文本分类中基于改进特征选择方法的研究*
2016-08-10胡改蝶樊孝仁崔艺馨
胡改蝶 樊孝仁 崔艺馨
(太原工业学院网络与信息中心 太原 030008)
文本分类中基于改进特征选择方法的研究*
胡改蝶樊孝仁崔艺馨
(太原工业学院网络与信息中心太原030008)
摘要文本分类不仅可以提高分类的效率,而且可使人们更快地找到想要获取的信息。在特征选择方法的基础上,分析了卡方统计法的缺点,对其提出了一种改进的方法,同时采用支持向量机分类的算法和词频-逆向文件频率权重函数对其进行了验证。通过实验得出此方法可以在很大程度上提高文本分类精确度,使分类的效果更好。
关键词效率; 文本分类; 特征选择; 卡方统计法
Class NumberTP311
1引言
网络发展到现今,几乎所有的知识、信息和新闻等都可以从网络中得到,但如何将网络中的内容更好地进行分类,更加方便人们进行查找,便成了一个热门话题。文本分类是属于机器学习中的一个重要应用。文本分类就是将海量的且杂乱无章的文档集通过计算机将其分别归到不同的类别中,就像映射进程一样,即将一个新文档映射到现有的类别中去,这种映射有两种,一种是一对一,另一种是一对多[1]。从模式分类的角度来看,常见的文本分类方法有基于统计方法、基于连接方法和基于规则方法[2]。文本分类大致步骤是:第一步是预处理;第二步是从上一步的语料库中提取相应的特征,即特征提取;第三步是特征选择;最后,重新对一个新文档集进行分类[3]。
2特征选择概述
所有的分类都要依赖于文本训练样例的特征词规模,特征词的规模达到数万个是再正常不过的,甚至可以达到亿级,因而做出决策模型的时间就很长,并且如此大的维数非常容易造成维度灾难。降低维数的输入而不影响分类准确率的方法有特征选择与特征抽取[4]。
特征选择也称特征子集或属性选择,即从特征子集中找到最佳子集作为特征词,因为最佳子集所含的维数最少,对分类准确率的贡献就最大。特征选择的目标是根据一个选择标准在原始特征集中选择一个子集,去掉不相关的特征,达到减少特征的个数,而且剩下的正相关的特征使模型得到了简化,使分类效果与准确度大大提高[5~6]。特征选择在文本分类中的方法比较多,有文档频率DF、信息增益IG、期望交叉熵ECE、卡方统计方法CHI、互信息MI、GSS Coefficient等[7]。
3卡方特征选择统计法与改进
卡方特征选择统计法从标准考虑角度来看,有距离、相关性和平衡度三种度量标准。其中,相关性度量标准在一定程度上能有效地去掉不相关的特征[8]。特征t在类别c中的CHI特征选择方法如式(1)所示,公式计算所得到的结果越大,说明此特征与类别之间的相关性越大,分类的结果也就越好。
(1)
本文从相关性度量标准和平衡度度量标准来进行相应的研究,前者主要是在文档中找到与特征相关比较大的词,从而进行特征选择[9];后者主要是在文档中找到与特征平衡度较高的词作为特征词,从而进行特征选择。但一些相关性不大的词和平衡度不太高的词却没有考虑在内。为了有效地解决这些问题,CHI特征选择方法进行了改进,改进后的式(2)。
(2)
其中:总文档数为n,类别为c,类别c中含有特征t的文档概率η=1.0*tfi/n,类别c的文档概率ξ=1.0*c/n。
4实验与结果分析
4.1语料库及实验环境
本实验的训练与测试语料库均由复旦大学信息与技术系国际数据库中心自然语言处理小组整理所得,从中抽取了八个类别,分别是计算机、交通、军事、环境、政治、体育、医药和经济。其中训练文本集有1569个,测试文本集有779个,文本集共2348个文本集。采用环境是Windows7专业版,Intel(R) Xeon(R) CPU E5504@2.00GHz处理器,2.00G内存,32位操作系统,Visual C++6.0开发语言。
4.2分类算法、权重及评价标准
文本分类算法有K-近邻算法、支持向量机(SVM)算法、决策树算法和朴素贝叶斯算法等,本实验采用SVM分类算法,这种算法是在类别中找到一个决策边界,只关心靠近边界的实例,落在内部的实例将其丢掉,可以从高维度的特征空间中学习到较好的分类超平面[10]。文本分类特征权重方法有布尔函数、平均根函数、TF-IDF函数和对数函数等,本文特征权重选择TF(IDF函数,它的理论是若一词在文档中出现的频率TF高,同时在其他文档中出现的次数比较少,那么这个词就有很好的区分类别的能力,因而它是信息搜索中最常用的方法,在分类中广泛应用[11]。实验过程中特征选择方法选用CHI,特征维数选择500。文本分类的评价标准有查全率(R,Recall)、查准率(P,Precision)、漏报率、准确率、宏平均、微平均、ROC曲线、代价因子和F-测度(F)等,本实验用到的评价标准是查全率(R)、查准率(P)和F-测度(F)[12]。
4.3结果分析
传统的CHI与改进后的CHI的查全率和查准率实验比较结果如表1所示,F-测度实验比较结果如表2所示。从表1和表2中可以看出,改进后CHI方法的查全率R、查准率P和F-测度的评价标准值都比传统CHI高,虽然某些值高出的并不明显,但整体来说,改进后的实验结果要好些。

表1 查全率和查准率实验结果比较

表2 F-测度实验比较结果
由于F-测度是由查全率与查准率得出的,在一定程度上F-测度结果是二者的综合,所以本实验给出了F-测度的比较曲线图,如图1所示。从图1中可以更加直观地看到,改进后的方法比传统的方法的F-测度的分类效果明显要好得多。
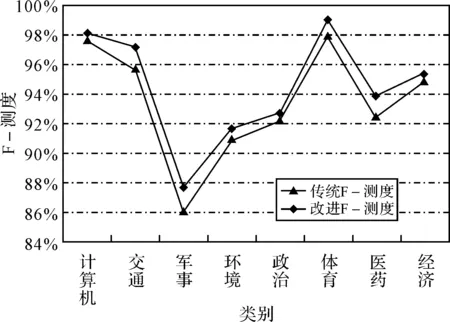
图1 F-测度比较曲线图
5结语
文本分类中的一个必不可少的、关键且重要的一步是特征选择方法,CHI统计法是特征选择方法中比较好的一种。本文将文本分类中CHI统计法进行了阐述与分析,并提出了一种改进的CHI方法,通过大量实验,进一步说明改进的方法是适用的、可行的、高效的。
参 考 文 献
[1] 王雷.文本分类相关技术研究[D].上海:复旦大学,2006.WANG Lei. Research On the Related Technology of Text Classification[D]. Shanghai: Fudan University,2006.
[2] 祝晓鲁,白振兴,贾海燕.自动文本分类技术研究[J].现代电子技术,2007(3):121-124.
ZHU Xiaolu, BAI Zhenxing, JIA Haiyan. A Survey of Algorithm of Text Categorization[J]. Modern Electronics Technique,2007(3):121-124.
[3] 陈艳秋,熊耀华.新型快速中文文本分类器的设计与实现[J].计算机工程与应用,2009,45(22):53-55.
CHEN Yanqiu, XIONG Yaohua. Design and implementation of new Chinese text classier[J]. Computer Engineering and Applications,2009,45(22):53-55.
[4] Ethem Alpaydin.机器学习导论[M].范明,昝红英,牛常勇,译.北京:机械工业出版社,2009:65-69.
Ethem Alpaydin. Machine learning[M]. FAN Ming, ZAN Hongying, NIU Changyong, et al. Beijing: China Machine Press,2009:65-68.
[5] 范小丽,刘晓霞.文本分类中互信息特征选择方法的研究[J].计算机工程与应用,2010,46(34):123-125.FAN Xiaoli, LIU Xiaoxia. Study on mutual information-based feature selection in text categorization[J]. Computer Engineering and Applications,2010,46(34):123-125.
[6] M. Dash, H. Liu. Feature Selection for Classification. Intelligent Data Analysis,2010,1:131-156.
[7] 张玉芳,王勇,刘明,等.新的文本分类特征选择方法的研究[J].计算机工程与应用,2013,49(5):132-135.
ZHANG Yufang, WANG Yong, LIU Ming, et al. New feature selection approach for text categorization[J]. Computer Engineering and Applications,2013,49(5):132-135.
[8] 范小丽.文本分类中特征选择方法的研究与应用[D].西安:西北大学,2011.
FAN Xiaoli. Research and Application of Feature Selection Method in Text Categorization[D]. Xi’an: Northwest University,2011.
[9] 胡改蝶,马建芬.文本分类中一种特征选择方法的改进[J].计算机与现代化,2011(5):20-21.
HU Gaidie, MA Jianfen. Improvement of Feature Selection Method in Text Classification[J]. Computer And Modernization,2011(5):20-21.
[10] Nello Cristianini, John Shawe-Taylaor.李国正,王猛,曾华军,译.支持向量机导论[M].北京:电子工业出版社,2004:8-15.
Nello Cristianini, John Shawe-Taylaor. Li Guozheng, Wang Meng, Ze Huajun. Introduction to Support Vector Machine[M]. Beijing: Publishing House of Electronics Industry,2004:8-15.
[11] 宋惟然.中文文本分类中特征选择和权重计算方法的研究[D].北京:北京工业大学,2013.
SONG Weiran. Researchon Feature Selection and Weighting Method for Chinese text Classification[D]. Beijing: Beijing University of Technology,2013.
[12] 郭亚维,刘晓霞.文本分类中信息增益特征选择方法的研究[J].计算机工程与应用,2012(27):119-122.
GUO Yawei, LIU Xiaoxia. Study on information gain-based feature selection in Chinese text categorization[J]. Computer Engineering and Applications,2012,48(27):119-122.
收稿日期:2016年1月4日,修回日期:2016年2月26日
作者简介:胡改蝶,女,硕士,助理工程师,研究方向:自然语言处理,文本分类,机器学习,计算机网络。樊孝仁,男,副教授,研究方向:信息与计算技术。崔艺馨,女,硕士,助理工程师,研究方向:计算机网络,数据挖掘。
中图分类号TP311
DOI:10.3969/j.issn.1672-9722.2016.07.022
Text Categorization Based on Improved Feature Selection in Text Categorization
HU GaidieFAN XiaorenCUI Yixin
(Network and Information Center, Taiyuan Institute of Technology, Taiyuan030008)
AbstractText categorization not only can improve the efficiency of categorization, but also can make people quickly find the information they want. On the basis of the feature selection method, this paper analyzes Chi-square (CHI) statistical method shortcomings, and proposes a Chi-square statistical method. At the same time, the Support Vector Machine (SVM) classification’s algorithm and Term Frequency-Inverse Document Frequency (TF-IDF) weight function are used on the validation. The experiment shows that this method can largely improve to the text categorization accuracy, the classification effect is greatly improved, make better classification.
Key Wordsefficiency, text categorization, feature selection, Chi-square statistical method
