数据虚拟化研究综述
2016-08-06赵国锋葛丹凤
赵国锋,葛丹凤
(1.重庆邮电大学 电子信息与网络研究院, 重庆 400065; 2.重庆市光通信与网络高校重点实验室, 重庆 400065)
数据虚拟化研究综述
赵国锋1,2,葛丹凤1
(1.重庆邮电大学 电子信息与网络研究院, 重庆 400065; 2.重庆市光通信与网络高校重点实验室, 重庆 400065)
摘要:大数据系统中数据源多,数据规模大,且数据具有异构异质的特点,为满足各种数据集成需求,如何快速高效地整合数据就显得越来越重要且具有挑战性。数据虚拟化能够灵活地实现各种数据集成需求,介绍数据虚拟化的概念、优势及应用需求,给出一种数据虚拟化系统架构,并对其中的数据虚拟化平面与管理平面以及各层的功能进行了阐述。重点针对数据虚拟化系统中存在的一些关键问题与挑战进行了详细分析,给出了需要进一步研究的课题与方向。
关键词:大数据;数据集成;数据虚拟化
0引言
近年来,大数据为众多行业的发展带来了重大机遇也面临着艰巨挑战。面对多样化、异构多源产生且跨行业整合的大规模数据,尤其是半结构化和非结构化的数据,必须解决数据采集、数据存储、数据分析、数据管理、数据安全5个方面的问题[1-4]。
在大数据技术创新的第一阶段,需要解决的主要问题是如何高效地组织存储与快速处理大数据。出现了以Hadoop为代表的分布式存储计算架构、以HDFS(Hadoop distributed fiel system)为代表的分布式文件系统、以BigTable、DynamoDB为代表的多种存储模型、大规模并行处理(massively parallel processing,MPP)数据库等大数据处理技术,这些技术是建立在大规模集群基础上的,需要大量的物理资源,其中也必然存在手工部署难、成本高、效率低、单点失效(无法保证服务的连续性)等问题[5-6]。
除了极少数企业,如Google,Facebook等,大多数企业并不具备提供上述技术与基础设施的能力,而云计算[7-8]为大数据提供了可以弹性扩展、相对便宜的存储空间和计算资源,使得越来越多的企业将自己的各种应用程序及信息基础设施转移到云平台上,云计算模式带来了大数据技术的第2次创新,即以用户业务需求为基础的技术创新[9-11]。
在构建全面的云基础设施时,虚拟化是最主要的技术创新。目前云中心使用的虚拟化技术通常包括计算虚拟化(虚拟机),存储虚拟化和网络虚拟化技术。这些技术成为构建云中心信息基础设施的基石,也为云中的大数据分析应用提供了技术保障。作为虚拟化技术的一种延伸,数据虚拟化技术引入到基于云的大数据平台,使得云上的大数据拥有跨节点、集群和层化的功能服务,为端用户提供高灵活性[12-16]。大数据促使数据虚拟化成为一种新兴的数据集成与管理方法,应用领域由金融服务、电信业和政府部门逐渐扩展到医疗、保险、零售、制造、电子商务及媒体/娱乐行业等[17-19]。
伴随着SaaS(software-as-a-service),IaaS(infrastructure-as-a-service)、PaaS(platform-as-a-service)等云计算模式以及大数据的应用,人们逐步认识到数据的价值并且将数据作为一种服务。同时也诞生新的商业模式,使用户可以按需订购各种所需的数据服务[20]。数据即服务(data-as-a-service,DaaS)作为一种数据资源的集中化管理和服务提供方法,使数据服务的提供更灵活,更有利于发挥数据的价值。同时大数据时代的到来也将促进DaaS模式的快速发展,用户将重点关注数据服务带来的价值而不再是技术细节[21]。
数据虚拟化是实现数据服务的关键技术,但是它也并非一个新概念。早在2003年就有人提出用数据虚拟化将多源数据进行统一逻辑抽象、集成或封装为数据服务发布[22-23],2009年引起一些研究者注意但并没有得到更多关注[24-25]。近年来随着大数据技术的发展,数据虚拟化再次得到重视。一般性来说,虚拟化是指对物理资源的透明模拟仿真。它将物理资源和逻辑资源相分离,使用户仅与逻辑的虚拟资源进行交互。因此物理上多个数据源可能存储在各处,而数据虚拟化技术并不改变数据源的物理存储位置,但是在逻辑上进行集中以便于数据管理和使用。数据虚拟化技术能够隐藏数据存储的相关技术细节及数据源位置等信息,为用户提供统一的数据服务访问层,实现数据即服务的目标。
数据虚拟化不管是作为大数据时代DaaS的一项关键技术还是一种独立的数据集成与管理方法,都是为数据消费者提供灵活的、多角度和全方位的公共数据访问。随着用户业务需求、云应用的扩展、大数据应用场景及数据复杂性的增长,数据虚拟化将成为一种主流的数据集成管理及用户交互技术。理论上讲,数据虚拟化平台追求的最终目标是不仅保证数据的有效共享,还提供数据分析和挖掘服务,让各种技术性细节都“不复存在”,使用户可以专注于解决业务应用问题。
1数据虚拟化的概念
1.1数据虚拟化的概念
数据虚拟化是针对异构、多源、多所有者的数据集,通过对数据资源的逻辑虚拟化,实现数据的集成管理并提供统一的访问接口,以便为各种数据消费需求提供跨数据源整合的数据服务。数据消费者不用关心数据从哪些数据源来,如何进行集成,以及数据的存储位置与方式、访问接口等细节,数据虚拟化将这些技术细节对用户应用隐藏,通过一个逻辑抽象层集成管理、整合各个数据源。数据的清洗、转换与加载在逻辑抽象层完成,实现用户以完全透明的方式访问所有的数据源。同时,数据处理整合的周期变得更短更灵活,并且能够确保数据的统一访问、建模、部署、优化和管理,逻辑上就像统一的一个数据资源,用户只需通过统一的接口进行访问即可[15,26-27]。
如图1所示,来自于企业、网络、感知、社交等等对象产生或提供的数据源,如企业销售数据、网站交易数据、统计数据等,具有数据多样化、异构化、分布式、不同开放性等特点,数据虚拟化系统提供跨数据源、跨平台的数据集成、管理与整合服务,为各种应用需求提供所需的数据服务。
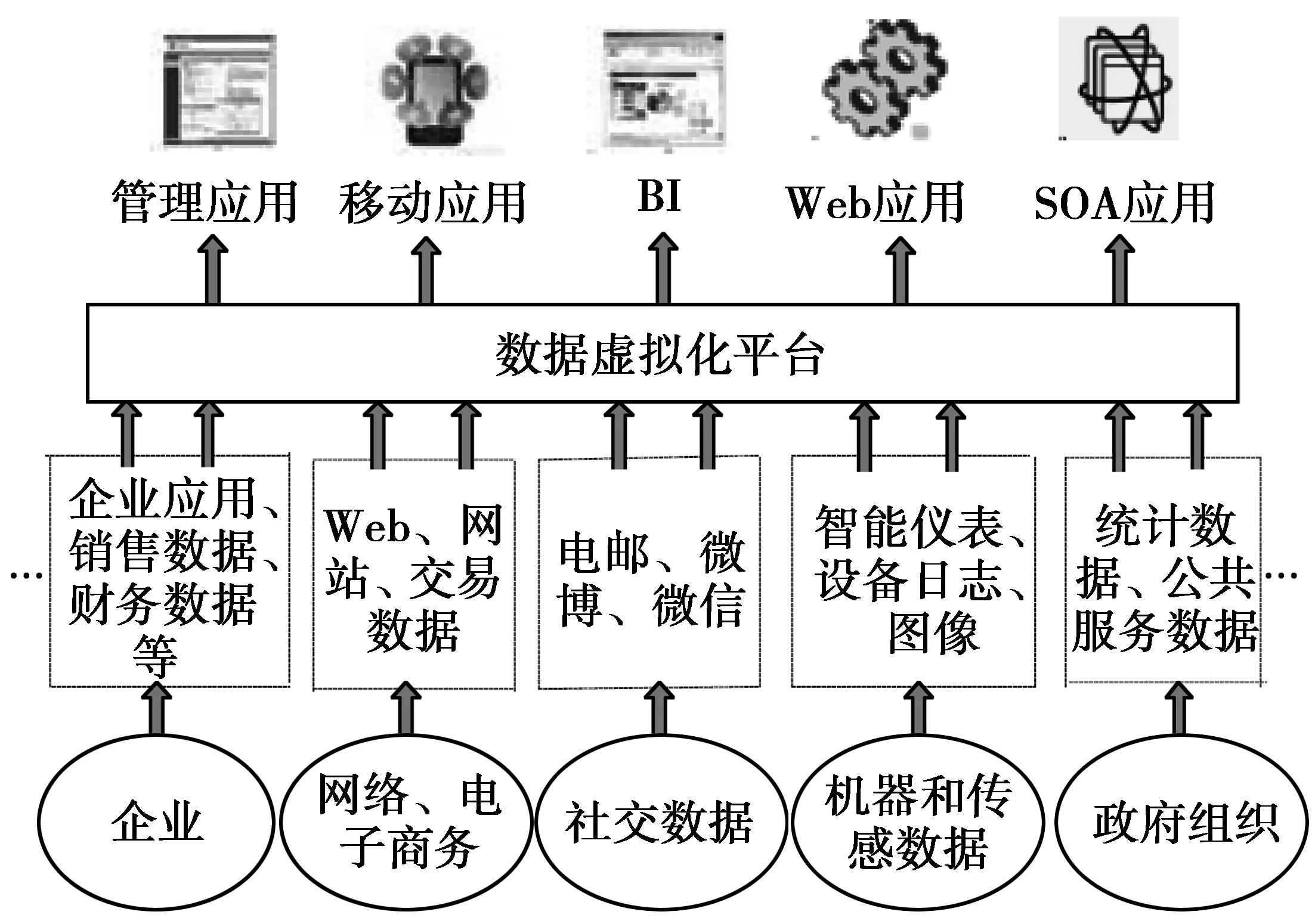
图1 数据虚拟化概念图Fig.1 Conceptual data virtualization
1.2数据虚拟化的应用
通过数据虚拟化,对数据消费者而言,不需提取和存储大量的异构数据集,只需查询请求已发布的数据服务,然后通过对应的APIs查询获取所需数据资源,从而大大简化用户对各个分散数据源信息的访问。
数据虚拟化在数据质量、缓存、查询处理等方面也有了较大的改善。通常在数据集成中引起数据质量问题的根源是对源数据的多次复制转移,而数据虚拟化恰恰从根本上解决了这个问题。数据虚拟化通过逻辑抽象层实现源数据的共享,而且不需关心数据源的位置,避免了数据多次复制、转移、加载过程导致的数据不一致等问题,从而提高了数据质量,降低数据出错的风险[28]。
在数据集成方面,郭树盛等[29]提出一种基于数据虚拟化的新型TEL方法,利用数据虚拟化创建虚拟表,在数据抽取和加载之前完成虚拟转换任务,避免应用临时数据存储区来暂存抽取过来的多源数据,减少数据缓存压力。此外文中还针对传统ETL(extract-transform-load)中存在的数据临时存储、查询响应慢问题,提出基于数据虚拟化的SeaBase架构(SeaBase是一个关系云数据库而非一组数据库的联邦)。由于SQL(structured query language)查询中可能包含不同应用的部分相同数据,利用数据虚拟化在SeaBase中缓存元数据而非源数据,一方面减少查询的响应时间,一方面也优化了数据存储。所以,数据虚拟化在数据集成方面带来了很多优势,为数据集成提供了一个新的方向。
数据虚拟化在未来将有广泛的应用。对于企业而言,通过数据虚拟化在数据仓库、应用程序、文本数据等数据源之上建立整合所有系统信息的数据层,可以减少数据的存储和维护成本,避免企业内部及外部数据孤岛的存在。对于一些难以用数字解释和认知的对象,如人类复杂多变的表情不能用单纯的数据进行准确表达,将数据虚拟化应用于反映认知对象信息的海量数据分析,有助于快速进行认知和决策。另外,通过数据虚拟化可以将多源数据进行整合,并以数据服务的方式发布到外部,这样就会催生出大量新的数据服务和应用。
2数据虚拟化系统架构
从用户应用的角度出发,我们认为数据虚拟化系统架构应该包含3层:应用层、数据虚拟化层和源数据层。其中,数据虚拟化层包括数据虚拟化平面和管理平面,二者相互结合执行全方位的查询、处理、集成和管理功能。数据虚拟化系统架构如图2所示。
2.1应用层
应用层主要是面向前端各种各样的数据查询访问应用,将用户的查询请求传递到数据虚拟化层。系统为数据消费者的查询请求提供多种访问接口,用于访问数据虚拟化系统,如某些数据消费者可以用JDBC/SQL接口访问,另一些数据消费者可以采用MDX(multi-dimensional expressions)接口或基于SOAP(simple object access protocol)接口访问相同的数据服务,对数据消费者而言可以根据自己确定的访问方式发起查询请求。

图2 数据虚拟化系统架构图Fig.2 Architecture of data virtualization system
2.2数据虚拟化层
数据虚拟化层是整个数据虚拟化系统的核心,包括2个平面:数据虚拟化平面和管理平面。其中,数据虚拟化平面包含4个层次的内容,完成数据的抽象、元数据建模、数据源映射、查询驱动与响应等功能;管理平面进行系统配置、管理、监测、安全、数据检查与维护等工作。下面对数据虚拟化平面及管理平面分别进行介绍。
2.2.1数据虚拟化平面
1)查询响应层。该层针对用户的查询需求,主要任务是制定最佳的查询处理策略和性能优化措施。其中处理策略是数据虚拟化系统根据用户查询请求对目标数据的访问方式给出执行方案与流程;优化器是系统确定数据访问方式之后,对查询过程作出优化以提高查询效率。
2)数据服务层。数据虚拟化系统面向用户会创建各种数据服务。数据服务的最常用对象是数据视图或虚拟表。整体上看,数据虚拟化系统中会定义2种类型的表:即虚拟表和数据封装表。由于不同的数据源所有者会开放全部或部分的数据给虚拟化系统,这些开放数据可能是原始数据,更多的是加工后的数据。封装表对应于不同的数据源,实现对开放源数据的接口封装,并作为这些数据源的代理供虚拟化系统调用。
在数据服务层进行数据视图/虚拟表的定义、认证和授权;数据服务的封装、发布与组合。视图/虚拟表的定义是建立在封装表或其他虚拟表之上,虚拟表之间可以进行组合与嵌套,虚拟表在定义之后可以作为一种数据服务发布出去。数据服务更多关注数据资源的获取与集成方式,而虚拟表的定义关注的是数据本身,因此数据虚拟化系统可以以虚拟表的方式呈现数据服务所需的底层数据。
3)元数据组织层。数据虚拟化系统不会存储数据源的物理数据,但是针对不同的数据源开放数据,需要对开放数据源的元数据进行组织存储与管理,并面向数据服务层作为其定义数据视图或虚拟表的基础。针对用户的查询请求,高性能的元数据组织、存储与快速查找是保证用户获取所需数据资源的关键。该层主要包括2个方面的内容:元数据的抽取、存储与元数据组织模型。
4)数据映射层。数据映射层实现虚拟表到数据源的映射,从而保证数据虚拟化平台向数据消费者交付正确的数据。在此应该理清虚拟表、映射与封装表三者之间的关系。虚拟表是建立在封装表基础之上,而封装表是以数据源为基础的。封装表与数据源之间是多对一的关系,根据一个数据源可以定义一个或多个封装表。定义虚拟表的过程也是定义映射的过程,在封装表基础上定义虚拟表。映射对于虚拟表而言相当于查询定义,包含虚拟表的结构(行、列选择;列转换;表名称改变;分组等)、数据如何被转换为虚拟表的内容等。如果没有映射,虚拟表就是一个没有内容的空表。因此,要保证正确的映射,必须正确分析封装表中数据间关系,保证从数据源到封装表再到虚拟表的定义是准确的。数据虚拟化系统中也允许少量虚拟表在起初不定义映射,它们是从数据消费者角度来定义的(自顶向下),因此定义时只关心数据消费需求而不考虑数据源表中数据类型、列间关系等,但是在后期必需执行映射的再定义。
总结来说,当用户发起一个查询请求,查询引擎确定查询策略并进行查询结果计算、优化及结果响应。若数据服务层没有预先定义该查询对应的虚拟表,则元数据组织层需根据系统存储的元数据信息对查询所需的相关元数据进行组织,生成对应的临时虚拟表。数据映射层实施相应虚拟表与封装表的映射,进而访问底层数据源。
2.2.2管理平面
管理平面的目标是通过配置、监测、管理控制等手段支撑整个虚拟化系统的安全、可靠、高效运行。通过对数据虚拟化系统的配置,完成生产、备份、故障切换等任务。数据虚拟化平台中的整合管理工具支持软件供应,对源数据访问的授权,与LDAP(lightweight directory access protocol)的整合以及其他安全工具等。系统管理工具管理服务器会话、数据服务、元数据等。
针对数据虚拟化平面的4个层次,管理平面也要完成对应的管理功能。对于数据映射层而言,要实现每个应用所需数据的映射,管理层必须实现对封装表、源数据、源数据间关系的管理;在元数据组织层,管理环境要实施对元数据的清洗、一致性检测等任务,保证元数据缓存的高效性;在数据服务层,管理环境要完成对虚拟表或数据服务组合、更新过程的维护等,部署管理器完成对数据服务的扩展部署,确保其持续可用;针对查询响应层,控制器、监测器、管理器等共同作用保证整个查询过程的正确实施。
2.3源数据层
源数据层针对各个数据所有者提供的多源异构数据源进行统一的接口管理,实现数据虚拟化系统中各种不同数据源的访问细节对用户进行屏蔽。通过ODBC/JDBC,JSON,API等接口,实现源数据的获取和传输,最终完成用户所需数据资源的交付。
特别注意:源数据层只是对各种物理数据源的访问接口管理,并不需要了解具体的物理源数据的组织、存储及管理方式;物理数据源由所有者管理,并根据自身策略来开放全部或部分源数据的视图给数据虚拟化系统。
3数据虚拟化的研究问题
一个完整的数据虚拟化系统应具备创建视图/虚拟表、提供数据服务、优化联合查询、数据缓存、以及细粒度的安全性等能力,使用户在不同数据源中发现数据、检索与访问数据。虽然数据虚拟化会在很大程度上能够提高数据集成的灵活性和敏捷性,如用户通过单一接入点访问不同数据源的数据、数据服务面向所有的数据消费者、避免数据物理转移、提高数据使用率等,但是仍然存在一些问题与挑战需要研究解决。
3.1异构数据源的集成
不同数据源的数据可能采用不同结构的数据,包括结构化、半结构化与混合结构数据。如有的数据集采用关系数据模式,有的采用HTML/XML文件,有的采用日志格式文件等。这些异构的数据源是数据统一集成中必然存在的巨大挑战。一些研究者从不同角度出发进行研究,例如,改进和扩展查询语言,将查询请求划分为多个子查询,基于语义相似性对元数据融合等[30-31]。数据虚拟化面向的是多种不同应用,若对每类应用的查询,分别优化其查询语言则会影响整个数据虚拟化平台的效率,因此数据虚拟化平台提供多种访问接口对来自不同数据源的数据进行统一存取或访问。例如,对于关系数据库SQL Server,Oracle,Access,Excel等利用ODBC接口通过SQL语言访问;对于web应用程序则可以用REST或JSON接口等,以便屏蔽数据源数据模型的异构性,提供对数据的统一访问。解决数据源的异构性是保证数据服务的基础,但是由于数据源的多样性及复杂性,可能需要开发和改善更多种访问接口,所以对于数据源的异构性问题不容小觑。
3.2异质数据的集成
对于数据异质性问题,Sujansky[32]从结构差异、命名差异、语义差异和内容差异4个方面分析了多源数据的异质性,如数据格式中存在多种日期与时间戳的格式,相同的数据在不同的数据源中有不同的定义等,因此数据异质性处理不当会导致集成数据的质量急剧下降。一些解决方案通过将数据虚拟化、抽象化,用一种统一的描述语言(如XML)或代码生成技术对所需数据进行处理或创建虚拟表、自动生成数据服务[33-34],对用户而言屏蔽掉了底层数据的存储格式、语义等方面的差异,一定程度上解决了这一问题,但是仍没有通用的数据模型。
由于XML语言易于操作、理解、跨平台可移植性等特点,很多数据虚拟化平台采用XML语言对数据进行统一描述,如文献[35]从数据描述方式的通用性出发,提出一种基于XML语言的DIMs(data information model)数据信息模型,并满足数据模型的可移植性。
解决数据异质性是进行元数据组织,创建可重用视图/虚拟表的前提。值得注意的是,由于底层数据模型的差异,在转化为统一数据格式时,如何保证数据的正确、完整、一致性,从而确保数据映射的准确性,这是急需解决的一个关键问题。
3.3数据映射
在图2所示的数据映射层,数据映射对查询到准确的源数据十分重要。基于一个数据源可以定义多个封装表,基于一个封装表也可以定义多个虚拟表。由于底层数据源的复杂多样性,分散的数据源间不可避免地会出现数据重复,建立的封装表间也会出现数据重叠现象。对查询而言,同一虚拟表可能会产生多个映射,进而引发底层数据源中相同数据的重复查询,导致查询的整体效率下降[36-38]。这个问题涉及到封装表与映射策略,在定义封装表及映射过程中,要考虑到源端数据中的重复数据现象,对于基于不同数据源创建的有重叠数据的封装表是进行舍弃还是有效地合并?此外对于自顶而下定义的虚拟表,如何根据查询需求来正确定义映射?在保证数据消费者查询到所需数据的同时又避免重复数据查询,这是实现数据高效及准确映射时面临的挑战。
3.4元数据组织模型
类似于数据库管理系统,元数据也是虚拟化系统运行的核心。在元数据组织模型方面,目前的数据组织模型中,有些只关注某种特定应用或服务本身,没有考虑数据源间的数据关系,导致用户在查询时不得不对数据描述及组织方式进行分析,再通过编程查找底层数据源,这对于希望简单快速地获取所需数据资源的用户而言过于复杂[39-41]。如文献[39]在数据即服务思想基础上,针对传统HTML数据模型在用户查询方面的不足,提出一种概念信息模型DEMODS(description model for DaaS ),该模型隐藏了服务自动查询方式,将各数据源的数据交予数据组合和分析工具,对用户而言不用关心中间查询的操作。文献[40]针对铁路分布式系统的信息转换、数据共享中存在的数据模型的异质性,提出一种基于XML的三维元数据组织模型,描述了不同系统中数据间关系,并实现不同数据模型与该元数据组织模型间的映射。
针对一个数据虚拟化系统,合适的元数据组织模型是关键。根据用户查询需求及源数据间关系,对元数据进行分析、重新归类,建立结构性与关联性良好的、通用的元数据组织模型,特别是在数据服务层没有预先定义虚拟表或数据服务的情况下,元数据组织模型对于及时快捷的数据交付十分重要。目前虚拟化系统中的元数据组织模型还没有统一的标准,由于应用需求的灵活多样性,研究合适的元数据组织模型非常关键。
3.5数据服务
大数据技术的创新及DaaS模式的发展不仅促进了数据服务的潮流还推动了组合数据服务的研究,即多个基本数据服务通过关联可以组合成满足业务需求的复合数据服务。文献[42-44]针对DaaS组合服务中存在的数据结构的不兼容、数据隐私问题进行了研究,并提出了相应的解决方法。数据虚拟化系统同样支持数据服务间的组合,在组合过程中,由于不同数据服务中数据属性、数据隐私程度、数据结构等的不同,也存在数据结构的不兼容、数据质量下降、数据访问权限差异等问题,目前数据虚拟化方案对这方面的研究较少,大都是用户在利用相应的分析组合工具进行处理,这增加了用户的负担。
由于数据虚拟化系统创建的主要对象是数据服务,未来的研究中可以将数据虚拟化系统与DaaS模式融合,将数据虚拟化系统创建的数据服务作为基本服务,通过DaaS将基本数据服务模式进行合并、删除、排序、数据结构调整等,组合成新的数据服务,在减少用户操作的同时保证组合数据服务的质量。
另外,对于非关系数据库,非结构化的数据内容而言,如何创建数据服务,能否以虚拟表的形式呈现各种底层数据源的查询,这也是创建数据服务中的一个重要问题。为了保证数据服务的持续可用,数据虚拟化系统需要对虚拟表进行更新,涉及到虚拟表如何根据底层数据源的变化进行自动即时更新。针对数据服务生成的虚拟表,如何保证更新的一致性及效率问题都是需要研究的重要问题[45-46]。
3.6查询优化
查询优化的目标是提高用户获取所需数据资源的效率,也是数据虚拟化系统中的关键问题。一些研究利用中间件思想,将查询优化建立在数据模型基础上。通过对数据的分析挖掘提取出能够表示数据属性、数据间关系的最少元数据,通过访问元数据缩小数据的查询范围从而减少查询响应时间,优化查询[47],这也从另一个角度说明了元数据的质量及组织模型的重要性。也有一些研究通过优化查询系统的性能,提高查询效率,如文献[48]通过在存储系统中加入一组丰富的硬件加速引擎来提高对存储数据的并行处理能力。一些企业如Cisco,Composite利用基于规则或成本的优化器对每个查询请求制定最佳查询方案,并利用扫描多路技术、约束传播技术、并行处理技术等优化网络资源和数据库,从而保证目标数据及时快捷地交付[49]。
目前数据虚拟化系统常用的一些查询优化技术有Query substitution, SQL pushdown,Parallel processing,Distributed joins,Ship joins,SQL override等。这些技术针对不同的应用场景,在某些方面也存在一定的限制,如Query substitution主要应用于嵌套虚拟表的查询;SQL pushdown不能用于底层数据源为序列文件或XML Web服务;Ship joins一般用于合并2个不同的数据源[50-52]。
由于应用的多样性,没有一种查询策略能够适用于所有的应用场景。此外在提高查询效率方面,除了应用这些优化技术,对于一些特定的查询应用,有时需要将查询请求转化为另一种查询语言。
从另外一个角度来看,应用缓存技术对于提高系统查询性能有极大的裨益。数据虚拟化系统通过提供灵活可扩展的缓存机制,针对底层数据源进行相关数据的缓存,对于查询而言,可以从缓存中查找数据,加速查询并减小底层数据源的查询负载。此外,为了保证缓存数据的一致性和新鲜度,还必须根据底层数据的变化即时更新缓存,这会涉及到数据一致性、更新效率问题。
3.7系统扩展性
数据虚拟化系统作为一种平台,新的数据源、应用请求、数据结构等会持续加入,系统必须具备良好的扩展性。
新的数据所有者会开放数据源并注册到系统平台,原有的开放数据源也会全部或部分注销,这样会引起系统内的元数据组织、虚拟表定义、数据映射、数据缓存等等面临重构问题,系统必须具备在线添加、修改、更新能力,如何提高系统的扩展性与伸缩性是一个重要问题。
由于用户的应用查询需求是无法预测的,要保证数据查询的性能,尤其是在处理一些大容量数据时,必须考虑到系统规模扩展后带来的性能挑战。在设计与开发数据虚拟化系统的早期阶段,就需注意考虑数据查询处理过程的性能与相关解决方案的可扩展性,以提高数据虚拟化系统的扩展性及查询性能。
另外,在数据源不断地更新与数据消费者访问规模增长的情况下,如何确保数据源、封装表与虚拟表的同步性、数据一致性,并保证所有数据消费者的QoE体验,这也是数据虚拟化系统需要考虑的重要课题。
3.8数据安全
数据安全包括数据的认证、授权和加密,认证和授权主要是针对用户而言的,而加密则是从数据本身考虑的,数据只有在安全的基础上实现有效的共享才会产生更大的价值[53-55]。数据虚拟化系统针对不同应用的相同数据服务实行不同的认证和授权机制,这一特性对数据安全又有新的要求,如查询与数据源间的安全通信、跨平台/跨系统访问的数据安全等。
当用户进行数据请求访问时,数据虚拟化系统会对用户凭证(如用户ID、密码等)进行检测。不同的用户即便是对相同的数据元素的访问权限也是不同的,如对于一个虚拟表,有些用户可能只具有该表部分内容的访问权限。需特别注意的是数据虚拟化系统只执行数据消费者权限的检测,确定用户对数据的访问权利,而源数据访问的授权工作则是由底层数据源的所有者决定的,二者的访问权限必须区分开。有些底层数据源有自己的安全访问机制,对数据消费者而言,要实施对源数据的访问需要具备虚拟表与底层数据源的两层访问权限;也有一些底层数据存储没有定义安全机制,对上层数据访问是完全公开的,用户只执行虚拟表的访问权限。因此,用户凭证的安全保存机制、合适的授权机制、安全认证性能等都是需要考虑的问题。
针对数据服务访问权限的定义也在一定程度上限制了用户查询数据的范围,因此在定义数据服务时也需要考虑相应的安全机制。但是从另外一方面来说,过于复杂的安全机制也会影响虚拟化系统在查询、处理数据时的性能。因此在设计数据服务时如何进行安全与性能的折衷将是一个挑战。
3.9系统管理
从图2中可以看出,数据虚拟化系统实质上也是一个数据共享的平台,它以一种更简单敏捷的架构提供数据服务,也必需提供对整个数据虚拟化环境的良好管理,解决由谁负责共享的基础架构,谁负责共享的数据服务等问题[24]。数据虚拟化管理平面需要多种系统管理工具,对系统运行过程实施管理、监控,如监测查询的数量、查询性能、系统的可用性、缓存的使用、缓存更新的速率等,这些都是需要考虑的问题。
4结束语
数据虚拟化的实质是数据联合及集成。对数据消费者而言,数据虚拟化平台将数据整合与集成,为各种用户提供所需的数据服务。对于数据提供者而言,数据源和存储位置是对用户隔离的,数据提供者对数据进行完整或部分开放以供用户共享。数据虚拟化需要屏蔽掉各数据源的异构特性,用户不用关心数据源位置也不用自己去进行数据转换和集成,通过数据虚拟化平台只需用统一的访问规范和接口,即可获取所需各数据源的数据。此外,利用虚拟化系统的整合功能,将数据资源进行加工处理,最后以各种数据服务的方式呈现出来,这也是数据虚拟化的魅力所在。
数据虚拟化平台可以与SOA(service-oriented architecture)架构结合,通过创建、发布数据服务和组合服务提高应用开发效率并简化服务维护。这样,则数据虚拟化系统将成为一个数据交换平台,各类应用所需的源数据在平台中进行按需整合、集成,或者通过发布数据服务或视图到外部世界进而催生出新的应用,使大数据的价值发挥到最大。
随着大数据应用范围的不断拓展,混合云中的大数据存在巨大的数据异构及异质性挑战也将推动数据虚拟化这个领域方向的发展。当然,未来数据虚拟化之路能够走多远,将取决于用户业务需求和大数据环境的复杂性。此外,还取决于用户对风险、复杂性和开放、安全的承受程度。
当然,数据虚拟化也并不适合或解决所有的数据集成问题,例如对于数据仓库或数据集市等某些特定应用案例,通过 ETL 或 ELT 有时可以提供更好的解决方案。某些情况下,混合的解决方案更加有效,所以要根据具体的数据资源、业务或数据消费者的特点正确进行数据虚拟化,不能过多的虚拟化也不能虚拟化不够。
参考文献:
[1]BATINI Carlo, SCANNAPIECO Monica. Data Quality Issues in Data Integration Systems[M]∥Data and Information Quality. Switzerland: Springer International Publishing, 2016:279-307.
[2]ZHANG X, XIANG S. Data Quality, Analytics, and Privacy in Big Data[M]∥Big Data in Complex Systems. Switzerland: Springer International Publishing, 2015:393-418.
[3]KETTOUCH M S, LUCA C, HOBBS M, et al. Data integration approach for semi-structured and structured data (Linked Data)[C]∥2015 IEEE 13th International Conference on Industrial Informatics (INDIN). Cambridge :IEEE,2015:820-825.
[4]CHEN M, MAO S, LIU Y. Big Data: A Survey[J]. Mobile Networks & Applications, 2014, 19(2):171-209.
[5]KHAN N, YAQOOB I, HASHEM I A, et al. Big data: survey, technologies, opportunities, and challenges[J]. The scientific world journal, 2014(2014):1-18.
[6]DEV D, PATGIRI R. A Survey of Different Technologies and Recent Challenges of Big Data[C]∥International Conference on Advanced Computing, NETWORKING and Informatics. India:Springer,2015:537-548.
[7]GONG Y, YING Z, LIN M. A Survey of Cloud Computing[C]∥Proceedings of the 2nd International Conference on Green Communications and Networks 2012 (GCN 2012). Berlin Heidelberg: Springer, 2013(3):79-84.
[8]BAHRAMI M, SINGHAL M. The Role of Cloud Computing Architecture in Big Data[M]∥Information Granularity, Big Data, and Computational Intelligence. Switzerland: Springer International Publishing, 2015:275-295.
[9]SANGEETHA K S, PRAKASH P. Big Data and Cloud: A Survey[M]∥Artificial Intelligence and Evolutionary Algorithms in Engineering Systems. India: Springer, 2015:773-778.
[10] MANJAIAH D H, SANTHOSH B, PINTO J L J. BigData: Processing of Data Intensive Applications on Cloud[C]∥Computational Intelligence for Big Data Analysis. Switzerland: Springer International Publishing, 2015:201-217.
[11] Sá J O E, MARTINS C, SIMES P. Big Data in Cloud: A Data Architecture[M]∥New Contributions in Information Systems and Technologies. Switzerland: Springer International Publishing, 2015:723-732.
[12] MANOHAR N. A Survey of Virtualization Techniques in Cloud Computing[C]∥Proceedings of International Conference on VLSI, Communication, Advanced Devices, Signals & Systems and Networking (VCASAN-2013). India: Springer, 2013:461-470.
[13] SI S M W, AYE H M, AUNG T N. A Study on the Effects of Virtualization on Mobile Learning Applications in Private Cloud[M]∥ Genetic and Evolutionary Computing. Switzerland: Springer International Publishing, 2016:167-175.
[14] TOFIGH T, ADIBI S, MOBASHER A, et al. Novel approach to big data collaboration with network operators network function virtualisation (NFV)[J]. International Journal of Parallel Emergent & Distributed Systems, 2014, 30(1):65-78.
[15] YASKIN S. Thoughts on Big data and Data Virtualization [EB/OL]. (2012-12-22) [2016-05-24]. http:∥cloudcomputing, sys-con.com/node/1803581.
[16] XIAO L, JIANG W, CHEN F X, et al. A Surveyof Cloud Computing Data Virtualization Service[M]∥Applied Mechanics and Materials.[s.l.]:Trans Tech Publications Inc, 2014(441): 1016-1019.
[17] HE P, WANG P, GAO J, et al. City-Wide Smart Healthcare Appointment Systems Based on Cloud Data Virtualization PaaS[J]. International Journal of Multimedia & Ubiquitous Engineering, 2015, 10(2):371-382.
[18] YU J, BAUMANN P, CROMPTON S, et al. Facilitate earth science data interoperability using the SCIDIP-ES data virtualization toolkit[J]. Earth Science Informatics, 2015, 8(3): 711-719.
[19] XU X, YANG J, TANG Z. Data Virtualization for Coupling Command and Control (C2) and Combat Simulation Systems[M]∥ Advances in Image and Graphics Technologies. Berlin Heidelberg: Springer, 2015:190-197.
[20] DELEN D, DEMIRKAN H. Data, information and analytics as services[J]. Decision Support Systems, 2013, 55(1):359-363.
[21] SARKAR P. Data as a Service : A Framework for Providing Reusable Enterprise Data Services[M]. [s.l.]:Wiley-IEEE Computer Society Press, 2015.
[22] WENG L, AGRAWAL G, CATALYUREK U, et al. Anapproach for automatic data virtualization[C]∥High performance Distributed Computing, 2004. Proceedings. 13th IEEE International Symposium on. [s.l.]: IEEE, 2004: 24-33.
[23] DINIZ B, NOGUEIRA D L, CARDOSO A, et al. Assessing Data Virtualization for Irregularly Replicated Large Datasets[C]∥Cluster Computing and the Grid, 2006. CCGRID 06. Sixth IEEE International Symposium on. [s.l.]:IEEE, 2006, 1: 505-512.
[24] Van der LANS R. Data Virtualization for business intelligence systems: revolutionizing data integration for data warehouses[M]. UK: Elsevier, 2012.
[25] HOPKINS B,CULLEN A,GILPIN M,et al.Data virtualization reaches the critical mass[EB/OL].(2011-06-15) [2016-05-23].https:∥www.forrester.com/report/Data+Virtualization+Reaches+Critical+Mass/-/E-RES59322.[26] DAVIS J R, EVE R. Data Virtualization: Going Beyond Traditional Data Integration to Achieve Business Agility[M]. [s.l.]: Nine Five One Press, 2011.
[27] PULLOKKARAN L J. Analysis of data virtualization & enterprise data standardization in business intelligence[D].USA:Massachusetts Institute of Technology,2013.
[28] LOSHIN, D. Effecting data quality improvement through data virtualization[EB/OL]. (2014-06-16)[2016-05-23].http:∥dataqualitybook.com/kii-content/DataQualityDataVirtualization.pdf.
[29] GUO S S, YUAN Z M, SUN A B, et al. A New ETL Approach Based on Data Virtualization[J]. Journal of Computer Science & Technology, 2015, 30(2):311-323.
[30] MUHAMMAD Intizar Ali, REINHARD Pichler, HONGLINH Truong, et al. DeXIN: An Extensible Framework for Distributed XQuery over Heterogeneous Data Sources[J]. Lecture Notes in Business Information Processing, 2009(24):172-183.
[31] MOURA A M D C, PORTO F, VIDAL V, et al. A semantic integration approach to publish and retrieve ecological data[J]. International Journal of Web Information Systems, 2015, 11(1):87-119.
[32] SUJANSKY W. Heterogeneous Database Integration in Biomedicine[J]. Journal of Biomedical Informatics, 2001, 34(4):285-298.
[33] ROCHLANI Yogesh R , ITKIKAR A R.Integrating Heterogeneous Data Sources Using XML[J]. International Journal of Advanced Research in Computer Engineering & Technology (IJARCET), 2013, 2(1):126-130.
[34] FOKOUE-NKOUTCHE A B, HASSANZADEH O, KEMENTSIETSIDIS A, et al. Data Virtualization Across Heterogeneous Formats: U.S. Patent 20,160,055,184[P]. 2016-2-25.
[35] PANG L Y, ZHONG R Y, FANG J, et al. Data-source interoperability service for heterogeneous information integration in ubiquitous enterprises[J]. Advanced Engineering Informatics, 2015, 29(3):549-561.
[36] SU S H, HLA K H M S. An efficient ontology approach for organizing and mapping deep Web resources[C]∥ Computer and Automation Engineering (ICCAE), 2010 The 2nd International Conference on. [s.l.]: IEEE, 2010:235-240.
[37] SCHADD F C, ROOS N. Word-Sense Disambiguation for Ontology Mapping: Concept Disambiguation using Virtual Documents and Information Retrieval Techniques[J]. Journal on Data Semantics, 2014:1-20.
[38] LUO Yonghong, CHEN Tefang. A Data Mapping Strategy of Parallel Data Mining in Grid[C]∥ The International Conference on E-Business and E-Government, ICEE 2010, 7-9 May 2010. Guangzhou, China: Reference Publications, 2010:1377-1382.
[39] VU Q H, PHAM T V, TRUONG H L, et al. DEMODS: A Description Model for Data-as-a-Service[C]∥ IEEE International Conference on Advanced Information Networking & Applications. Washington, DC, USA: IEEE Computer Society, 2012:605-612.
[40] WANG H, XU W, JIA C. Metadata-oriented Data Model Supporting Railway Distributed System Integration[J]. Journal of Software, 2012, 7(4):814-822.
[41] HELVOIRT S V, WEIGAND H. Operationalizing Data Governance via Multi-level Metadata Management[M]∥ Open and Big Data Management and Innovation. Switzerland: Springer International Publishing,2015:260-272.
[42] AMAROUCHE I A, BENSLIMANE D, ALIMAZIGHI Z. Enabling Semantic Mediation in DaaS Composition: Service-Based and Context-Driven Approach[J]. International Journal of Information Technology & Web Engineering, 2013, 8(4):1-19.
[43] ARAFATI M,DAGHER G G,FUNG B C M,et al.D-Mash:A Framework for Privacy-Preserving Data-as-a-Service Mashups[C]∥IEEE, International Conference on Cloud Computing.Anchorage,AK:IEEE,2014:498-505.[44] TBAHRITI S E, MRISSA M, MEDJAHED B, et al. Privacy-aware DaaS services composition[J]. Lecture Notes in Computer Science, 2011, 6860(55):202-216.
[45] 张鹏, 韩燕波, 王桂玲. 基于数据服务的嵌套视图动态更新方法[J]. 计算机学报, 2013, 36(2):226-237.ZHANG Peng,HAN Yanbo,WANG Guiling.Implementing Dynamic Nested View Update Based on Data Service[J].Chinese Journal of Computers,2013,36(2):226-237.
[46] HAN Y, WANG G, JI G, et al. Situational data integration with data services and nested table[J]. Service Oriented Computing & Applications, 2013, 7(2):129-150.
[47] HAAS L M, KOSSMANN D, WIMMERS E L, et al. Optimizing Queries Across Diverse Data Sources[C]∥ VLDB 97: International Conference on Very Large Data Bases. 2001:276-285.
[48] PANGAL G, SCHMITZ M B, RAVINDRAN V, et al. Apparatus and method for data virtualization in a storage processing device: US, US 7353305[EB/OL].[2016-05-24]. http:∥xueshu.baidu.com/s?wd=paperuri%3A%2879e397dac9889e8ef005e3b1277dba39%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fwww.freepatentsonline.com%2F7353305.html&ie=utf-8&sc_us=9640895184321966038.
[49] YUHANNA N, GILPIN M. The Forrester Wave?: Data Virtualization, Q1 2012[EB/OL]. [2016-05-26]. https:∥www.em360tech.com/wp-content/files_mf/13419239601888_forresterwavedatavirtualization_ar.pdf.
[50] TELETIA N, HALVERSON A D, BLAKELEY J A, et al. Performing parallel joins on distributed database data: US, US8473483[P]. 2013.
[51] CHEN Y, ZHANG Y Q. A Query Substitution-Search Result Refinement Approach for Long Query Web Searches[C]∥ Ieee/wic/acm International Conference on Web Intelligence, Wi 2009, Main Conference Proceedings. Milan, Italy: Reference Publications, 2009:245-251.
[52] NI Xing-wang. Research on the Semi-join Query Optimization Technology[J]. Journal of Yangtze University(Natural Science Edition), 2014,11(34):55-58.
[53] LI G S. Research on Security Mechanism of Sharing System Based on Geographic Information Service[M]∥ Proceedings of the International Conference on Information Engineering and Applications (IEA) 2012. London: Springer, 2013:345-351.
[54] LEI D, ZHOU K, JIN H, et al. SFDS: A Security and Flexible Data Sharing Scheme in Cloud Environment[C]∥ International Conference on Cloud Computing and Big Data. Wuhan:IEEE, 2014:101-108.
[55] THILAKANATHAN D, CHEN S, NEPAL S, et al. Secure Data Sharing in the Cloud[M]∥Security, Privacy and Trust in Cloud Systems. Berlin Heidelberg: Springer,2014:45-72.
DOI:10.3979/j.issn.1673-825X.2016.04.009
收稿日期:2016-07-05
修订日期:2016-07-19通讯作者:赵国锋zhaogf@cqupt.edu.cn
基金项目:国家自然科学基金(61501075)
Foundation Item:The National Natural Science Foundation of China(61501075)
中图分类号:
文献标志码:A
文章编号:1673-825X(2016)04-0494-09
作者简介:

赵国锋(1972-),男,陕西人,教授,博士生导师,主要研究方向为互联网技术、网络测试与测量。E-mail: zhaogf@cqupt.edu.cn

葛丹凤(1990-),女,河南人,硕士研究生,主要研究方向为网络管理。E-mail:1255349756@qq.com。
(编辑:魏琴芳)
A survey on data virtualization
ZHAO Guofeng1, 2, GE Danfeng1
(1. Institute of Electrical Information and Network Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065,P. R. China; 2. Optical Communication and Network Key Laboratory of Chongqing, Chongqing 400065, P. R. China)
Abstract:Varieties of data sources, gigantic volume, heterogeneous data structures shape the big data, where the data integration plays an important role. However, how to integrate data fast and effectively in big data system remains a big challenge. Data virtualization is characterized by a good potential of data integration, thus, we first introduce its concept and advantages. Then, we propose an architecture including two planes and detail the functionalities of each layers within each plane. To benefit future work in this field, we show some issues and research topics on data virtualization.Finally,we briefly discuss and conclude this paper.
Keywords:big data;data integration;data virtualization
