基于Hadoop的Java调用Matlab混合编程的车牌识别
2016-08-08蔡春晓李燕龙
蔡春晓,李燕龙,陈 晓
(1.桂林电子科技大学 教学实践部, 广西 桂林 541004; 2.桂林电子科技大学 信息科技学院, 广西 桂林 541004)
基于Hadoop的Java调用Matlab混合编程的车牌识别
蔡春晓1,李燕龙1,陈晓2
(1.桂林电子科技大学 教学实践部, 广西 桂林541004; 2.桂林电子科技大学 信息科技学院, 广西 桂林541004)
摘要:在交通行业日益发展的今天,车牌识别技术对于公路车辆监管以及车辆轨迹跟踪越来越重要,考虑到庞大的车辆信息数据量,单机处理数据能力已不能满足实时性的要求。本文在详细研究分布式处理平台Hadoop的工作原理后,利用其强大的HDFS存储系统与MapReduce数据处理方案,通过Java对Matlab的调用,简化了识别程序,搭建了分布式处理平台,即使在数据量庞大的情况下也能够进行车牌识别分布式计算。实验结果表明,在处理2 000张以上的车牌图像时,运行效率提升了2倍左右。
关键词:云计算;车牌识别;混合编程;分布式计算
0引言
近年来,随着我国公路交通事业的日益发展和人民生活水平的提升, 车辆数目不断增加, 通过车牌识别来统计车辆轨迹的方法对于交通管制的作用也变得愈发重要[1]。 为了能够快速存储和处理庞大的车牌号信息数据, 必须借助分布式处理平台。 Hadoop是Apache基金会所开发的一种分布式基础架构, 具有高可靠性、 高拓展性、 高效性、高容错性、低成本等一系列特性,用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。Hadoop框架最核心的设计HDFS与MapReduce分别可以实现海量数据存储与海量数据计算。
2006年初, 通过借鉴Google的GFS和Map Reduce技术,Nutch项目的开发团队解决了前期面临的软件扩展性问题,实现了开源的Nutch分布式文件系统(NDFS)和MapReduce计算框架。由于NDFS和MapReduce具有较高的应用价值,而不仅限于搜索领域,开发团队将它们从Nutch项目中拆分出来,组成一个新的开源项目Hadoop,NDFS随即更名为HDFS。2008年初,Hadoop成为Apache的重点研究项目,得到了一些国际厂商的支持,如FaceBook、Yahoo以及阿里巴巴等互联网巨头,这使得Hadoop迎来了它的快速发展[2]。
在短短的几年中,Hadoop成为了目前为止最为成功、最广泛使用的大数据处理主流技术和系统平台,并成为一种大数据处理事实上的工业标准[3],得到工业界大量的进一步开发和改进,并在业界和应用行业,尤其是互联网行业得到广泛的应用。
由于在系统性能和功能方面存在不足,Hadoop在发展过程中不断改进,自2007年推出首个版本以来,目前已经先后推出数十个版本。Hadoop系统在大规模数据分布存储和批处理能力[4],以及在系统的可扩展性和易用性上具有不少其他系统难以具备的优点, 并且由于近几年来业界和应用行业在Hadoop开发和应用上已有大量的前期投入和上线应用系统,以及Hadoop形成的包含各种丰富的工具软件的完整生态环境,同时也随着Hadoop自身向新一代系统的演进和不断改进,在今后相当长一段时间内,Hadoop系统将继续发挥其在大数据处理领域的重要作用,同时其他各种新的系统也将逐步与 Hadoop系统相互融合和共存[5-6]。
Hadoop的底层框架由Java编写,考虑到各种计算情况下,有些Java代码实现的运算并不高效,而利用Matlab写好相应的函数,再由Java将其调用会显得更加方便[7]。Java 语言具有跨平台性、可移植性、多线程、分布式、安全可靠等优点。但 Java 程序设计语言对一些较为复杂的数值计算的编程较繁琐,编程效率较低。对于较为复杂的分析与处理可以采用 Java 及 Matlab 的混合编程,实现二者的优势互补。
1Hadoop平台以及eclipse开发环境的搭建
1.1Hadoop平台介绍
分布式文件系统HDFS和分布式计算框架MapReduce是Hadoop的两大核心组成部分。其中,HDFS负责大规模数据集的分布式存储,是一个典型的主从式体系结构,由1个主节点(NameNode)和多个从节点(DataNode)构成;整个Hadoop集群中,只允许同时存在一个NameNode节点,它是整个系统的主控服务器,用于管理HDFS的命名空间和协调客户端的文件访问。MapReduce构建在HDFS之上,为存储在HDFS上的数据提供分布式计算框架,由1个JobTracker和多个TaskTracker组成;JobTracker负责整个MapReduce的资源监控和作业调度,TaskTracker负责执行JobTracker分配下来的计算任务;用户通过客户端将编写好的MapReduce程序提交到JobTracker端,之后MapReduce作业被分解为若干个Map Task和Reduce Task,任务调度器按照一定的调度策略(可配置)将任务分配到适当的TaskTracker上执行。两者紧密结合、相互协调,为Hadoop高效、可靠地处理大数据提供了保障。
分布式计算的简略实施步骤如下:①集群下每台计算机安装Linux操作系统;②每台计算机修改主机名(主机名和IP地址的映射), 配置hosts文件(在/etc/hosts中添加机器名和相应的IP);③创建用户;④配置ssh,使master主机与每台slave主机实现无密码登陆;⑤安装JDK;⑥安装Hadoop;⑦在master主机上配置好,再分发到各台slave主机。此外,安装Hadoop后需修改环境变量,加入Hadoop路径,为方便统一管理,在Hadoop根目录下建立文件夹:mkdir tmp、mkdir hdfs、mkdir logs、mkdir hdfs/name、mkdir hdfs/data,可将文件夹权限修改为可读写;再修改/Hadoop/conf/目录下的配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、 mapred-site.xml、masters、slaves;配置masters和slaves:分别用gedit打开masters和slaves,前者加入hadoopm,后者加入hadoops即可;将配置文件hosts、bashrc同步到集群各个节点中,并把配置好的hadoop发送到集群中各个节点;对集群的分布式文件系统进行格式化,并检查系统启动情况。
1.2开发环境安装
①在Linux下安装eclipse;
②安装eclipse-hadoop插件;
③配置eclipse;
④测试插件是否安装成功。
由于本文所论述的识别车牌方法涉及Hadoop内部HDFS文件系统的工作原理,而开发环境的安装只为了能够让开发者运用自己所擅长的语言编译出适用于某种特定功能的代码,故关于开发环境的具体安装方法及步骤本文不再赘述。
至此,系统环境搭建已完成[8]。
2Matlab的调用与MapReduce的运算执行
2.1Matlab车牌识别算法
车牌识别需经过触发拍照、图像采集、图像预处理、车牌定位、字符分割、字符识别、输出结果等一系列过程,其中字符识别为核心内容。目前,用于车牌字符识别(OCR)的算法已经有很多种,主要有基于模板匹配的OCR算法[9]、基于特征分析的字符识别算法及基于人工神经网络的OCR算法[10]。本文以基于模板匹配车牌识别Matlab算法为例,实现在Hadoop云计算平台上Java调用Matlab混合编程的车牌识别处理过程。
如图1所示,基于模板匹配的OCR算法过程为:首先对待识别字符进行二值化,并将其尺寸大小缩放为字符数据库中模板的大小,然后与所有的模板进行匹配,最后选最佳匹配作为结果。模板匹配是图像识别方法中最具代表性的基本方法之一[11],它是将从待识别的图像或图像区域中提取的若干特征量与模板相应的特征量逐个进行比较,计算它们之间规化的互相关量,其中互相关量最大的一个就表示期间相似程度最高,可将图像归于相应的类。通常情况下用于匹配的图像各自成像条件存在差异,本文采用相减的方法求得字符与模板中最相似的字符,然后找到相似度最大的输出[12]。
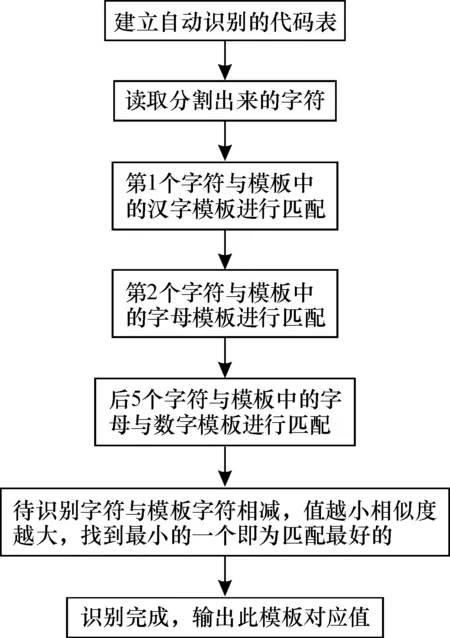
图1 车牌识别算法Fig.1 License plate recognition algorithm
2.2Java对于Matlab的调用
考虑到计算的各种情况,有些用Java代码实现的计算难免会显得不够高效。而利用Matlab写好相应的计算函数,然后打包成jar包供Java调用,在某些情况下会更加方便。以下说明如何实现这一过程:
(1)确定计算机上已安装Matlab或者Matlab动态链接库,并且完成Java的运行环境配置,Matlab的版本必须为2006b+(包括2006b或更高版本), 因为只有在这些版本中才有Matlab Builder for Java(也叫Java Builder)[13]。
(2)打开Matlab,在Command Window框中输入deploytool,在Name中输入名字,在Location中选择路径,最后在Type中选择Java Package。
(3)在Matlab中找到Java Package窗口,添加class文件,因为此文件就是以后导入到Java中要作为一个对象的名字,故当命名class文件的时候需要注意,其本身即为放在new后面作为构造函数的类名,本文命名为test。
(4)点击类名下的Add files,将刚才编辑好的m文件test.m等相关函数文件加到test.prj当中。
(5)打包:在Matlab安装的目录中找到“… oolboxjavabuilderjarjavabuilder.jar”的文件,在刚刚打包的文件夹中找到对应的包,本文为test.jar,将这两个jar包导入到Java项目当中,新建Java类文件test.java,这个Matlab文件转为了Java类就可以直接被Java项目调用。
2.3MapReduce执行流程
借助Hadoop 框架及云计算核心技术MapReduce 来实现数据的计算和存储,并且将HDFS分布式文件系统和HBase分布式数据库很好地融入到云计算框架中,从而实现云计算的分布式、并行计算和存储,并具有很好的处理大规模数据的能力。
MapReduce的任务可分为两个阶段:Map阶段和Reduce阶段。每个阶段都使用键值对作为输入和输出,IO类型可由程序员进行选择。一个MapReduce工作单元,包括输入数据、MapReduce程序和配置信息。作业控制由JobTracker(1个)和TaskTracker(多个)执行。MapReduce程序执行时,输入的数据会被分成等长的数据块,这些数据块即为分片。Map任务运行在本地存储数据的节点上,才能获得最好的效率。Map的结果只是用于中间过渡,这个中间结果要传给Reduce任务执行,Reduce任务的结果才是最终结果,Map中间值最后会被删除。
一个MapReduce工作(job)会将文件系统中的数据输入并分隔为多个独立的分块(split);每个分块都会被提交给一个Map任务处理;经Map任务处理后,所有具有相同属性的数据会被提交给一个Reduce任务处理;Reduce任务将处理结果输回文件系统。而本文使用到MapReduce最核心的功能则需通过对Map任务与Reduce任务的编程实现。
进行任务配置: job.setOutputKeyClass(key3_T.class); job.setOutputValueClass(value3_T.class); 编写Map extends Mapper类时实现数据映射过程“〈key1,value1〉→〈key2,value2〉”;编写Reduce extends Reducer类时实现数据归约过程“〈key2,list(value2)〉→〈key3,value3〉”。
数据输入方法:数据在进入Map任务前首先需要经过分隔和格式化的过程; 输入数据经过分隔形成若干个相互无关的输入分片(Input Split), 各个输入分片中的每条数据记录都会被格式化为〈key,value〉的形式传递给Map任务;输入方法由InputFormat接口类的实现定义。
3实验结果与分析
本文搭建的Hadoop云平台由4台普通PC组成,其中1台作为NameNode节点(Master), 其余3台作为DateNode节点(Slave)。NameNode节点用于存放系统目录和分配计算任务等,DateNode节点用于存储实际数据和提供计算资源。
本文所实现的车牌识别系统能从车牌图像中自动提取车牌区域,自动分隔字符,进而对字符进行识别,得到车牌号码。整个车牌识别系统的核心功能为车牌定位与字符识别,但其他功能也是重要组成部分,关系着整个系统的准确性与效率。在切割过程中会有对中文单个字符进行切割的现象,可以通过修改配置参数或者用基于距离的分割方法对车牌进行切割解决,主要需要完成MapReduce处理过程设计、InputFormat功能设计、Map任务功能设计、Reduce任务功能设计等。
MapReduce处理过程的设计:输入文件为带有元数据和图像数据的车牌消息源文件; Map任务为从车辆照片中识别获得数字化车牌;Reduce任务为对具有相同车牌的元数据进行归类和排序;输出文件为含有车牌轨迹和定位信息的结果文件。
Map任务功能的设计:对图像数据(类型为BufferedImage,作为Value输入)进行检测,测定车牌位置,并进行倾斜校正; 再将车牌分隔为字符后对字符进行模板对比识别; 得出数字化的车牌序列(类型为Text, 作为Key输出)。
Reduce任务功能的设计:对具有相同序列化车牌(类型为Text,作为Key输入和输出)的元数据集合(类型为Iterable〈Text〉, 作为value输入)进行归类合并, 并按照时间顺序进行排序后输出(类型为Text, 作为value输出)。
实验中具体的识别过程为:首先取字符模板,接着依次取待识别字符与模板进行匹配,将其与模板字符相减,得到的0越多就越匹配。把每一幅相减后图0值最多个数对应的模板保存下来,即为识别出来的结果[14]。识别结果如图2所示。
设置4组分别包含有100、 500、 1 000、2 000张车牌信息的随机图像,测试系统在单机情况和分布式情况下的处理耗时,其中分布式又分为单节点(slave_1)、双节点(slave_2)和三节点(slave_3)3种情况。在得到相同输出结果的情况下,系统耗时如图3所示。

图2 识别结果Fig.2 Recognition results
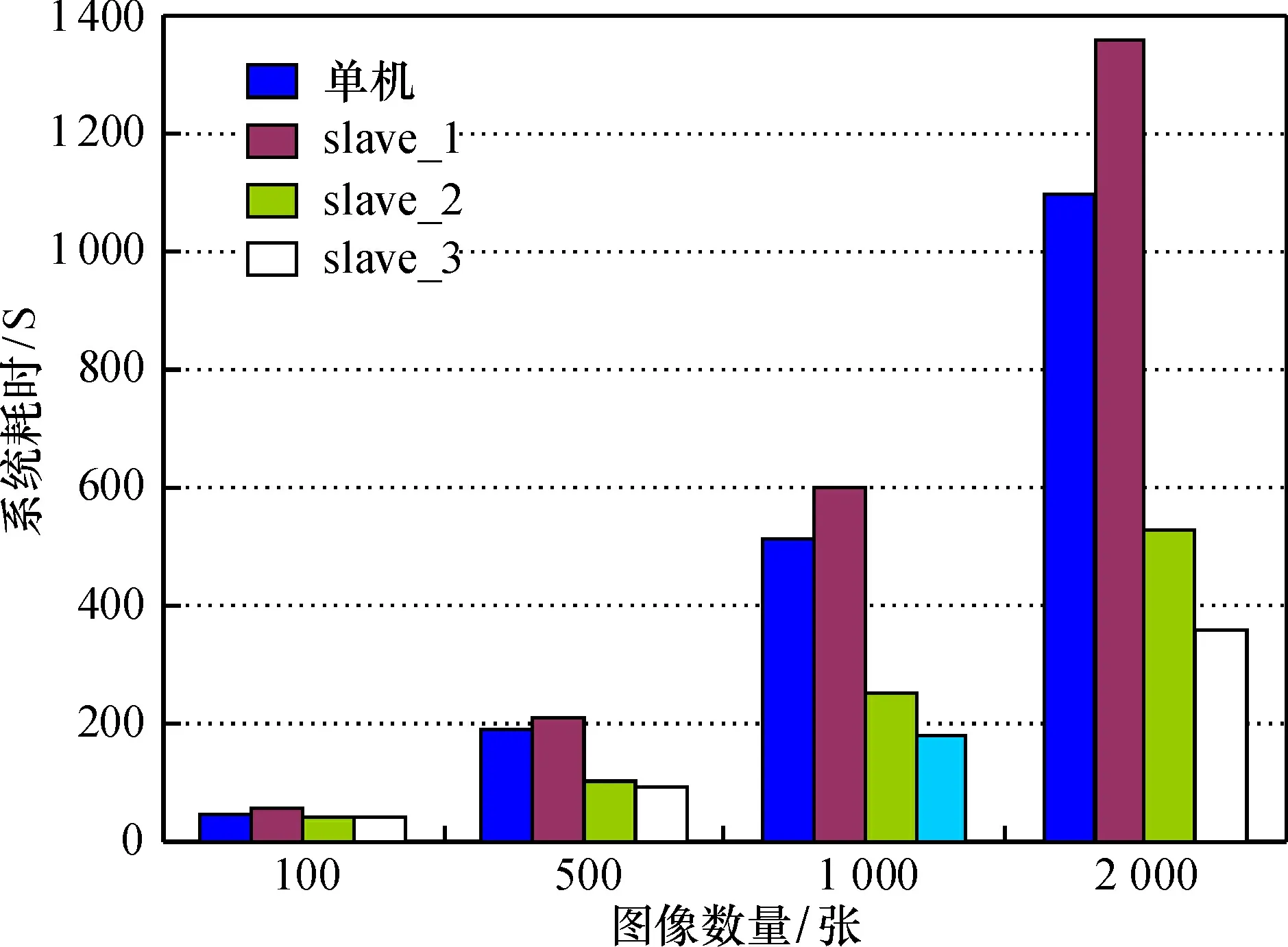
图3 图像识别系统耗时Fig.3 Time used in image recognition system
可知,在单机和1个节点的情况下,系统耗时接近,且单机处理速度稍快,这是由于单机环境下省去了主机与节点间通信和数据交换的时间开销。随着节点数的增加,系统处理速度显著提升,同时由于采用Java调用Matlab处理,处理过程更加灵活,并且图像数据量越大,分布式并行处理的优势越明显。实验结果显示,当图像达到2 000张时,基于云架构的系统较单机系统的处理速度快了2倍左右。因此,基于云平台的车牌识别系统在处理海量图像数据时,性能优于传统单机识别系统。
4结束语
由于目前技术限制,文中所阐述的车牌识别技术还有一些问题,其解决方案如下:(1)本程序使用的是投影法进行车牌字符切割, 会有对中文单个字符进行切割的现象, 可以通过修改配置参数或者用基于距离的分割方法对车牌进行切割解决; (2)文件调用,程序本身不能识别HDFS文件系统路径,所以程序运行时调用的是本地系统的模板文件,这样会降低效率。解决方法有两个:第一是将程序中的路径替换成HDFS文件路径;第二是将模板文件放到每一台机器的统一路径下。
采用Java与Matlab混合编程来实现MapReduce功能不仅在识别车牌的效率有了大幅提升,在其他图像处理、通信、计算领域都具有很好的应用前景,同时易于开发者编写、更改代码来实现功能的调整,如此一来,极大促进了云计算的应用和推广。
参考文献:
[1]何苏勤,杨美荟.嵌入式视频监控系统实时性研究[J].计算机工程,2009,35(4): 235-237,240.
[2]董西成.Hadoop 技术内幕:深入解析MapReduce 架构设计与实现原理[M].北京:机械工业出版社,2013.
[3]Zhao X M, Ma H D,Zhang H T,et al. Metadata extraction and correction for large-scale traffic surveillance videos[C]//2014 IEEE International Conference on Big Data, 2014:412-420.
[4]罗军舟,金嘉晖,宋爱波,等.云计算:体系架构与关键技术[J]. 通信学报, 2011,32(7):3-21.
[5]王鹏,黄华峰,曹珂.云计算:中国未来的IT战略[M].北京:人民邮电出版社,2010.
[6]张建勋,古志民,郑超.云计算研究进展综述[J].计算机应用研究,2010,27(2): 429-433.
[7]Echel B.Java编程思想[M].4版.陈昊鹏,译.北京:机械工业出版社,2007.
[8]Metsker S J,Wake W C.Java设计模式[M]. 2版.张逸,史磊,译.北京:电子工业出版社, 2012
[9]刘佐濂,邓荣标,孔嘉圆.一种车牌识别算法的实现[J].中国科技信息,2005,23(2):56-57.
[10]Yoshida T, Kagesawa M,Ikeuchi K,Local-feature based vehicle recognition system using parallel vision board[J].Elecironic and Communication in Japan,2003,86(5):1-10.
[11]史绍强,王英健,唐贤瑛.基于整形特征与模糊识别的手写体汉字识别[J].微机发展,2004,14(1):114-116.
[12]叶晨洲, 杨杰,宣国荣. 车辆牌照字符识别[J].上海交通大学学报,2000,34(5):672-675.
[13]张银鹤,唐有明,王俊伟. 点石成金:JSP+Ajax网站开发典型实例[M].北京:电子工业出版社,2009.
[14]Ching Y T.Detecting line segments in an image:A new implementation for Hough Transform[J]. Pattern Recognition Letters,2001, 22(3): 421-429.
文章编号:1674-9057(2016)02-0383-05
doi:10.3969/j.issn.1674-9057.2016.02.033
收稿日期:2015-06-16
基金项目:广西自然科学基金项目(2013GXNSFAA019334)
作者简介:蔡春晓(1980—)男,硕士,讲师,研究方向:计算机控制、云计算、大数据,fjcainiao@guet.edu.cn。
通讯作者:李燕龙,讲师,lylong@guet.edu.cn。
中图分类号:TP391.9
文献标志码:A
Effective recognition of license plate based on invoking of Matlab from Java in Hadoop
CAI Chun-xiao1, LI Yan-long1, CHEN Xiao2
(1.Department of Experiential Practice,Guilin University of Electronic Technology, Guilin 541004,China;2.Institute of Information Technology of Guilin University of Electronic Technology, Guilin 541004,China)
Abstract:With the development of transportation industry, the technology of license plate recognition plays a more important role in the traffic regulation and vehicle tracing than before.Present bulkiness of vehicle information and the capacity of stand-alone data processing can not meet the real-time requirements.The powerful storage system of HDFS and data solution of Map Reduce are used to improve license plate recognition algorithm after studying the principle of Hadoop (a platform of distributed data processing). By Java of Matlab calls, the recognition procedure is simplified, and a distributed processing platform is set up.The license plate recognition can be distributed in computing with a large amount of data. Experimental results show that when dealing with more than 2 000 images of license plates, operating efficiency improved about 2 times.
Key words:cloud computing; license plate recognition; hybrid programming; distributed computing
引文格式:蔡春晓,李燕龙,陈晓.基于Hadoop的Java调用Matlab混合编程的车牌识别[J].桂林理工大学学报,2016,36(2):383-387.
