基于更新样本智能识别算法的自适应集成建模
2016-08-11汤健柴天佑刘卓余文周晓杰
汤健 柴天佑 刘卓 余文 周晓杰
基于更新样本智能识别算法的自适应集成建模
汤健1,2柴天佑2刘卓2余文3周晓杰2
选择表征建模对象特性漂移的新样本对软测量模型进行自适应更新,能够降低模型复杂度和运行消耗,提高模型可解释性和预测精度.针对新样本近似线性依靠程度(Approximate linear dependence,ALD)和预测误差(Prediction error,PE)等指标只能片面反映建模对象的漂移程度,领域专家结合具体工业过程需要依据上述指标和自身积累经验进行更新样本的有效识别等问题,本文提出了基于更新样本智能识别算法的自适应集成建模策略.首先,基于历史数据离线建立基于改进随机向量泛函连接网络(Improved random vector functional-link networks,IRVFL)的选择性集成模型;然后,基于集成子模型对新样本进行预测输出后采用在线自适应加权算法(On-line adaptive weighting fusion,OLAWF)对集成子模型权重进行更新,实现在线测量阶段对建模对象特性变化的动态自适应;接着基于领域专家知识构建模糊推理模型对新样本相对ALD (Relative ALD,RALD)值和相对PE(Relative PE,RPE)值进行融合,实现更新样本智能识别,构建新的建模样本库;最后实现集成模型的在线自适应更新.采用合成数据仿真验证了所提算法的合理性和有效性.
集成学习,更新样本识别,模糊推理,近似线性依靠,预测误差
引用格式汤健,柴天佑,刘卓,余文,周晓杰.基于更新样本智能识别算法的自适应集成建模.自动化学报,2016,42(7): 1040-1052
工业过程对象受原料属性、产品质量和产量及环境气候等因素的影响而具有动态特性,这些动态变化通常包括传感器漂移和过程漂移,在机器学习领域将其统称为概念漂移[1].基于历史数据构建的软测量模型难以适应这些变化,导致预测性能下降.处理概念漂移的自适应机理包括样本选择(如滑动窗口)、样本加权(如递推更新)和在线集成学习(如子模型权重自适应、子模型参数自适应、子模型增加或删减)[2].集成学习模型的更新包括基于样本和基于批两种方式,其中基于批的在线集成更新方式的较长更新时间周期常导致更新模型难以反映当前状态,基于样本的在线集成更新方式则可以快速适应过程对象变化.本文的研究基于后一种更新策略.
采用每个新样本均进行模型更新并不符合工业实际情况.为选择能够代表过程对象概念漂移的新样本进行模型更新,已有策略包括[3]:基于主元分析(Principal component analysis,PCA)模型的平方预测误差(Square prediction error,SPE)和Hotellin′T2指标[4]、基于核特征空间近似线性依靠(Approximate linear dependence,ALD)条件[5[7]以及基于建模样本原始空间ALD条件[8-9].但是,基于PCA监控指标的方法因不设定更新阈值难以有效控制模型更新次数、基于PEB仅考虑了模型预测性能、采用ALD条件虽通过设定阈值有效控制了模型更新次数却未考虑模型预测性能的变化.
针对具体工业实践,领域专家通常综合考虑过程特性变化和软测量模型预测性能等指标,依据自身经验知识决策是否有必要进行软测量模型更新.因此,如何有效地结合领域专家知识,融合ALD值和模型预测误差(Prediction error,PE)所代表的具有不同视角的概念漂移程度,即基于领域专家的经验和知识获取模糊规则,对是否对软测量模型进行更新采用智能化识别是本文的关注焦点.
研究表明,集成学习算法具有较好的概念漂移处理能力.文献[10]给出了基于加权集成的集成模型自适应系统的结构.汤健等提出了基于OLKPLS (On-line kernel partial least squares)算法更新回归子模型和在线自适应加权融合(On-line adaptive weighting fusion,OLAWF)算法更新子模型加权系数的磨机负荷参数在线软测量方法[9].上述两种方法未对集成模型结构进行更新,难以有效地适应概念漂移.
文献[11]提出应用于分类问题的选择性负相关学习算法;文献[12]给出预设定集成尺寸和权重更新速率的自适应集成模型;文献[13]提出基于改进Adaboost.RT算法的集成模型;文献[14]提出能够随识别目标复杂程度自适应变化的分类器动态选择与循环集成方法,并可调整模型参数实现集成模型精度和效率的折衷;文献[15]指出面向回归问题的在线集成算法较少,并提出了基于样本更新的动态在线集成回归算法.面向高维小样本数据,上述方法难以建立学习速度快、性能稳定的在线集成模型.
选择适合的子模型构建方法对集成模型的快速更新极为重要.误差逆传播神经网络(Back propagation neural network,BPNN)被过拟合、训练时间长等问题所困扰.面对小样本数据时,BPNN难以建立稳定性较高的预测模型.基于结构风险最小化的支持向量机(Support vector machine,SVM)建模方法适用于小样本数据建模,需要花费较多时间求解最优解,难以采用重新训练方式实现模型快速更新,其在线递推模型是以次优解替代最优解.随机向量泛函连接网络(Random vector functional link,RVFL)求解速度快[16-18],但在面向小样本数据建模时同样存在预测性能不稳定的问题,并且难以直接用于高维数据建模.理论上,基于RVFL的集成模型具有更好的建模可靠性[19-20].在隐含层映射关系未知的情况下,将SVM中的核技术引入RVFL构建改进的RVFL(Improved RVFL,IRVFL)模型可有效克服上述问题[21].
RVFL作为一种单隐层的人工神经网络模型,难以直接采用高维数据建模.维数约简是首先需要面对的问题[22],解决方法主要是特征选择[23-24]和特征提取[25-26]技术.特征选择方法主要是选择与函数分类或估计目标关系密切的部分变量实现约简;丢弃的部分特征可能会降低估计模型的泛化能力.特征提取是采用线性或非线性的方式确定适当的低维空间取代原始高维空间,无需丢弃部分特征变量,避免了特征选择技术丢弃部分特征引起的缺陷.基于偏最小二乘(Partial least squares,PLS)的特征提取方法[27]克服了PCA提取的潜在特征只关注输入数据、并非能有效用于函数估计问题的缺点;并且,PLS递推算法较为容易实现[28].显然,针对RVFL难以有效解决高维共线性数据的直接建模问题,将其结合基于PLS的特征提取是较佳的解决方案之一.
综上,本文提出了基于更新样本智能识别的在线集成建模方法.该方法首先提出一种采用模糊规则融合新样本的相对ALD(Relative ALD,RALD)值和相对PE(Relative PE,RPE)值的智能更新样本识别算法,然后采用改进的递推PLS(Recursive,RPLS)对潜在特征进行递推更新,最后重新训练并优化选择具有快速学习能力的IRVFL集成子模型,在线测量过程中基于OLAWF算法进行权重系数动态更新.
1 更新样本识别概述
离线构建的非线性模型f(·)不能代表具有时变特性的工业过程的当前工况.工业过程模型在时刻mn的输入输出关系采用下式表示.
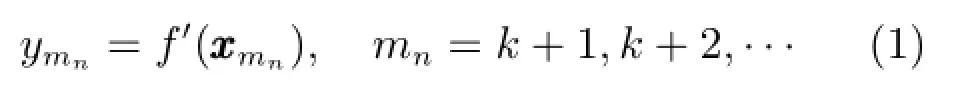
正常工况下运行的工业过程多是慢时变的,多数新样本可能并没有包含明显的时变信息.每次新样本出现时,采用每个新样本进行模型更新不但耗时而且没有必要.显然,识别能够代表过程对象概念漂移的新样本进行离线模型的自适应更新对简化模型结构、降低运算消耗和提高模型预测性能很有必要.
下文描述文献中常用方法[3].
1.1基于PCA的方法
基于PCA的过程监视方法在化工、半导体制造等具有时变特性的工业过程得到成功应用.利用建立离线模型f(·)的训练数据构建PCA模型.将标定后的新样本分为两部分:

计算新样本的SPE和Hotelling′s T2[29]:

通常,SPE用于度量新样本在残差子空间上的投影,表示新样本偏离模型的程度;T2度量新样本在主元子空间上的变化,表示新样本在模型内部的偏离程度.如果SPE和T2满足如下条件,不进行模型更新[4]:
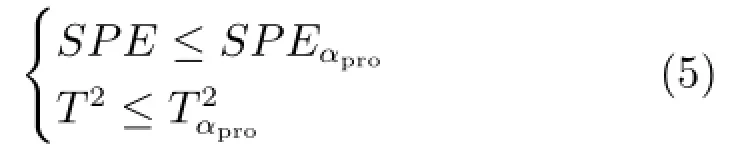
其中,SPEαpro和表示SPE和T2的控制限,其定义详见文献[24].
1.2基于ALD的方法
相对于建模样本,工业过程中采集的新样本通常存在突变和缓变两种变化.文献[5,8]提出利用新样本和建模样本间的ALD值描述这种变化,其定义如下:■■
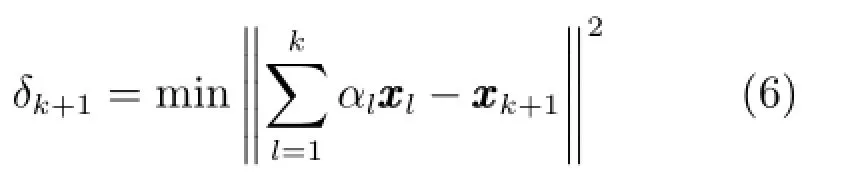
在线建模过程中,通常比较关注建模精度和建模速度,它们是两个相互冲突的优化目标.实际应用中,不同工业系统对建模精度与速度的侧重程度不同,阈值的选择策略也不同:1)侧重于建模精度时选择较小阈值,极限情况是v=0,即每个新样本均参与更新;2)侧重于建模速度时选择较大阈值,极限情况是v=vlim,即没有新样本参与模型更新;3)若需要在建模精度和速度间进行均衡,阈值选择可表述为如下单目标优化问题[9]:
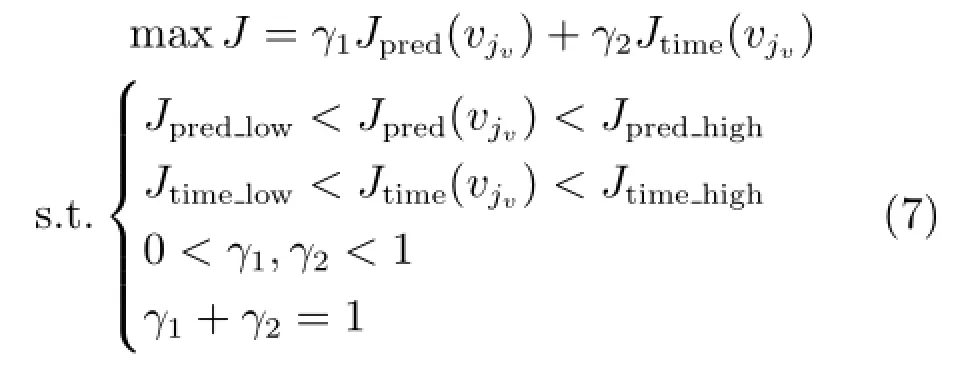
其中,Jpred(vjv)和Jtime(vjv)是采用阈值时的建模精度和速度和和是工业过程可以接受的建模精度、建模速度的下限和上限和是在建模精度和建模速度间进行均衡的加权系数.
通常,最佳阈值需要依据使用者经验和特定领域问题的背景进行选择.
1.3基于PE的方法
文献[7]基于模型选择性稀疏策略基本思想(即当过程的实际测量值能被模型准确估计时,表明当前模型是准确的,不必进行模型更新;当预测误差超过一定范围时进行模型更新),提出了基于预测误差限(PE bound,PEB)的更新样本识别算法;提出通过有效地与领域专家的先验知识相结合,选择适合的PEB值可避开完全黑箱数据模型的弊端.
当PEB满足如下条件时,不进行模型更新:
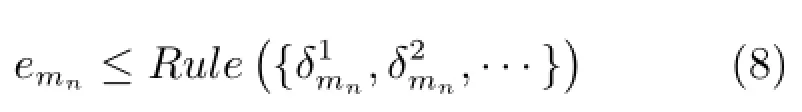

该方法依据实际需要预先定义多个δmn阈值和相应规则对更新样本进行识别.
1.4更新方法小结
由以上表述可知:1)基于PCA模型识别更新样本的方法不设定更新阈值,难以有效控制模型更新次数,预测模型精度与更新速度间的均衡较难控制;2)采用ALD条件在建模样本的核特征空间和原始空间中判断新样本与建模样本库的线性独立关系的方法,虽然通过设定阈值可有效控制模型更新次数,但对模型预测性能的变化未予以考虑;3)基于PEB的方法考虑模型预测性能,难以准确涵盖过程特性漂移,而且对于某些难以在短时间内获得预测变量真值的复杂工业过程不能实现更新样本的识别.实际上,复杂工业过程的时变特性(概念漂移)的影响不仅体现在当前单个新样本相对于建模样本的变化(ALD值)和相对于旧模型预测精度的变化(PE值),还表现为某段时间内ALD值和PE值的累计变化.
如何依据这些变化进行模型更新与否的识别决策往往需要领域专家根据不同工业现场的实际情况而定,即基于专家知识进行智能决策.因此,如何有效地结合领域专家知识,融合ALD阈值和模型PE值,即基于领域专家的经验和知识获取模糊规则,综合考虑新样本相对复杂过程的变化和预测输出的波动范围,研究智能化更新样本识别方法是值得关注的研究热点之一.
2 基于更新样本智能识别的自适应集成建模策略及其实现
通常工业过程都是在完成当前时刻软测量的一段时间后才能获得该时刻对应的真值,其滞后时间的长短随工业过程的不同而具有差异性.也就是说,我们首先基于旧模型进行在线测量,然后依据采用离线化验等其他手段得到的真值对模型进行在线更新,为下一时刻的软测量服务,即分为在线测量和在线更新两个阶段.
本文提出基于智能更新样本识别算法的在线集成建模策略,由离线建模、在线测量和在线更新模块三部分组成,如图1所示.其中,离线建模由数据预处理、潜在特征提取、候选子模型构建、集成子模型选择与合并等组成;在线测量模块由在线数据预处理、在线潜在特征提取、在线集成子模型预测、在线子模型权系数更新及在线合并子模型输出等部分组成;在线更新模块包括数据递推预处理、智能更新识别、潜变量特征递推更新、集成子模型更新、非更新特征及集成子模型赋值等组成部分.
该方法不同于其他在线集成模型方法,集成子模型加权系数的更新是在在线测量阶段通过OLAWF算法完成的,能够更好地适应工业过程的动态变化.
2.1离线建模模块
此处采用文献[21]提出的基于潜变量特征的选择性集成IRVFL的建模策略构建离线软测量模型,主要包括潜变量特征提取、子模型构建、子模型选择和子模型合并4个模块,如图2所示.
由图2可知,共有4个学习参数需要选择:潜变量特征个数h、候选子模型数量J、IRVFL算法的核参数和惩罚参数CRVFL.建立离线选择性集成模型的过程可表述为求解如下优化问题:

图1 建模策略图Fig.1 The proposed modeling strategy
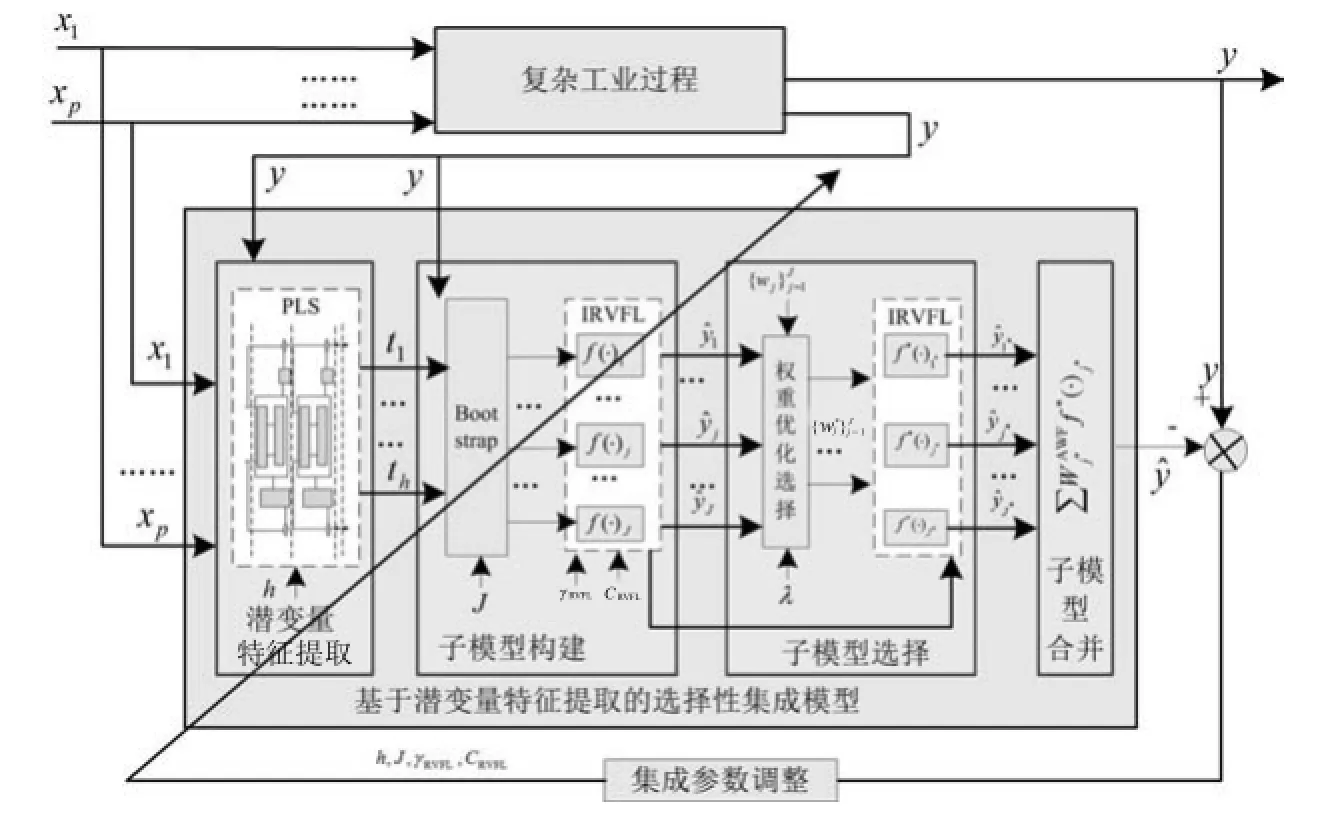
图2 基于潜变量特征的选择性集成IRVFL离线软测量模型建模策略Fig.2 Selective ensemble IRVFL off-line soft sensor model based on latent variable features

其中,JRMSRE表示选择性集成模型的均方根相对误差(Root mean square relative error,RMSRE);kvalid表示验证样本集的数量;OpSel(·)表示集成子模型的优化选择方法;J∗表示优选的集成子模型的数量表示优选的集成子模型的加权系数.
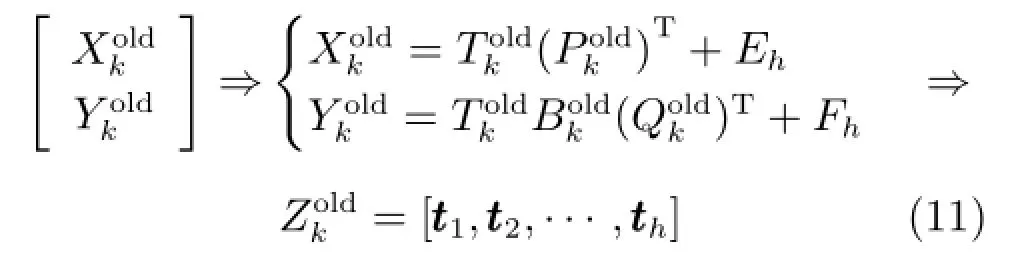
分别表示由训练数据分解得到的得分矩阵、输入数据负荷矩阵、输出数据负荷矩阵和PLS内部模型的系数矩阵.采用Bootstrap算法基于提取的潜在特征矩阵产生的训练子集,即
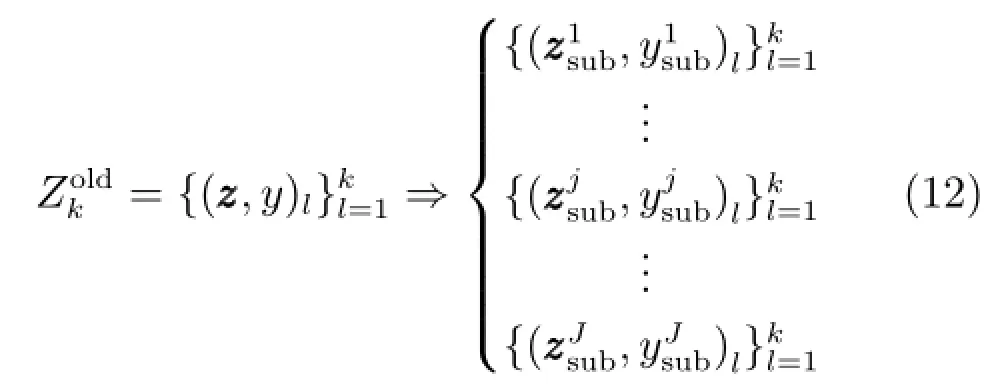
其中,J是训练子集的数量,即候选子模型的数量.采用核矩阵替代RVFL的隐含层特征映射RVFL算法针对第j个候选子模型的输出可表示为
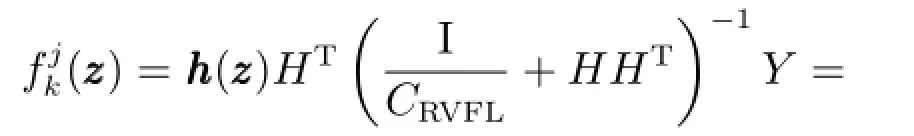

其中,H是RVFL的隐含层矩阵.
从构建的J个候选子模型选择J∗个集成子模型的过程可表示为
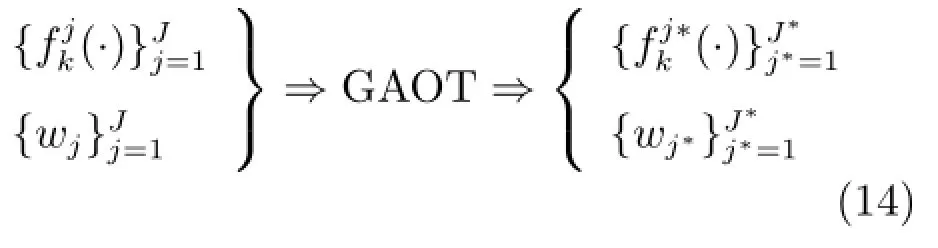
由以上离线建模过程可知,本文建立的选择集成模型采用“采集训练样本”的方式产生训练子集并构建选择性集成模型,并非工业工程常用多模型建模策略所采用的“聚类算法获得代表不同工况的训练样本构建集成子模型再集成的策略”;此外,本文采用SVM核矩阵替代RVFL的隐含层映射,输入权重的随机性得到抑制.因此,对集成模型的学习参数进行更新是必要的.另外,无论采用何种方式产生训练子集,只要过程对象漂移产生的新工况在建模样本覆盖范围之外,都有必要对集成模型的结构和参数同时进行更新.
2.2在线测量模块
在线数据预处理时,新样本采用旧均值和方差进行标定
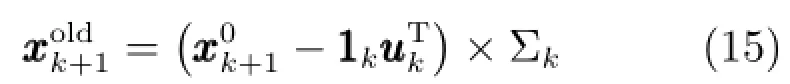
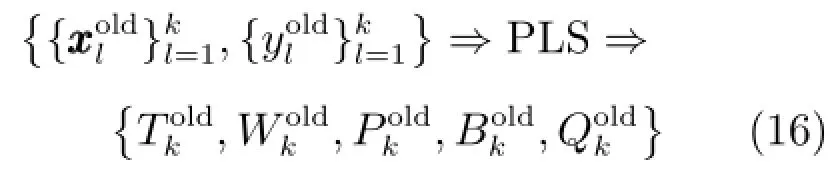
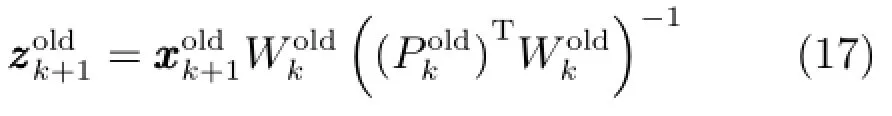
新样本基于第j个旧集成子模型的预测输出
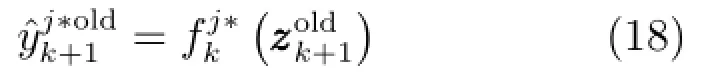
采用在线AWF算法计算集成子模型权系数[3]
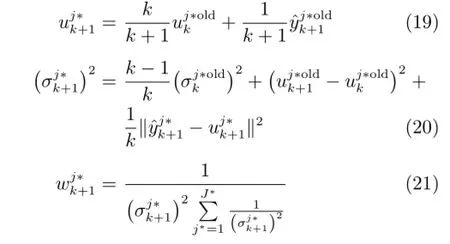
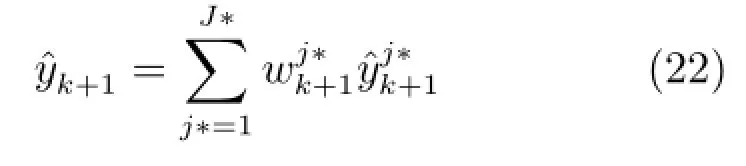
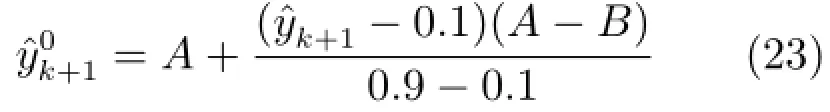
2.3在线更新模块
通常,获得k+1时刻真值后进行模型更新,因而在k+1时刻更新的模型只能在k+2时刻进行基于软测量模型的在线测量输出.
2.3.1数据递推预处理
在线数据预处理需考虑新样本对旧建模样本的均值和方差的影响.首先对旧建模样本的均值和方差进行递推更新
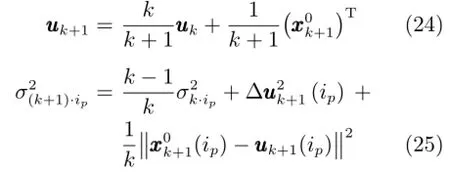
新样本标定的递推形式为
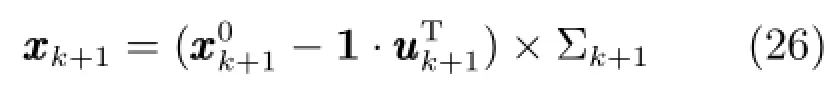
2.3.2更新样本智能识别更新样本智能识别中同时考虑新样本ALD值和PE值的影响.基于领域专家知识总结规则,建立基于Mamdani模糊推理系统的智能模型对ALD值和PE值进行融合输出.采用文献[8]的方法计算相对于建模样本库的ALD绝对值
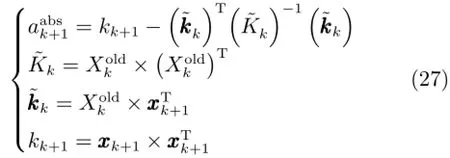
计算新样本的相对ALD(RALD)值ak+1:
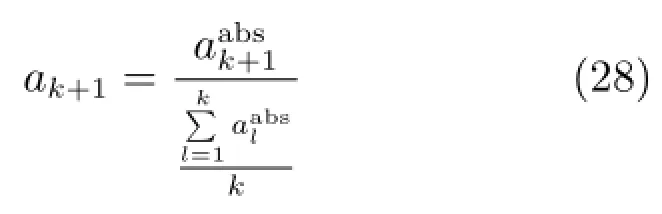
上述过程可采用如下公式表示:
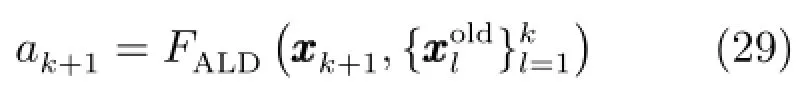
考虑k+1时刻PE值的影响,定义相对预测误差(RPE)如下:
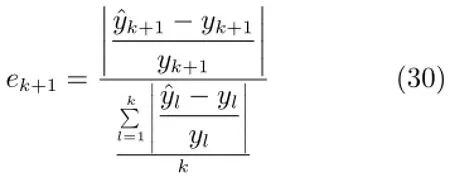
此处将融合新样本RPE和RALD值建立的更新样本智能识别算法记为Fcom(·),并将智能识别算法的输出称为模糊融合值,记为usk+1,用下式表示:
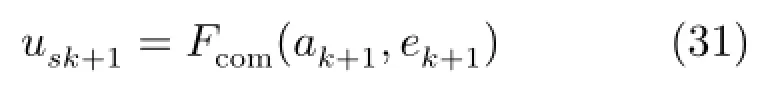
采用基于专家经验总结的模糊推理规则实现对RALD值和RPE值的融合输出,参考PID控制器设计的比例—积分控制律,总结如表1所示49条专家规则.
表1中,RALD、RPE和Us分别表示新样本面对旧建模样本库的相对近似线性依靠值、新样本基于旧模型的相对预测误差值和模糊融合值.

表1 更新样本模糊推理规则Table 1 Fuzzy inference rulers of the updating sample
采用重心法对Us进行去模糊处理.将样本选择阈值记为θcom,阈值函数Fthre(·)可记为
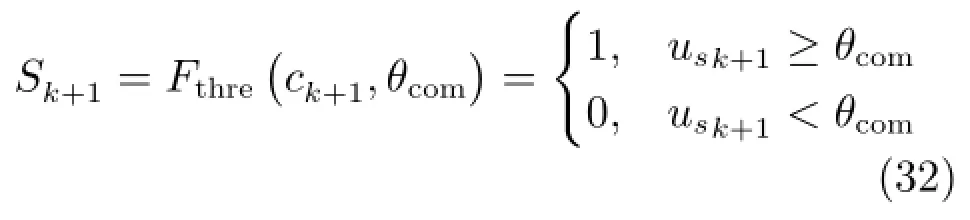
其中,Sk+1=1表示识别该新样本为更新样本.
2.3.3潜变量特征递推更新
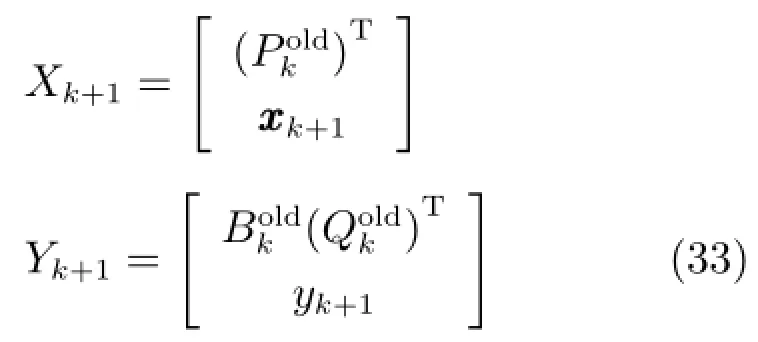
基于以上输入输出数据建立新PLS模型
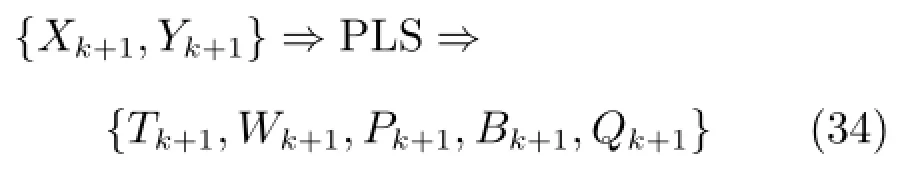
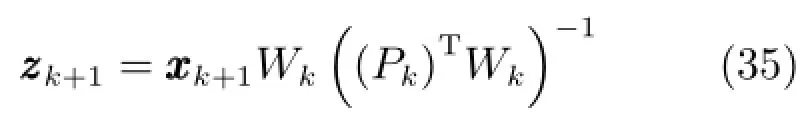
2.3.4集成子模型更新
确定采用子模型更新时,建模样本集为
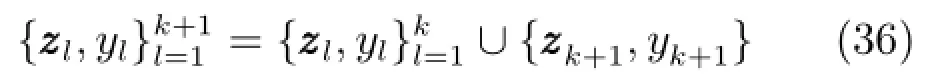
因IRVFL算法具有较快的学习速度,此处采用新建模样本库重新训练方式进行集成模型更新.更新后的集成子模型对训练样本的输出为
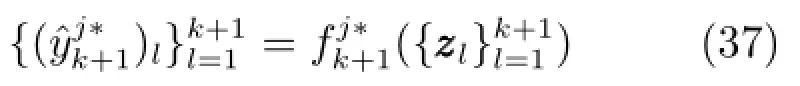
为保证采集到第(k+2)个新样本时在线测量模块可以正常运行,需更新的变量及模型包括:建模样本的均值 uuuk+1和标准差Σk+1,潜变量特征提取模型的Bk,Qk,Pk+1和Wk+1,集成子模型集成子模型预测值的均值和方差按如下公式进行赋值:

3 仿真验证
采用如下函数生成仿真数据模拟工业过程的非线性和时变特性:
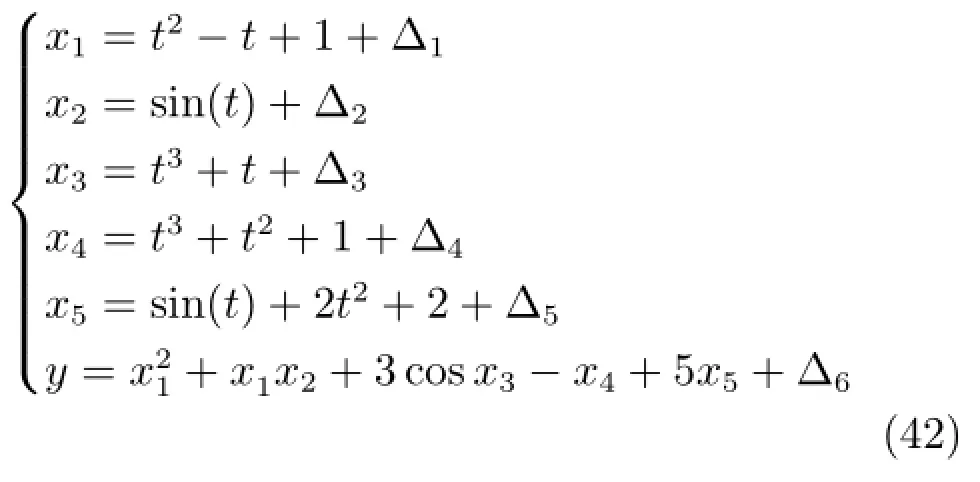
仿真合成数据分布在C1、C2、C3和C4共4个不同区域.训练样本数量由分别来自C1、C2和C3区域的各30个样本组成.测试样本由C1、C2 和C3区域的各30个样本以及C4区域的90个样本组成.
3.1离线模型结果
基于90个训练样本,采用PLS进行特征提取,不同LV的方差贡献率如表2所示.
表2表明,前3个LVs分别描述了X-Block和Y-Block方差变化率的99.73%和99.51%.不同模型学习参数(核半径、惩罚参数、候选子模型数量、潜变量数量)与均方根预测相对误差(RMSRE)间的关系如图3所示.
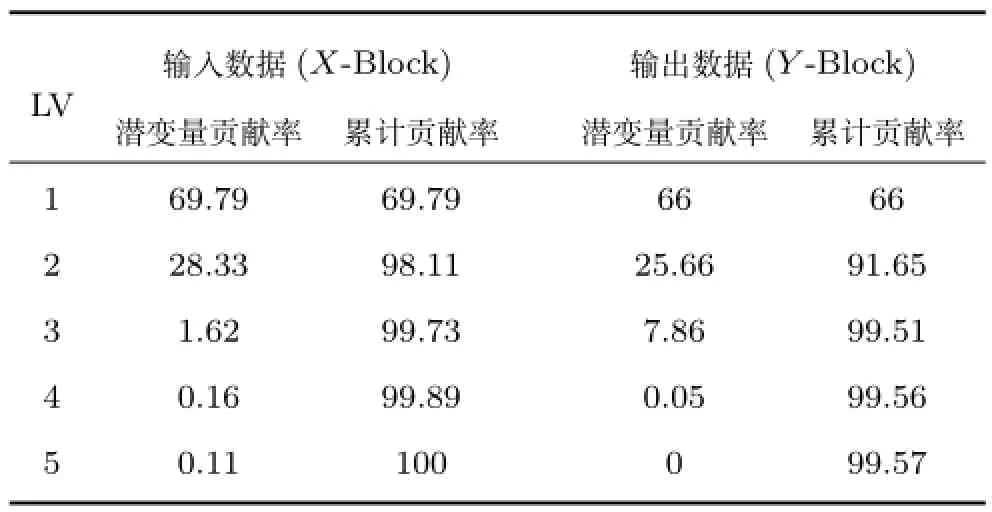
表2 仿真数据的方差贡献率(%)Table 2 Percent variance contribution of the simulation data(%)
依据图3进行建模参数选择.为便于比较,将RALD值和RPE值采用极差法标定在-3与+3之间,测试样本相对于初始建模样本的RALD值、RPE值及模糊融合值如图4所示.
由图4可知,后90个测试样本相对于建模样本的变化高于前90个测试样本,主要原因是后90个样本代表的新的概念漂移未能被初始建模样本所覆盖;以阈值0为界限,由位于阈值线上方的样本分布可知,所提更新样本识别算法可有效地融合RALD值和RPE值.由上可知,进行集成模型的在线更新非常必要.
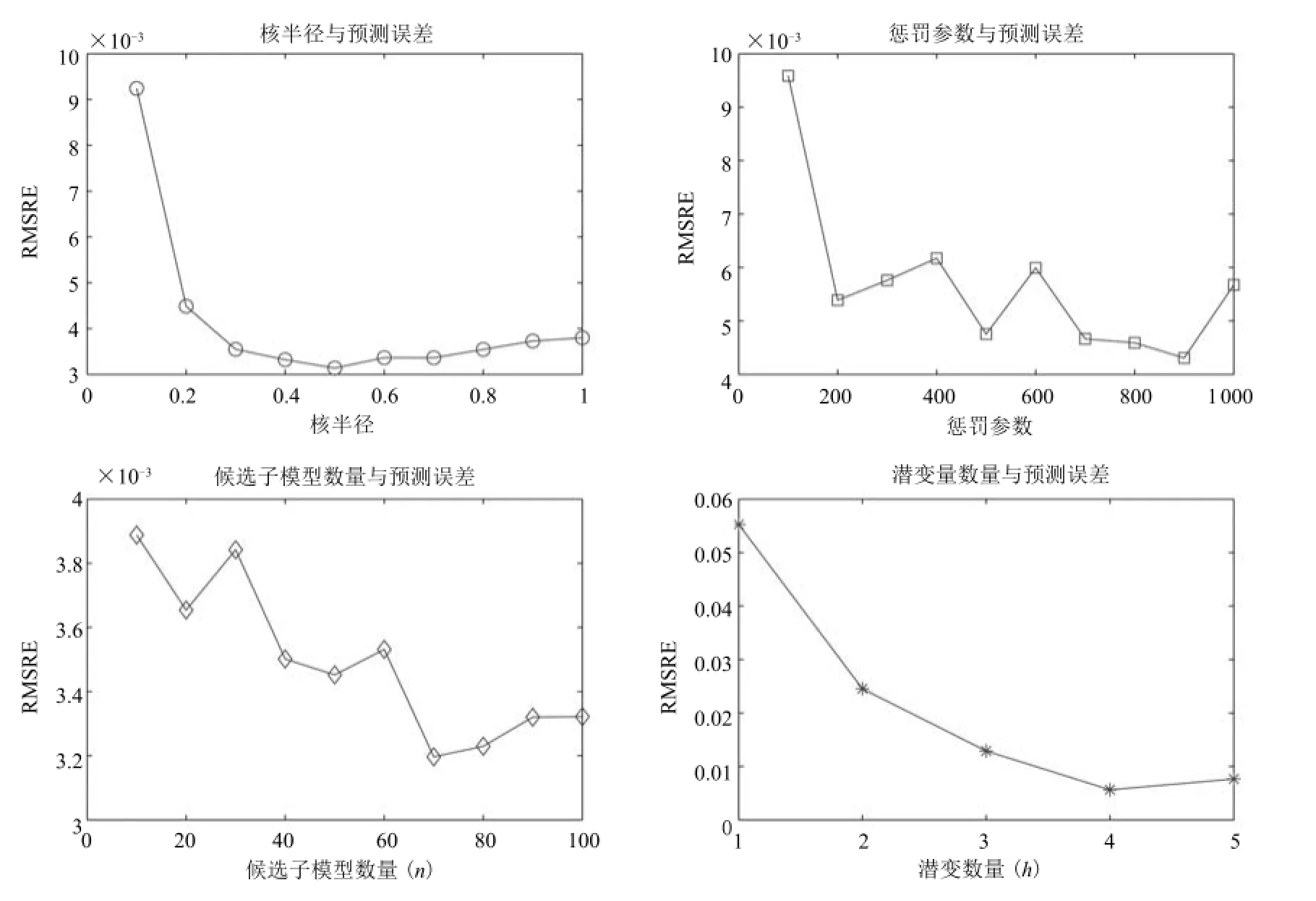
图3 离线模型学习参数与预测误差Fig.3 Learning parameters and prediction errors of the off-line model
3.2在线模型结果
模糊融合阈值θcom的大小决定了模型更新次数的多少,较大的阈值代表更多的样本参与更新.本文将阈值的取值范围定为-3~+3之间.当θcom= -1.5时,测试样本相对于在线更新模型建模样本的RALD值、在线更新模型的RPE值、对两者融合的模糊融合值及在线更新模型的测试曲线,如图5所示.表3给出了离线模型,基于RALD值、RPE值和模糊融合值的在线更新模型重复20次的统计结果.
图5和表3表明:
1)从更新最多的样本编号上看,本文方法选择的样本基本上覆盖了RALD和RPE方法选择的样本,如依据RALD方法未选择的第93和97个样本、依据RPE方法未选择的第99和106个样本在本文所提模糊融合方法中均进行了选择,表明该方法可以有效地融合RALD和RPE方法中独立存在的片面信息.
2)在模型预测性能上,不同更新阈值时的不同更新方法的最大、最小和平均预测误差如图6所示.
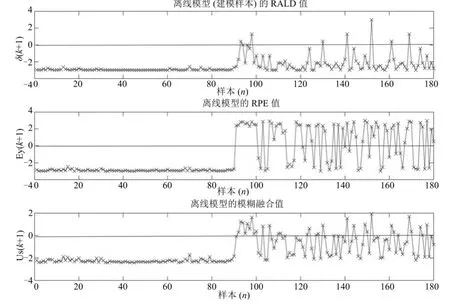
图4 测试样本相对于离线模型(建模样本)的RALD值、RPE值及模糊融合值Fig.4 RALD,RPE and fuzzy fusion values of the testing samples relative to off-line model(modeling samples)
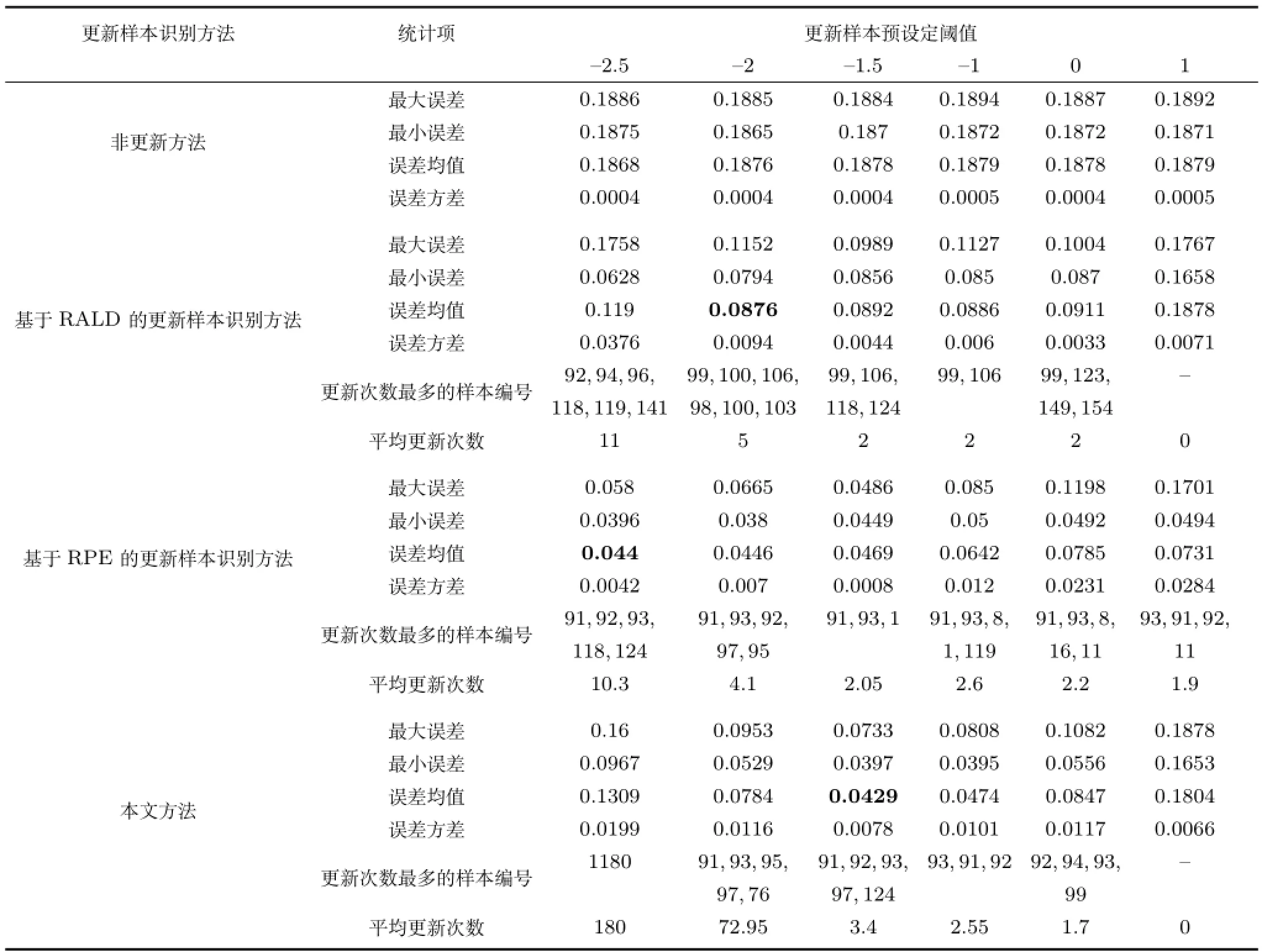
表3 仿真数据在线更新模型重复20次的统计结果Table 3 Statistical results of the online updating model with repeated 20 times for the simulation data
图6表明,未更新时软测量模型具有最差的泛化性能,主要是因为离线模型不能适应C4区域所表征的新工况;对于基于RALD、基于RPE和本文所提方法更新的软测量模型的预测性能均有一定程度的提高.在阈值取-1.5时,基于RPE的方法具有最佳的最大预测误差,本文方法具有最佳的最小和平均预测误差.如,基于本文、RPE和RALD方法的平均RMSRE分别为0.0429、0.0469和0.0892,方差分别为0.0078、0.0008和0.0044.
图6还表明,从曲线形状的角度观察,本文所提方法的预测误差说明存在最佳的阈值能够使软测量模型具有最佳预测性能.
3)在更新样本数量上,本文方法与基于RALD和RPE方法相当,如在样本更新阈值为-1.5时,基于本文方法、RPE方法和RALD方法的重复20次的平均更新样本数量分别3.4、2.05和2,表明三种方法均只需采用较少数量的更新样本即可得到较佳预测性能,原因之一在于每次样本更新后均是重新建立集成子模型,对集成模型的结构、权重系数等均进行了更新;不足之处是未对集成子模型的超参数(如核半径)进行更新.如何在线更新模型超参数将进一步研究,以便提高模型的泛化性能.
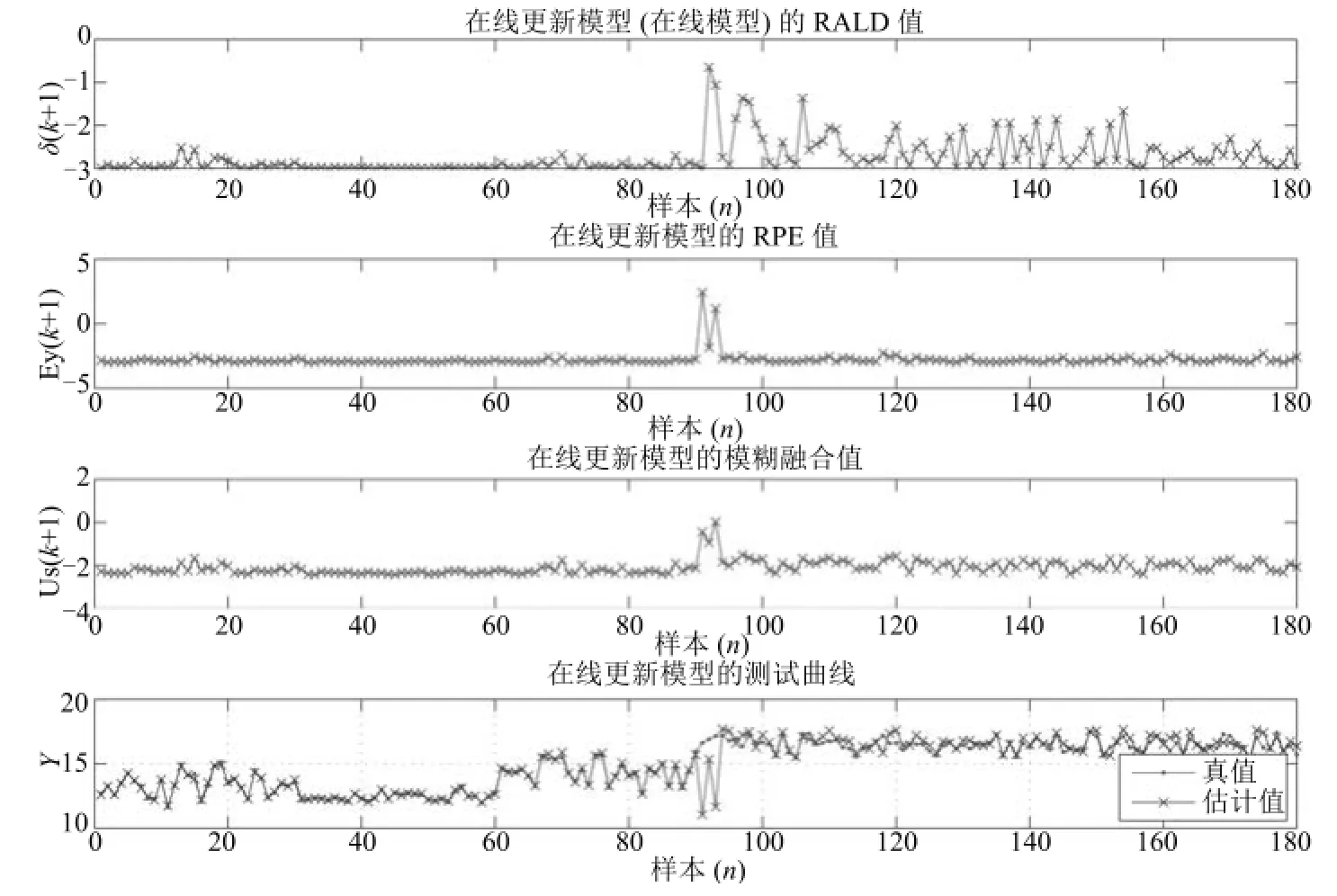
图5 θcom=-1.5时的在线集成模型预测输出Fig.5 Prediction output of the online ensemble model with θcom=-1.5

图6 基于不同更新样本识别方法软测量模型的预测误差Fig.6 Prediction errors of the soft sensor models based on different updating sample identification methods
4)从不同阈值的影响上看,理论上阈值越小,模型的预测性能越好,即参与更新的样本越多模型预测误差越小;当更新样本数量累计过多时模型的预测性能提高较小,甚至反而下降,这是因为过多与临近工作点无关的样本恶化了模型预测性能.下步研究中将考虑如何识别和删减恶化模型性能的多余样本.
5)本文方法与文献[9]提出的在线KPLS方法相比,模型更新次数明显减少,主要原因在于本文所提方法更新了模型结构,进一步表明集成模型结构在线更新的必要性和有效性.
综上,本文方法对具有明确时变特性的建模过程数据是有效的.需提出的是,模糊规则的调整需要领域专家依据具体建模对象特性、软测量模型性能及其他难以量化的因素等综合确定.在后续研究中,需要结合真实的时变工业过程数据进行进一步的细化研究.
4 结论
本文提出的在线更新学习中,模型更新次数是通过模糊规则融合新样本的相对近似线性依靠值和相对预测误差值确定的.智能识别模型的模糊规则主要是依靠领域专家经验确定,在实际应用中需要结合具体的工业过程应用对象进行提取,并提供可供调整的人机交互界面.另外,主要关注更新样本近似线性依靠条件,还是预测误差所表征的概念漂移可通过调整隶属度函数进一步细划.因此,该方法能够有效地实现更新样本的智能识别,通过合理设定模糊推理规则能够在集成模型预测性能与更新效率之间进行均衡,结合具体工程应用将具有广阔前景.
本文方法进行近似线性依靠条件计算需要记录全部训练样本,更新集成模型也需要存储建立核矩阵的潜在特征,导致集成模型存储的数量逐渐递增.集成模型的快速递推更新、模型超参数的快速优化选择等问题将在后续研究中逐步解决.
References
1 Tsymbal A.The Problem of Concept Drift:Definitions and Related Work,Technical Report,The University of Dublin,Trinity College,Department of Computer Science,Dublin,Ireland,2004.
2 Soares S G,Ara´ujo R.An on-line weighted ensemble of regressor models to handle concept drifts.Engineering Applications of Artificial Intelligence,2015,37:392-406
3 Tang Jian,Tian Fu-Qing,Jia Mei-Ying,Li Dong.Load Soft Sensor of Rotating Mechanical Device based on Frequency Spectral Data-driven.Beijing:National Defense Industrial Press,2015.167-173(汤健,田福庆,贾美英,李东.基于频谱数据驱动的旋转机械设备负荷软测量.北京:国防工业出版社,2015.167-173)
4 Liu J L.On-line soft sensor for polyethylene process with multiple production grades.Control Engineering Practice,2007,15(7):769-778
5 Engel Y,Mannor S,Meir R.The kernel recursive leastsquares algorithm.IEEE Transactions on Signal Processing,2004,52(8):2275-2285
6 Yu W.Fuzzy modelling via on-line support vector machines. International Journal of Systems Science,2010,41(11):1325-1335
7 Liu Y,Wang H Q,Yu J,Li P.Selective recursive kernel learning for online identification of nonlinear systems with NARX form.Journal of Process Control,2001,20(2):181-194
8 Tang J,Yu W,Chai T Y,Zhao L J.On-line principal component analysis with application to process modeling.Neurocomputing,2012,82:167-168
9 Tang Jian,Chai Tian-You,Yu Wen,Zhao Li-Jie.On-line KPLS algorithm with application to ensemble modeling parameters of mill load.Acta Automatica Sinica,2013,39(5):471-486(汤健,柴天佑,余文,赵立杰.在线KPLS建模方法及在磨机负荷参数集成建模中的应用.自动化学报,2013,39(5):471-486)
10 Kadlec P,Grbi´c R,Gabrys B.Review of adaptation mechanisms for data-driven soft sensors.Computers and Chemical Engineering,2011,35(1):1-24
11 Tang K,Lin M L,Minku F,Yao X.Selective negative correlation learning approach to incremental learning.Neurocomputing,2009,72(13-15):2796-2805
12 van Heeswijk M,Miche Y,Lindh-Knuutila T,Hilbers P A,Honkela T,Oja E,Lendasse A.Adaptive ensemble models of extreme learning machines for time series prediction.In:Proceedings of the 19th International Conference on Artificial Neural Networks.Limassol,Cyprus:Springer-Verlag,2009.305-314
13 Tian H X,Mao Z Z.An ensemble ELM based on modified AdaBoost.RT algorithm for predicting the temperature of molten steel in ladle furnace.IEEE Transactions on Automation Science and Engineering,2010,7(1):73-80
14 Hao Hong-Wei,Wang Zhi-Bin,Yin Xu-Cheng,Chen Zhi-Qiang.Dynamic selection and circulating combination for multiple classifier systems.Acta Automatica Sinica,2011,37(11):1290-1295(郝红卫,王志彬,殷绪成,陈志强.分类器的动态选择与循环集成方法.自动化学报,2011,37(11):1290-1295)
15 Soares S G,Ara´ujo R.A dynamic and on-line ensemble regression for changing environments.Expert Systems with Applications,2015,42(6):2935-2948
16 Pao Y H,Takefuji Y.Functional-link net computing:theory,system architecture,and functionalities.Computer,1992,25(5):76-79
17 Igelnik B,Pao Y H.Stochastic choice of basis functions in adaptive function approximation and the functional-link net.IEEE Transactions on Neural Network,1995,6(6):1320-1329
18 Comminiello D,Scarpiniti M,Azpicueta-Ruiz L A,Arenas-Garc´ıa J,Uncini A.Functional link adaptive filters for nonlinear acoustic echo cancellation.IEEE Transactions on Audio,Speech,and Language Processing,2013,21(7):1502-1512
19 Alhamdoosh M,Wang D H.Fast decorrelated neural network ensembles with random weights.Information Sciences,2014,264(6):104-117
20 Cao F L,Wang D H,Zhu H Y,Wang Y G.An iterative learning algorithm for feedforward neural networks with random weights.Information Sciences,2016,328:546-557
21 Tang J,Jia M Y,Li D.Selective ensemble simulate metamodeling approach based on latent features extraction and kernel learning.In:Proceedings of the 27th Chinese Control and Decision Conference(2015 CCDC).Qingdao,China:IEEE,2015.6503-6508
22 Fukunaga K,Hayes R R.Effects of sample size in classifier design.IEEE Transactions on Pattern Analysis and Machine Intelligence,1989,11(8):873-885
23 Tang Jian,Chai Tian-You,Cong Qiu-Mei,Yuan Ming-Zhe,Zhao Li-Jie,Liu Zhuo,Yu Wen.Soft sensor approach for modeling mill load parameters based on EMD and selective ensemble learning algorithm.Acta Automatica Sinica,2014,40(9):1853-1866(汤健,柴天佑,丛秋梅,苑明哲,赵立杰,刘卓,余文.基于EMD和选择性集成学习算法的磨机负荷参数软测量.自动化学报,2014,40(9):1853-1866)
24 Tang J,Yu W,Chai T Y,Liu Z,Zhou X J.Selective ensemble modeling load parameters of ball mill based on multiscale frequency spectral features and sphere criterion.Mechanical Systems and Signal Processing,2016,66-67:485 -504
25 Tang J,Chai T Y,Liu Z,Yu W.Selective ensemble modeling based on nonlinear frequency spectral feature extraction for predicting load parameter in ball mills.Chinese Journal of Chemical Engineering,2015,23(12):2020-2028
26 Yu Jian-Bo,Lu Xiao-Lei,Zong Wei-Zhou.Wafer defect detection and recognition based on local and nonlocal linear discriminant analysis and dynamic ensemble of Gaussian mixture models.Acta Automatica Sinica,2016,42(1):47-59(余建波,卢笑蕾,宗卫周.基于局部与非局部线性判别分析和高斯混合模型动态集成的晶圆表面缺陷探测与识别.自动化学报,2016,42(1):47-59)
27 Dhanjal C,Gunn S R,Shawe-Taylor J.Efficient sparse kernel feature extraction based on partial least squares.IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(8):1347-1361
28 Qin S J.Recursive PLS algorithms for adaptive data modeling.Computers and Chemical Engineering,1998,22(4-5):503-514
29 Yue H H,Qin S J.Reconstruction-based fault identification using a combined index.Industrial and Engineering Chemistry Research,2001,40(20):4403-4414

汤 健北方交通大学计算技术研究所博士后.1998年在海军工程学院获工学学士学位,2006年和2012年在东北大学分别获得控制理论与控制工程专业硕士和博士学位.主要研究方向为工业过程综合自动化系统,基于数据驱动的软测量,复杂系统建模与仿真.
E-mail:tjian001@126.com
(TANG JianPostdoctor at the Research Institute of Computing Technology,Beifang Jiaotong University.He received his bachelor degree from Naval College of Engineering in 1998,master degree and Ph.D.degree in control theory and control engineering from Northeastern University in 2006 and 2012,respectively.His research interest covers integrated automation of industrial processes,soft sensor based on data-driven,modeling and simulation of complex system.)

柴天佑中国工程院院士,东北大学教授,IEEE Fellow,IFAC Fellow,欧亚科学院院士.主要研究方向为自适应控制,智能解耦控制,流程工业综合自动化理论、方法与技术.本文通信作者.
E-mail:tychai@mail.neu.edu.cn
(CHAITian-YouAcademician of Chinese Engineering Academy,professor at Northeastern University,IEEE Fellow,IFAC Fellow,and academician of the International Eurasian Academy of Sciences.His research interest covers adaptive control,intelligent control,and integrated automation of industrial process.Corresponding author of this paper.)

刘卓东北大学博士研究生.主要研究方向为复杂工业过程建模.
E-mail:liuzhuo@ise.neu.edu.cn
(LIUZhuoPh.D.candidateat Northeastern University.Her main research interest is soft sensor modeling for complex industries.)

余文墨西哥国立理工大学高级研究中心自动化部教授.1990年在清华大学获学士学位,1992年和1995年在东北大学分别获得电子工程专业的硕士和博士学位.自2006年至今一直担任东北大学的访问教授.主要研究方向为复杂工业过程建模与控制,机器学习.
E-mail:yuw@ctrl.cinvestav.mx
(YU WenProfessor in the Departamento de Control Automatico of the Centro de Investigation de Estudios Avanzados,National Polytechnic Institute M´exico.He received his bachelor degree from Tsinghua University in 1990,the master and Ph.D.degrees,both in electrical engineering from Northeastern University in 1992 and 1995,respectively.He holds a visiting professorship at Northeastern University from 2006.His research interest covers modeling and control of the complex industrial process,and machine learning.)

周晓杰东北大学流程工业综合自动化国家重点实验室副教授.主要研究方向为复杂工业过程建模与机器学习.
E-mail:xjzhou@mail.neu.edu.cn
(ZHOU Xiao-JieAssociate professor at the State Key Laboratory of Synthetical Automation for Process Industries,Northeastern University.Her research interest covers dynamic system modeling for complex industrial processes and machine learning.)
Adaptive Ensemble Modelling Approach Based on Updating Sample Intelligent Identification
TANG Jian1,2CHAI Tian-You2LIU Zhuo2YU Wen3ZHOU Xiao-Jie2
Some new samples can represent concept drift of the modeling plant.Adaptive updating soft sensor model with these new samples can reduce model complexity and running consumption,improve model interpretation and prediction performance.Concept drift embodies on both approximate linear dependence(ALD)and prediction error(PE).In industrial practice,whether to update the old soft measuring models should be decided by the domain experts.Aimmed at these problems,a new online ensemble modeling approach based on updating sample intelligent identification is proposed in this paper.At first,the offline ensemble model based on improved random vector functional-link networks(IRVFL)algorithm is used for online prediction using the new sample.Then,relative ALD(RALD)and relative PE(RPE)values of the new sample are fed into the fuzzy inference model based on domain expert′s knowledge,whose output is used to identify whether this new sample is taken to updating the model.At last,the ensemble model is updated with the re-training strategy.Simulation results based on synthetic data show that the proposed method is valid and effective.
Ensemble learning,updating sample identification,fuzzy inference,approximate linear dependence,prediction error
10.16383/j.aas.2016.c150766
Tang Jian,Chai Tian-You,Liu Zhuo,Yu Wen,Zhou Xiao-Jie.Adaptive ensemble modelling approach based on updating sample intelligent identification.Acta Automatica Sinica,2016,42(7):1040-1052
2015-11-20录用日期2016-03-10
Manuscript received November 20,2015;accepted March 10,2016
国家高技术研究发展计划(863计划)(2015AA043802),国家自然科学基金(61573364,61273177,61305029,61503066,61573249),中国博士后科学基金(2013M532118,2015T81082,2015M581355),流程工业综合自动化国家重点实验室开放课题基金资助项目(PAL-N2015 04),江苏高校优势学科建设工程资助项目,江苏省大气环境与装备技术协同创新中心资助
Supported by National High Technology Research and Development Program of China(863 Program)(2015AA043802),National Natural Science Foundation of China(61573364,612731 77,61305029,61503066,61573249),Postdoctoral Science Foundation of China(2013M532118,2015T81082,2015M581355),Open Project Fund of the State Key Laboratory of Synthetical Automation of Process Industry(PAL-N201504),the Priority Academic Program Development of Jiangsu Higher Education Institutions,and Collaborative Innovation Center of At-
mospheric Environment and Equipment Technology of Jiangsu Province
本文责任编委吴立刚
Recommended by Associate Editor WU Li-Gang
1.北方交通大学计算所北京 100029中国2.东北大学流程工业综合自动化国家重点实验室沈阳 110004中国3.墨西哥国立理工大学高级研究中心(CINVESTAV-IPN)墨西哥07360墨西哥
1.Research Institute of Computing Technology,Beifang Jiaotong University,Beijing 100029,China2.State Key Laboratory of Synthetical Automation for Process Industries,Northeastern University,Shenyang 110004,China3.Departamento de Control Automatico,CINVESTAV-IPN,M´exico D.F.07360,M´exico
