。实验结果表明:在动态和静态优先级调度下,任务抢占次数大小顺序为F-PS > RDS > ADS;当抢占时间消耗大于临界值时,RDS和ADS的任务可调度率与F-PS接近。
多核处理器系统调度; 限制抢占调度; 常规延迟调度; 自适应延迟调度
实时系统已经广泛应用于航空航天、军事电子、进程控制、网络通信以及多媒体系统等领域[1-3]。在这些系统中,任务越来越复杂,对处理器的性能要求越来越高。长久以来,半导体厂商将研究重点放在提高时钟频率上,然而,时钟频率的提高会导致处理器能耗的急剧提升[4],限制了单核处理器性能的持续提升。为了研制高性能处理器,硬件厂商将研究重点转到在一个芯片上集成更多的处理器上,即多处理器系统。与单处理器系统相比,同等性能的情况下,多处理器系统的功耗更低。多处理器系统的发展使多处理器平台的任务调度算法的研究越来越迫切。
单处理器平台上任务调度算法的分类有很多种[5]。根据任务的优先级在执行过程中是否改变,任务调度算法可以分为静态优先级和动态优先级调度算法,例如单调期限调度算法(Deadline Monotonic,DM)[6]和最早期限优先算法(Early Deadline First,EDF)[7];根据任务是否允许延时,任务调度算法可以分为强实时调度算法(Hard real-time scheduling)和弱实时任务调度算法(Weak real-time scheduling);根据任务在执行过程中是否允许被抢占,任务调度算法可以分为可抢占调度算法(Preemptive Scheduling,PS)以及不可抢占算法(Non-Preemptive Scheduling,NPS)。
为了保证实时性,多处理器系统任务调度算法都有抢占调度机制,即高优先级任务可以抢占CPU上正在运行的低优先级任务。然而,由抢占造成的操作系统额外时间消耗增加了任务的最坏情况响应时间(Worst Case Response Time,WCRT),可能造成低优先级任务不可调度。限制抢占调度(Limited Preemptive Scheduling,LPS)是介于完全可抢占(Fully PS,F-PS)与不可抢占调度(Fully NPS,F-NPS)之间的一种调度,兼有两者的优缺点。
本文涉及的多核处理器系统限制抢占调度算法包括两种:一种是高优先级任务只抢占所有正在运行任务中最低优先级的任务;另一种是高优先级任务抢占最早可被抢占的低优先级任务,该任务优先级可能不是最低的。
与单处理器系统实时调度算法相比,多处理器系统实时调度算法不仅要考虑任务的执行策略,还要考虑任务的CPU分配问题。很多优良的单处理器实时调度算法在多处理器系统上的表现并不突出,例如“Dhall 效应”[8]。文献[9]已经证明,在单核处理器上,LPS的性能比F-PS与F-NPS优良。在多核处理器系统,文献[10]和文献[11]分别对基于固定优先级和动态优先级的LPS的性能作了仿真研究,但两者都没有考虑任务抢占的操作系统时间消耗。而本文考虑了任务抢占过程的操作系统时间消耗;对基于固定优先级的LPS和基于动态优先级的LPS的性能作了横向对比,对设计者在不同应用场景之下选择不同的多核处理器系统LPS有一定的指导作用。
1 基于固定抢占点的限制抢占调度算法
1.1概述
综合可预知性和效率考虑,F-PS与F-NPS算法各有优缺点[12]。F-PS算法在保证高优先级任务得到及时响应的同时增加了低优先级任务的WCRT。而在一些特殊场合,例如I/O读写等,由于造价问题,F-NPS占主导地位。限制抢占调度算法是一种介于F-PS与F-NPS的一种算法,同时兼顾两种算法的优缺点。
1.2固定抢占点模型
固定抢占点 (Fixed Preemptive Points,FPP)模型是文献[13]中提到的一种限制抢占模型。在FPP模型中,任务被若干FPP分为不同的不可抢占区域(Non-Preemptive Region,NPR),抢占只允许发生在FPP位置。图1为FPP模型示意图,其中任务τ被FPP分为两个不可抢占的部分τ1和τ2,即τ在执行τ1和τ2期间不允许被高优先级任务抢占。
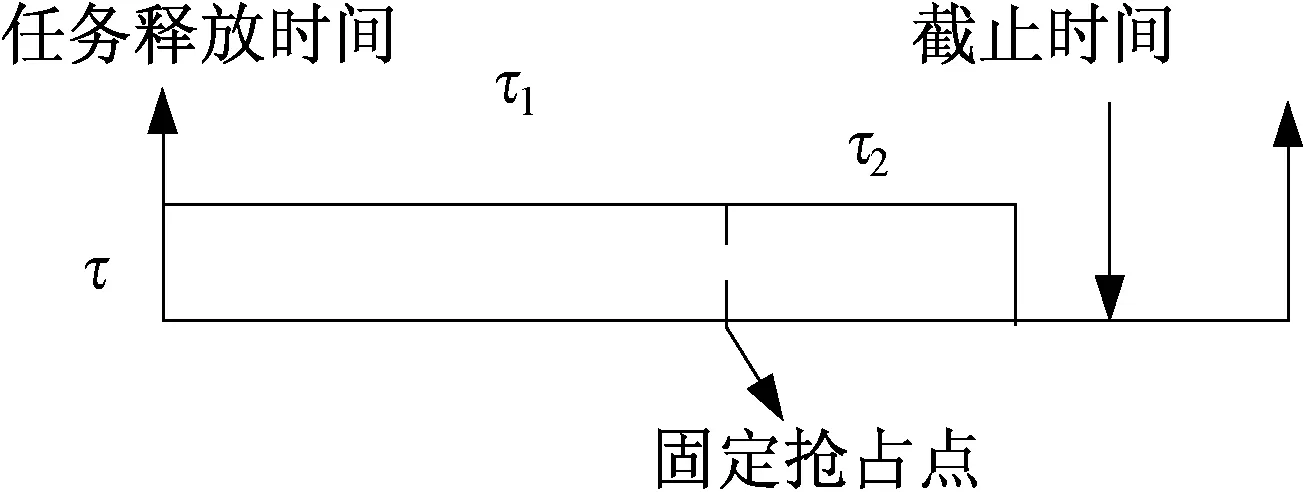
图1 固定抢占点 (FPP)模型Fig.1 Model of fixed preemptionpoint(FPP)
与F-PS相比,固定抢占点模型使高优先级任务执行延迟一段时间,延迟时间与NPR的长度有关。该延迟可能造成高优先级任务错过截止日期,从而造成任务集不可调度。同时,NPR的设置使任务集在执行过程的抢占次数减少,任务抢占过程的操作系统总时间消耗减少。当抢占过程的操作系统总时间消耗较大时,固定抢占点模型的性能将会明显提升。
不难发现,F-PS是固定抢占点模型的特殊情况,即NPR = 1。当NPR长度大于任务的可执行时间时,固定抢占点模型退化为F-NPS。
1.3两种基于固定抢占点模型的LPS
本文提出了两种基于固定抢占点模型的多处理器平台的限制抢占调度算法即常规延迟限制抢占调度(Regular Deferred Limited Preemptive Scheduling,RD-LPS)和自适应延迟限制抢调度(Adaptive Deferred Limited Preemptive Scheduling,AD-LPS)。在RD-LPS中,高优先级任务抢占最先执行到固定抢占点的任务,该任务可能不是所有正在执行中最低优先级的任务。在AD-LPS中,当高优先级任务被释放时,抢占只发生在所有正在执行任务中最低优先级任务的最近固定抢占点位置。图2和图3分别展示了RD-LPS和AD-LPS两种调度策略。任务τ1的优先级最低,τ3的优先级最高。当τ3被释放时,τ1和τ2正在执行。在RD-LPS中,τ3抢占τ2,而在ADS-LPS中,τ3抢占τ1。
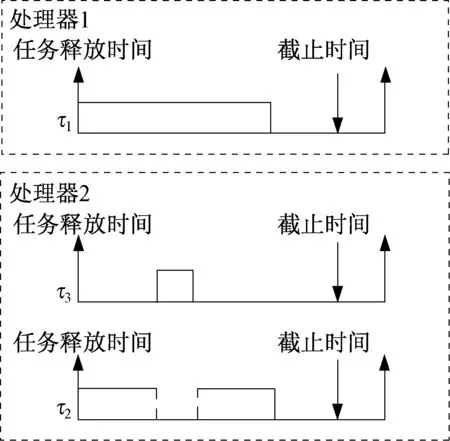
图2 一般延迟限制抢占调度(RD-LPS)Fig.2 Regular deferred limited preemptive scheduling

图3 自适应延迟限制抢占调度(AD-LPS)Fig.3 Adaptive deferred limited preemptive scheduling
1.4算法适应硬件平台
按照计算内核是否对等,多核处理器可以分为同构多核和异构多核。前者所有的计算内核地位对等,后者采用“主处理核+协处理核”的设计。目前比较主流的多核处理器各CPU核心之间的通信机制主要是基于总线共享的Cache结构和基于片上的互联结构。前者结构简单,通信速度高,但是可扩展性差;后者可扩展性好,结构复杂,软件改动较大。
本文的仿真实验中,各个处理器内核对等,采用基于总线共享的Cache结构,处理器内核共享一个任务队列。
2 实时任务模型
2.1任务模型
设有一个任务集
(1)
其中τi(1≪i≪n)为周期任务。每个周期任务τi可以用以下四元表示:
(2)
其中:Ci为任务执行所需要的时间;Ti为周期任务周期;Bm为不能被抢占区域的长度;R(i,j) 为第i个任务的第j个实例的释放时间;Di为周期任务的相对截止期限。本文假设任务集所有任务的第1个实例在t= 0 释放,R(i,j) 的计算公式如下:
(3)
2.2操作系统时间消耗
任务抢占保证了系统的实时性,但是操作系统在任务抢占过程中有一些额外消耗。文献[13]提出在每次抢占过程中,操作系统的额外时间消耗包括上下文切换、总线时间消耗等。当抢占次数过于频繁时,操作系统的额外时间消耗可能导致任务超出截止期限,即不可调度。图4中,操作系统额外时间消耗导致任务τ1的执行完成时间超出了截止期限,即该任务不可调度。

图4 抢占导致任务不可调度Fig.4 Deadline miss due to the overheads caused by preemption
3 实验设计
3.1任务生成器
任务生成器对整个仿真结果有着至关重要的作用。任务生成算法必须满足两点要求:(1)算法随机生成任务的过程是无偏(Unbiased)和理想的(Ideally);(2)可以根据特定设定值生成任务。本文采用Unifast-Discard[14]算法来生成任务。该算法可以根据预先设定的任务数量和任务总可调度利用率(Utilization)生成分布均匀的任务,满足任务生成算法的要求。
在多处理器系统中,任务可调度的必要条件是任务的总可调度利用率小于处理器的数量。
3.2仿真工具
按照任务分配不同CPU的机制,多处理器系统任务调度可分为划分调度(Partitioned Scheduling)和全局调度(Global Scheduling)[15]。本文采用全局调度机制,即所有处理器共享一个任务队列。
按照任务优先级分配机制的不同,多处理器系统任务调度可分为固定优先级调度(FPS)和动态优先级调度(DPS)。在仿真过程中,本文采用了两种经典的调度策略,即DM和EDF调度,分别代表两种调度机制。
为了评估不同调度算法之间的性能差异,搭建了一个仿真平台,包括:
(1) 任务生成器。该生成器能根据设定的任务数量和任务总可调度利用率生成任务集;
(2) 抢占调度算法,即G-P-FPS 和 G-P-DPS;
(3) 不可抢占调度算法,即G-NP-FPS;
(4)一般延迟限制抢占调度算法,即G-RD-FPS 和 G-RD-DPS;
(5) 自适应限制抢占调度算法,即G-AD-FPS 和 G-AD-DPS。
3.3实验内容
仿真工具搭建完成后,设计一些实验来评估调度算法性能的差异。通过控制变量法来验证某一因素对实验结果的影响,实验包括:
(1) 改变总可调度利用率;
(2) 改变每个任务集的任务数量;
(3) 改变系统中处理器的数目;
(4) 改变不可抢占区域的长度;
(5) 改变抢占过程中操作系统额外消耗的时间。
4 仿真实验结果
4.1实验参数
实验参数的选择对实验结果有很大影响,本文的实验参数如下:处理器数目为16;任务集数目为30;每个任务集任务数目为30;每个任务的任务实例数目为2 000;任务总可调度利用率为0.6×处理器数目;任务最小周期为[1,500];NPR长度为3;抢占过程操作系统额外时间消耗为1。
4.2任务总可调度利用率的影响
任务的总可调度利用率对任务执行过程中的抢占次数有一定的影响。实验中,将任务总可调度利用率从2增加到12,其他条件不变。图5展示了不同任务总可调度利用率下的抢占次数。可知:
(1) 抢占次数随总可调度利用率的增大而增大。因为随着任务总可调度利用率的增大,任务的执行时间变长,抢占次数变多;
(2) 动态优先级调度下的抢占次数远大于固定优先级下的调度次数。因为每个时间单元,任务的优先级发生改变,抢占次数增多;
(3) 在两种优先级调度机制下,抢占次数的大小顺序是一致的。抢占次数的大小顺序是:完全抢占调度(G-P-S)> 一般延迟限制抢占调度(G-RD-S)> 自适应延迟限制抢占调度(G-AD-S)。

图5 不同任务总可调度利用率下的抢占次数Fig.5 Numbers of preemption different task utilizations
4.3每个任务集任务数量的影响
将单个任务集的任务数量从20增加到40,图6展示了不同任务数量下的抢占次数。由图6可知:
(1) 抢占次数随单个任务集任务数量的增加而增加。因为任务数量变大,任务抢占的概率增大。
(2) 动态优先级调度下的抢占次数远大于固定优先级下的调度次数。
(3) 在两种优先级调度机制下,抢占次数的大小顺序与4.2节实验结果相同。
(4) G-P-FPS与G-RD-FPS的抢占次数比较接近。
4.4处理器数量的影响
将处理器数量从2增加到28,仿真结果如图7所示。由图7可知:
(1) 动态优先级调度下,抢占次数随处理器数目的增加而增加。静态优先调度下,随着处理器数量的增加,抢占次数先减小后增大。
(2) 动态优先级调度下的抢占次数远大于固定优先级调度下的抢占次数。
(3) 在两种优先级调度机制下,抢占次数的大小顺序与4.2节、4.3节的实验结果相同。

图6 单个任务集任务数量不同时的抢占次数Fig.6 Numbers of preemption varying the number of tasks per taskset

图7 处理器数目不同时的任务抢占次数Fig.7 Numbers of preemption varying the number of processors
4.5NPR长度的影响
不可抢占区域(NPR)的长度对LPS的表现有很大的影响,对F-P-S 和F-NP-S没有影响,仿真结果如图8所示。由图8可知:
(1) 随着NPR长度的增加,抢占次数减少。当NPR长度增加时,任务的可抢占点变少,发生抢占的概率变低,次数变少。
(2) 当NPR长度比较小时,动态优先级调度下的抢占次数远大于固定优先级调度。随着NPR长度的增加,差距减小。当NPR长度较大时,任务的执行时间与NPR长度相近,动态优先级调度退化为静态优先级调度,两者的抢占次数接近。
(3) 两种优先级调度机制的抢占次数大小顺序一致。
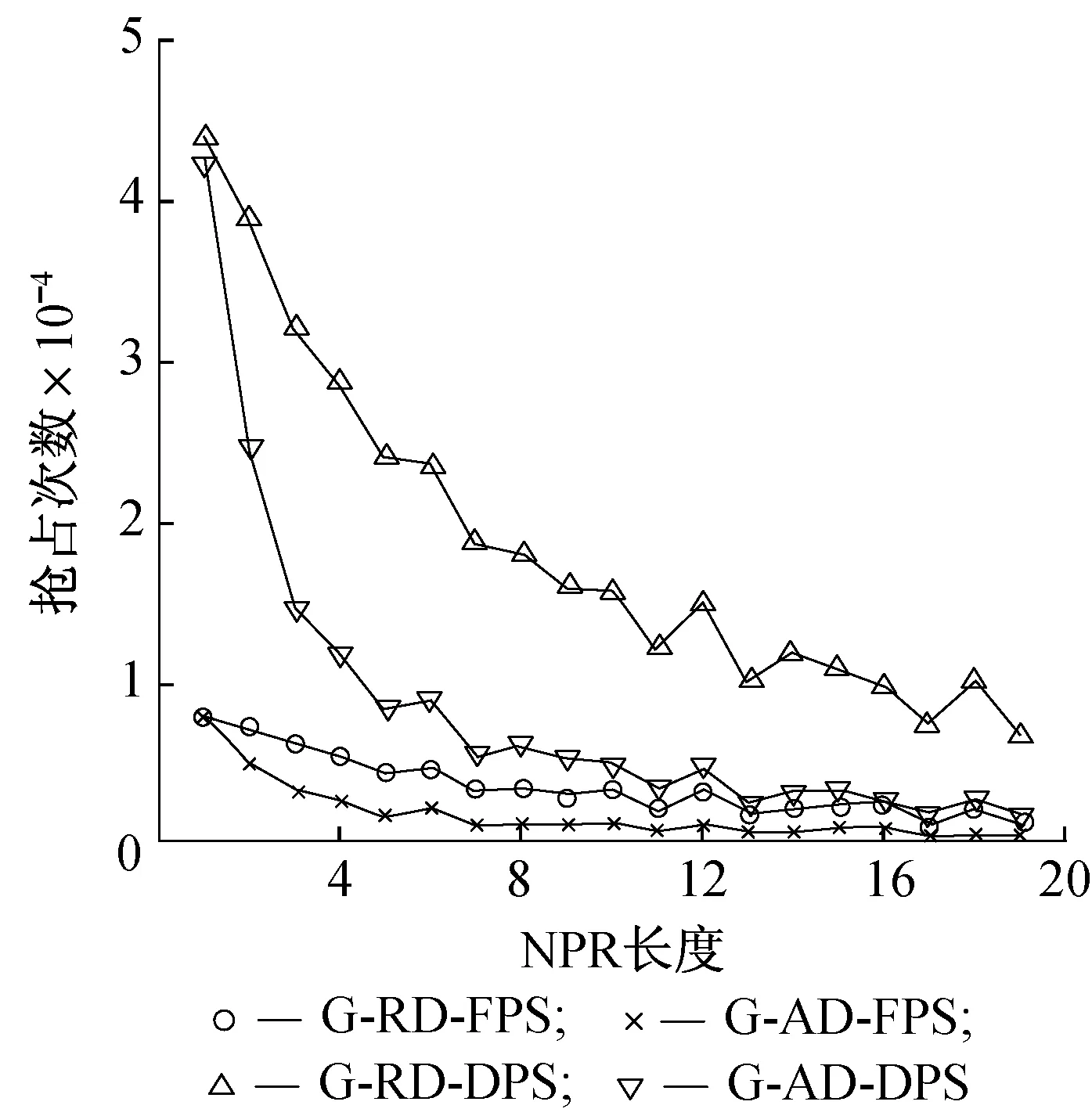
图8 NPR长度不同时的任务抢占次数Fig.8 Numbers of preemption varing the length of NPR
4.6抢占过程操作系统额外时间消耗的影响
在每次抢占过程中,操作系统会有一些额外的时间消耗,影响调度算法的表现。图9和图10分别示出了随着操作系统额外时间消耗的增大,任务在动态优先级和静态优先级调度的可调度率。由图9和图10知:
(1) 随着抢占消耗时间的增加,可抢占的调度算法的任务可调度率快速降低,当时间消耗数值大于6时,抢占调度的任务可调度率低于不可抢占调度;当数值大于19时,抢占调度的可调度率接近0。
(2) 额外时间消耗的增加对G-P-DPS的影响程度最大,因为在该调度中,抢占次数最多。当时间消耗大于某个值时,可抢占调度与限制抢占调度的可调度率接近。
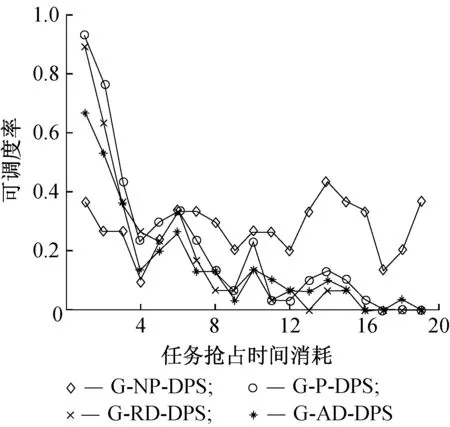
图9 动态优先级调度下抢占时间不同时的可调度率Fig.9 Schedulable ration of tasksets varying the overheads under dynamic priority scheduling

图10 静态优先级调度下抢占时间不同时的可调度率Fig.10 Schedulable ration of tasksets varying the overheads under static priority scheduling
5 结论和展望
综合在仿真平台上实施一系列的仿真实验结果,不难发现,在多处理器平台上:
(1) 动态优先级调度的抢占次数远大于静态优先级调度的抢占次数;在每次抢占过程中,操作系统都有一定的时间消耗。操作系统的时间消耗增大时,动态优先级调度的性能明显下降。当时间消耗达到一定程度时,动态优先级调度的性能比静态优先级调度差。
(2) 抢占次数的大小顺序为G-P-DPS > G-RD-DPS > G-AD-DPS > G-P-FPS > G-RD-FPS > G-AD-FPS。
(3) 抢占调度的任务可调度率随抢占时间消耗的增大而降低。当时间消耗大于某个值时,抢占调度的任务可调度率低于不可抢占调度。
本文仍有一些局限之处:首先,由于实验条件的限制,本文的限制抢占调度算法的性能未能在实际多核处理器平台上验证;其次,本文仿真产生的任务为周期性任务,多核平台的限制抢占调度算法对非周期性任务的性能表现是否与周期性任务相似尚未得到验证。
[1]王涛.实时系统任务调度若干关键技术的研究[D].哈尔滨:哈尔滨工程大学,2006.
[2]宾雪莲.实时系统中的任务调度技术研究[D].长沙:国防科学技术大学,2004.
[3]彭浩,韩江洪,陆阳,等.多处理器硬实时系统的抢占阈值调度研究[J].计算机研究与发展,2015,52(5):1177-1186.
[4]ANSARI K H,CHITRA P.Power-aware scheduling of fixed priority tasks in soft real-time multicore systems[C]//2013 IEEE International Conference on Emerging Trends in Computing,Communication and Nano Technology.USA:IEEE,2013:496-502.
[5]LI Jie.The research of scheduling algorithms in real-time system[C]//2010 International Conference on Computer and Communication Technologies in Agriculture Engineering.USA:IEEE,2010:333-336.
[6]LEUNG J,WHITEHEAD J.On the complexity of fixed priority scheduling of periodic real-time tasks[J].Performance Evaluation,1982:2(4):237 -250.
[7]LIU C L,LAYLAND J.Scheduling algorithms for multiprogramming in a hard real-time systems[J].Journal of the ACM,1973,20(1):46-61.
[8]DHALL S K,LIU C L.On a real-time scheduling problem[J].Operations Research,1978,26:127-140.
[9]MARINHO J,NELIS V.Limited preemptive global fixed task priority[C]//2013 IEEE 34th Real-Time Systems Symposium.Canada:IEEE,2013:182-191.
[10]NIE YONGGAO,THEKKILAKATTIL A.Limited preemptive fixed priority scheduling of real-time tasks on multi-processors[D].Sweden:Malardalen University,2015.
[11]ZHU Kaiqian,THEKKILAKATTIL A.Limited preemptive early deadline first scheduling of real-time tasks on multi-processors[D].Sweden:Malardalen University,2015.
[12]GRENIER M,NAVET N.Fine-tuning MAC-level protocols for optimized real-time QoS[J].IEEE Transactions on Industrial Informatics,2008,4(1):6-15.
[13]BUTTAZZ G C,BERTOGNA M,YAO Gang.Limited preemptive scheduling for real-time systems[J].IEEE Transactions on Industrial Informatics,2013,9(1):3-15.
[14]DAVIS R,BURNS A.Priority assignment for global fixed priority pre-emptive scheduling in multiprocessor real-time systems[C]//30th IEEE Real-Time Systems Symposium.Washington,DC:IEEE,2010:398-409.
[15]LAUZAC S,MELHEM R,MOSS′E D.Comparison of global and partitioning schemes for scheduling rate monotonic tasks on a multiprocessor[C]//10th Euromicro Workshop on Real-Time Systems.Berlin:IEEE,1998:188-195.
Real-Time Task Limited Preemptive Scheduling on Multi-processors
WANG Hua-zhong,NIE Yong-gao
(Key Laboratory of Advanced Control and Optimization for Chemical Process,Ministry of Education,East China University of Science and Technology,Shanghai 200237,China)
In multi-processors scheduling,fully preemptive scheduling (F-PS) may result in the tasks with lower priority beyond the deadline.In this work,two limited preemptive scheduling (LPS) algorithms are proposed to solve the above problem.The first one is regular deferrable scheduling (RDS),in which the tasks with higher priority preempt the first among the lower priority tasks that finish executing a non-preemptive region.The other is adaptive deferrable scheduling (ADS),where the scheduler waits to preempt the lowest priority running task.A series of experiments are carried out via the built simulator to investigate the performance of the two LPS,which show:(1) the number of preemptions in dynamic and static scheduling is F-PS > RDS >ADS;(2) the schedulable ratios of RDS and ADS are almost equal to the one of F-PS when the time consuming in preemptions is bigger that the threshold.
multi-processors scheduling; limited preemptive scheduling; regular deferrable scheduling; adaptive deferrable scheduling
A
1006-3080(2016)03-0393-06
10.14135/j.cnki.1006-3080.2016.03.016
2015-09-25
王华忠(1969-),男,江苏南京人,副教授,博士,从事工业过程模型化与控制的研究。
TP316
