藏文手写识别样本预处理
2016-08-10付吉
付吉
(西北民族大学数学与计算机科学学院 甘肃兰州 730030)
藏文手写识别样本预处理
付吉
(西北民族大学数学与计算机科学学院 甘肃兰州 730030)
藏文图像处理技术在藏语字符识别过程中占有重要的地位,本文研究了几种藏文图像预处理算法。针对手写藏文样本的归一化进行了深入研究,并得到了实验结果。这些结果表明这些处理是有效的,能为藏文的手写识别提供有力的支持。
图像预处理;归一化;藏文手写识别
1 引言
1997年,国家质量技术监督局设计和规定了信息系统字型并发布了标准《信息技术信息交换用藏文编码字符集基本集》[1],从此,藏文字符的识别拉开了序幕,1999年,西北民族大学对藏文基本字符用投影法从垂直、水平、两对角线四个方向五个子特征进行研究,并给出了特征抽取、模式匹配、字符分类的算法[2]。2003年,王华和丁晓青提出了一种基于统计模式识别的多字体印刷藏文字符识别方法[3]。2006~2011年,西北民族大学在藏文联机手写识别的研究方面取得系列成果[4~6]从联机手写藏文字符预处理、特征提取、特征压缩、分类器设计到最后的音节联想等,提出了一整套的联机手写藏文字丁的识别方法,完成了562个现代藏文的联机手写识别系统。对联机手写梵音藏文识别研究而言,目前还没有这方面的深入的研究报道,可以将联机手写梵音藏文识别系统划分成以下几项工作:藏语文字的获取,图像去燥,二值化,归一化,特征提取,梵音藏文的识别。梵音藏文样本采集和预处理是联机手写梵音藏文识别的基础,因此我们提出“梵音藏文样本采集和预处理”,希望通过梵音藏文样本采集和预处理的研究为进一步的研究联机手写梵音藏文识别奠定基础。
2 联机手写梵音藏文样本预处理
2.1 手写体梵音藏文样本灰度化
联机手写样本采集到的数据在计算机中是一幅真彩色的图像。针对文字识别主要关心手写笔画,颜色并不重要。因此,要对样本图像做灰度化处理。从另一方面讲,真彩色图像的数据量是灰度图像的三倍,图像灰度化后可以提高效率。图像灰度化主要有四种算法:取分量法、取最大值法、平均值法和加权平均法等,其中最常用的是后两种算法。对这几种算法我们都做了尝试。
2.2 手写体梵音藏文样本二值化
图像经过灰度化处理后每个像素有256个灰度级。但是这些灰度级对笔画结构没有太大用途,因此可以对样本图像进一步简化,图像二值化。该算法是将图像按照相应的规则划分成两种颜色。对藏文手写样本图像二值化的基本要求是既要让笔画中不要出现空白点又要保持原来的结构特征。图像二值化的关键是阈值的选择。比较成熟的算法有整体阈值二值化、局部阈值二值化和动态阈值二值化法。整体阈值算法可以用下列公式表示:

式中:h(x,y)表示点(x,y)二值化后的灰度值,f(x,y)表示灰度图像的点(x,y)的灰度值。这种算法简单,而且速度是最快的,但是它不能根据每个藏文字符样本来选择最佳的阈值。当样本图像清晰,轮廓明显,选这种算法比较好。图1中(a)表示为灰度图像,(b)为二值化后的图像。
针对全局阈值二值化的不足,有人提出了一种灰度直方图确定阈值方法。由于手写识别样本图像的背景是白色的而笔画的颜色接近于黑色中间的灰度值比较少,决定其直方图基本上呈现出来个比较大的波峰,所以当把阈值选在两个大波峰中间的波谷的为阈值时二值化的效果会更好。图2中(a)为字符样本图像的灰度图像,(b)为二值化图像。
2.3 手写体梵音藏文样本平滑
平滑的目的在于去除孤立的噪音点,填充手写体藏文字符边界小凹陷或删除其中小的凸起。平滑算法有中值滤波、均值滤波等。
中值滤波方法基本思想用图像像素点领域灰度值的中值来代替该像素点的灰度值。中值滤波可以用(2)式表示:

图1 图像灰度化
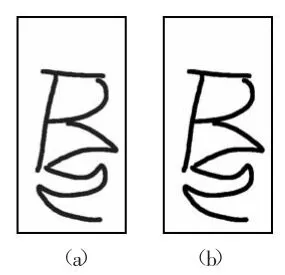
图2 图像二值化

式中:f(m,n)为设定模板区域的像素值,模板大小可以为3×3或5×5。均值滤波是指在图像上对目标像素给一个模板,该模板包括了其周围的临近像素再用模板中的全体像素的平均值来代替原来像素值,(3)式是均值滤波的算法:

式中:f(m,n)是模板区s域的像素值,同样模板大小可为3×3或5×5。图3展示了手写藏文字符样本平滑效果,其中(a)表示平滑处理之前的图像,(b)为平滑处理之后的图像。
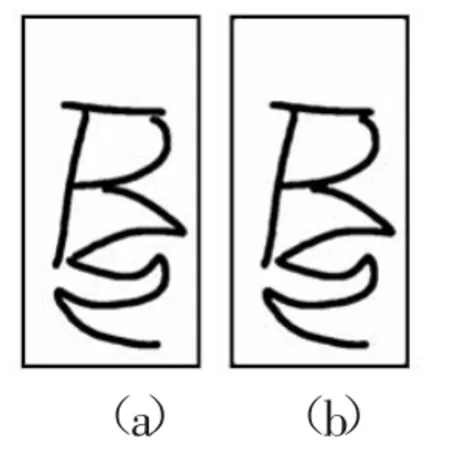
图3 平滑前后对比图像
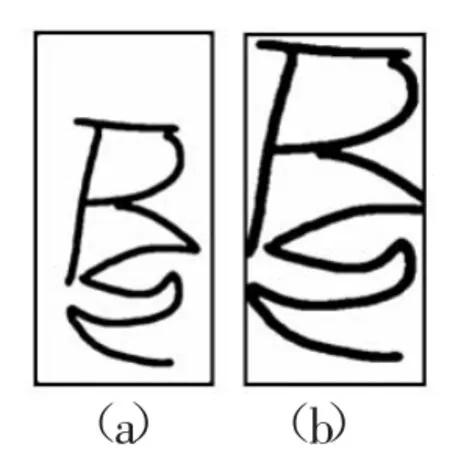
图4 归一化前后对比图像

图5 倾斜化矫正前后对比图像
2.4 手写体梵音藏文样本归一化处理
归一化是手写体梵音藏文样本预处理非常重要的步骤。由于采集的样本图像中的字符大小方面存在很大的差异,因此必须进行归一化处理,有利于减少训练时间,并且能提高是被的准确率。标准的字符图像就是把原来各不相同的字符统一到同一高度和宽度。归一化有两种方法,重心归一化和外框归一化。本文采用的外框归一化。该算法首先要找到笔画的最左、最右、最上和最下点所在的位置;然后利用这四个点得到一个刚好能将手写的字符框住图像;最后通过缩放将该图像缩放到预先设定的标准图像大小。图4展示了归一化前于归一化后的手写藏文样本图像的效果。
2.5 手写体梵音藏文样本倾斜矫正
人们在手写字符时不能保证非常的正,往往是有一定的倾斜角度的。如果不对这些倾斜角度做处理,会加大训练负担,降低识别率。可以选用Hough变换算法进行倾斜矫正,图5表示出来手写藏文字符矫正前后的效果。
3 总结
手写体藏文识别不能缺少其预处理部分。这些工作的好坏决定了最终识别的效率和正确率。通过一系列的预处理,消除图像中与识别无关的因素,降低了影响识别效率的因素,而保留了与识别相关的最重要的因素。
[1]吴佑寿,丁晓青.汉字识别:原理、方法与实现(第一版)[M].北京:高等教育出版社,1992.
[2]王维兰.藏文基本字符识别算法研究[J].西北民族学院学报(自然科学版),1999.
[3]王华,丁晓青.一种多字体印刷藏文字符识别方法[J].中文信息学报,2003,17(6).
[4]柳洪轶,王维兰.联机手写藏文识别中字丁的规范化处理.计算机应用研究,2006,8:179~181.
[5]Weilan Wang,Jianjun Qian,Daohui Wang,Zhuoma Duojie.Online Handwriting Recognition of Tibetan Characters Based on the Statistical Method.Journal of Communication and Computer,2011,8:188~200.
[6]王维兰.一种联机手写藏文字丁的识别方法[ZL].ZL200910128595.8.西北民族大学,2011.
TP391.4
A
1004-7344(2016)08-0028-02
西北民族大学研究生科研(实践)创新项目(NO.Yxm2014178)。
2016-3-1
付 吉(1988-),男,仡佬族,硕士研究生在读,研究方向为智能信息处理与应用软件。
