医保欺诈行为的主动发现
2016-08-06唐璟宜孙有坤周海林
□文/唐璟宜 孙有坤 周海林
(安徽财经大学金融学院 安徽·蚌埠)
医保欺诈行为的主动发现
□文/唐璟宜 孙有坤 周海林
(安徽财经大学金融学院 安徽·蚌埠)
[提要] 针对在医疗行业中存在的医疗保险欺诈行为,应当有合适的方法去及时发现并制止,只有这样才能使医疗保险金能真正落到实处。本文使用主成分分析、K-m eans聚类分析等方法,并运用M A TLA B、SPSS等软件对数据进行分析,并对我国医保行业现状进行分析,为相关部门自动识别医保诈骗提供具体的模型及识别方法。
关键词:医保欺诈;主动发现;主成分分析;K-m eans聚类
收录日期:2016年6月13日
一、数据挖掘预处理
由于本文主要研究的是医保欺诈行为,所以数据处理中只保留所有参保人员,将非参保人员的就诊拿药数据剔除,减少无关数据的干扰。
(一)数据清洗。针对本文的研究目的,有目的地进行数据清洗。首先是删除大量对于本次数据挖掘没有用的数据,只保留相关数据列;其次是对于缺失的必要数据采用数据归约的方法填补空缺。
(二)数据转换。将文本型、字符型数据转换为数字型数据,以方便后续研究。如用“1”和“0”代替性别的“男”、“女”;将出生日期转换为患者年龄等。
二、医保欺诈行为主动发现模型
(一)类型Ⅰ:医保卡持有人已死亡。这是最容易发现的骗保行为,故优先考虑该种类型的骗保行为主动发现。通过MATLAB编程对医保卡和身份证号列进行筛选处理,找到一个医保卡ID对应多个医保手册号的情况。利用MATLAB软件进行筛选,将筛选出的ID利用Excel的vlookup函数查找出对应的身份证号,找出嫌疑人的关键信息。可以将一卡两人用、一卡三人用的医保卡ID和医保手册号筛选出来。而病人也有死亡标志说明,可以查出死亡病人的ID再查找其医保卡消费情况,对比病人的死亡时间以及账单号的交易时间,若病人的死亡时间在前而交易时间在后,则为医保欺诈记录。根据所使用的数据表,暂未发现这类医保欺诈,但仍应该警惕,及时把死亡者的医保卡注销,避免这类医保欺诈的发生。
(二)类型Ⅱ:医保卡持有人未亡。对预处理后的数据进行分析,可以发现病人的医保费用与参保人的年龄、消费频率、消费药品的金额之间具有一定的关联性。本文主要从病人年龄与消费金额、病人消费频率与消费金额两方面的联系,发现异常可疑数据,并针对这些可疑数据进行分析,进一步鉴别其特征,判断是否属于医保欺诈行为。

表1 各个年龄段对应的平均费用及其上限
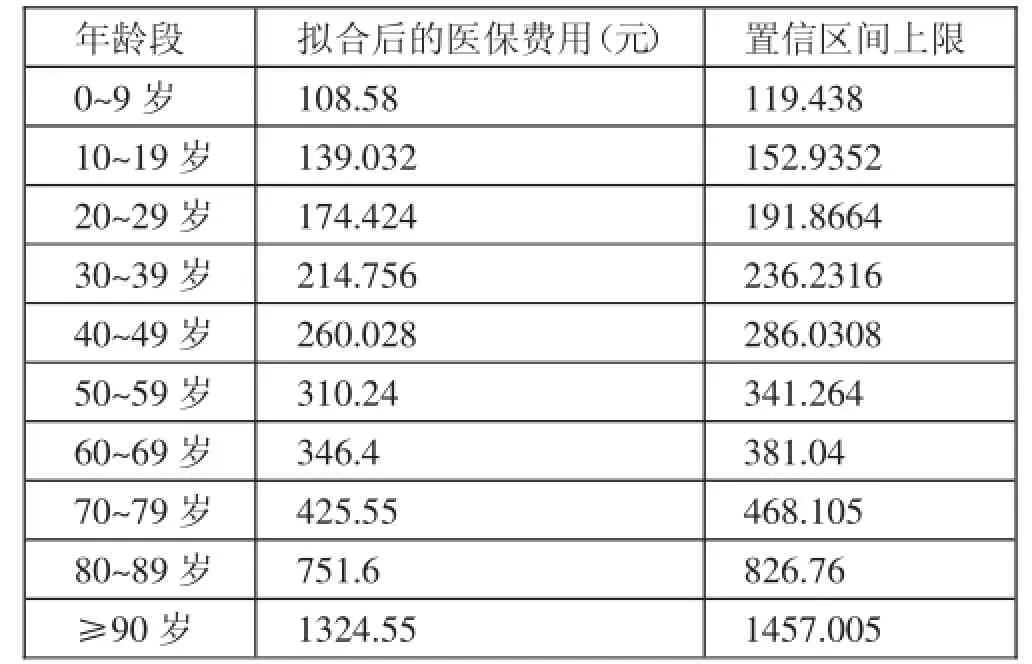
表2 拟合函数计算的各年龄段平均费用及其上限

表3 各聚类对应的案例数(单位:个)
1、模型Ⅰ:年龄医费模型。根据研究的数据对象,建立病人年龄与医保费用的关系模型,使用SPSS软件进行分析。首先将所有参保人的年龄分成十个阶段:0~9岁、10~19岁、20~29岁、30~39岁、40~49岁、50~59岁、60~69岁、70~79岁、80~89岁、90岁以上。在此,根据医保欺诈的特点,医保欺诈的费用越高越有可能存在欺诈行为,故只考虑平均费用置信区间的上限无意义。人为将置信区间设定为向上浮动10%。在EXCEL表中使用分类汇总操作,计算出各阶段医保支付费用平均值及平均费用置信区间的上限,如表1所示。(表1)
利用EXCEL画出图形,通过观测散点的分布情况来确定拟合函数,利用数理统计方法中的多元回归统计方法可以得到因变量与自变量之间的回归关系函数表达式。(图1)
在图中可以发现60岁以上的曲线呈明显上升趋势,于是建立分段函数,分别对0~59岁和60岁以上进行拟合,拟合的回归曲线如图2和图3所示。(图2、图3)
于是建立得到医保费用关于年龄的函数,如下:
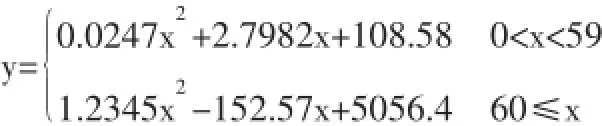
在上述方程的基础上建立初步筛选规则:按病人的年龄找到对应的置信区间,若发现病人的实际花费其所在区间上限,则该病人医保费用花费超过一般标准,具有医保诈欺的嫌疑,将对这些病人进行进一步具体审查。(表2)
2、模型Ⅱ:消费频率与金额模型。由于在医保欺诈中,骗保人通常使用的手段包括两种:一是拿着别人的医保卡配药;二是在不同的医院和医生处重复配药。这些行为使有医保欺诈嫌疑的病人所对应消费记录中,某个医保卡ID对应的药费明细存在记录多、频率大、药费总和高的特点。即消费金额高和消费频率高是医保欺诈一个最大的特征。于是,本文具体研究存在着这两种消费特征的医保记录,具体识别其中的医保欺诈行为,依据此种情况,可以将药费和频率等基于k-means算法进行聚类分析。
K-means算法是以数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。本文使用的K-means算法以欧式距离作为相似度测度,通过对某一初始聚类中心向量的最优分类,得到对应评价指标最小。算法采用误差平方和准则函数作为聚类准则函数。首先在ACCESS中进行数据预处理,再利用SPSS分析数据属性的特征,选择典型数据作为初始聚类中心,进行k-means聚类分析求出每个病人的消费频率与消费药品的总金额。
本文选择四类数据作为初始的聚类中心:1、消费频率高,消费金额大;2、消费频率低,消费金额大;3、消费频率高,消费金额小;4、消费频率低,消费金额小。结果如表3所示。(表3)从表3中可以看出第一类数据含有341个样本,这类病人消费频率高且消费额大,可能存在医保欺诈行为。用这种方法可以快速发现所有有欺诈嫌疑的记录。
3、类型Ⅲ:医师、科室参与欺诈。当找出所有可疑的欺诈记录后,可以通过不同表之间的数据映射关系来找到与嫌疑人员有关的嫌疑科室、嫌疑医生,从而可以确定协助作案的科室医生,便于以后的重点监督和排查。
根据医保诈骗的作案特点,在某些情况下,科室可以通过伪造病历和票据通过医保报销,以骗取医保金,造成某些患者费用和频率较高。为了有针对性地对这类数据进行查找,根据这几个表的映射关系,筛选出与嫌疑人员ID有关的科室并且统计他们与嫌疑人员进行操作的次数,以此进行查找。首先统计原始数据,原始数据有下医嘱科室与执行科室两种科室,在医保诈骗事件中,下医嘱科室的欺诈嫌疑较大,因此重点分析下医嘱科室信息。利用疑似人员的医保卡号筛选出与之相关的科室,并统计出与这些疑似ID进行交易的次数来确定科室的嫌疑度。根据与嫌疑ID交易的次数进行排序,当某些科室的交易次数和与其相邻的科室样本突然发生较大变化,可以此作为分界点,划分出嫌疑科室。与嫌疑科室同理,可以采用同样的方法查询出嫌疑医生。由这种方法,可以找到医保欺诈事件高发的重点科室,这些科室可能本身存在嫌疑,或是较为容易被不法分子利用空隙进行医保欺诈。

图1 各年龄段对应的平均费用散点图

图2 0~59岁医保支付平均费用的回归曲线图

图3 60岁以上医保支付平均费用的回归曲线图
三、医保欺诈数据分析
根据数据处理的结果,发现我国医疗保险存在如下三类的欺诈现象:(1)医疗保险需求方的欺诈违规行为。在现实情况中主要表现有:冒名顶替就医、以药换药、倒卖药品等;(2)医疗保险服务提供方的欺诈违规行为。主要可能表现为:重复收费、虚报医疗费用、倒卖医疗票据等;(3)医疗保险服务提供方与需求方联合的欺诈违规行为。主要的欺骗手段有:在医院挂床、用物充药、帮助提供虚假证明、伪造虚假病历等。其中,第一类行为最为普遍,第二、第三类行为较少,但一旦发生将会发生严重影响。这些行为对我国的医疗保险基金造成严重损失,危害我国医疗保险基金的公平性与公正性。
四、对完善医保制度的建议
(一)进一步改革支付制度。在总额控制支付模式的框架下,应当以总额预付为主,结合多种付费方式的复合型支付制度,综合考虑如按病种、床日、人头、项目付费等因素,从多个角度来合理定价,减少由于药费过高而使参保病人产生的骗保心理,让参保病人住的安心,让医保基金用到实处。
(二)建立医保信息智能网络平台。一个参保病人对应一个电子账户,将病例电子化,详细记录病人的一切看病用药信息。该账户应做到全国甚至世界范围内共享。
(三)完善对医保定点医院的内部管理。合理划分基金管理机构的职责并做到权力制衡,建立医疗服务监督评价体系和奖惩制度。
(四)完善对医保定点医院的外部监督。加大对医保定点医院、医师以及各类机构的违规行为的查惩力度,如发现有医保违规行为,将取消涉案医保医师的执业资质。
五、总结
前人的研究包括采用基于统计回归或神经网络思想的优化改进方法,而这些方法都属于辅助学习方法,需要基于一定量的已知数据,或拥有较为丰富的先验知识,以获取识别因子作为学习材料,用以主动识别其他大量数据中包含的可能欺诈数据。该方法的问题在于欺诈样本点的选取过于依赖人的主观性,对于普遍意义上欺诈数据的识别不具备较强的参考价值。
为避免人工筛选欺诈数据带来的主观误差,需要找到非辅助学习的方法。聚类分析法可以满足这一条件,但传统的聚类分析采用欧氏距离作为分类标准,不足之处在于将各种影响因素的重要程度视为相同的,会造成一些不重要的参量(如年龄)却和一些重要的参量(如病人一个月之内的开药次数)同等的影响着最后的分类。
为解决该问题,本文将主成分分析引进聚类分析,成为基于主成分分析的聚类分析算法。主成分分析模型是一种降维的算法,可以有效地将存在欺骗行为的数据范围缩小化,减少数据的冗余性,并保持数据的有效性。同时,聚类分析能够很好的反映类之间的关系,本文中的各个因素虽然是彼此独立的,但是对于存在欺诈行为的情况时,数据内部会产生相关性,通过聚类分析可以快速有效地掌握它们之间的关系。在改进的主成分聚类分析法中,将这两种统计方法的优势结合,相辅相成,以达到综合评价的目的。
主要参考文献:
[1]殷瑞飞.数据挖掘中的聚类方法及其应用——基于统计学视角的研究[D].厦门:厦门大学,2008.
[2]江小平,李成华,向文,张新访,颜海涛.K-m eans聚类算法的M apReduce并行化实现[J].华中科技大学学报(自然科学版),2011.6.39.
[3]王文华.基于蚁群算法模糊聚类的图像分割[D].重庆:重庆大学,2009.
基金项目:国家级大学生创新项目(编号:201510378153)
中图分类号:D 9
文献标识码:A
