一种不等长的多模态间歇过程故障检测方法
2016-08-06郭金玉袁堂明
郭金玉,袁堂明,李 元
一种不等长的多模态间歇过程故障检测方法
郭金玉,袁堂明,李元
(沈阳化工大学信息工程学院,辽宁 沈阳 110142)
摘要:提出一种不等长的多模态间歇过程故障检测方法。首先,运用局部加权算法对不等长批次数据进行预处理。在训练样本中确定不等长数据的最大可保留长度,利用k近邻信息,通过加权重构出不等长批次缺失的数据点。其次,对等长的训练集构造局部近邻标准化矩阵,运用K-means算法进行模态聚类,使用局部离群因子方法确定第一控制限,并剔除离群样本。最后,对各个模态建立MPCA模型并确定第二控制限。根据各个模态控制限的匹配系数计算统一的统计量和控制限,在统一的控制限下进行多模态故障检测。将提出方法应用于半导体工业过程,仿真结果表明,与传统的故障检测算法相比,本文算法提高了故障检测率,验证了该方法的有效性。
关键词:多模态过程;故障检测;不等长数据;主元分析;算法;模型;局部离群因子;局部近邻标准化矩阵
引 言
在制药、化学、食物和半导体工业中,需要不断提高系统的自动化程度来满足生产操作的平稳、安全等要求,与此同时也使工业过程的复杂性越来越高,系统的安全性面临严峻的挑战。如何对生产过程进行实时监控,及时发现故障成为近年来过程控制领域中的一个研究热点[1]。在过程控制领域中,以大量历史数据为基础的多元统计过程监控方法受到了广泛的关注,形成了一批研究成果[2-3]。多向主元分析[4](multiway principal component analysis, MPCA)和多向核主元分析[5](multiway kernel principal component analysis, MKPCA)方法能够进行间歇过程的检测和诊断。但是对于多工况、多模态间歇过程的检测效果往往不理想。
近年来,许多学者通过不同角度分析多模态工业过程,并提出了多种故障诊断方法[6-7]。为了解决具有非高斯、非线性的多模态间歇过程故障检测问题,He等[8]提出了基于 k近邻(k-nearest neighbor, kNN)的故障检测算法。为了建立单个模型来实现多模态过程的监控目的,华东理工大学的马贺贺等[9]提出一种基于马氏距离局部离群因子(local outlier factor,LOF)的方法进行故障检测。刘帮莉等[10]提出一种基于局部密度估计的多模态过程监控策略。针对间歇过程的多工况和非线性特征,郭小萍等[11]提出一种基于近邻特征标准化(nearest neighborhood feature standardization, NNFS)样本的核特征量故障检测方法,采用近邻方法标准化样本,并基于核方法建立故障检测模型。Deng等[12]提出一种基于局部近邻相似度分析的多模态故障检测方法,将该方法应用到连续过程的故障检测中。郭金玉等[13]在此基础上,提出了一种基于在线升级主样本建模的批次过程 kNN故障检测方法。然而这些多模态故障诊断方法用于间歇过程时,需要假设间歇生产过程数据是等长的,且数据没有污染。
由于间歇过程的生产特点,不同批次的生产周期不同,不可避免地会出现不等长批次问题。解决间歇过程批次不等长问题,通常采用最短长度法[14]。另一种方法是基于统计特征的分块法[15],该方法把不等长的间歇过程分成相同数目的子块,计算每个子块的均值和方差,将这些统计特征组合成一个等长的特征向量,运用主元分析(principal component analysis, PCA)进行过程监视。现场过程数据中不可避免地包含不同程度的误差、测量噪声和系统噪声等,这些问题会给数据带来一定的污染,使得多模态生产过程数据产生局部的离群点[16]。这种离群点会使主元方向发生偏移, 在进行故障检测前,如果不对这类数据进行分析和预处理,就会影响最终故障诊断的准确性。针对间歇生产过程中的批次不等长和复杂多模态过程的故障检测问题,本文提出一种不等长的多模态间歇过程故障检测算法。运用局部加权算法(local weighted algorithm, LWA)进行不等长的预处理。在此基础上,运用局部近邻标准化矩阵(local neighbor normalized matrix, LNNM) 进行多模态间歇过程故障检测。该方法可以避免信息的丢失影响多模态过程的聚类效果[17],同时剔除离群点,通过构造局部近邻标准化矩阵使得多模态间歇过程故障诊断结果更加准确。
1 基于局部加权算法的预处理
在实际的间歇过程中,由于生产要求不同等情况会产生不等长的数据,不等长批次数据的三维描述如图1所示。为了解决间歇过程批次数据的不等长问题,本文提出了基于局部加权算法的预处理算法。该方法是一种有效的数据恢复算法,其充分利用局部的信息,根据一定的规则选择相应的近邻,求出近邻对应的权值,由近邻和权值重构出缺失的数据点。
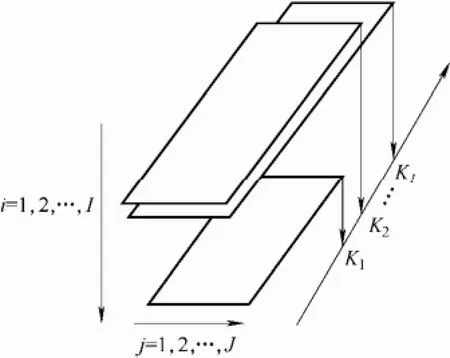
图1 不等长批次数据的三维描述Fig.1 Three-dimensional description of uneven-length batch data
假设在每个批次(i=1, 2, …, I) 时间持续不定的操作循环中,K(K = K1, K2, …, KI)为每个批次的时间长度,每一时刻检测J 个变量,形成了不规则的三维数据集合X,即
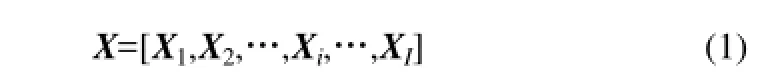
其中,第i个批次矩阵表示为 Xi(Ki×J),Xi∈RKi×J。分别把每个批次矩阵按照时刻的方向展开成批次向量形式,所有批次向量的集合为B,即

其中,Bi∈R1×Ci,Ci=Ki×J,i=1, 2, …, I。
由于每个批次Xi有不同的时间长度Ki,三维数据集合X展开后的轨迹长度Ci是不相同的。所有批次长度按照从大到小的顺序排列成向量L,二维数据矩阵B按照向量 L的顺序进行重新排列,记为B*。
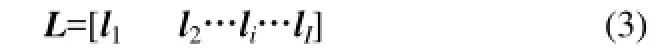
其中,l1≥l2≥…≥li≥…≥lI。
为了有效地利用较长批次的信息,需要将 B*分为完备矩阵F和不完备矩阵M,并确定矩阵的维数D。一般选取最长批次的长度作为矩阵的维数D,即D=l1。在极端的情况下,当满足该条件下的批次样本数小于近邻数k时,需要相应地减少D的大小,选择次长度作为矩阵的维数D,即D=l2,直到满足该条件的批次样本足够多。本文假设取D=li,所有长度大于D的批次按照D的维数进行保留,并归为集合F,而所有维数小于D的批次对缺失的数据点进行定位,将这些位置标记为 NaN。将存在 NaN标记的批次向量归为不完备矩阵M,这样保证了矩阵F和M的维数都相等。假设F中的样本数大小为If,M中的样本数大小为Im,则
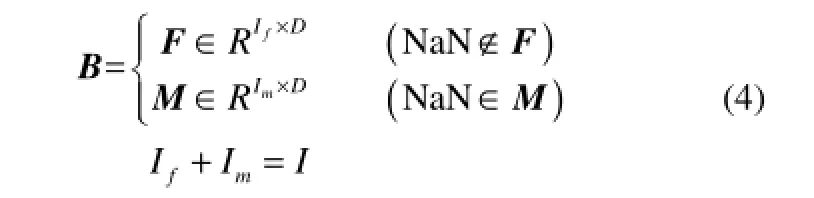
在不完备样本矩阵M中,按照完整性的大小对样本进行排序。这里的完整性是指缺失率的大小。缺失率越大,完整性越小。先对完整性最大的样本M1的缺失数据点进行恢复。假设M1样本中的数据点为lm个,则缺失数据点的个数为D-lm。为了实现选取k个近邻,M1中的lm个数据点组成向量M1,s。根据kNN规则,在F中寻找M1,s的k个近邻,将该向量集合记为矩阵M1,k,其中每个向量的维数均为lm。按照局部线性重构的原理,M1,s可以用k个近邻的重构近似来表示。M1,s的重构表示为

其中,w1,w2,…, wk为样本M1,s的k个近邻重构权值,由它们所组成的向量为W,其中
为了使式(5)中重构后的 M1,s尽可能无偏,需要找到一个最优的 wj使得误差平方和ε(wj)最小。
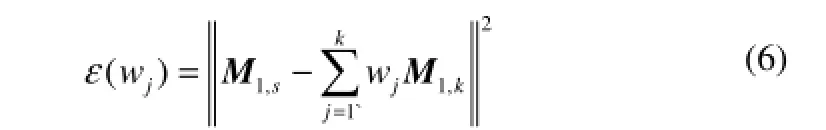
确定最优的wj为

其中,Zj=[M1,1-M1,s, M1,2-M1,s,…,M1,k-M1,s]T,ek,j=[1, 1,…,1k,j]T[18]。
找到权值wj就可以对M1的缺失数据点M1,s进行重构。在F中近邻矩阵M1,k所在的列向量组成新的近邻矩阵 M1,d,其维数为 D。具有缺失数据的M1的加权重构表示为


图1 基于局部加权算法的预处理流程Fig.1 Flow chart of preprocessing based on local weighted algorithm
2 基于局部近邻标准化矩阵的多模态过程故障检测
2.1 局部近邻标准化矩阵(LNNM)
假设 u是U中的一个样本点,为了消除不同变量之间量纲的影响,对各个样本进行标准化。样本的标准化为

其中,us为标准化后的数据点;um为该数据点所在变量的均值;ustd为该数据点所在变量的方差。
经过标准化后的所有批次样本矩阵为Us,其中每个样本有I个近邻。对Us中的样本计算所有近邻到该样本的欧氏距离,并对该距离由小到大进行排序。该近邻的距离矩阵Dk为从矩阵Dk可以看出每个样本都有I个近邻,其中每个样本的最近邻是其本身,对应的近邻距离为零,即di1=0, i=1, 2,…,I。

Dk是每个样本到其近邻的距离矩阵,包含样本之间的距离信息,具有唯一性和独立性。为了充分挖掘距离矩阵Dk与样本U的关系,并消除无关近邻的影响,本文在Dk基础上构造局部标准化距离矩阵Ds。Ds中的每个元素ds(ui, ut) 为
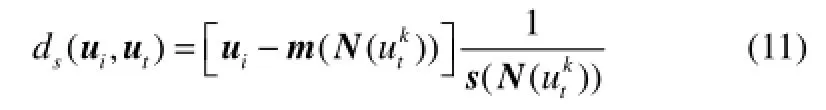
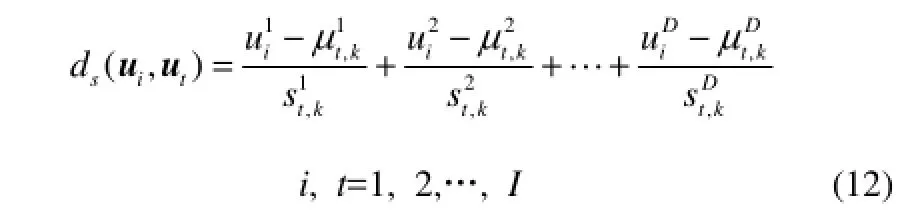
经过式(12)计算后,所有样本之间的距离会重新定义,所有样本的近邻也会发生相应的变化。每个样本到各个近邻的距离由小到大进行排序,该近邻矩阵表示为Dks,即

将建模的批次样本矩阵变换成局部近邻标准化矩阵,使样本特征更加明显。与此同时,原始样本的维数降低为 I。由此可见,这种变换也起到了降低维数的作用。
2.2 模态的聚类与离群点的剔除
K-means 算法是一种广泛应用的聚类算法。本文运用K-means聚类算法对Dks进行模态聚类。假设有e个模态,各模态的中心作为模态标签(r1, r2,…, re)。为了消除样本噪声的影响,需要剔除每类中相似度较低的样本,本文使用LOF方法确定第一道控制限,剔除各模态的离群样本。LOF方法详见文献[9]。
2.3 多模态MPCA模型的建立
假设Xr=Dks,r∈Rnr×I是Dks经过K-means 聚类后的某一模态矩阵,其中r 为该模态的标签,nr为该模态样本的个数,I为样本的维数。对Xr进行主成分分解为
其中,P∈RI×A是最大 A个特征值对应的负载矩阵,T∈Rnr×A是得分矩阵,E∈Rnr×I是残差向量。在进行故障检测时,通常用平方预测误差(squared prediction error, SPE)(也称Q统计量)和Hotelling’s T2来检测过程是否发生异常。
SPE指标衡量样本向量在残差空间投影的变化。模态r的SPE统计量为
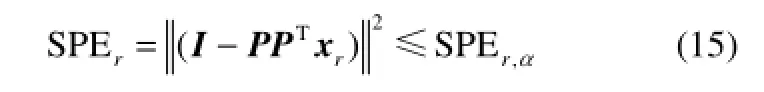
其中,SPEr,α表示置信水平为α的控制限,定义为

模态r的Hotelling’s T2统计量衡量变量在主元空间中的变化,计算公式为

其中,Λ=diag{λ1,…, λA},表示置信度为α的控制限,定义为
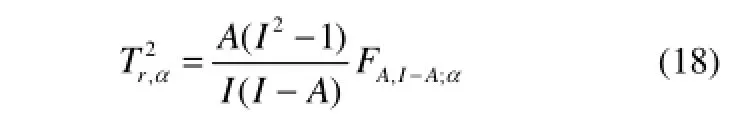
其中,FA,I-A;α是带有A和I-A个自由度、置信水平为α的F分布临界值。
计算出单个模态计量的控制限后,为了使多模态数据进行统一检测,本文选取公倍数的方法确定每个模态的控制限匹配系数,从而达到统一控制限的目的。多模态SPE统计量统一的控制限如下
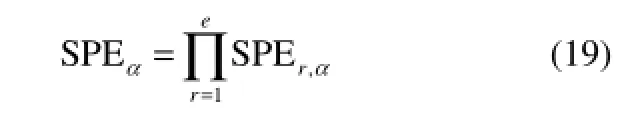
其中,e为模态的总数,第r个模态SPE的匹配系数为

多模态T2统计量统一的控制限如下

第r个模态T2的匹配系数为
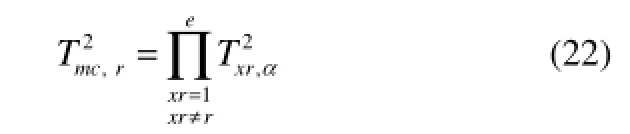
对测试样本运用K-means进行模态聚类,计算所属模态r下的统计量SPEr和T2r,分别乘以匹配系数SPEmc,r和T2mc,r,计算出统一的统计量,达到在统一的控制限下进行多模态过程检测的目的。
3 仿真结果与分析
3.1 半导体生产过程数据
本文应用半导体工业实例——A1堆腐蚀过程的数据比较不同故障诊断方法的性能。半导体生产过程是个典型的非线性、时变、多阶段和多工况的复杂多模态间歇过程。从40个测量变量中选取 17个变量作为检测变量,参见文献[21]。半导体工业数据由3个模态的107个正常批次和20个故障批次构成,其中1~34批次为第1模态,35~70批次为第2模态,71~107批次为第3模态。每个模态分别选取32个批次用于建模,剩下的正常批次作为校验批次用来验证模型的准确性,因此建模批次为96个,正常校验批次为11个,故障批次为20个。
3.2 基于局部加权算法的缺失数据恢复
为了验证本文方法在处理不等长问题上数据恢复的准确性,将该算法与两种常用的数据恢复方法进行比较。常见的两种数据恢复的方法为均值法(mean algorithm, MA)[22]和 EM-PCA[23](expectation maximization-principal component analysis)方法。首先对某个建模批次按最短的长度进行截取。截取后的数据为 Xu,然后构造一定缺失率下的不等长数据,并记录各个缺失点的真实值,使用相对误差和总体平均相对误差来衡量3种算法的恢复效果。各缺失数据点的相对误差为

总体平均相对误差为

其中,ma为缺失数据个数,xu表示恢复后的数据点,x*表示原始数据点。
在半导体数据中任选1个批次,随机产生20‰的缺失数据点,分别运用MA法、EM-PCA算法和LWA算法对缺失的数据点进行恢复,并将3种方法的恢复结果进行对比分析。在LWA算法中,k的选择必须要小于F中样本的大小,且k的值不能太小。如果太小,重构的信息就不充分。在恢复缺失数据时,k选择为8。3种恢复方法的相对误差如图3所示。由图3可以看出,在不同的缺失数据点,本文方法的相对误差都小于平均值法和EM-PCA算法。由此可见,本文提出的局部加权算法对缺失数据进行恢复,误差最小,准确性最高。

图3 3种方法在缺失点的相对误差Fig.3 Relative errors of three methods for missing points
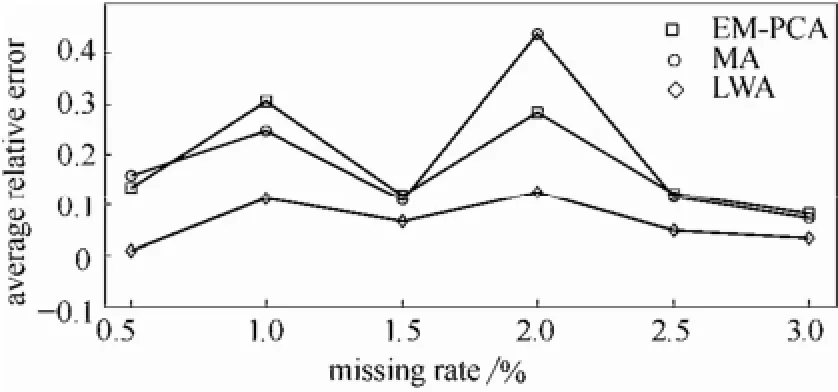
图4 不同缺失率下3种方法的平均相对误差Fig.4 Average relative errors of three methods at different missing rates
为了验证本文方法在不同缺失率下数据恢复的有效性,缺失率分别设置为 5‰、10‰、15‰、20‰、25‰ 和 30‰,3种方法的平均相对误差如图4所示。由图4可以看出,在不同的缺失率下,LWA方法的平均相对误差最小,恢复效果最好。
本文将 96个不等长的建模批次按照局部加权重构的方法恢复成等长数据后,批次的统一长度D为1700,而按照截取最短长度的方法只能保留1479维变量,丢弃了很多信息,使用本文的方法处理间歇过程中的不等长问题将充分挖掘原始数据的信息。
3.3 基于局部近邻标准化矩阵的模态聚类
计算等长批次数据的近邻距离矩阵Dk。图5是每个样本到其各个近邻距离的三维描述。从图5中可以看出样本近邻的距离矩阵没有模态特征,无法进行模态的准确聚类。
通过将数据进行局部标准化后,把各个近邻距离二次转换成局部近邻标准化矩阵。在计算局部近邻标准化矩阵时,k的选取主要考虑两个方面:一方面,k的选择不能过大,k需要小于单模态数,即k<32;另一方面,k的选择不能过小,如果k过小,局部近邻标准化距离矩阵的模态特征不明显。k的值在 20~30之间比较合适,本文中k=28。图6是局部近邻标准化矩阵中各个近邻距离的三维描述。从图6中可以看出原始的样本变换成局部近邻标准化矩阵后,突显各个模态间和模态内的特征,明显地呈现出3个模态,易于样本的模态聚类。

图5 样本的各个近邻距离Fig.5 Distances of neighbor samples

图6 局部近邻标准化矩阵的近邻距离Fig.6 Distances of each neighbor in local neighbor normalized matrix
使用K-means方法分别对近邻矩阵和局部近邻标准化矩阵进行样本的分类,如图7和图8所示。从图7可以看出,欧氏距离矩阵不能有效地分开前两个模态,而图8中运用局部近邻标准化矩阵能够对各个模态进行准确地聚类。
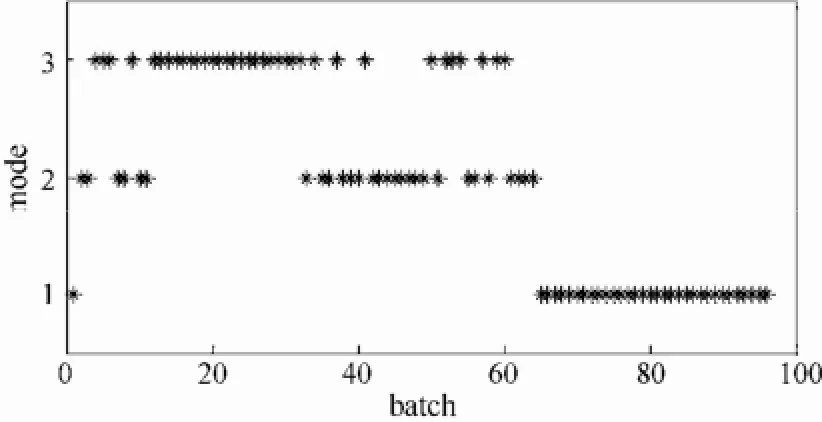
图7 近邻矩阵的K-means 聚类结果Fig.7 Clustering results of neighbor matrix using K-means

图8 局部近邻标准化矩阵的K-means聚类结果Fig.8 Clustering results of local neighbor normalized matrix using K-means
当新的批次到来时,首先运用LWA处理成等长的批次,在建模样本矩阵U中找到它的各个近邻,计算出该样本的局部近邻标准化矩阵。对该矩阵使用K-means方法进行模态的聚类,由各训练样本的模态标签确定待测批次所属的模态,然后,在其所属的模态下进行故障检测。将该过程称为自适应模态聚类的故障检测。基于LNNM的多模态过程故障检测结果如图9所示。由图9可以看出,本文方法只有1个校验批次超出控制限,但是各模态故障批次数据全部都能检测出来,没有漏检批次。

表1 在不同的数据恢复长度下LNNM方法的故障检测结果Table 1 Comparisons of fault detection results for LNNM with different data restoration lengths
为了验证缺失数据对故障检测的影响,选择不同的数据恢复长度,LNNM方法的故障检测结果如表1所示。由表1可以看出,当批次数据的恢复长度大于1632时,故障检测结果最佳,并保持稳定。
3.4 与其他算法的性能对比
3.4.1 与不等长间歇过程故障检测方法的性能对比
为了说明本文方法的有效性,将本文方法与其他几种处理不等长间歇过程的故障检测方法进行对比。运用最短长度法把不等长的批次截成等长的批次,然后运用MPCA、MKPCA和NNFS进行故障检测。各方法的主元个数通过累计贡献率确定。当贡献率大于 85%时,MPCA的主元个数为 2。MKPCA和 NNFS的核函数选用径向基函数。MKPCA的主元个数为62,核窗宽C=4200。NNFS的主元个数为8,近邻数k为35。运用文献[15]中基于多块统计特征(multiblock statistics, MBS)的不等长间歇过程故障检测方法进行检测。各方法的检测结果如表2所示。由表2可以看出,4种方法的故障批次没有全部检测出来,都存在漏报。

图9 基于LNNM的多模态过程故障检测结果Fig.9 Fault detection results of multimode process based on LNNM
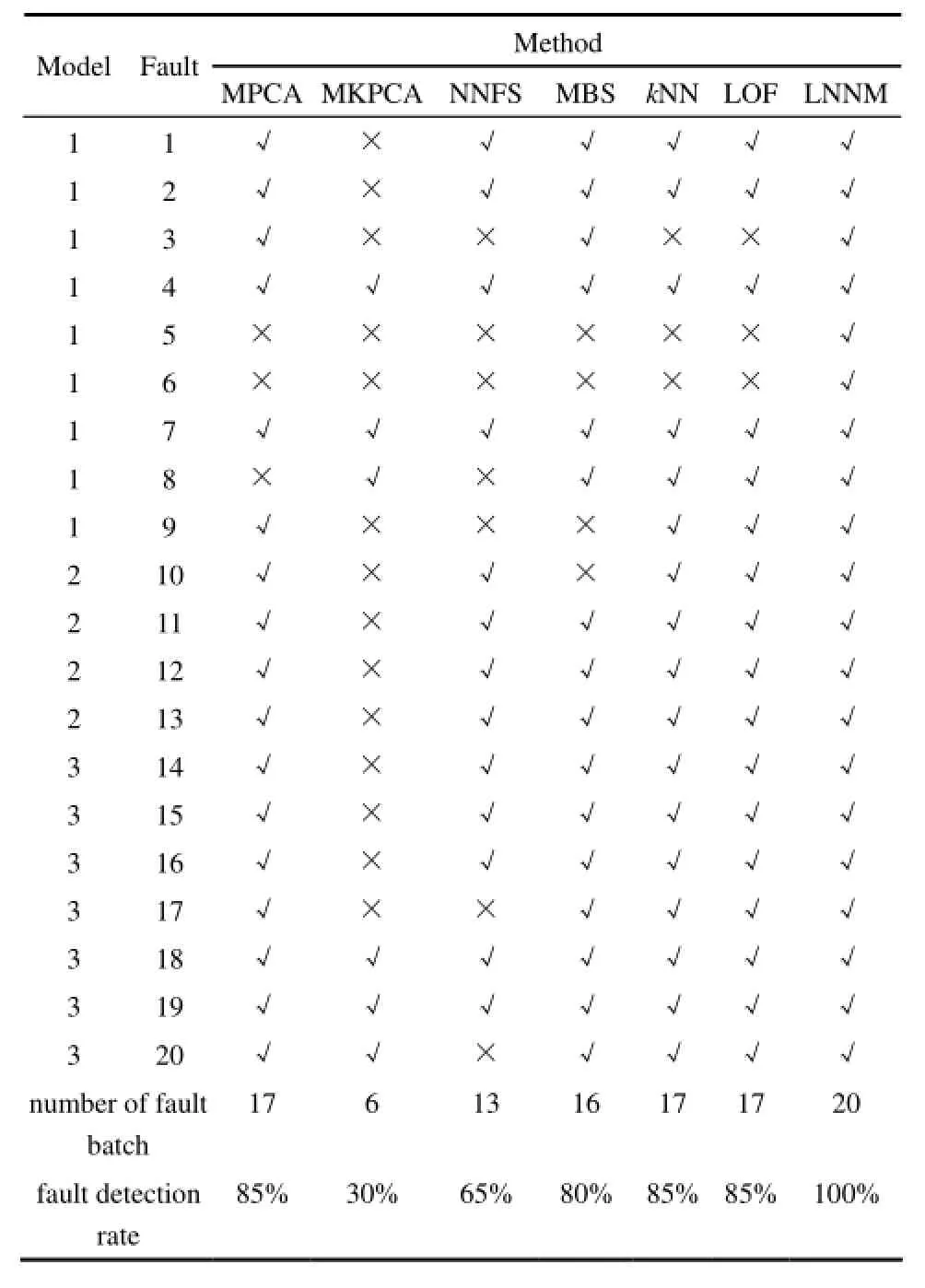
表3 各方法对20种故障的检测结果对比Table 2 Comparisons of detection results for 20 faults with different methods
3.4.2 与多模态过程故障检测方法的性能对比 运用最短长度法把不等长批次截成等长的批次,然后运用基于 kNN、LOF的多模态故障检测方法进行检测。kNN中,近邻数k=3。各方法的检测结果如表2所示。与上述不等长间歇过程的故障检测方法相比,多模态算法的检测性能有所提高。但是两种方法仍存在漏报。
各种方法对11个校验批次的检测结果对比如表3所示。由表2和表3可以看出,对于具有 3个模态的半导体间歇过程数据,MKPCA算法的检测效果最不理想,原因是该算法受核窗宽参数的影响很大,目前没有一种有效的方法确定核窗宽的取值。MPCA处理半导体数据时,由于数据的非线性和多工况等特性的影响,容易产生误报。MBS方法的性能受分块大小的影响。基于欧氏距离的 kNN 和 LOF 算法能检测出 17个故障批次,但是对于与边缘建模样本距离很近的故障数据的检测效果不佳。与上述算法相比,本文方法的故障检测效果最好。原因如下。
(1)在处理不等长批次问题上,本文方法能有效地保留不等长数据的信息,避免建模数据信息的缺失和不完善。
(2)只要选取的近邻数k小于单模态的样本数,本文方法就能建立局部近邻标准化矩阵模型。该模型突显各个模态的轮廓特征,能准确捕捉模态之间和模态内的非线性位置关系,降低误报和漏报。
(3)通过剔除离群样本点,减少边缘建模数据的偏离程度,提高SPE和T2控制限的准确度。其他方法无法检测出来的微小故障3、5和6,该方法也能成功检测出来,提高故障检测率。

表3 各方法对校验批次的检测结果对比Table 3 Comparisons of detection results for validation batch with different methods
4 结 论
本文提出一种不等长的多模态间歇过程故障检测方法。该算法首先利用局部加权方法处理不等长的间歇过程数据,在此基础上由样本数据构造局部近邻标准化矩阵,放大了各个模态的特征,与此同时,也起到了降低维数的作用。通过对该矩阵的聚类和离群点的剔除,实现了自适应跟随模态分离,并确定统一的模型控制限。 将本文的方法应用到实际的半导体工业数据中,仿真结果表明,与传统的故障检测算法相比,本文算法的故障检测率最高,验证了该方法的有效性。
符 号 说 明
A, B,C, D ——分别为主元个数、批次展开矩阵、批次长度集合和恢复数据的长度。
E, e, eu,lm——分别为残差向量、模态总数、缺失数据点的相对误差和数据点的个数
F,I,J,K,k ——分别为完备数据集、批次总数、变量个数、采样时间向量和近邻个数
L, M, N, P ——分别为批次长度集合、不完备矩阵、样本近邻编号矩阵和负载矩阵
U, M1,——分别为标准化近邻矩阵、维数分别为lm和D的样本
v, W, X, Z——分别为变量、权值矩阵、多模态样本、样本与近邻样本的差值矩阵。
α, λ , Σ——分别为置信水平、特征值和协方差矩阵
上、下角标
i,j——批次序号,变量序号
r——模态编号
If,Im——完备数据集,不完备数据集
References
[1] 周东华, 李钢, 李元. 数据驱动的工业过程故障诊断技术[M]. 北京: 科学出版社, 2011: 1-14.
ZHOU D H, LI G, LI Y. Industrial Process Fault Diagnosis of Data-driven [M]. Beijing: Science Press, 2011: 1-14.
[2] GE Z Q, SONG Z H, GAO F R. Review of recent research on data-based process monitoring [J]. Industrial & Engineering Chemistry Research, 2013, 52(10): 3543-3562.
[3] 郭金玉, 齐蕾蕾, 李元. 基于DMOLPP的间歇过程在线故障检测[J]. 仪器仪表学报, 2015, 36(1): 28-36.
GUO J Y, QI L L, LI Y. On-line fault detection of batch process based on DMOLPP [J]. Chinese Journal of Scientific Instrument, 2015, 36(1): 28-36.
[4] NOMIKOS P, MACGREGOR J F. Monitoring batch processes using multiway principal component analysis [J]. AIChE J., 1994, 40(8): 1361-1375.
[5] JIA M X, XU H Y, LIU X F, et al. The optimization of the kind and parameters of kernel function in KPCA for process monitoring [J]. Computers & Chemical Engineering, 2012, 46(15): 94-104.
[6] ZHAO S J, ZHANG J, XU Y M. Performance monitoring of process with multiple operation modes through multiple PLS models [J]. Journal of Process Control, 2006, 16(7): 763-772.
[7] YU J. A nonlinear kernel Gaussian mixture model based inferential monitoring approach for fault detection and diagnosis of chemical processes [J]. Chemical Engineering Science, 2012, 68(1): 506-519.
[8] HE Q P, WANG J. Fault detection using the k-nearest neighbor rule for semiconductor manufacturing processes [J]. IEEE Transactions on Semiconductor Manufacturing, 2007, 20(4): 345-354.
[9] 马贺贺, 胡益, 侍洪波. 基于马氏距离局部离群因子方法的复杂化工过程故障检测 [J]. 化工学报, 2013, 64(5): 1674-1682.
MA H H, HU Y, SHI H B. Fault detection of complex chemical processes using Mahalanobis distance-based local outlier factor [J]. CIESC Journal, 2013, 64(5): 1674-1682.
[10] 刘帮莉, 马玉鑫, 侍洪波. 基于局部密度估计的多模态过程故障检测 [J]. 化工学报, 2013, 65(8): 3071-3081.
LIU B L, MA Y X, SHI H B. Multimode process monitoring based on local density estimation [J]. CIESC Journal, 2014, 65(8): 3071-3081.
[11] 郭小萍, 姜芹芹, 李元. 近邻标准化样本核特征量驱动的间歇过程故障检测 [J]. 计算机与应用化学, 2014, 31(10): 1157-1161.
GUO X P, JIANG Q Q, LI Y. Fault detection based on kernel feature statistics of samples standardized with nearest neighborhood for batch process [J]. Computers and Applied Chemistry, 2014, 31(10): 1157-1161.
[12] DENG X G, TIAN X M. Multimode process fault detection using local neighborhood similarity analysis [J]. Chinese Journal ofChemical Engineering, 2014, 22(11): 1260-1267.
[13] 郭金玉, 陈海彬, 李元. 基于在线升级主样本建模的批次过程kNN故障检测方法 [J]. 信息与控制, 2014, 43(4): 495-500.
GUO J Y, CHEN H B, LI Y. kNN fault detection method for batch process based on principal sample modeling upgraded online [J]. Information and Control, 2014, 43(4): 495-500.
[14] 郭金玉,赵璐璐,李元. 基于统计特征的不等长间歇过程故障诊断研究 [J]. 计算机应用研究, 2014, 31(1): 128-130.
GUO J Y, ZHAO L L, LI Y. Fault diagnosis for uneven-length batch processes based on statistic features [J]. Application Research of Computers, 2014, 31(1): 128-130.
[15] GUO J Y, CHEN H B, LI Y. MPCA fault detection method based on multiblock statistics for uneven-length batch processes [J]. Journal of Computational Information Systems, 2013, 9(18): 7181-7190.
[16] SONG B, SHI H B, MA Y X, et al. Multisubspace principal component analysis with local outlier factor for multimode process monitoring [J]. Industrial & Engineering Chemistry Research, 2014, 53(42): 16453-16464.
[17] WANG F, TAN S, PENG J, et al. Process monitoring based on mode identification for multi-mode process with transitions [J]. Chemometrics and Intelligent Laboratory Systems, 2012, 110(1): 144-155.
[18] XIANG S M, NIE F P, PAN C H, et al. Regression reformulations of LLE and LTSA with locally linear transformation [J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 2011, 41(5): 1250 -1262.
[19] GUO J Y, YUAN T M, LI Y. Imputation of missing data based on locally weighted algorithm [J]. Journal of Computational Information Systems, 2015, 11(4): 1195-1204.
[20] MA H H, HU Y, SHI H B. Fault detection and identification based on the neighborhood standardized local outlier factor method [J]. Industrial & Engineering Chemistry Research, 2013, 52(6): 2389-2402.
[21] LI Y, ZHANG X M. Diffusion maps based k-nearest-neighbor rule technique for semiconductor manufacturing process fault detection [J]. Chemometrics and Intelligent Laboratory Systems, 2014, 136(15): 47-57.
[22] MUTEKI K, MACGREGOR J F, UEDA T. Estimation of missing data using latent variable methods with auxiliary information [J]. Chemometrics and Intelligent Laboratory Systems, 2005, 78(1): 41-50.
[23] 孙怀宇, 刘芳, 李元. EM-PCA在化工过程随机缺失数据补值中的应用研究 [J].计算机与应用化学, 2013, 30 (7): 735-738.
SUN H Y, LIU F, LI Y. Imputation of random missing data in chemical engineering process with EM-PCA [J]. Computers and Applied Chemistry, 2013, 30 (7): 735-738.
2015-07-20收到初稿,2015-11-22收到修改稿。
联系人:李元。第一作者:郭金玉 (1975-),女,博士研究生,副教授。
Received date: 2015-07-20.
DOI:10.11949/j.issn.0438-1157. 20151157 10.11949/j.issn.0438-1157.20151157
中图分类号:TP 277
文献标志码:A
文章编号:0438—1157(2016)07—2916—09
基金项目:国家自然科学基金重大项目(61490701);国家自然科学基金项目(61174119);辽宁省教育厅项目(L2013155, L2015432);辽宁省教育厅重点实验室项目(LZ2015059)。
Corresponding author:LI Yuan, li-yuan@mail.tsinghua.edu.cn supported by the Key Project of National Natural Science Foundation of China (61490701), the National Natural Science Foundation of China (61174119), the Education Department Research Project of Liaoning Province (L2013155, L2015432 ) and the Key Laboratory Project of Education Department of Liaoning Province (LZ2015059).
Fault detection method for uneven-length multimode batch processes
GUO Jinyu, YUAN Tangming, LI Yuan
(College of Information Engineering, Shenyang University of Chemical Technology, Shenyang 110142, Liaoning, China)
Abstract:A fault detection algorithm for uneven-length multimode batch processes is proposed. First, the local weighted algorithm is used to preprocess the uneven-length batch data. In the training sample, the maximum retention length of uneven-length data is determined. Using the k-nearest neighbor information, the missing data points are reconstructed by weighting reconstruction. Secondly, the local neighbor normalized matrix is estimated for the training set of equal length. The K-means algorithm is used to classify the models. The local outlier factor method is used to determine the first control limits and remove outliers. Finally, the MPCA model is established and the second control limits are determined for each model. The unified statistics and control limits are calculated according to the matching coefficients of the control limit of the various models. The multimode fault detection is carried out under the unified control limits. The algorithm is applied to the semiconductor industrial process. Simulation results show that the proposed algorithm improves the fault detection rate relative to the traditional fault detection algorithms. The effectiveness of the proposed method is verified.
Key words:multimode process; fault detection; uneven-length data; principal component analysis; algorithm; model; local outlier factor; local neighbor normalized matrix
